



昨年、私たちはGridDBとKafkaを使ってデータを取り込む方法についてのガイド・チュートリアルをリリースしました。このガイドでは、CSVからコンソール・プロデューサーにデータを入力し、Kafkaを経由して、GridDBのJDBC Sinkを経由して、GridDB自体にデータを取り込むプロセスを開発者向けに説明しました。
今回のブログでは、JDBC Kafka コネクタの新しいアップデートのため、逆の手順で進めていきます。つまり、GridDB JDBC Sourceを使用して、データベースであるGridDBからKafkaを経由して、コンシューマー(または他のKafka Sinkプラグイン)にデータを移動します。
このプロセスを実演するために、最新のチュートリアルSimulating IoT Data with Goで紹介した goスクリプトを使用します。このチュートリアルでは、IoTデータセットをシミュレート・真似するために、大量の生成・ランダムなデータを挿入するシンプルなスクリプトを作成するプロセスを説明しています(目的は、素早くて雑なIoTの概念実証を作成することです)。
基本的な流れは次のようになります。goスクリプトでGridDBデータベースにデータを書き込み、それをsourceコネクタで読み込み、Kafkaに投入し、最終的にコンソールに出力することができるようになります。 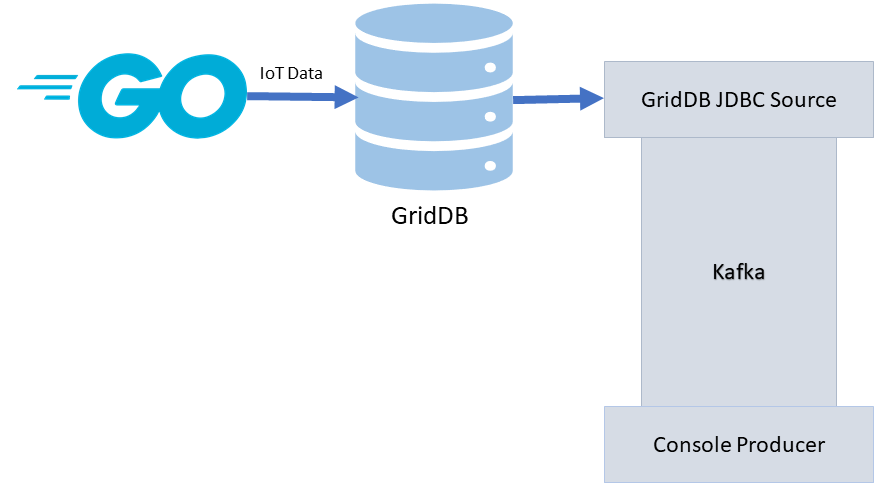
インストール
これを実行するための手順の大部分は、基本のチュートリアルに記載されています。基本的には、Kafkaのダウンロードとセットアップ、zookeeperサーバーの実行、そしてKafkaサーバーの実行が必要となります。そこから、Kafka-Connect-JDBC-GridDBコネクタを Git Repo から mvn package でビルドします。
.jarファイルをビルドしたら、kafka/libsディレクトリにcpします。また、 GridDB JDBC ドライバー .jar も同様にディレクトリに配置してください。ここからは、基本のチュートリアルの内容から進んで新しい領域の説明に入ります。
GridDBソースコネクタの設定
次に、GridDB シンクコネクタの設定ファイルを構成します。このファイルでは、Kafka サーバーが GridDB サーバーと通信するための認証情報を与えるためのパラメータと接続情報を定義します。GridDBをデフォルトでインストールしている場合は、この設定ファイルをそのまま使用することができます。
config/connect-jdbc.propertiesファイルに、次のように追加します。
bootstrap.servers=localhost:9092
name=griddb-sources
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
key.converter.schemas.enable=true
value.converter.schemas.enable=true
batch.size=1
mode=bulk
topic.prefix=gridstore-02-
table.whitelist="kafkaBlog"
connection.url=jdbc:gs://239.0.0.1:41999/defaultCluster/public
connection.user=admin
connection.password=admin
auto.create=true
transforms=TimestampConverter
transforms.TimestampConverter.type=org.apache.kafka.connect.transforms.TimestampConverter$Value
transforms.TimestampConverter.format=yyyy-MM-dd hh:mm:ss
transforms.TimestampConverter.field=datetime
transforms.TimestampConverter.target.type=Timestamp基本のチュートリアルとの主な違いは、コネクタクラスが変更されたことと、table.whitelistパラメータが追加されたことです。今回のデモでは、Kafkaトピック全体を構成する単一のGridDBコンテナを見てみましょう。
使い方
データソースとしてのGridDB
データの挿入
このブログでは、ランダムな値をGridDBデータベースに挿入するgo スクリプト・チュートリアルを使用します。チュートリアルのドキュメントでは、もう少し詳しく説明されていますが、基本的にこのスクリプトを使うと、開発者は、N個のセンサーを使ってX回にわたって「生成された」IoTデータをGridDBサーバーに挿入することができます。IoTベースのデータであるため、「センサー」からのすべてのデータはTime Series containerに挿入されます。
スクリプトを実行するには、
$ go run singlePut.go 24 5最初の数字は、シミュレーションを行う総時間数で、2番目の数字は、「出力」されるデータの増分です。この場合、スクリプトはcurrent timeから24時間後までのデータを、5分ごとに生成します。また、このスクリプトにはデフォルトで15個のセンサーが設定されており、それぞれの時点で同じコンテナに生成されます。
もし同様にするのであれば、singlePut.go スクリプトを変更して、コンテナ名を好きなものに更新してください。コンテナ名が jdbc.properties ファイルでホワイトリストに登録されているテーブルと一致することを確認してください。このブログでは、kafkaBlogを使用しています。
containerName := "kafkaBlog"
conInfo, err := griddb_go.CreateContainerInfo(map[string]interface{} {
"name": containerName,
"column_info_list":[][]interface{}{
{"timestamp", griddb_go.TYPE_TIMESTAMP},
{"id", griddb_go.TYPE_SHORT},
{"data", griddb_go.TYPE_FLOAT},
{"temperature", griddb_go.TYPE_FLOAT}},
"type": griddb_go.CONTAINER_TIME_SERIES,
"row_key": true})
if (err != nil) {
fmt.Println("Create containerInfo failed, err:", err)
panic("err CreateContainerInfo")
}
defer griddb_go.DeleteContainerInfo(conInfo)スクリプトの残りの部分では、いくつかのfor loopsを使って実際のデータ生成を行います。
for i := 0; i < int(arrLen); i++ {
innerLen := numSensors
fullData[0][i] = make([]interface{}, innerLen)
times[i] = make([]time.Time, innerLen)
id[i] = make([]int, innerLen)
data[i] = make([]float64, innerLen)
temp[i] = make([]float64, innerLen)
var rowList []interface{}
// iterates through each sensor (ie. will emit data N amount of times )
for j := 0; j < innerLen; j++ {
addedTime := i * minutes
timeToAdd := time.Minute * time.Duration(addedTime)
incTime := now.Add(timeToAdd)
times[i][j] = incTime
id[i][j] = j
data[i][j] = (r1.Float64() * 100) + numSensors // using the random seed
x := (r1.Float64() * 100) + 2
temp[i][j] = math.Floor(x*100) / 100 // temp should only go 2 decimal places
var row []interface{}
row = append(row, times[i][j])
row = append(row, id[i][j])
row = append(row, data[i][j])
row = append(row, temp[i][j])
rowList = append(rowList, row)
// fmt.Println("fullData: ", fullData[0][i][j])
}
fullData[0][i] = rowList
}ソースコネクタの使用
以上が完了すると、ソースコネクタを使ってテーブルを読み込み、データをKafkaに送り込むことができるようになります。では、ソースコネクタを実行してみましょう。
kafkaのディレクトリから、以下を実行します。
$ ./bin/connect-standalone.sh config/connect-standalone.properties config/connect-jdbc.propertiesこれでコネクタが起動し、ホワイトリストに登録されているテーブルの検索を開始します。見つからない場合は、次のようなメッセージが表示されます。
[2021-08-14 01:04:08,047] WARN No tasks will be run because no tables were found (io.confluent.connect.jdbc.JdbcSourceConnector:150)
しかし、そのデータが入力されると、コネクターの出力が表示されます。
[2021-08-14 01:05:18,149] INFO WorkerSourceTask{id=griddb-sources-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:487)
[2021-08-14 01:05:18,156] INFO Started JDBC source task (io.confluent.connect.jdbc.source.JdbcSourceTask:257)
[2021-08-14 01:05:18,156] INFO WorkerSourceTask{id=griddb-sources-0} Source task finished initialization and start (org.apache.kafka.connect.runtime.WorkerSourceTask:225)
[2021-08-14 01:05:18,157] INFO Begin using SQL query: SELECT * FROM "kafkaBlog" (io.confluent.connect.jdbc.source.TableQuerier:164)このメッセージで、データベースが接続され、Kafkaにストリームされていることが確認できました。
Kafkaのコンテンツを読む
これで動作するようになり、ターミナルでKafkaのメッセージを次のように見ることができるようになります。
$ bin/kafka-console-consumer.sh --topic gridstore-03-kafkaBlog --from-beginning --bootstrap-server localhost:9092コンテナの内容をKafkaのメッセージとして出力します。
{"schema":{"type":"struct","fields":[{"type":"int64","optional":false,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"timestamp"},{"type":"int32","optional":true,"field":"id"},{"type":"double","optional":true,"field":"data"},{"type":"double","optional":true,"field":"temperature"}],"optional":false,"name":"kafkaBlog"},"payload":{"timestamp":1628903073145,"id":4,"data":9.307559967041016,"temperature":38.70000076293945}}
{"schema":{"type":"struct","fields":[{"type":"int64","optional":false,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"timestamp"},{"type":"int32","optional":true,"field":"id"},{"type":"double","optional":true,"field":"data"},{"type":"double","optional":true,"field":"temperature"}],"optional":false,"name":"kafkaBlog"},"payload":{"timestamp":1628903373145,"id":3,"data":35.1313591003418,"temperature":79.73999786376953}}
Processed a total of 2 messagesまとめ
これで、GridDBデータベースをKafka Source Connectorとして使用できるようになりました。
次のステップとして、ぜひ他のSinkコネクタを試してみてください。例えば、Kafka HTTP Sink コネクタを使用すると、ペイロードをHTTPエンドポイントに送信することができます。これにより、データを任意のslackチャンネルに送信してアラートを出すなど、様々なことができるようになります。
Twitter コネクタもありますので、ぜひ使ってみてください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb