
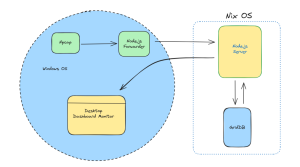


以前のブログ で、GridDB Cloud v1.2でリリースされた変更点についてご紹介しましたが、今回は新たに Power BIとの連携について紹介したいと思います。
Power BI はソフトウェアサービス、アプリケーション、コネクタの集合体で、相互に関連性のないデータソースを、まとまりがあり視覚的にめりはりの効いた、双方向の洞察が可能な形で連携させることを可能にします。基本的にこのマイクロソフトのアプリケーションは、Excel、GridDB Cloudなど様々なソースからデータを集約し、このデータすべてを1つのグラフィックで可視化することができます。このPower BIのビジュアルは素晴らしいものです。
GridDB Cloudを接続する
GridDB CloudのデータをPower BIアプリケーションに表示するには、様々な方法があります。ここでは、カスタムクエリ、ファイル、ODBC、オンプレミスデータゲートウェイの4つの方法について、順を追って説明します。
Custom Query
カスタムクエリを始めるには、まずPower BI内の「データを取得」タブを選択し、「白紙のクエリ」オプションを選択します。すると、新しいウィンドウが表示されます。
![]()
このウィンドウで、「アドバンスト・エディター」を選択します。
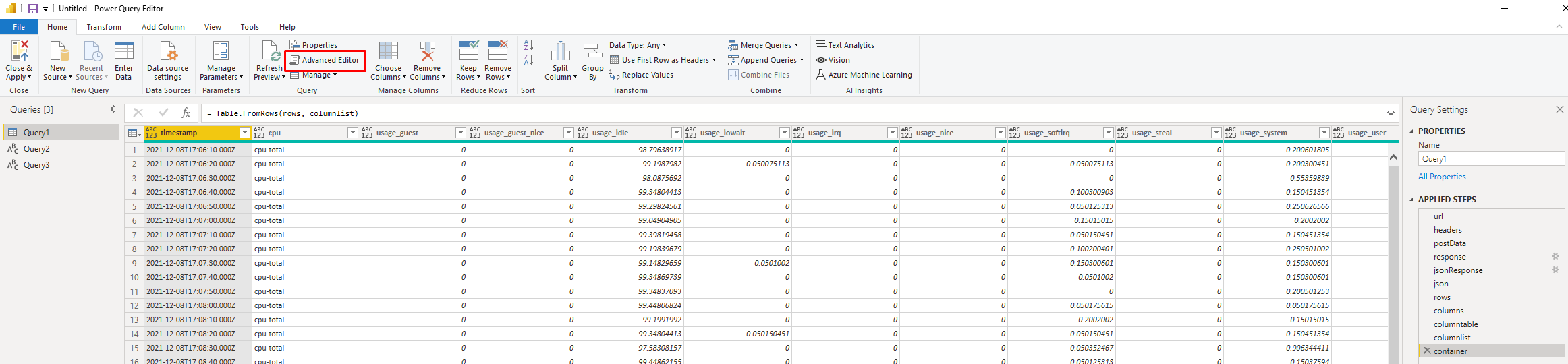
このエディタを使えば、何でもありのカスタムクエリを新規に作成することができます。ここで、GridDB Cloudインスタンスに直接クエリを発行することができます。以下がテンプレートです。
let
url = "{URL}/{clusterName}/dbs/{DB NAME}/sql",
headers = [#"Content-Type" = "application/json; charset=UTF-8", #"Authorization" = "{User/Password}"],
postData = Text.ToBinary("[{""type"":""sql-select"", ""stmt"":""{SQL STATEMENT}""}]"),
response = Web.Contents(
url,
[
Headers = headers,
Content = postData
]
),
jsonResponse = Json.Document(response),
json = jsonResponse{0},
rows = json[results],
columns = json[columns],
columntable = Table.FromRecords(columns),
columnlist = Table.ToList(Table.SelectColumns(columntable, "name")),
container = Table.FromRows(rows, columnlist)
in
containerこのようにすべての情報を記入すると、以下のようになります。
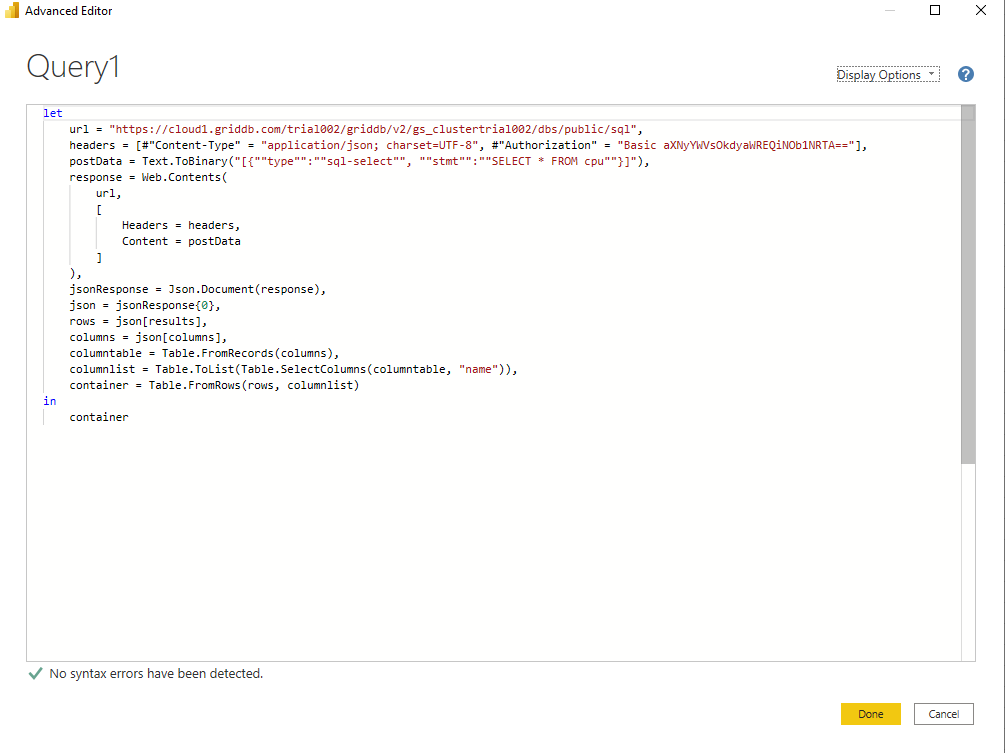
let
url = "<myurl>",
headers = [#"Content-Type" = "application/json; charset=UTF-8", #"Authorization" = "Basic aXNyYWVsOkdyaOb1NRTA=="],
postData = Text.ToBinary("[{""type"":""sql-select"", ""stmt"":""SELECT * FROM cpu""}]"),
response = Web.Contents(
url,
[
Headers = headers,
Content = postData
]
),
jsonResponse = Json.Document(response),
json = jsonResponse{0},
rows = json[results],
columns = json[columns],
columntable = Table.FromRecords(columns),
columnlist = Table.ToList(Table.SelectColumns(columntable, "name")),
container = Table.FromRows(rows, columnlist)
in
container</myurl>コンテナ cpu は、以前のブログ で説明した GridDB Telegraf 出力プラグインから受け取ったデータです。
このクエリを設定すると、選択したSQL文のデータがすべて取得されるはずです。確認できたら、「適用して閉じる」を選択してください。
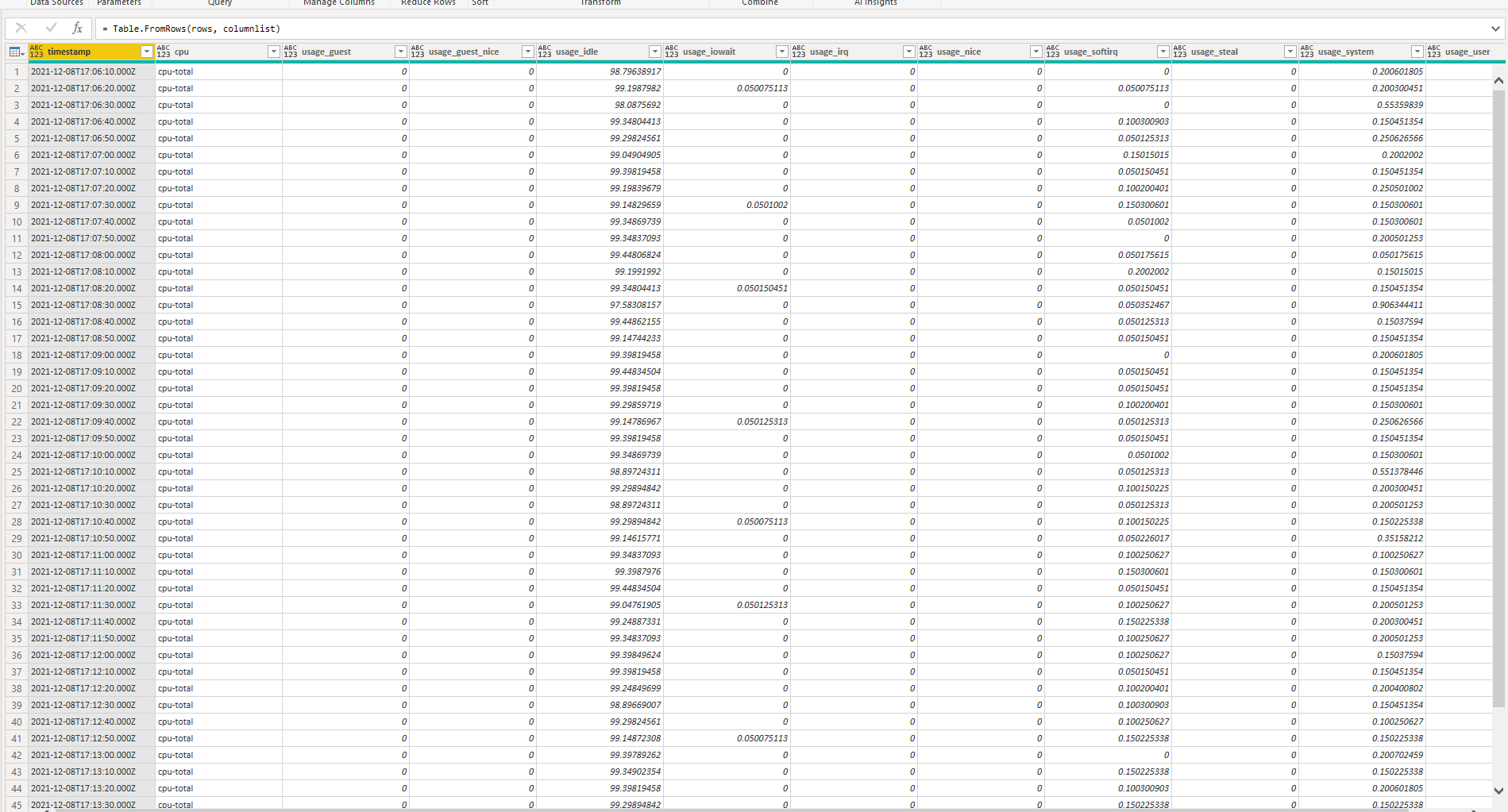
File Import (CSV)
ファイルのインポートを始めるには、まずGridDB CloudのダッシュボードからPower BIにインポートしたいコンテナをエクスポートします。
エクスポートされると、コンテナの内容の .csv ファイルを含むコンテナの zip をダウンロードすることができます。ここから、Windows Powershellを開いて使用します。
powershellで.csvファイルの場所・ディレクトリに移動し、次のコマンドを入力します。
$TARGET_CSV=Get-ChildItem <.csv file name inside directory>
次に、以下を実行します。
$CURRENT_PATH=(Convert-Path .)
$JSON_DATA=ConvertFrom-Json -InputObject (Get-Content -Path ((($TARGET_CSV).BaseName) + "_properties.json") -Raw)
$COL_NAME=$JSON_DATA.columnSet | ForEach-Object { $_.columnName }
$CSV=Import-Csv -Path $TARGET_CSV -Header $COL_NAME | Select-Object -Skip 4
$CSV | Export-Csv -Path ($CURRENT_PATH + "\Convert_" + ($TARGET_CSV.Name)) -Encoding Default -NoTypeInformation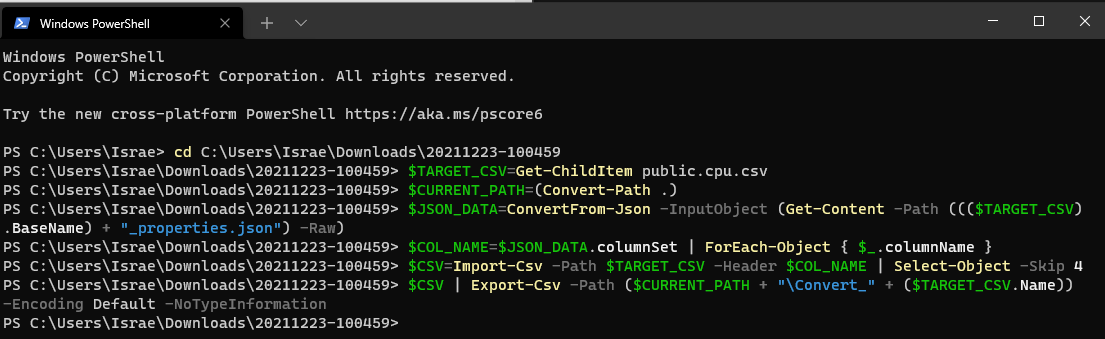
これらのコマンドは、作業ディレクトリ内に元の.csvファイルと同じファイル名で、ファイル名の先頭に Converted_ を付加したファイルを生成します。
Power BIにアクセスしてデータを取得し、TEXT/CSVを選択して、新しく作成した.csvファイルを指定します。
ODBC
ODBCとは何か?
Open Database Connectivity (ODBC) は、 “データベース管理システムにアクセスするための標準 API” です。今回のユースケースでは、Windows マシンと GridDB Cloud インスタンスをこの規格で接続し、そこから Power BI に接続します。
まず、GridDB Cloud を v-net ピアリングで接続する必要があります。この作業については、GridDB Cloud入門のブログで詳しく説明しています。
Windows Virtual MachinでODBCをセットアップする
Azure のリソースグループが GridDB クラウドインスタンスに正常に接続できることを確認したら、次のステップでは Power BI アプリケーションを実行するために使用する Windows VM をセットアップします。Windows VM のセットアップは簡単で、GridDB Cloud インスタンスとのピアリングが有効になっているリソースグループと仮想ネットが共有されていることを確認すればセットアップが完了です。
VMの中に入ったら、GridDB Cloudのサポートセクション(クエスチョンマークのアイコン)にあるソフトウェアパッケージをダウンロードすることができます。まず、GridDB ODBC コネクタをインストールします。これは非常に簡単なステップです。64-bit ODBC ディレクトリに移動し、管理者として GridStoreODBC_64bit_setup.bat を実行します。このスクリプトは、そのディレクトリから C:\Program Files\TOSHIBA\GridStore\bin にファイルをコピーします。
次に、システムプロパティアドバンスセクションに移動して、システム環境変数を編集します。ここにたどり着く簡単な方法は、”SystemPropertiesAdvanced.exe “を検索して、そのプログラムを実行することです。詳細設定タブにある環境変数ボタンを探し、PATHを編集してください。PATHに新しい行を作成して、新しくインストールしたファイルのディレクトリを直接指すようにします (C:\Program Files\TOSHIBA\GridStore\bin) 。
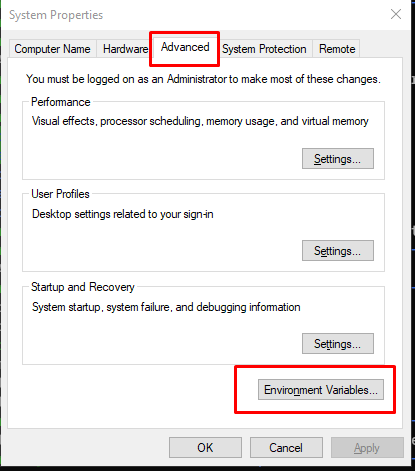
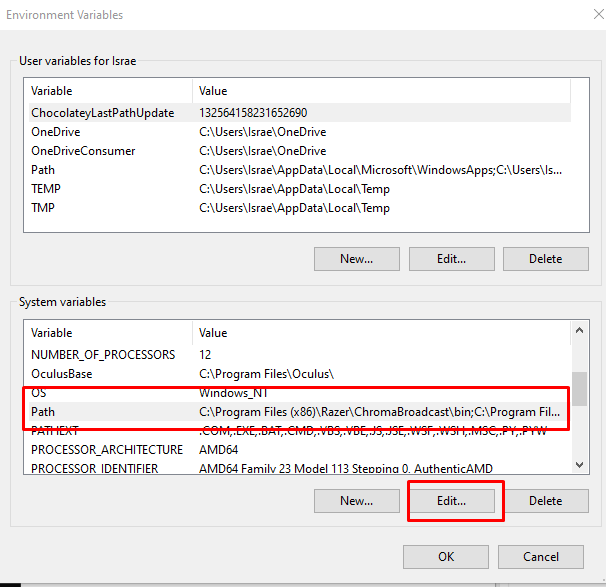
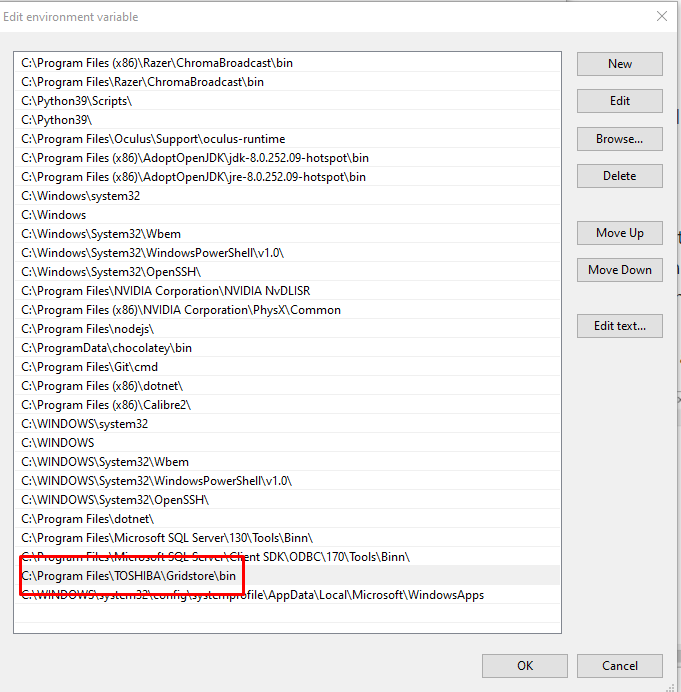
ODBCをデータソースとして登録する
まず最初に、ODBCをSystem DSNとして設定します。そのために、Windowsで “ODBC “を検索し、ODBC Data Source Administrator (64-bit) を実行します。しかし、オンプレミスゲートウェイを使用する場合は、64ビットアーキテクチャを使用する必要があります(詳しくは後述します)。
System DSN Tabを選択し、Add...ボタンをクリックします。
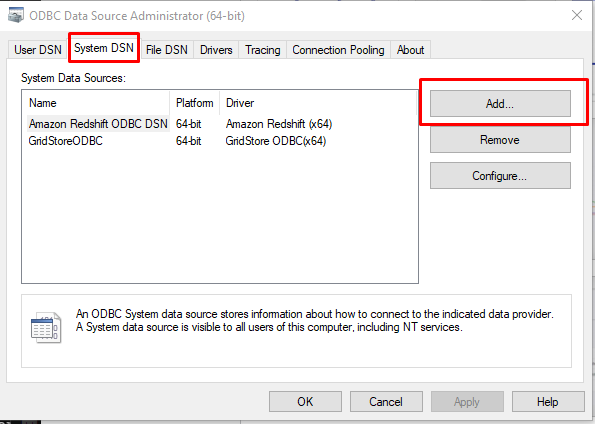
GridStore ODBCを選択し、認証情報を入力します。保存先は、GridDB Cloud Dashboardで直接確認することができます。
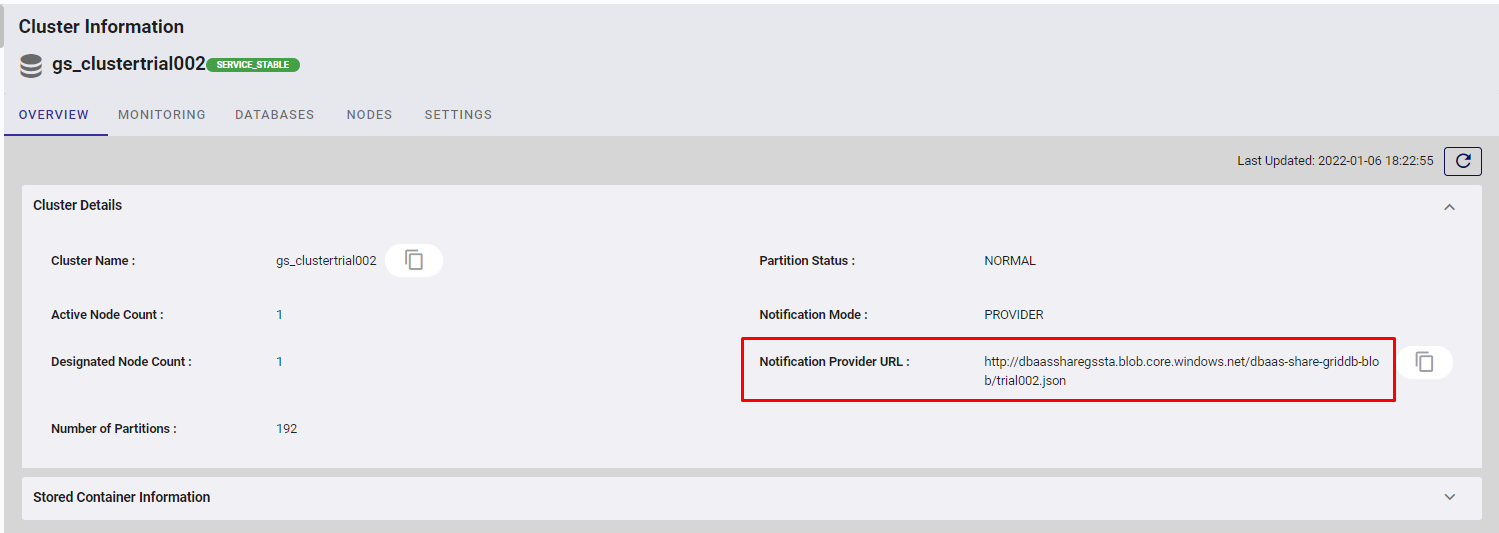
ここまで正しく設定できていれば、”Connected “のメッセージが表示されるはずです。
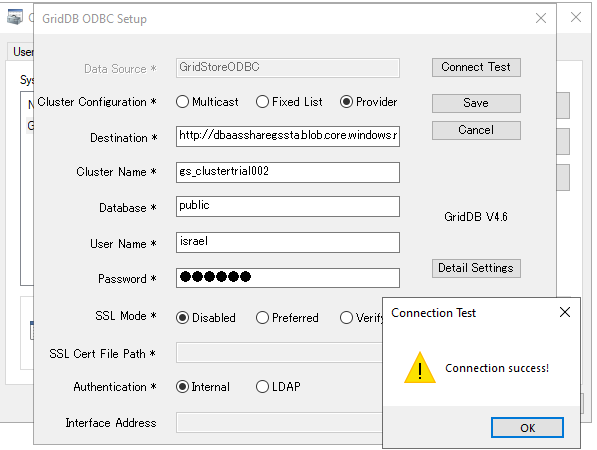
もし、ここで何らかの問題が発生した場合は、システム環境のPATHが更新されているかどうかを確認してください。それでもうまくいかない場合は、システム変数が実際に更新されていることを確認するために、システムの完全な再起動が必要となる可能性があります。
接続すると、Power BIアプリでODBCをデータソースとして使用することができます。そこで、アプリを開き、Get Data –> More –> ODBC を選択します。
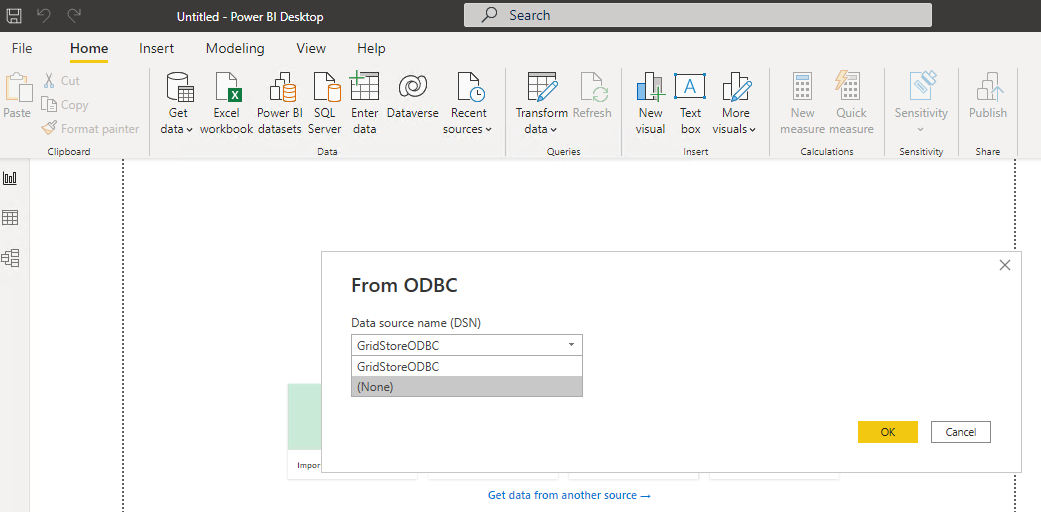
新しく作成したODBC GridDB Cloud接続がドロップダウン・リストに表示されているはずです。これを選択し、可視化したいコンテナを選択します。
On-Premise Data Gateway
On-Premise Data GatewayとPower BI サービスをインストールする
On-Premise data gatewayは、すでにODBCで確立した接続の上に構築されています。開始するには、 Microsoft’s On-Premise Docs Page からソフトウェアをダウンロードします。
始める前に、Power BI Serviceのアカウントにサインアップしておく必要があります。これにより、Webポータルを介してデータソースを共有することができるようになります。
さて、これで前提条件がすべて整ったので、さっそく始めましょう。まず、マシンにゲートウェイをインストールします。このステップは、.exe ファイルにあるインストール・ウィザードがプロセスを案内してくれるので、非常に簡単です。起動したら、Power BI アプリケーションに進みます。
Power BI サービスにデータセットを登録する
Power BIアプリ内で、右上のボタンからPower BIアカウントと同じアカウントにサインインします。ここで、ODBCデータソースを使用し、データセットをロードします。次に、Power BI ファイルを保存し、ホームタブから「公開」を選択します。「my workspace」を選択し、「Open filename.pbix」をクリックすると、ブラウザでPower BI サービスのポータルが起動します。
ポータル内で歯車のアイコン、「設定」をクリックし、「ゲートウェイの管理」に進みます。ここで新しいゲートウェイを作成できますが、まだデータソースを追加する必要はありません。
次に、歯車のアイコンをもう一度クリックして、今度は「設定」を選択し、「データセット」セクションに移動します。このセクションには、デスクトップ上のPower BIアプリケーションから保存・公開したデータセットが表示されます。Actionsセクションから、トグルボタンを展開し、データソースを表示し、Add to gatewayリンクを選択します。
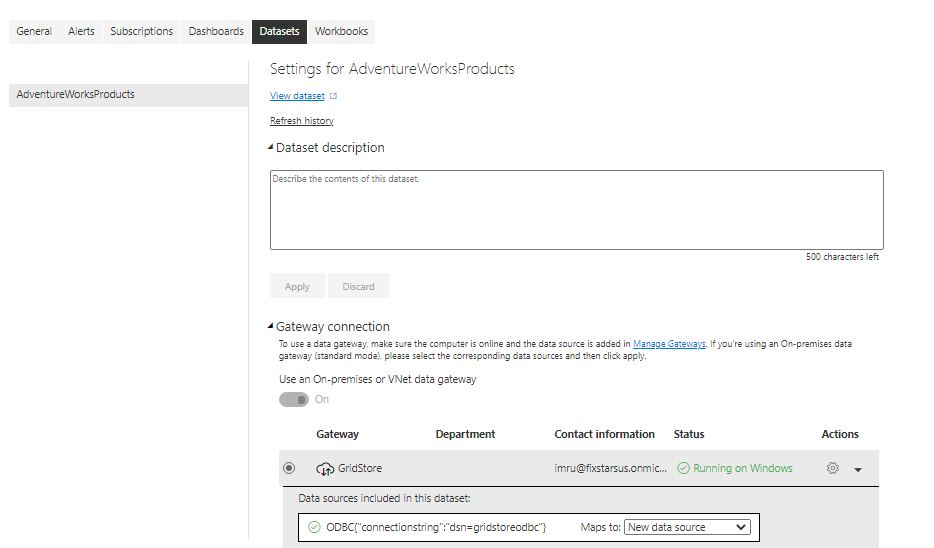
接続文字列(dsn=<ODBC Name>)や基本的な登録情報(GridDB Cloud User、Passwordなど)を入力します。
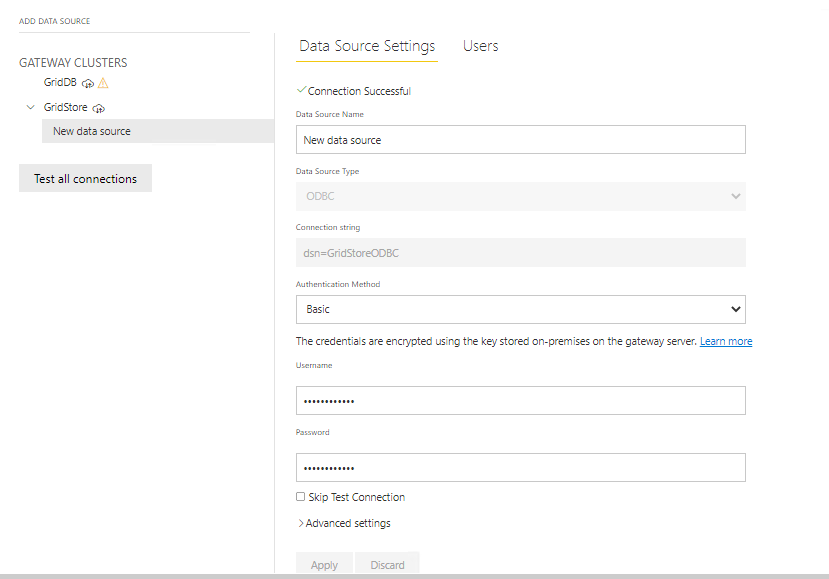
入力が完了すると、Power BIポータルでデータソースが使用できるようになります。
データを可視化する
これで、Power BIにデータを取り込み、アプリケーション上で直接データを可視化できるようになりました。
可視化を始める前に、データの形式を少し変更する必要があります。デフォルトでは、クエリによって集められたすべてのカラムは STRING 形式に設定されています。つまり、値を何らかの形で視覚化しようとすると、アプリケーションはその値を COUNT としてしか使用できないというおかしな動作が発生することになります。
これを修正するには、上部のホームタブにある「データの変換」ボタンをクリックします。そこから、各列名の横にある書式アイコンをクリックします。
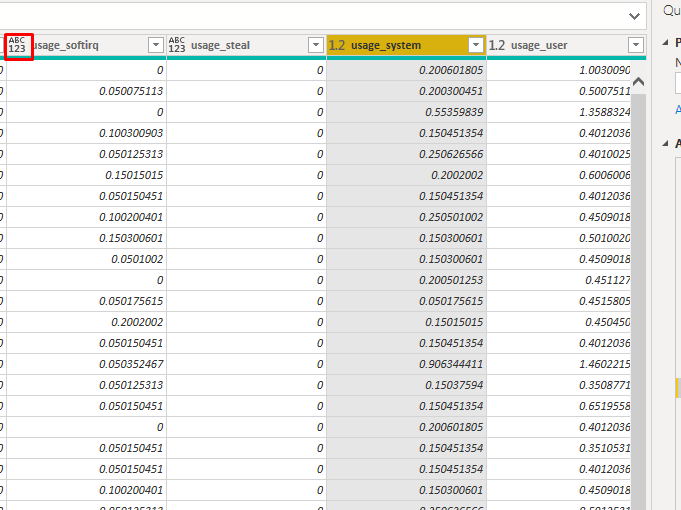
今回の例の場合、形式はDecimal Numberを選択しました。
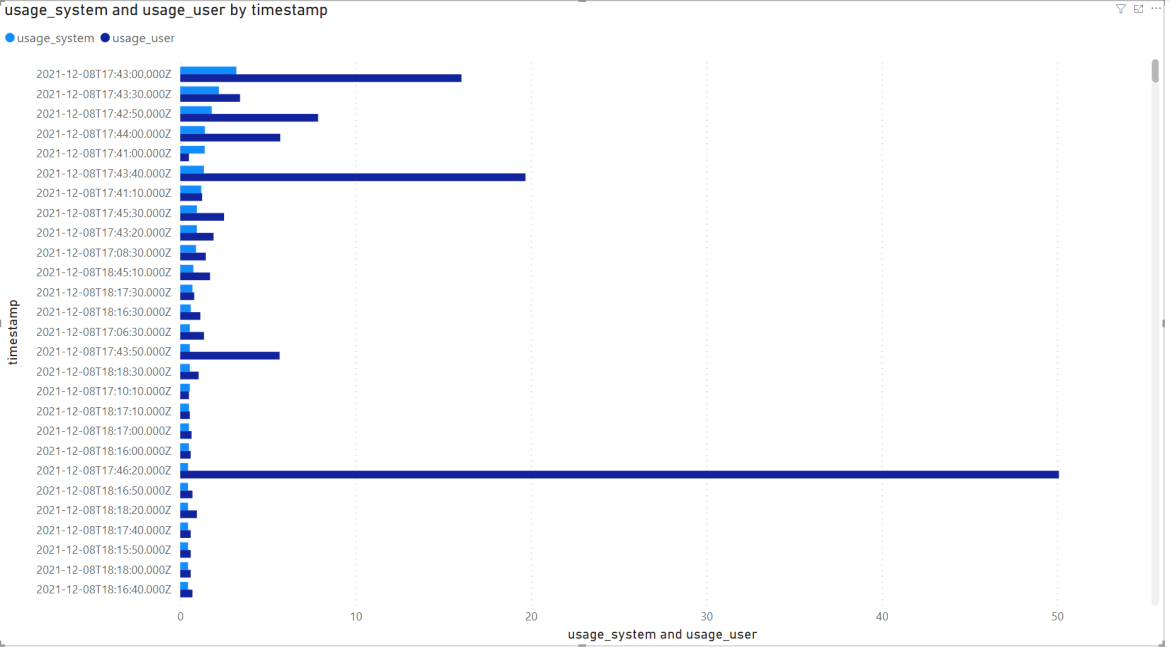
ここでデータを可視化してみましょう。今回は、軸をTimeStamp、値をUsage_systemとUsage_userに設定しました。このデータのクラスタ化された棒グラフがこちらです。
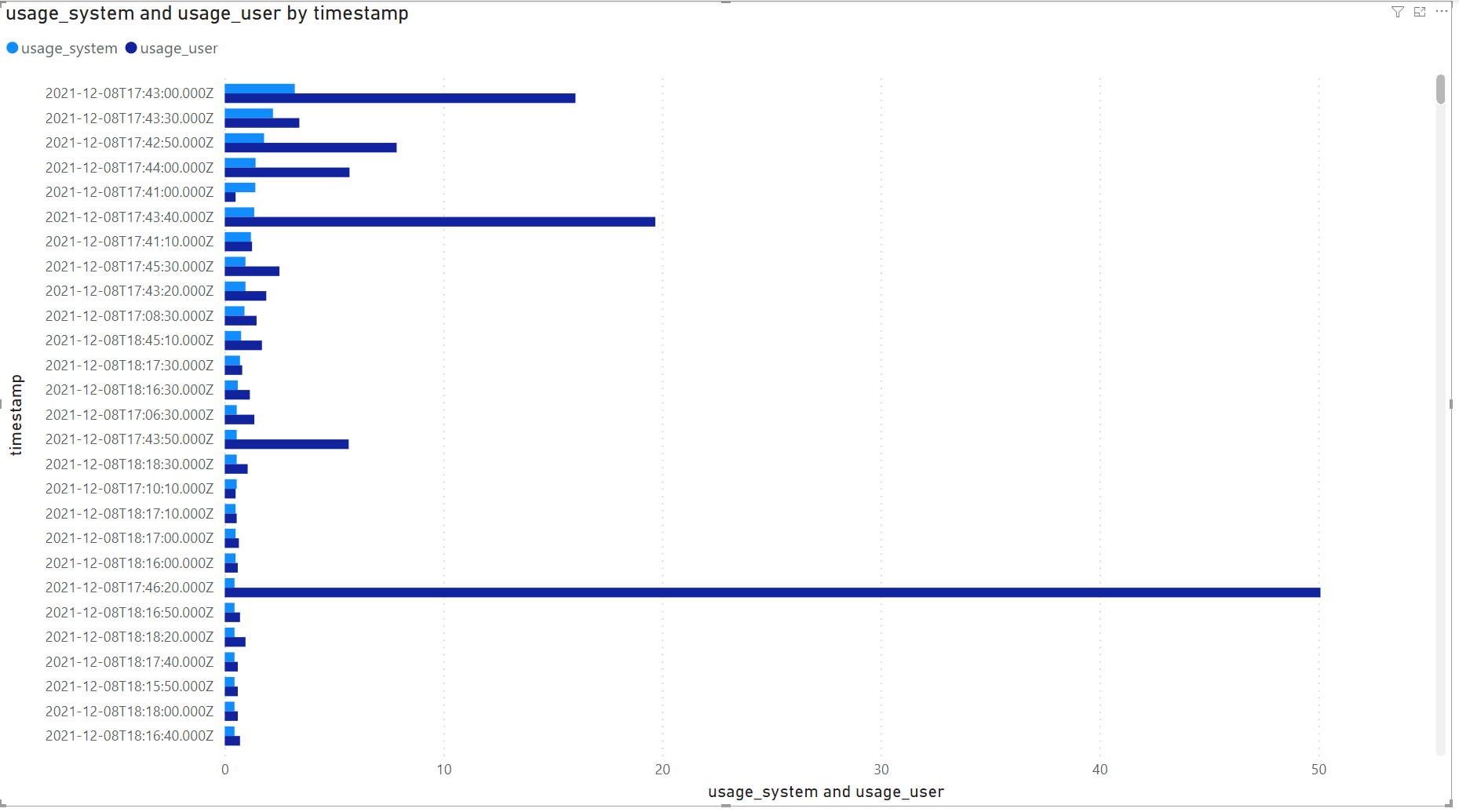
そして、以下が線グラフです。
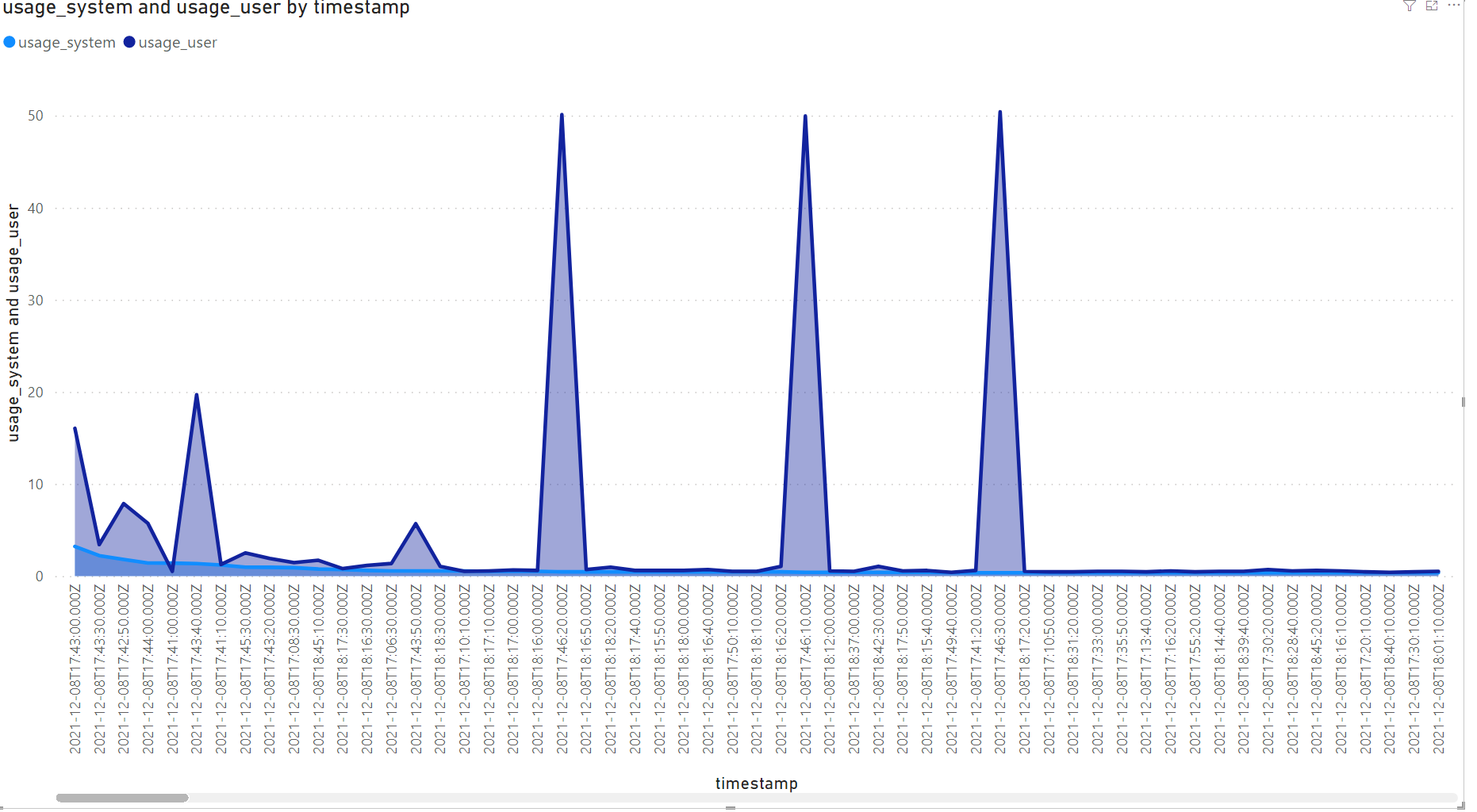
まとめ
このように、異種のデータソースを集約して見やすく可視化したい場合は、Power BIのカスタムクエリを使ってGridDB Cloudのデータを収集する方法が非常に便利であると言えます。GridDB Cloudのトライアルをご希望の方は、こちらからお申込みください。
https://www.global.toshiba/jp/products-solutions/ai-iot/griddb/product/griddb-cloud.html
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb