



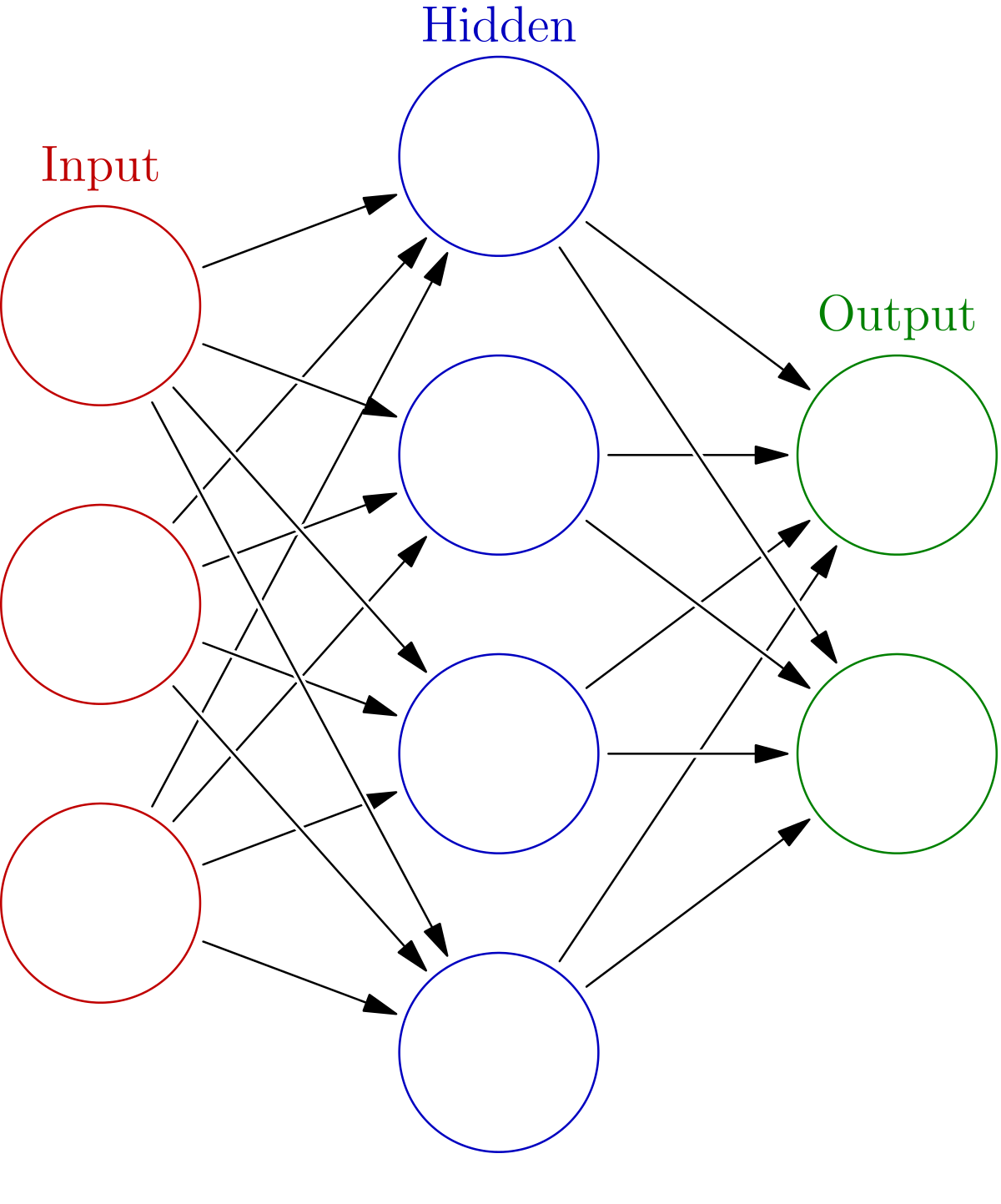
ニューラルネットワークは、過去5年間で機械学習と予測モデリングの世界を席巻しました。ニューラルネットワークは、データの複雑な関係を学習する能力を持ち、金融からロボット工学まで、さまざまな分野でその効果が確認されています。人間の脳にヒントを得たニューラルネットワークは、あるニューロンから別のニューロンへの信号伝達の原理で動作します。ニューラルネットワークは、主に3種類のノード層(入力層、1つまたは複数の隠れ層、出力層)で構成されています。各ノードは、非線形関数を用いて他のノードに接続する人工的なニューロンで、重みとしきい値が関連付けられています。ニューロンは、出力が指定されたしきい値を超えた場合にのみ活性化される。このようにして、データはネットワークの次の層に渡されます。
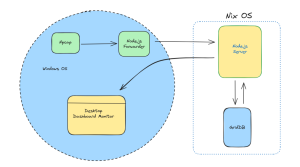
東芝GridDBは、IoTやビッグデータに最適化されたスケーラブルなデータベースです。GridDBは、大量のデータを簡単に収集、保存、照会することができます。さらに、GridDBは高いスケーラビリティと信頼性を備えているため、ニューラルネットワークの学習・推論用のデータベースとしても最適です。GridDBのインストールは非常に簡単で、ドキュメントも充実しています。また、python-gridDBクライアントについては、このビデオを参照してください。
この記事では、PythonでGridDBを使って、シンプルなニューラルネットワークベースの分類モデルを作成します。ここでは、ディープラーニングモデルの開発と評価のために、使いやすい無料のオープンソースPythonライブラリであるKerasを使用します。
セットアップ
まずは、GridDBをセットアップしましょう。
Ubuntu 20.04でのGridDB Pythonクライアントのクイックセットアップ
- GridDBのインストール
ここからdebをダウンロードしてインストールします。
- GridDB Cクライアントのインストール
ここからUbuntu向けのgriddb-c-clientをダウンロードしてインストールします。
- その他のインストール
1) Swigのインストール
wget https://github.com/swig/swig/archive/refs/tags/v4.0.2.tar.gz
tar xvfz v4.0.2.tar.gz
cd swig-4.0.2
./autogen.sh
./configure
make
2) pythonクライアントのインストール
wget https://github.com/griddb/python_client/archive/refs/tags/0.8.4.zip
unzip 0.8.4.zip
cd python_client-0.8.4
make
対応するpythonのバージョンのpython-devがインストールされていることを確認してください。この記事ではpython 3.8を使用します。
3) 環境変数の設定
環境変数に正しい位置を示す必要があります。
export CPATH=$CPATH:<python header file directory path>
export LIBRARY_PATH=$LIBRARY_PATH:<c client library file directory path>
こちらのように、dockerでGridDBを利用することもできます。
Python ライブラリ
次にpythonのライブラリをインストールします。matplotlib、numpy、keras、tensorflow、pandasのインストールはpipで簡単にできます。
pip install keras
pip install numpy
pip install tensorflow
pip install matplotlib
pip install pandas
予測
ステップ 1: データセットをダウンロードする
今回は、Kaggleから公開されているデータセットを使用します。今回は、携帯電話の価格分類を選びました。目的は、携帯電話を4つの価格カテゴリーに分類することです。以下は、データセットの説明です。
| カラム | 説明 |
|---|---|
| battery_power | 電池が一度に蓄えることのできるエネルギーの総量。単位はmAh。 |
| blue | Bluetoothの有無 |
| clock_speed | マイクロプロセッサが命令を実行する速度 |
| dual_sim | デュアルSIMに対応しているかどうか |
| fc | フロントカメラの画素数 |
| four_g | 4Gを搭載しているかどうか |
| int_memory | 内蔵メモリ(ギガバイト) |
| m_dep | 携帯電話の厚み。単位はcm。 |
| mobile_wt | 携帯電話の重量 |
| n_cores | プロセッサのコア数 |
| pc | メインカメラの画素数 |
| px_height | 画面の解像度(縦) |
| px_width | 画面の解像度(横) |
| ram | RAM(単位:メガバイト) |
| sc_h | 画面のサイズ(縦)。単位はcm。 |
| sc_w | 画面のサイズ(横)。単位はcm。 |
| talk_time | 1回の充電での最長通話時間 |
| three_g | 3Gを搭載しているかどうか |
| touch_screen | タッチスクリーンの有無 |
| wifi | 無線LANの有無 |
| price_range | 0(低コスト)、1(中コスト)、2(高コスト)、3(非常に高コスト) |
ステップ 2: ライブラリーのインポート
まず、データセットを読み込むためのpandas、ビジュアル化のためのmatplotlib、深層学習モデルのためのtensorflowなど、関連するライブラリをインポートします。
import tensorflow as tf
import numpy as np
import pandas as pd
from tensorflow import keras
from tensorflow.keras import layers
ステップ 3: データの読み込みと処理
データ読み込み
まず、データを読み込みます。これにはpandasのread_csv機能を使います。データセットには、テストとトレーニングがすでに2つのファイルに分けられていることに注意してください。
dataframe = pd.read_csv('train.csv')あるいは、GridDBを使ってこのデータフレームを取得することもできます。
特徴量のエンコーディング
まず、データセットをカテゴリーと数値のフォーマットにエンコードします。数値の場合はデータを正規化し、カテゴリカルの場合はデータタイプを変換します。また、特徴量のセットを作成し、特徴量のセットからターゲットを削除します。
numeric_feats = ["mobile_wt", "m_dep", "int_memory", "fc", "clock_speed", "talk_time","n_cores", "sc_w", "sc_h", "ram", "px_width","px_height","pc", "battery_power"]
dataframe[numeric_feats] = dataframe[numeric_feats].apply(lambda x: (x - np.mean(x)) / (np.max(x) - np.min(x)))
categorical_feats = ["blue", "four_g", "dual_sim", "wifi", "touch_screen", "three_g","price_range"]
dataframe[categorical_feats] = dataframe[categorical_feats].astype("category")
features = numeric_feats + categorical_feats
features.remove("price_range")
これで、データセットを記述し、分布を確認することができます。
dataframe[numeric_feats].describe()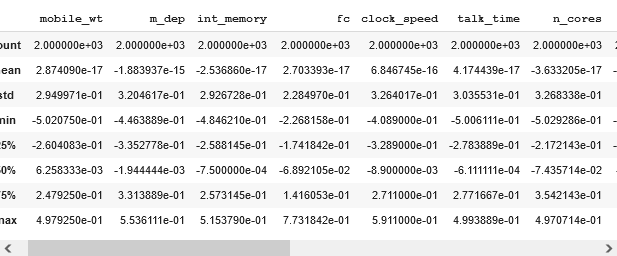
dataframe[categorical_feats].describe()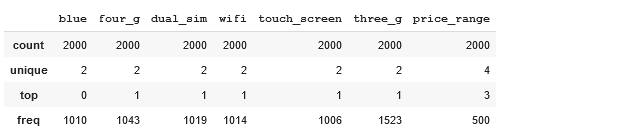
データを検証用と学習用に分ける
次に、学習中にデータをテストするための小さな検証セットを作成し、データに過剰適合していないことを確認します。ここでは、データの20%を検証セットとして使用します。
val_dataframe = dataframe.sample(frac=0.2, random_state=1337)
train_dataframe = dataframe.drop(val_dataframe.index)
print("Number of training samples:", len(train_dataframe))
print("Number of validation samples:", len(val_dataframe))
Keras用のデータの準備
これはマルチクラスの分類問題なので ターゲットをワンショットエンコーディングに変換する必要があります。これには tf.keras.utils.to_categorical を使用します。kerasはnumpyの配列を取り込むので、pandasのデータフレームをnumpyに変換します。
Y_train = tf.keras.utils.to_categorical(train_dataframe["price_range"], num_classes=4)
Y_val = tf.keras.utils.to_categorical(val_dataframe["price_range"], num_classes=4)
X_train = train_dataframe[features].values
X_val = val_dataframe[features].values
ステップ 4: 予測
次に、予測のプロセスを開始します。
初期化について
予測のための簡単なモデルを作成します。12層の高密度の層を追加します。なお、入力次元は20としています。そして、オーバーフィッティングを助けるドロップアウトモジュールを追加します。最後に、さらにいくつかの隠れ層を追加し、ソフトマックスで終了します。ソフトマックスでは、4つのクラスに対する4つの確率スコアが得られます。モデルの構成は、層を追加したり削除したりして自由に変更することができます。
# define the keras model
model = keras.Sequential()
model.add(layers.Dense(12, input_dim=20, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(8, activation='relu'))
model.add(layers.Dense(4, activation='softmax'))
学習
次に、モデルをコンパイルします。損失としてカテゴリカルクロスエントロピーを使用し、精度で評価します。理想的には、AUCやその他の適切と思われる指標を使用することができます。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])次に、200回のエポックでモデルを学習します。
num_epochs = 200
history = model.fit(X_train,
Y_train,
epochs=num_epochs ,
validation_data=(X_val, Y_val))
Epoch 1/200
50/50 [==============================] - 0s 2ms/step - loss: 0.1648 - accuracy: 0.9431 - val_loss: 0.2359 - val_accuracy: 0.9125
Epoch 2/200
50/50 [==============================] - 0s 2ms/step - loss: 0.1871 - accuracy: 0.9388 - val_loss: 0.1986 - val_accuracy: 0.9175
Epoch 3/200
....
Epoch 199/200
50/50 [==============================] - 0s 1ms/step - loss: 0.1245 - accuracy: 0.9575 - val_loss: 0.4880 - val_accuracy: 0.8075
Epoch 200/200
50/50 [==============================] - 0s 1ms/step - loss: 0.1267 - accuracy: 0.9600 - val_loss: 0.4585 - val_accuracy: 0.8150
評価
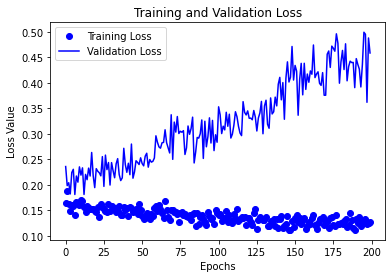
次に、訓練と検証の損失と精度をプロットします。理想的には、損失が減少し、精度が向上するはずです。
history = history.history
import matplotlib.pyplot as plt
%matplotlib inline
epochs = list(range(num_epochs))
loss = history["loss"]
val_loss = history["val_loss"]
plt.plot(epochs, loss, 'bo', label="Training Loss")
plt.plot(epochs, val_loss, 'b', label="Validation Loss")
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss Value')
plt.legend()
plt.show()
epochs = list(range(num_epochs))
accuracy = history["accuracy"]
val_accuracy = history["val_accuracy"]
plt.plot(epochs, accuracy, 'bo', label="Accuracy")
plt.plot(epochs, val_accuracy, 'b', label="Val Accuracy")
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss Value')
plt.legend()
plt.show()
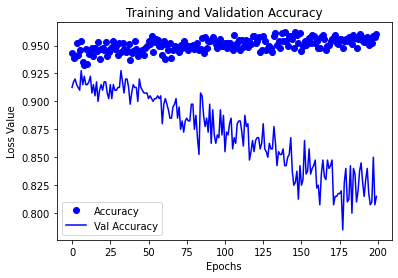
これは、モデルがオーバーフィットしていることを意味しています。この場合、エポック数を減らす、別の損失関数を使用する、データを議論するなど、いくつかの戦略を試すことができます。
予測
# evaluate the keras model
test = pd.read_csv('test.csv')
test[numeric_feats] = test[numeric_feats].apply(lambda x: (x - np.mean(x)) / (np.max(x) - np.min(x)))
if "price_range" in categorical_feats:
categorical_feats.remove("price_range")
test[categorical_feats] = test[categorical_feats].astype("category")
feats = test[features].values
predictions = model.predict(feats)
predictions = np.argmax(predictions, axis=1)
最後にテストデータをロードして予測します。kerasは各クラスの確率を返すので、クラスを得るためにargmaxを取ることに注意してください。
まとめ
この記事では、分類タスクのためにシンプルなニューラルネットワークを訓練する方法を学びました。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb