GridDB バックアップガイド
Revision: 1546
Table of Contents
1 はじめに
1.1 本書の目的と構成
本書では、GridDB のデータベースのデータ障害やノード障害に備えたバックアップの手順と復旧方法について説明します。
本書は、GridDBを用いた運用システム設計およびGridDBの運用管理を行う管理者の方を対象としています。
本書は、以下のような構成となっています。
-
バックアップ運用
- バックアップの種類とバックアップの利用方法について説明します。
-
障害からのリカバリ
- 障害の検出と障害からのリカバリ方法を説明します。
1.2 用語の説明
本書で用いる用語を説明します。
| 用語 | 意味 |
|---|---|
| パーティション | コンテナを配置するデータ管理の単位です。クラスタ間でのデータ配置の最小単位であり、ノード間の負荷バランスを調整するため(リバランス)や、障害発生時のデータ多重化(レプリカ)管理のためのデータ移動や複製の単位です。 |
| パーティショングループ | 複数のパーティションをまとめたグループであり、ディスクに永続化される際のファイルシステム上のデータ単位です。1つのパーティショングループに1つのチェックポイントファイルが対応します。パーティショングループは、ノード定義ファイルの並列度(/dataStore/concurrency)の数分作成されます。 |
| チェックポイントファイル | パーティショングループがディスクに書き込まれたファイルです。 ノード定義ファイルのサイクル(/checkpoint/checkpointInterval)でメモリ上の更新情報が反映されます。 |
| トランザクションログファイル | トランザクションの更新情報がログとして逐次保存されます。 |
| LSN(Log Sequence Number) | パーティションごとに割り当てられる、トランザクションでの更新時の更新ログシーケンス番号を示します。 クラスタ構成のマスタノードは、各ノードが保持している全パーティションのLSNのうちの最大数(MAXLSN)を保持しています。 |
| レプリカ | 複数のノードにパーティションを多重化配置することを指します。レプリカには更新されるマスタデータであるオーナと参照に利用されるバックアップがあります。 |
2 バックアップ運用
GridDBの障害に備えたバックアップ運用について説明します。
2.1 バックアップの種類
データベース障害やアプリケーションの誤動作によるデータ破壊に備えるために、定期的なバックアップの採取が必要です。バックアップ運用は、障害発生時のリカバリの要件(いつの時点にリカバリするか)、バックアップにかかる時間、バックアップのために用意できるディスクの容量に応じて、バックアップの種別やバックアップの間隔を決定します。リカバリ保障のサービスレベルからの要求やシステムのリソースに応じて対処方法を選択する必要があります。
GridDBでは、ノード単位のオンラインバックアップが可能です。これをGridDBクラスタを構成する全ノードに対して順次行うことで、サービスを継続しながら、クラスタ全体としてオンラインバックアップが行えます。 GridDBの提供するオンラインバックアップの種類には以下のものがあります。
| バックアップ種別 | バックアップの動作 | 復旧時点 |
|---|---|---|
| フルバックアップ | 現在利用中のクラスタデータベースをノード定義ファイルで指定したバックアップディレクトリにノード単位にオンラインでバックアップする。 | フルバックアップ採取時点 |
| 差分・増分バックアップ | 現在利用中のクラスタデータベースをノード定義ファイルで指定したバックアップディレクトリにノード単位にオンラインでバックアップし、以降のバックアップでは、バックアップ後の更新ブロックの差分増分のみをバックアップする。 | 差分増分バックアップ採取時点 |
| 自動ログバックアップ | 現在利用中のクラスタデータベースをノード定義ファイルで指定したバックアップディレクトリにノード単位にオンラインでバックアップするとともに、トランザクションログファイルの書き込みと同じタイミングでトランザクションログも自動で採取します。トランザクションログファイルの書き込みタイミングは、ノード定義ファイルの/dataStore/logWriteModeの値に従います。 | 最新トランザクションの更新時点 |
利用するバックアップの種類に応じて復旧できる時点が異なります。
GridDBの提供する各バックアップの動作と、利用を推奨するシステムについて以下に示します
-
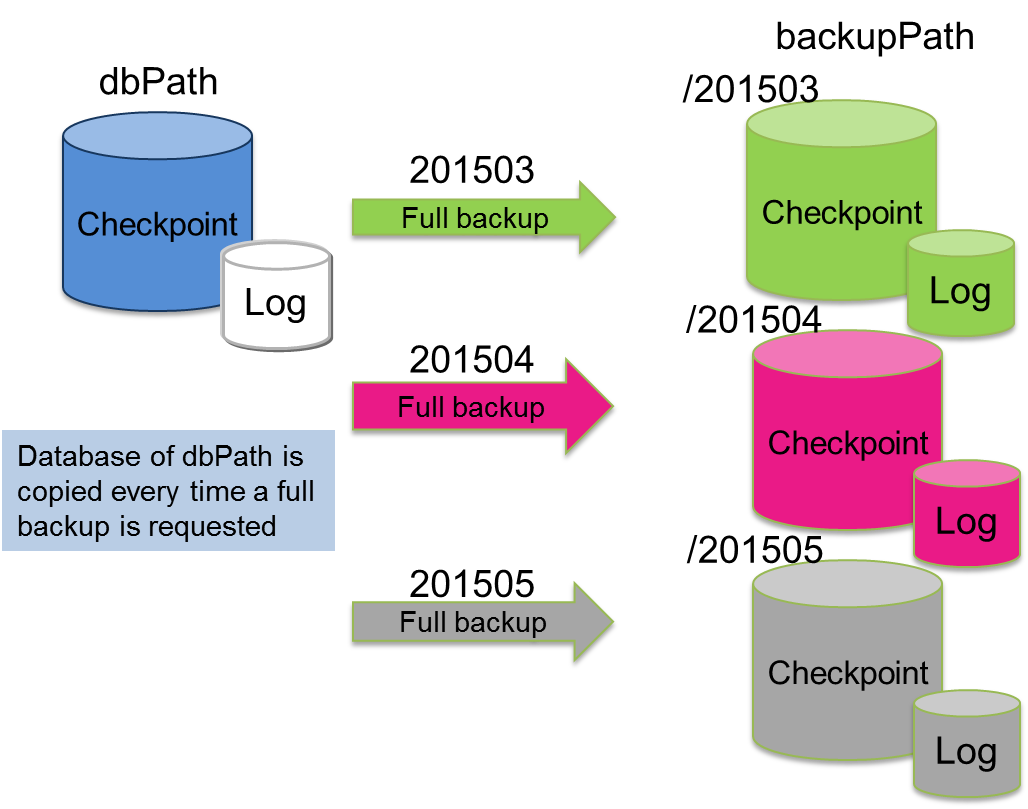
フルバックアップ
参照系のシステムでは、データ更新が行われる夜間バッチなどの後にフルバックアップを採取します。フルバックアップはすべてのデータベースファイルのデータをコピーするため、時間がかかります。また、バックアップ採取先のデータ容量としてデータベースファイルと同じ容量が必要です。
バックアップを何世代保持するのかに応じて、実データベースサイズの掛け算でバックアップディスク容量が必要です。
フルバックアップ
-
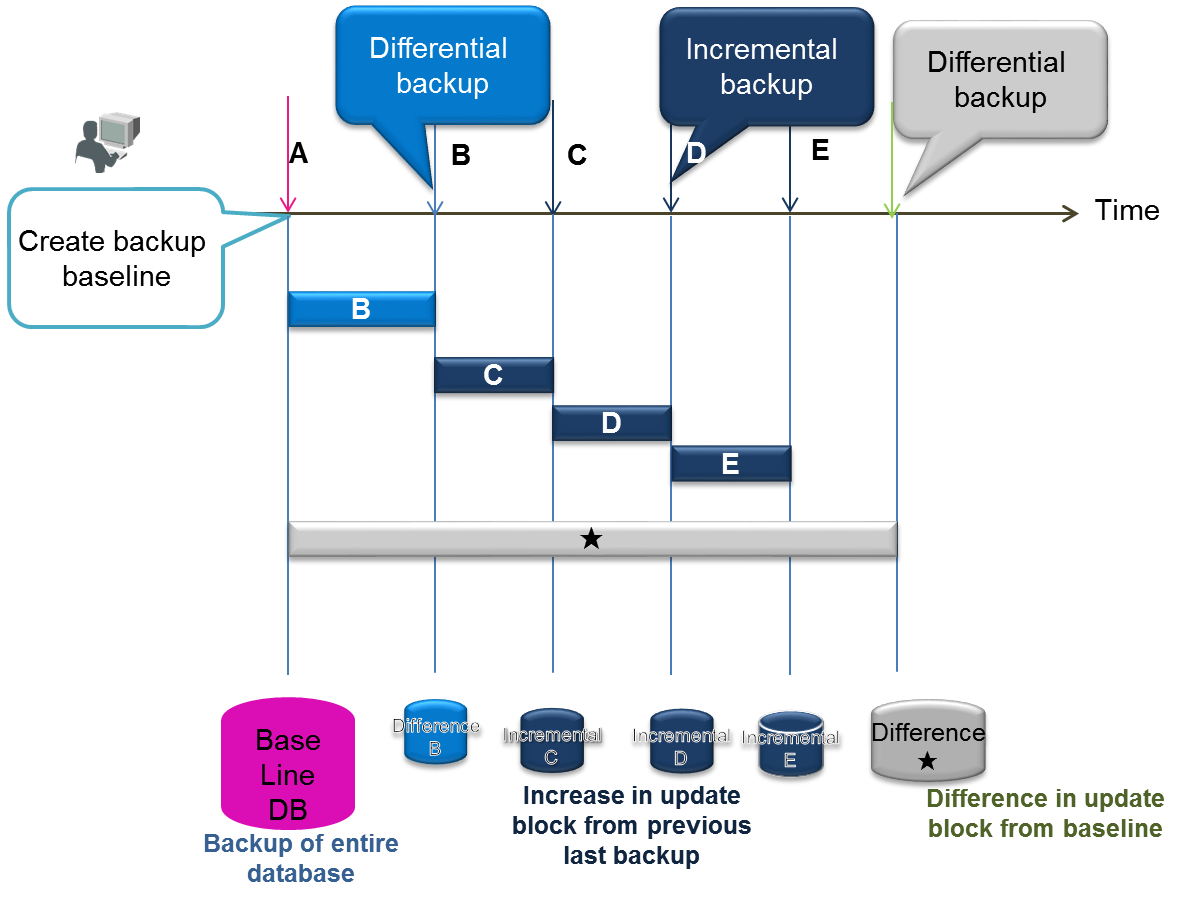
差分・増分バックアップ
フルバックアップで全データベースのバックアップを採取後、更新されたデータの差分のみをバックアップできます。バックアップを短時間に行いたいシステムで、夜間のバッチ運用でバックアップを自動的に、月1回のフルバックアップ(ベースライン作成)、1週間に1回の差分(since)バックアップ、毎日増分バックアップ(incremental)などのように計画的な運用を行うシステムに向いています。
差分・増分バックアップ
増分バックアップは、更新データのみを用いたバックアップのため、フルバックアップや差分バックアップと比較して高速にバックアップが行えます。しかし障害発生時のリカバリではフルバックアップのデータに対して更新ブロックをロールフォワードする必要があるため、リカバリに時間がかかります。定期的なBaselineやSince指定での差分バックアップが必要です。
-
自動ログバックアップ
自動ログバックアップ指定でのフルバックアップ(ベースライン作成)採取以降、更新ログがバックアップディレクトリに収集されます。自動的にトランザクションログが採取されるため、バックアップ操作は不要です。運用を省力化する場合やバックアップでシステムに負荷を与えたくない場合に指定します。ただし、定期的にBaselineを更新しない場合、障害発生時のリカバリで利用するトランザクションログファイルが増え、リカバリに時間がかかることになります。差分・増分バックアップでは、同じブロックのデータが更新された場合に1つのデータとしてバックアップされますが、自動ログバックアップでは更新の都度のログが採取されるため、障害回復時のリカバリには、差分・増分よりも時間がかかります。
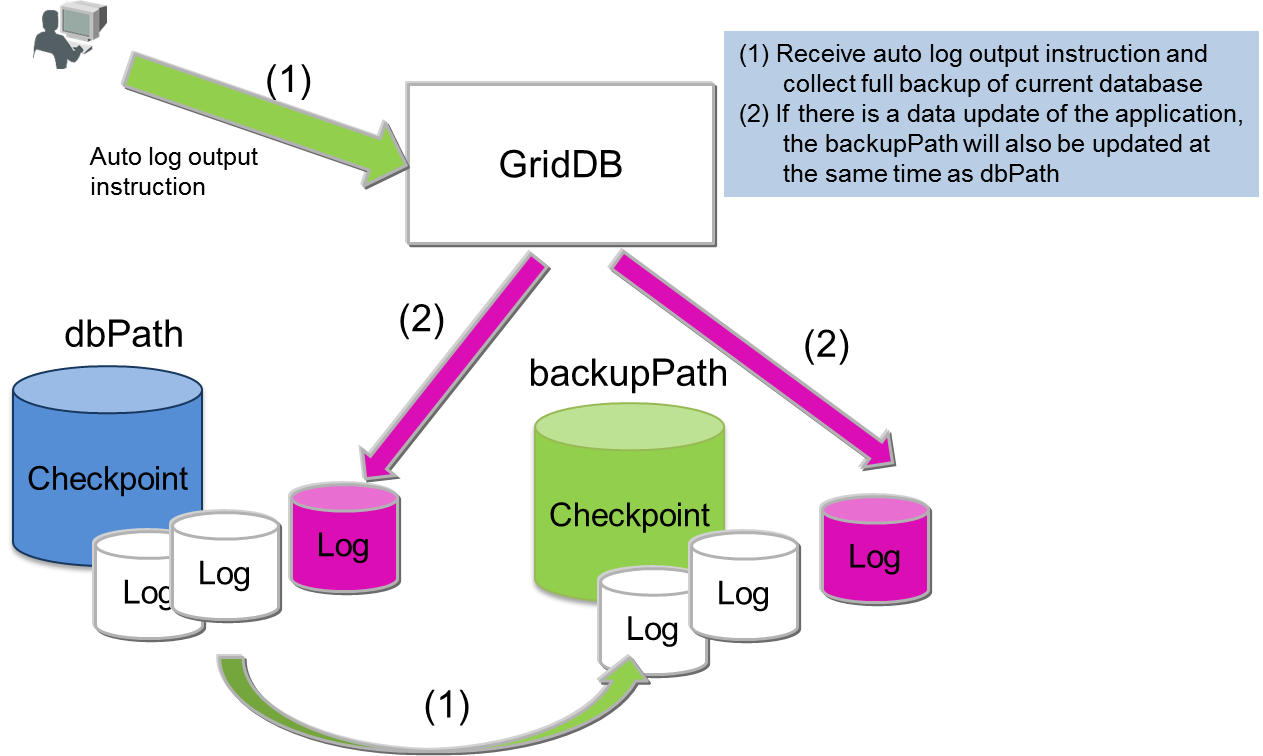
自動ログバックアップ
【注意】
・差分・増分バックアップ、自動ログバックアップでも障害発生時のリカバリ時間を短縮するにはベースラインとなるフルバックアップを定期的に採取する必要があります。バックアップの種別は、コマンドのオプションで指定します。
なお、オフラインバックアップを行うには、クラスタを構成する全ノードを停止し、各ノードのデータベースファイルの配置ディレクトリ(gs_node.jsonのdataStore/dbPathで示すディレクトリ)下のデータをバックアップしてください。クラスタデータベースに関連するデータはすべてdbPathディレクトリ下に配置されています。
2.2 バックアップ関連パラメータの確認
バックアップ先は、ノード定義ファイルの /dataStore/backupPathで指定します。ディスクの物理障害を考慮して、バックアップ先とデータベースファイル(/dataStore/dbPath)は必ず異なる物理ディスクに配置するように設定してください。
トランザクションのログ永続化には2つのモードがあります。デフォルト値はNORMALです。
- NORMAL チェックポイントにより、不要になったトランザクションログファイルは削除されます。
- KEEP_ALL_LOGS 全てのトランザクションログファイルを残します。
KEEP_ALL_LOGSは、他社のバックアップソフトウェアとの連携等でログファイルの削除を指示する運用を行うなど特別な用途の場合のみ指定しますが、通常は利用しません。
ノード定義ファイルの指定例を以下に示します。
$ cat /var/lib/gridstore/conf/gs_node.json # 設定の確認例
{
"dataStore":{
"dbPath":"/var/lib/gridstore/data",
"backupPath":"/mnt/gridstore/backup", # バックアップディレクトリ
"storeMemoryLimit":"1024",
"concurrency":2,
"logWriteMode":1,
"persistencyMode":"NORMAL" #永続化モード
:
:
}
2.3 バックアップの注意点
バックアップ実行時の注意点を以下にまとめます。
- バックアップでは、データベースファイルの定期的なバックアップに加え、$GS_HOME/confディレクトリ(デフォルトでは、/var/lib/gridstore/conf)にあるノード定義ファイル(gs_node.json)、クラスタ定義ファイル(gs_cluster.json)、ユーザ定義ファイル(password)のバックアップをOSのコマンドを用いて採取しておいてください。定義ファイルのバックアップは、設定変更やユーザ登録・変更した場合には、必ず実施してください。
-
クラスタ構成変更やシステムの負荷に応じてパーティションは自動配置されます(リバランス)。パーティションの配置が変更となった後に差分ログバックアップを指定すると、『パーティション状態変更によりログバックアップできない』とエラーが通知されます。この場合、必ずクラスタを構成する全ノードのバックアップ(baseline)を採取してください。パーティションの再配置(リバランス)は以下のようなクラスタ構成変更でも発生します。
- ノード追加によるクラスタ構成台数の増加
- ノードの切り離しによるクラスタ構成台数の縮小
- バックアップデータを用いてリストアすると、バックアップ完了直前の状態に復元されます。
- バックアップ中にバックアップ先のディスクで障害が発生した場合、採取されたバックアップは不完全なため、これを用いてのリストアはできません。
- オンラインバックアップを実行すると、複数のコンテナ間で関連した更新をしている場合にデータの静止点がとれません。クラスタ全体として論理的に不整合な状態でバックアップが作成される可能性があります。必要に応じてトランザクションの実行を停止/禁止し、静止状態でバックアップを実行するようにしてください。
- GridDBでは、障害発生した場合には自動的にデータ再配置が行われます。そのため、バックアップ中に障害が発生すると、必要なデータがバックアップされなくなる可能性があります。障害発生時には、再度、1台目のノードからバックアップを取り直してください。
2.4 バックアップの実行
フルバックアップ、差分・増分バックアップ、自動ログバックアップの各々の利用方法を説明します。
どのバックアップでも、バックアップ名(BACKUPNAME)という名前を指定してバックアップを実行します。バックアップで作成されるデータは、ノード定義ファイルのbackupPathで指定したディレクトリ下にBACKUPNAMEでディレクトリが作成され、配置されます。
BACKUPNAMEは、12文字以内の英数字で指定できます。
2.5 フルバックアップ
障害発生時、フルバックアップの採取完了時点までリカバリできます。フルバックアップをクラスタを構成するすべてのノードに対して実施します。バックアップデータはコマンドのBACKUPNAMEで示すディレクトリに配置されます。採取したバックアップデータをわかりやすく管理するためにBACKUPNAMEに日付を指定する運用をお勧めします。
以下のコマンドをクラスタ内の全ノードに対して実行します。
$ gs_backup -u admin/admin 20141025
この例では、
- バックアップディレクトリ下に『20141025』というディレクトリが作成され、
- チェックポイントファイル(gs_cp_n_p.dat)、トランザクションログファイル(gs_log_n_m.log)、バックアップ情報ファイル(gs_backup_info.json,gs_backup_info_digest.json)さらにLSN情報ファイルがバックアップディレクトリに作成されます。
チェックポイントファイルとトランザクションログファイルは、ノード定義ファイルの並列度(/dataStore/concurrency)の数分作成されます。
$ cd /mnt/gridstore/backup $ ls -l 20141025 -bash-4.1$ ls -l 20141025 合計 13502036 -rw-r--r-- 1 gsadm gridstore 731 10月 25 06:39 2015 gs_backup_info.json -rw-r--r-- 1 gsadm gridstore 82 10月 25 06:39 2015 gs_backup_info_digest.json -rw-r--r-- 1 gsadm gridstore 6759120896 10月 25 06:37 2015 gs_cp_0_1.dat -rw-r--r-- 1 gsadm gridstore 7064846336 10月 25 06:38 2015 gs_cp_1_1.dat -rw-r--r-- 1 gsadm gridstore 1048576 10月 25 06:38 2015 gs_log_0_161.log -rw-r--r-- 1 gsadm gridstore 1048576 10月 25 06:39 2015 gs_log_1_161.log -rw-r--r-- 1 gsadm gridstore 706 10月 25 06:39 2015 gs_lsn_info.json
バックアップコマンドは、バックアップの指示をサーバに通知するだけで処理の完了は待ち合わせません。
バックアップ処理の完了は、gs_statコマンドのステータスで確認してください。
$ gs_backup -u admin/admin 20141025 $ gs_stat -u admin/admin --type backup BackupStatus: Processing
-
バックアップ状態(BackupStatus)は、以下のいずれかになります。
- Processing : 実行中
- - : 完了もしくは未稼働
バックアップが正しく採取できたか否かは以下のコマンドのステータスで確認できます。
$ gs_backuplist -u admin/admin BackupName Status StartTime EndTime ------------------------------------------------------------------------ 20141025NO2 P 2014-10-25T06:37:10+0900 - 20141025 NG 2014-10-25T02:13:34+0900 - 20140925 OK 2014-09-25T05:30:02+0900 2014-09-25T05:59:03+0900 20140825 OK 2014-08-25T04:35:02+0900 2014-08-25T04:55:03+0900
バックアップリストのStatusの記号は以下を示します。
- P :バックアップ実行中
- NG : バックアップ実行中にエラーが発生し、バックアップデータが異常
- OK : 正常にバックアップが採取されている
2.6 差分・増分ブロックバックアップ
障害発生時、ベースライン(基準点)となるフルバックアップとベースライン以降の差分・増分バックアップを用いて、最後の差分・増分バックアップ採取時点まで復旧できます。差分・増分バックアップのベースラインとしてフルバックアップを取得し、以降差分・増分バックアップを指定します。
データの更新容量とリカバリにかかる時間のサービス目標に応じてバックアップの採取間隔は検討する必要がありますが、以下を目安として運用してください。
- ベースラインのフルバックアップ(baseline) : 一か月毎に実行
- ベースライン以降の更新ブロックの差分バックアップ(since) : 一週間毎に実行
- ベースラインや差分バックアップ以降の更新ブロックの増分バックアップ(incremental) : 毎日実行
フルバックアップのベースライン作成は以下で指定します。
$ gs_backup -u admin/admin --mode baseline 201504 $ gs_stat -u admin/admin --type backup BackupStatus: Processing(Baseline)
バックアップのベースラインとして、データディレクトリにあるデータベースファイルが、バックアップディレクトリ下にコピーされます。
ベースライン作成後の定期的な差分・増分ブロックのバックアップ(ベースラインのフルバックアップ以降に更新されたデータブロックのバックアップ)は、バックアップコマンドのモードとしてincrementalやsinceを指定します。BACKUPNAMEには、ベースライン作成時のBACKUPNAMEと同じ値を指定します。
***** 増分バックアップの場合 $ gs_backup -u admin/admin --mode incremental 201504 $ gs_stat -u admin/admin --type backup BackupStatus: Processing(Incremental) ***** 差分バックアップの場合 $ gs_backup -u admin/admin --mode since 201504 $ gs_stat -u admin/admin --type backup BackupStatus: Processing(Since)
バックアップが正しく採取できたか否かは以下のコマンドで確認できます。差分・増分バックアップは、複数のバックアップで1つのリカバリ単位となるため、BACKUPNAMEの一覧では1つとして扱われます。したがってステータスの詳細を見るには、バックアップ名を指定して詳細を確認します。
差分・増分バックアップであるというこことはBACKUPNAMEの先頭に"*":アスタリスクがついていることで確認できます。差分・増分のバックアップのステータスは常に"--"です。
差分・増分バックアップのステータスは、gs_backuplistコマンドの引数にBACKUPNAMEを指定することでステータスが確認できます。
***** BACKUPNAMEの一覧を表示します $ gs_backuplist -u admin/admin BackupName Status StartTime EndTime ------------------------------------------------------------------------ *201504 -- 2015-04-01T05:20:00+0900 2015-04-24T06:10:55+0900 *201503 -- 2015-03-01T05:20:00+0900 2015-04-24T06:05:32+0900 : 20141025NO2 OK 2014-10-25T06:37:10+0900 2014-10-25T06:37:10+0900 ***** 個別のBACKUPNAMEを指定し、詳細情報を表示します $ gs_backuplist -u admin/admin 201504 BackupName : 201504 BackupData Status StartTime EndTime -------------------------------------------------------------------------------- 201504_lv0 OK 2015-04-01T05:20:00+0900 2015-04-01T06:10:55+0900 201504_lv1_000_001 OK 2015-04-02T05:20:00+0900 2015-04-01T05:20:52+0900 201504_lv1_000_002 OK 2015-04-03T05:20:00+0900 2015-04-01T05:20:25+0900 201504_lv1_000_003 OK 2015-04-04T05:20:00+0900 2015-04-01T05:20:33+0900 201504_lv1_000_004 OK 2015-04-05T05:20:00+0900 2015-04-01T05:21:15+0900 201504_lv1_000_005 OK 2015-04-06T05:20:00+0900 2015-04-01T05:21:05+0900 201504_lv1_001_000 OK 2015-04-07T05:20:00+0900 2015-04-01T05:22:11+0900 201504_lv1_001_001 OK 2015-04-07T05:20:00+0900 2015-04-01T05:20:55+0900
差分・増分のバックアップデータは、バックアップディレクトリに以下の規則でディレクトリが作成され、データが配置されます。
- BACKUPNAME_lv0 : 差分・増分バックアップのベースラインのバックアップデータが配置されます。lv0固定です。
-
BACKUPNAME_lv1_NNN_MMM : 差分・増分バックアップの差分(Since)と増分(Incremental)のバックアップデータが配置されます。
- NNNは、差分バックアップ時に数字がカウントアップされます。
- MMMは、差分バックアップ時に000にクリアされ、増分バックアップ時に数字がカウントアップされます。
バックアップリストのStatusの記号は以下を示します。
- P :バックアップ実行中
- NG : バックアップ実行中にエラーが発生し、バックアップデータが異常
- OK : 正常にバックアップが採取されている
差分・増分バックアップでは、BackupDataで示すディレクトリ下に、gs_log_n_m_incremental.logという名前で更新ブロックのログが出力されます。
差分・増分バックアップはフルバックアップと比較してバックアップ時間を削減できます。しかし障害発生時のリカバリにはフルバックアップのデータに更新ブロックをロールフォワードするため、リカバリには時間がかかります。定期的なベースライン取得やSince指定によるベースラインからの差分バックアップを実施してください。
2.7 自動ログバックアップ
GridDBが自動的にトランザクションログをバックアップディレクトリに出力します。従って、常に最新の状態にリカバリすることができます。自動的なバックアップ操作のため、『システムの利用時間の低い時間にあらかじめスケジューリングしてバックアップ処理をしたい』といったシステムの運用形態に応じた計画的なバックアップはできません。また、自動ログバックアップにより、通常運用中にも多少のシステム負荷が発生します。従って、システムのリソースに余裕がある場合にのみ本指定を用いることをお勧めします。
自動ログバックアップを利用するには次のように指定します。
$ gs_backup -u admin/admin --mode auto 201411252100 $ gs_stat -u admin/admin --type backup
コマンドを実行するとBACKUPNAMEで示すディレクトリにバックアップを取得します。
-
自動ログバックアップでは、バックアップ中のエラーに対する動作設定が、オプションmodeで指定できます。
- auto :バックアップエラー時、ノードはABNORMALとなり停止する。
- auto_nostop :バックアップエラーでバックアップは不完全な状態となるが、ノードは運用を継続する。
この例では、
- バックアップディレクトリ下に『201411252100』というディレクトリが作成されます。
- フルバックアップと同様にチェックポイントファイル(gs_cp_n_p.dat)、トランザクションログファイル(gs_log_n_m.log)、バックアップ情報ファイル(gs_backup_info.json,gs_backup_info_digest.json)さらにLSN情報ファイルがバックアップディレクトリに作成されます。チェックポイントファイルとトランザクションログファイルは、ノード定義ファイルの並列度(/dataStore/concurrency)の数分作成されます。
- 『201411252100』ディレクトリ下にトランザクションの実行完了とともにトランザクションログファイル(gs_log_n_m.log)が作成されます。
自動ログバックアップで運用した場合、障害発生時のリカバリは、2)のフルバックアックデータに対して、3)のトランザクションログファイル(gs_log_n_m.log)をロールフォワードします。従ってリカバリに利用するログファイルが多数になるとリカバリ時間が増大しますので、定期的に、--mode autoを指定してフルバックアップを採取してください。
2.8 バックアップ動作の確認
現在実行しているバックアップのモードや実行状態の詳細はgs_statコマンドで取得できる情報でも確認できます。
$ gs_stat -u admin/admin
"checkpoint": {
"archiveLog": 0,
"backupOperation": 3,
"duplicateLog": 0,
"endTime": 0,
"mode": "INCREMENTAL_BACKUP_LEVEL_0",
"normalCheckpointOperation": 139,
"pendingPartition": 1,
"requestedCheckpointOperation": 0,
"startTime": 1429756253260
},
:
:
gs_statで出力されるバックアップ関連の各パラメータの意味は以下です。
- archiveLog : 現在のバージョンでは利用していません。互換性のための項目です。
- backupOperation :システム起動後のバックアップ実行回数。
-
duplicateLog : 自動ログバックアップが行われ、ログの2重出力が行われているか否かを示します。
- 0:自動ログバックアップoff
- 1:自動ログバックアップon
- endtime :バックアップやチェックポイント実行中は、"0"です。処理が完了すると時刻が設定されます。
-
mode :バックアップやチェックポイントの処理名が表示されます。実行中もしくは最後に実行されたバックアップの処理名が表示されます。
- BACKUP : フルバックアップや自動ログバックアップでのフルバックアップの実行
- INCREMENTAL_BACKUP_LEVEL_0: 差分・増分バックアップのベースライン作成
- INCREMENTAL_BACKUP_LEVEL_1_CUMULATIVE : ベースラインからの差分バックアップ
- INCREMENTAL_BACKUP_LEVEL_1_DIFFERENTIAL : 前回のバックアップからの増分バックアップ
2.9 コンテナ情報の採取
データベース障害発生時には、どのコンテナがリカバリ対象なのかを把握してコンテナの使用者に連絡するなどの手立てが必要です。リカバリ対象のコンテナを検出するには、定期的に以下の情報を採取している必要があります。
-
パーティションに配置されているコンテナ一覧
- コンテナはアプリケーションシステムの仕様に応じて、動的に作成されパーティションに配置されるため、gs_shコマンドで定期的にコンテナ一覧とパーティション配置の一覧を出力しておく必要があります。
コンテナ一覧を出力するgs_shのコマンドスクリプトを作成しておくことで運用の省力化が図れます。
以下の例では、gs_shのサブコマンドを listContainer.gshというファイル名で作成します。
setnode node1 198.2.2.1 10040 setnode node2 198.2.2.2 10040 setnode node3 198.2.2.3 10040 setcluster cl1 clusterSeller 239.0.0.20 31999 $node1 $node2 $node3 setuser admin admin gstore connect $cl1 showcontainer connect $cl1 db0 showcontainer : dbの数分繰り返す quit
クラスタを構成するノードを示すnode1,node2,node3といったノード変数や、cl1というクラスタ変数、ユーザ設定やデータベース情報は適宜環境に合わせて変更してください。gs_shの詳細は『GridDB 運用管理ガイド』(GridDB_OperationGuide.html)を参照ください。
gs_shのスクリプトファイルを以下のように実行することで、コンテナとパーティションの一覧が採取できます。
$ gs_sh listContainer.gsh>`date +%Y%m%d`Container.txt
20141001Container.txtには以下の形式で情報が保存されます。
Database : public Name Type PartitionId ------------------------------------------------ container_7 TIME_SERIES 0 container_9 TIME_SERIES 7 container_2 TIME_SERIES 15 container_8 TIME_SERIES 17 container_6 TIME_SERIES 22 container_3 TIME_SERIES 25 container_0 TIME_SERIES 35 container_5 TIME_SERIES 44 container_1 TIME_SERIES 53 : Total Count: 20 Database : db0 Name Type PartitionId --------------------------------------------- CO_ALL1 COLLECTION 32 COL1 COLLECTION 125 Total Count: 2
3 リカバリ操作
障害発生時のリカバリ操作の概要は以下のとおりです。
- 障害の認識とリカバリ範囲の確認
- リカバリ操作とノード起動
- ノードのクラスタへの組込み
- 復旧結果の確認と操作
3.1 障害の認識とリカバリ範囲の確認
GridDB内で障害が発生すると、エラーが発生したノードのイベントログファイルに障害の原因が出力されるとともに、ノードの動作が継続不能と判断した際は、ノードがABNORMAL状態となり、クラスタサービスから切り離されます。
クラスタ構成では、通常複数レプリカが存在する運用を実施しているため、ノードがABNORMALとなってもクラスタサービスが停止することはありません。パーティションがレプリカも含めてすべて障害となった場合、データのリカバリが必要です。
データのリカバリが必要か否かは、マスタノードのステータスをgs_statで確認し、/cluster/partitionStatus の値が"OWNER_LOSS"の場合リカバリが必要です。
$ gs_stat -u admin/admin -p 10041
{
"checkpoint": {
:
},
"cluster": {
"activeCount": 2,
"clusterName": "clusterSeller",
"clusterStatus": "MASTER",
"designatedCount": 3,
"loadBalancer": "ACTIVE",
"master": {
"address": "192.168.0.1",
"port": 10011
},
"nodeList": [
{
"address": "192.168.0.2",
"port": 10011
},
{
"address": "192.168.0.3",
"port": 10010
}
],
"nodeStatus": "ACTIVE",
"partitionStatus": "OWNER_LOSS", ★
"startupTime": "2014-10-07T15:22:59+0900",
"syncCount": 4
:
リカバリしなければならないデータは、gs_partitionコマンドで確認します。--lossオプションを指定してコマンドを実行することで問題のあるパーティションが確認できます。
以下の例では 192.168.0.3のノードの問題によりパーティション68がエラーになっています。
$ gs_partition -u admin/admin -p 10041 --loss
[
{
"all": [
{
"address": "192.168.0.1",
"lsn": 0,
"port": 10011,
"status": "ACTIVE"
},
:
:
,
{
"address": "192.168.0.3",
"lsn": 2004,
"port": 10012,
"status": "INACTIVE" <--- このノードのステータスがACTIVEでない
}
],
"backup": [],
"catchup": [],
"maxLsn": 2004,
"owner": null, //クラスタ内でパーティションのオーナが不在の状態
"pId": "68", //リカバリが必要なパーティションID
"status": "OFF"
},
{
:
}
]
3.2 リカバリ操作とノード起動
3.2.1 バックアップデータからのリカバリ
ディスク障害などで、利用しているシステムの問題でデータベースに問題が発生した場合、バックアップデータからリカバリします。リカバリ時は以下のことに注意する必要があります。
【注意点】
- クラスタ定義ファイルの、パーティション数と処理並列度のパラメータ値には注意してください。バックアップしたノードの設定値とリストアするノードの設定値は同一にしてください。同一でないと正しくノードが起動できません。
- 特定の時点にクラスタデータベースをリカバリしたい場合、バックアップ、リストアの作業をクラスタ全体で行う必要があります。
- クラスタ運用で一部のノードをリストアした場合には、他のノードで保持するレプリカの方が有効となり(LSN情報が新しい場合に発生)、リストアしたバックアップデータベースの状態に戻すことができない場合があります。
- 特に、バックアップを作成した時点からクラスタの構成が変化している場合には、リストアの効果がありません。そのノードをクラスタに参加させると自律的にデータを再配置するので、リストアしても高い確率でデータが無効になります。
- バックアップ情報ファイルの情報が欠けている場合、または内容を改変した場合は、GridDBノードはサービスを開始できません。
GridDBノードにバックアップデータをリストアします。
バックアップしたデータからリストアする場合、以下の手順で操作を行います。
-
ノードが起動していないことを確認します。
- クラスタ定義ファイルが、参加させるクラスタの他のノードと同一であることを確認します。
-
リカバリに利用するバックアップ名を確認します。この操作はノード上で実行します。
- バックアップのステータスを確認し、正しくバックアップされているものを選択します。
-
ノードのデータベースファイルディレクトリ(デフォルトでは、/var/lib/gridstore/data)に過去のトランザクションログファイル、チェックポイントファイルが残っていないことを確認します。
- 不要であれば削除、必要であれば別のディレクトリに移動してください。
- ノードを起動するマシン上で、リストアコマンドを実行します。
- ノードを起動します。
バックアップしたデータの確認には、以下のコマンドを用います。
- gs_backuplist -u ユーザ名/パスワード
以下は、バックアップ名の一覧を表示する具体例です。バックアップ名の一覧は、ノードの起動状態に関わらず表示できます。ノードが起動状態で、バックアップ処理中の場合はStatusは"P"(Processingの略)と表示されます。
バックアップのリスト表示では、最新のものから順に表示されます。以下の例の場合、201504のBACKUPNAMEが最新です。
$ gs_backuplist -u admin/admin BackupName Status StartTime EndTime ------------------------------------------------------------------------ *201504 -- 2015-04-01T05:20:00+0900 2015-04-24T06:10:55+0900 *201503 -- 2015-03-01T05:20:00+0900 2015-04-24T06:05:32+0900 : 20141025NO2 OK 2014-10-25T06:37:10+0900 2014-10-25T06:37:10+0900 20141025 NG 2014-10-25T02:13:34+0900 - 20140925 OK 2014-09-25T05:30:02+0900 2014-09-25T05:59:03+0900 20140825 OK 2014-08-25T04:35:02+0900 2014-08-25T04:55:03+0900 $ gs_backuplist -u admin/admin 201504 BackupName : 201504 BackupData Status StartTime EndTime -------------------------------------------------------------------------------- 201504_lv0 OK 2015-04-01T05:20:00+0900 2015-04-01T06:10:55+0900 201504_lv1_000_001 OK 2015-04-02T05:20:00+0900 2015-04-01T05:20:52+0900 201504_lv1_000_002 OK 2015-04-03T05:20:00+0900 2015-04-01T05:20:25+0900 201504_lv1_000_003 OK 2015-04-04T05:20:00+0900 2015-04-01T05:20:33+0900 201504_lv1_000_004 OK 2015-04-05T05:20:00+0900 2015-04-01T05:21:15+0900 201504_lv1_000_005 OK 2015-04-06T05:20:00+0900 2015-04-01T05:21:05+0900 201504_lv1_001_000 OK 2015-04-07T05:20:00+0900 2015-04-01T05:22:11+0900 201504_lv1_001_001 OK 2015-04-07T05:20:00+0900 2015-04-01T05:20:55+0900
【注意点】
- StatusがNGと表示される場合、そのバックアップファイルはファイルが破損している可能性があるため、リストアすることはできません。
この201504のバックアップデータのうちでリカバリに利用されるデータを確認します。gs_restoreの--testオプションではリカバリに利用する、差分・増分バックアップのデータが確認できます。--testオプションでは、リカバリに利用する情報の表示のみでデータのリストアは行いません。事前確認する際に利用してください。
上記例で出力された201504のBACKUPNAMEのリカバリでは、ベースラインの201504_lv0ディレクトリのデータ、および差分(Since)の201504_lv1_001_000ディレクトリ、増分(Incremental)の201504_lv1_001_001ディレクトリのデータがリカバリに利用されることを示しています。
$ gs_restore --test 20150424 BackupName : 20150424 BackupFolder : /var/lib/gridstore/data/backup RestoreData Status StartTime EndTime -------------------------------------------------------------------------------- 201504_lv0 OK 2015-04-01T05:20:00+0900 2015-04-01T06:10:55+0900 201504_lv1_001_000 OK 2015-04-07T05:20:00+0900 2015-04-01T05:22:11+0900 201504_lv1_001_001 OK 2015-04-07T05:20:00+0900 2015-04-01T05:20:55+0900
なお、特定のパーティションの障害の場合、そのパーティションの最新データがどこに保持されているのかを確認する必要があります。
クラスタを構成するすべてのノード上で、gs_backuplistコマンドを用い、--partitionIdオプションに確認したいパーティションIDを指定して実行します。最も数値の大きいLSNを含むノードのバックアップを利用してリカバリします。
*** クラスタを構成する各ノードで実行します。 $ gs_backuplist -u admin/admin --partitionId=68 BackupName ID LSN --------------------------------------------------------------------------------- *201504 68 81512 *201503 68 2349 20140925 68 0
"*"は、差分・増分バックアップのBACKUPNAMEの場合に付与されます。
以下は、バックアップデータをリストアする実行例です。リストアはノードを停止した状態で実行します。
$ mv ${GS_HOME}/data/*.{dat,log} ${GS_HOME}/temp # データベースファイルの移動
$ gs_restore 201504 # リストア
gs_restoreコマンドの実行により、以下のような処理が実行されます。
- バックアップディレクトリ(ノード定義ファイルの /dataStore/backupPath)の下にある、201504_lv0および201504_lv1_001_001ディレクトリから、バックアップファイル群をデータディレクトリ(ノード定義ファイルの /dataStore/dbPath)にコピーする。
リストア後はノードを起動します。起動後の処理は、ノード起動後の操作を参照してください。
$ gs_startnode -u admin/admin -w
3.2.2 ノード障害からのリカバリ
ノード障害でノードの状態がABNORMALになったり、ノードが異常終了した際は、イベントログファイルでエラー原因を特定する必要があります。
データベースファイルに障害がない場合、ノードの障害原因を除去し、ノードを起動するだけでデータベースファイルのデータはリカバリできます。
ノードの状態がABNORMALになったときは、一旦ノードを強制終了させエラー原因を調査後再起動します。
強制的にノードを停止します。
$ gs_stopnode -f -u admin/admin -w
エラー原因を特定し、データベースの障害ではないと判断した場合、ノードを起動します。ノードを起動することで、トランザクションログのロールフォワードが行われ、最新の状態にデータがリカバリされます。
$ gs_startnode -u admin/admin -w
起動後の処理は、ノード起動後の操作を参照してください。
3.3 ノード起動後の操作
ノード起動後には以下の操作を行います。
- ノードをクラスタに組み込む
- データ一貫性の確認とフェイルオーバー操作
3.3.1 ノードをクラスタに組み込む
ノードを起動後、回復したノードをクラスタに組み込むには、gs_joinclusterコマンドを実行します。
$ gs_joincluster -n 5 -c clusterSeller -w -u admin/admin
3.3.2 データ一貫性の確認とフェイルオーバー操作
ノードをクラスタに組み込んだ後、パーティションのリカバリ状態を確認します。オンラインで動作しているクラスタに対して、データベースファイルのリカバリをバックアップから実施した場合、オンラインで保持しているパーティションのLSNに一致しない場合があります。以下のコマンドでパーティションの詳細情報を調べ、コンテナ情報の採取で採取した情報と照らし合わせることで、ロスト対象に含まれるコンテナがわかります。
gs_partitionコマンドを用いてパーティションの欠損情報を取得します。パーティションの欠損が発生している場合は、欠損が発生しているパーティションのみが表示されます。
$ gs_partition -u admin/admin --loss
[
{
"all": [
{
"address": "192.168.0.1",
"lsn": 0,
"port": 10040,
"status": "ACTIVE"
},
{
"address": "192.168.0.2",
"lsn": 1207,
"port": 10040,
"status": "ACTIVE"
},
{
"address": "192.168.0.3",
"lsn": 0,
"port": 10040,
"status": "ACTIVE"
},
],
"backup": [],
"catchup": [],
"maxLsn": 1408,
"owner": null,
"pId": "1",
"status": "OFF"
},
:
]
LSNがマスタノードが保持するMAXLSNと異なる場合パーティション欠損と判断されます。クラスタを構成するノードのstatusはACTIVEですが、パーティションのstatusはOFF状態です。このままシステムに組み込むにはgs_failoverclusterコマンドを実行します。
$ gs_failovercluster -u admin/admin --repair
フェイルオーバーの完了は、マスタノードに対するgs_statコマンドの実行で/cluster/partitionStatusがNORMALになっていること、gs_partitionコマンドでパーティションの欠損が発生していないことで確認します。
3.4 リカバリ完了後の操作
リカバリ完了後は、クラスタを構成する全ノードでフルバックアップを採取してください。
4 付録
4.1 バックアップディレクトリに配置されるファイル
ノード定義ファイルの /dataStore/backupPathの指すディレクトリ下にバックアップコマンドのBACKUPNAMEで指定した名前でディレクトリが作成され、以下のファイルが配置されます。なお、差分・増分バックアップの場合は、バックアップディレクトリ下に BACKUPNAME_lv0 (ベースライン) BACKUPNAME_lv1_NNN_MMM(差分・増分バックアップ)ディレクトリが作成され、同様に以下のファイルが配置されます。
-
チェックポイントファイル(gs_cp_n_p.dat)
- ノード定義ファイルの/dataStore/concurrencyの数分のファイルがあります。
-
トランザクションログファイル(gs_log_n_m.log)
- フルバックアップ時もしくは、自動ログバックアップの動作に応じて新しいしいトランザクションログファイルが追加されます。
-
差分・増分ブロックログファイル(gs_log_n_m_incremental.log)
- 差分・増分バックアップで、更新ブロックのトランザクションログファイルを保持します。
-
バックアップ情報ファイル(gs_backup_info.json,gs_backup_info_digest.json)
- バックアップ時の情報として、バックアップの採取開始時間、完了時間やバックアップファイルのサイズなどの情報がgs_backup_info.jsonに保持され、gs_backup_info_digest.jsonにダイジェスト情報が保持されています。本ファイルを元にgs_backuplistで情報が出力されます。
-
シーケンス番号(gs_lsn_info.json)
- パーティション更新のシーケンス番号を示すLSN(Log Sequence Number)が出力されます。バックアップ採取時点でパーティションが保持しているLSNが出力されます。
4.2 不要となったバックアップデータの削除
不要となったバックアップデータの削除は、BACKUPNAME単位に不要となったディレクトリを削除するのみです。バックアップデータの管理情報はすべて各々のBACKUPNAMEのディレクトリ下にあるため、他のレジストリ情報などを削除するといった操作は不要です。なお、差分・増分バックアップの際は、BACKUPNAME_lv0, BACKUPNAME_lv1_NNN_MMMのディレクトリ群をすべて削除してください。