




In this article, we will be looking at how to visualize and analyze weather data using GridDB. We will be loading a dataset available as a CSV file into GridDB, then fetching the data from GridDB and performing data analysis on it. We will be using the Weather Dataset.
Full source code for this article can be found here
Loading Data into GridDB and then fetching data from GridDB
var griddb = require('griddb_node');
const createCsvWriter = require('csv-writer').createObjectCsvWriter;
const csvWriter = createCsvWriter({
path: 'out.csv',
header: [
{id: "DATE", title:"DATE"},
{id: "WIND", title:"WIND"},
{id: "IND", title:"IND"},
{id: "RAIN", title:"RAIN"},
{id: "IND.1", title:"IND.1"},
{id: "T.MAX", title:"T.MAX"},
{id: "IND.2" , title:"IND.2"},
{id: "T.MIN", title:"T.MIN"},
{id: "T.MIN.G", title:"T.MIN.G"},
]
});
const factory = griddb.StoreFactory.getInstance();
const store = factory.getStore({
"host": '239.0.0.1',
"port": 31999,
"clusterName": "defaultCluster",
"username": "admin",
"password": "admin"
});
// For connecting to the GridDB Server we have to make containers and specify the schema.
const conInfo = new griddb.ContainerInfo({
'name': "windspeedanalysis",
'columnInfoList': [
["name", griddb.Type.STRING],
["DATE", griddb.Type.STRING],
["WIND", griddb.Type.STRING],
["IND", griddb.Type.STRING],
["RAIN", griddb.Type.STRING],
["IND.1", griddb.Type.STRING],
["T.MAX", griddb.Type.STRING],
["IND.2", griddb.Type.STRING],
["T.MIN", griddb.Type.STRING],
["T.MIN.G", griddb.Type.STRING]
],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});
const csv = require('csv-parser');
const fs = require('fs');
var lst = []
var lst2 = []
var i =0;
fs.createReadStream('./dataset/windspeed.csv')
.pipe(csv())
.on('data', (row) => {
lst.push(row);
console.log(lst);
})
.on('end', () => {
var container;
var idx = 0;
for(let i=0;i<lst.length;i++){
// lst[i]['DATE'] = String(lst[i]["DATE"])
// lst[i]['WIND'] = parseFloat(lst[i]["WIND"])
// lst[i]['IND'] = parseInt(lst[i]["IND"])
// lst[i]['RAIN'] = parseFloat(lst[i]["RAIN"])
// lst[i]['IND.1'] = parseInt(lst[i]["IND.1"])
// lst[i]['T.MAX'] = parseFloat(lst[i]["T.MAX"])
// lst[i]['IND.2'] = parseInt(lst[i]["IND.2"])
// lst[i]['T.MIN'] = parseFloat(lst[i]["T.MIN"])
// lst[i]['T.MIN.G'] = parseFloat(lst[i]["T.MIN.G"])
store.putContainer(conInfo, false)
.then(cont => {
container = cont;
return container.createIndex({ 'columnName': 'name', 'indexType': griddb.IndexType.DEFAULT });
})
.then(() => {
idx++;
container.setAutoCommit(false);
return container.put([String(idx), lst[i]['DATE'],lst[i]["WIND"],lst[i]["IND"],lst[i]["RAIN"],lst[i]["IND.1"],lst[i]["T.MAX"],lst[i]["IND.2"],lst[i]["T.MIN"],lst[i]["T.MIN.G"]]);
})
.then(() => {
return container.commit();
})
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
}
store.getContainer("windspeedanalysis")
.then(ts => {
container = ts;
query = container.query("select *")
return query.fetch();
})
.then(rs => {
while (rs.hasNext()) {
let rsNext = rs.next()
lst2.push(
{
'DATE': rsNext[1],
"WIND": rsNext[2],
"IND": rsNext[3],
"RAIN": rsNext[4],
"IND.1": rsNext[5],
"T.MAX": rsNext[6],
"IND.2": rsNext[7],
"T.MIN": rsNext[8],
"T.MIN.G": rsNext[9],
}
);
}
csvWriter
.writeRecords(lst2)
.then(()=> console.log('The CSV file was written successfully'));
return
}).catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
});
Note: For running the d3.js in the html file an httpserver should be run first to read the output csv file containing the data fetched from GridDB.
Data Visualization:
For the purpose of plotting and drawing tables, we will use D3.js, a library that allows manipulation of documents based on data. HTML DOM manipulation and visualization is possible with this library.
We will first start with printing the first few rows of the dataset to get a feel for the data. For this purpose we are going to have to write the code for creating and inserting data into an html table. This is going to be helper code and will be included in the source files, and is beyond the scope of this article.
Once this is done, we can write the code for printing the table.
let result = data.flatMap(Object.keys);
result = [...new Set(result)];
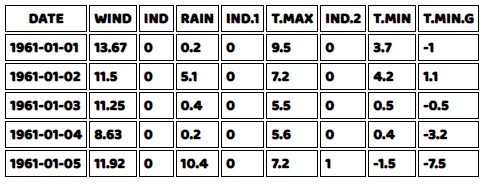
tables("data_table",data,result,true)In the code above, result is the array of columns of our data, and “data_table” is the HTML Element ID for the table we are going to insert data into. The last argument is a flag for showing the top 5 rows, which we set to true.
Here we see the result of our code:
Now that we see the kind of data that we have, we would now want to look at a summary of different statistics related to all the numeric columns of our data. We can use the same helper function for the drawing the table to the HTML document, but we will need to write the code for getting all the summarized quantities. We will get the Minimum, Maximum, Deviation, Mean, Median and a Count of rows that are not null in the data. Fortunately D3.js provides functions for most of these, but we will have to create a helper function for the count of not null rows. We can simply write a for loop and increment a value if the row for that column is not null and return the value at the end.
const countNotNull = (array) => {
let count = 0
for(let i = 0; i < array.length; i++){
if(isNaN(parseInt(array[i]))==false && array[i]!==null){ count++ }}
return count
};With that out of the way, we can write the for loop for getting the summary data of our dataset. We are going to use an HTML element with the ID “data_table2” to draw this table.
let obj = {}
let summary_data = []
for(let i = 0; i < result.length; i++){
obj[result[i]] = data.map(function(elem){return elem[result[i]]});
let count = 0
let summarize = {}
if(result[i]!='DATE'){
obj[result[i]] = obj[result[i]].map(Number)
}
summarize['Field'] = result[i]
summarize['Max'] = d3.max(obj[result[i]])
summarize['Min'] = d3.min(obj[result[i]])
summarize['Deviation'] = d3.deviation(obj[result[i]])
summarize['Mean'] = d3.mean(obj[result[i]])
summarize['Median'] = d3.median(obj[result[i]])
summarize['Count Not Null'] = countNotNull(obj[result[i]])
summary_data.push(summarize)
}
let result2 = summary_data.flatMap(Object.keys)
result2 = [...new Set(result2)];
tables("data_table2",summary_data,result2,false)The result should be as follows:
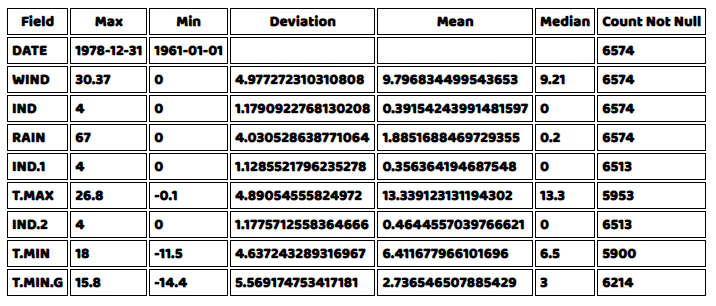
Now, we would want to see the actual distributions for each of the columns in the data in the form of histogram and a box plot. Again for both plots we will need to write helper functions, which are provided in the source files. After writing those helper functions, we can call them directly in our main javascript file.
## WindSpeed
histogram("my_dataviz",obj['WIND'],'Average Wind Speed')
boxplot("my_dataviz",obj['WIND'],"Wind Speed")
## Precipitation
histogram("my_dataviz2",obj['RAIN'],'Precipitation (Rain)',"orange")
boxplot("my_dataviz2",obj['RAIN'],"Precipitation (Rain)",'brown')
## Max Temperature
histogram("my_dataviz3",obj['T.MAX'],'Max Temperature',"green")
boxplot("my_dataviz3",obj['T.MAX'],"Max Temperature",'yellow')
## Min Temperature
histogram("my_dataviz4",obj['T.MIN'],'Min Temperature',"purple")
boxplot("my_dataviz4",obj['T.MIN'],"Min Temperature",'pink')
## Minimum Grass Temperature
histogram("my_dataviz5",obj['T.MIN.G'],'Minimum Grass Temperature',"cyan")
boxplot("my_dataviz5",obj['T.MIN.G'],"Minimum Grass Temperature",'orange')
## Indicator Variable
histogram("my_dataviz6",obj['IND'],'Indicator')
## Indicator Variable 1
histogram("my_dataviz7",obj['IND.1'],'Indicator 1',"orange")
## Indicator Variable 2
histogram("my_dataviz8",obj['IND.2'],'Indicator 2',"green")In each of these plotting functions, the first argument is the ID of the html element in which we want to draw the plot, then the array of the column of the data we want to plot, then a title and a CSS-compatible color code. We can visualize the results by opening the html file from the web server.
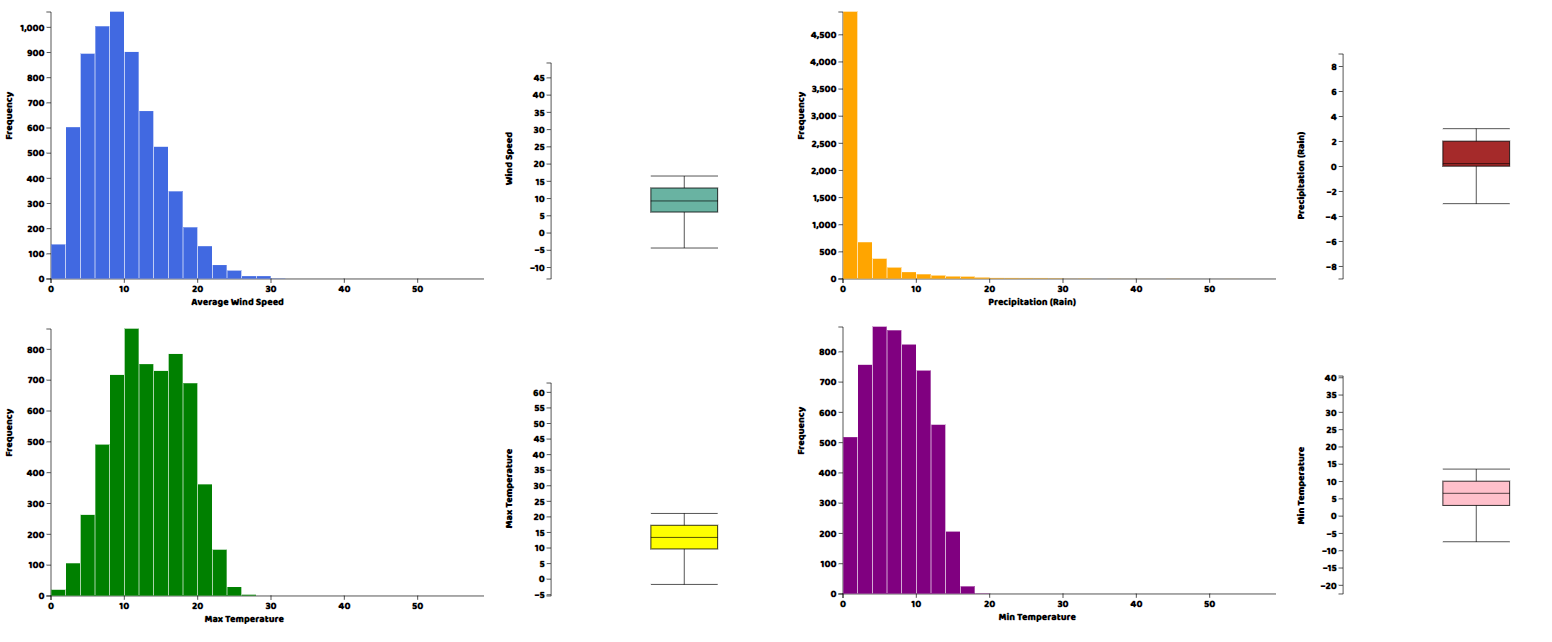
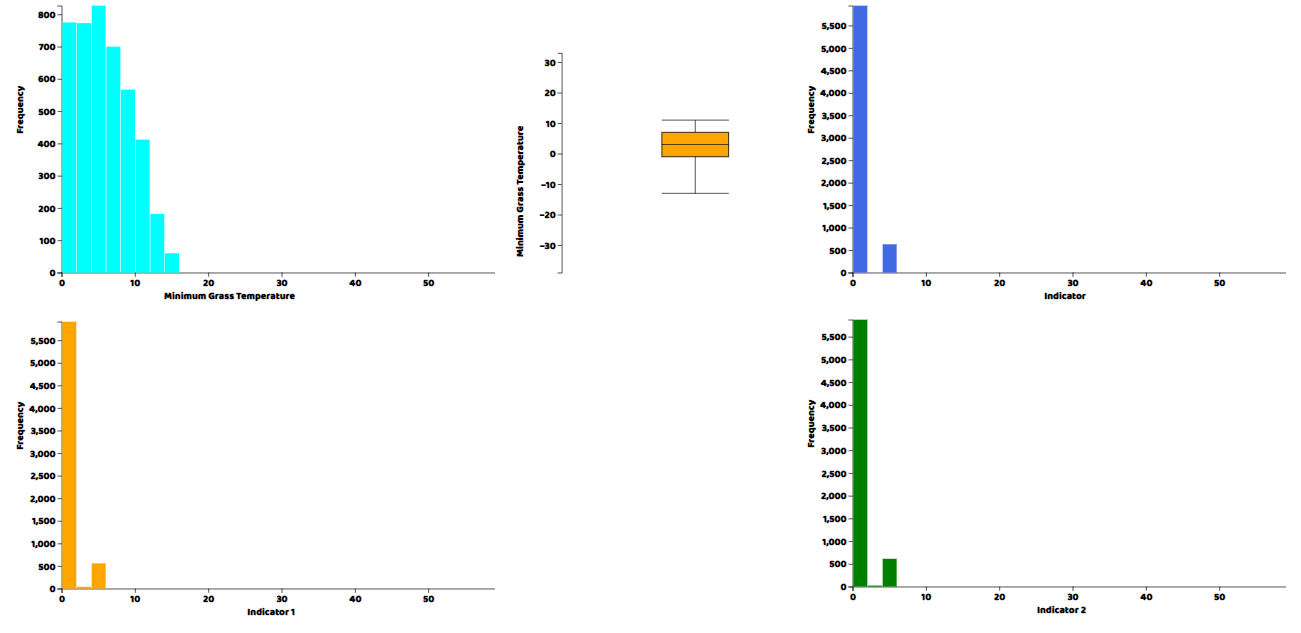
We’ve had a look at plots for distributions, but since the data is a timeseries, we should also plot its columns against time to visualize the trends and patterns in the data. So now we are going to make a line plot of each of the variables in the dataset. The lineplot() function was written by us and is included in the source files.
lineplot("my_dataviz9",data,obj,'DATE','WIND','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','RAIN','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','T.MAX','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','T.MIN','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','T.MIN.G','#4169e1')And here are the results.
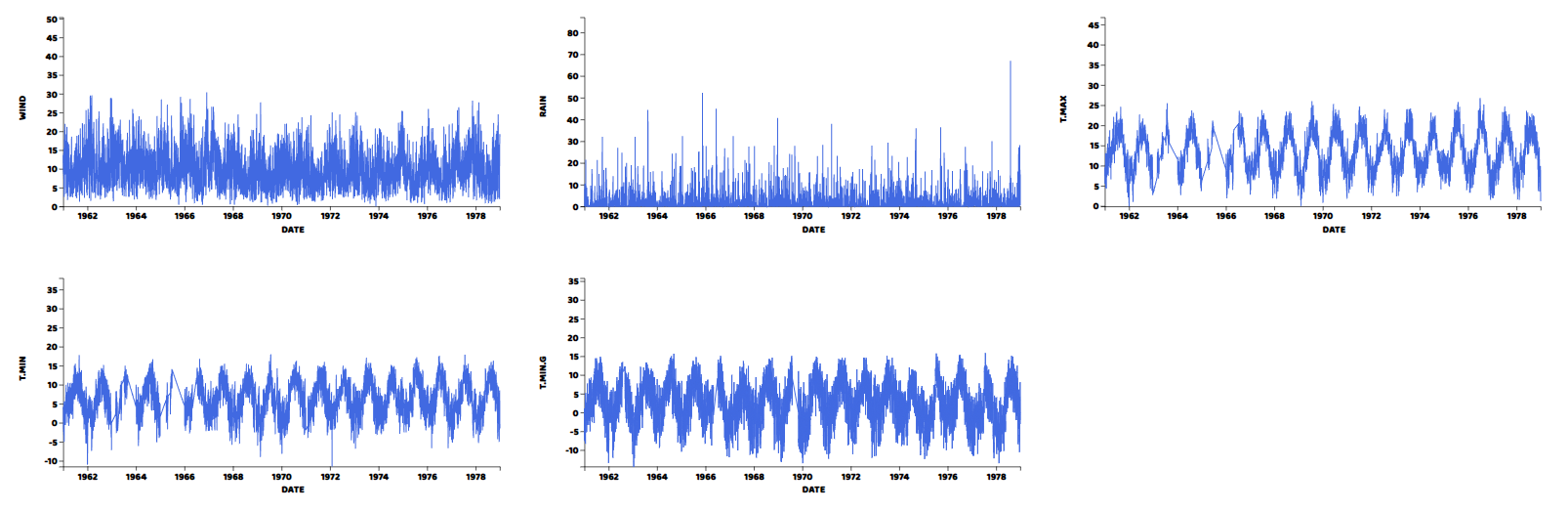
We can see from the graphs that all variables have periodic pattern as expected from weather data and have averages just as shown by the histograms.
Lastly, we can plot a correlation matrix to see which columns are correlated with each other, an important thing to look for when making predictions, as we would want to include variables in our model that are correlated with the target variable and exclude variables that are correlated to each other. A simple call to correllogram() function with the data as an argument will give us the correlation matrix. correllogram() comes from correl.js file which is provided in the source file.
correlogram(data)And here is what the correlation matrix looks like:
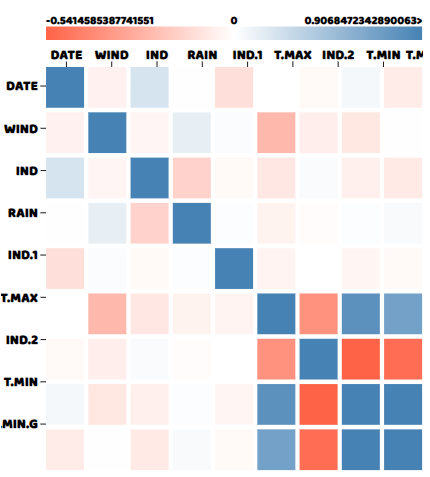
Full source code for this article can be found here
We can see from the correlation matrix that T.MIN and T.MIN.G are highly correlated with each other, while T.MIN and IND2 are the negatively correlated. While other variables mostly have near to zero correlation with each other, which is expected.
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.