GridDB® テクニカルリファレンス
Revision: 1423
Table of Contents
1 はじめに
1.1 本書の目的と構成
本書では、GridDBのアーキテクチャや提供する機能について説明します。
本書は、GridDBを用いたシステム設計・開発を行う設計・開発者およびGridDBの運用管理を行う管理者の方を対象としています。
本書は、以下のような構成となっています。
-
GridDBとは
- GridDBの特長やGridDBの適用例を説明します。
-
GridDBのアーキテクチャ
- GridDBのクラスタ動作のしくみやデータモデルについて説明します。
-
GridDBの提供する機能
- GridDBの提供するデータ管理の機能や、データモデル特有の機能、運用機能について説明します。
-
パラメータ
- GridDBの動作を制御するパラメータについて説明します。
2 GridDBとは
GridDBは、キーと複数の値からなるデータ(ロウと呼ばれる)の集合を管理する、分散NoSQL型データベースです。データをすべてメモリに配置するインメモリデータベースとしての構成に加え、ディスク(SSDも含む)とメモリの利用を併用したハイブリッド構成も取れます。ハイブリッド構成を用いることで、小規模、小メモリシステムでも活用可能です。
GridDBはビッグデータソリューションで必要となる3つのV(Volume,Variety,Velocity)に加えデータの信頼性/可用性を備えています。また自律的なノード監視と負荷バランシング機能により、クラスタ運用の省力化が実現できます。
2.1 GridDBの特徴
2.1.1 大容量データ(Volume)
システムの規模拡大とともに扱うデータの容量は増大し、大容量データを素早く処理するためにはシステムの拡張が必要になります。
システムの拡張のアプローチには、大きく分けてスケールアップ(垂直スケーラビリティ)とスケールアウト(水平スケーラビリティ)の2つのアプローチがあります。
-
スケールアップとは
動作するマシンへのメモリ追加、ディスクのSSD化、プロセッサの追加などの方法でシステムを増強するアプローチです。一般的に、1つ1つの処理時間を短縮してシステムを高速化するという効果がある反面、複数台マシンを用いたクラスタ運用ではないため、スケールアップ時には一旦ノードを停止する必要がある、障害発生時に障害回復に時間がかかるなどの欠点があります。
-
スケールアウトとは
システムを構成するノードの台数を増やして処理能力を向上させるアプローチです。一般的に、複数のノードを連携して動作させることになるため、メンテナンスや障害発生時でもサービスを完全に停止させる必要がない点が利点となる反面、ノード台数が増えるために運用管理の手間が増大するなどの欠点があります。並列度の高い処理を行なうのに向いたアーキテクチャです。
GridDBでは、動作するノードをスケールアップしてシステム増強する方法に加え、システムに新たなノードを追加し、稼働するクラスタに組み込むスケールアウトでシステムを拡張することもできます。
GridDBは、インメモリ処理データベースとしてもスケールアウトモデルで大容量化が可能です。GridDBでは 、複数ノードで構成されるクラスタ内のノードにデータを分散配置します。したがって複数ノードのメモリが1つの大きなメモリ空間として利用できるため大規模なメモリデータベースが提供できます。
また、メモリの利用だけでなく、ディスクを併用したハイブリッド構成のデータ管理も可能のため、単体のノードで動作させた場合も、メモリサイズを超えたデータを保持して、アクセスができます。メモリサイズに制限されない大容量化も実現できます。
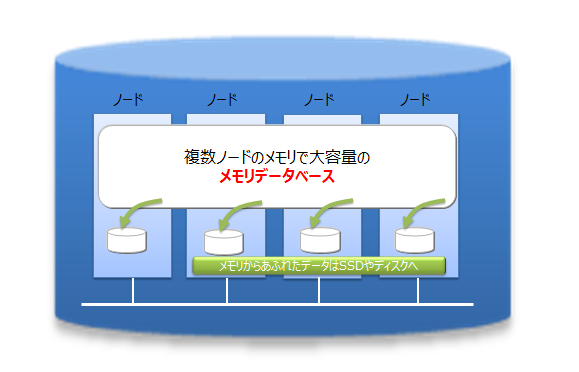
インメモリ/ディスクの併用
スケールアウトでのシステム拡張は、オンラインで行うことができます。そのため、システムの成長とともに増大するデータに対応するために、運用中のシステムを停止することなく対応できます。
スケールアウトでシステムに組み込んだノードには、システムの負荷に応じて適切にデータが配置されます。GridDBが負荷バランスを最適化するため、運用管理者がデータ配置を気にする必要はありません。このような運用を自動化する仕組みが組み込まれており、運用も容易です。
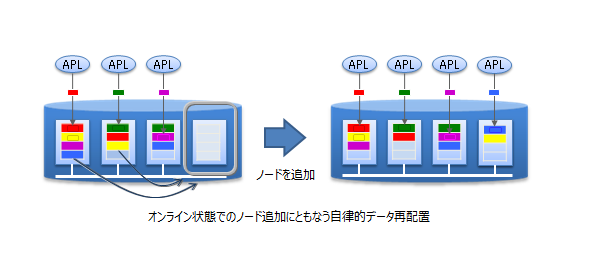
スケールアウトモデル
2.1.2 さまざまなデータ(Variety)
GridDBのデータは、Key-Valueを発展させたKey-Container型のデータモデルです。コンテナというRDBのテーブルに相当する器にデータを格納します。(コンテナをRDBのテーブルとして考えるとわかりやすいです。)
GridDBのデータアクセスでは、Key-Valueデータベース構造のため、Keyで絞り込みができるモデルが最も高速に処理できます。管理する実体に対応して、キーとなるコンテナを用意するという設計が必要です。
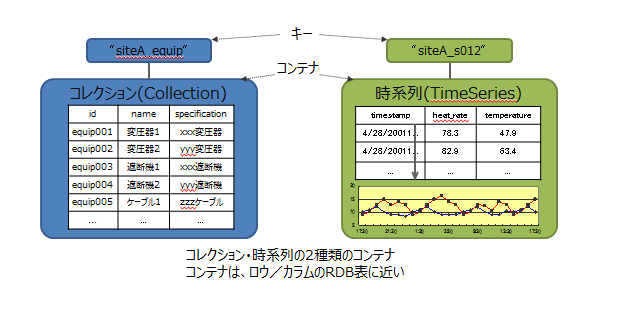
データモデル
コンテナには、センサ等の時々刻々発生する時間と値のペアになった大量の時系列のデータを扱うのに適したコンテナ(時系列コンテナ)に加え、位置情報などの空間データを登録し、空間固有の演算(空間の交差)を行うこともできます。配列型のデータやBLOBなどの非定型なデータにも対応しているため、さまざまなデータを扱うことができます。
時系列コンテナには、特有の圧縮機能や保持期限の切れたデータの解放機能などを提供しており、大量に発生するデータの管理に適しています。
2.1.3 高速処理(Velocity)
GridDBには、さまざまなアーキテクチャ上の工夫が組み込まれ、高速化を実現しています。
- できるだけメモリ上で処理をする
全てのデータがメモリに配置されインメモリで動作するシステムの場合、ディスクへのアクセスオーバヘッドをあまり気にする必要がありません。しかし、メモリ上に保持できないほどの大量のデータを処理するためには、アプリケーションのアクセスするデータを局所化し、ディスクに配置されたデータへのアクセスをできるだけ少なくする必要があります。
GridDBではデータアクセスを局所化するために、関連のあるデータをできるだけ同じブロックに配置する機能を提供します。データにヒント情報を与えることで、ヒントに従ったデータブロックへのデータ集約が実現できるため、データアクセス時のメモリミスヒットを減らし、データアクセス処理を高速化します。アプリケーションでのアクセス頻度やアクセスパターンに応じて、メモリ集約のヒントを設定することで、限られたメモリ領域を有効活用して動作させることができます。(アフィニティ機能)
- オーバヘッドを減らす
データベースに対して並列にアクセス時のロックやラッチなどの、データベースの実行処理の待ちとなる事象をできるだけ少なくするために、CPUコア・スレッドごとに占有するメモリ、DBファイルを割り当て、排他、同期処理の待ちをなくしています。
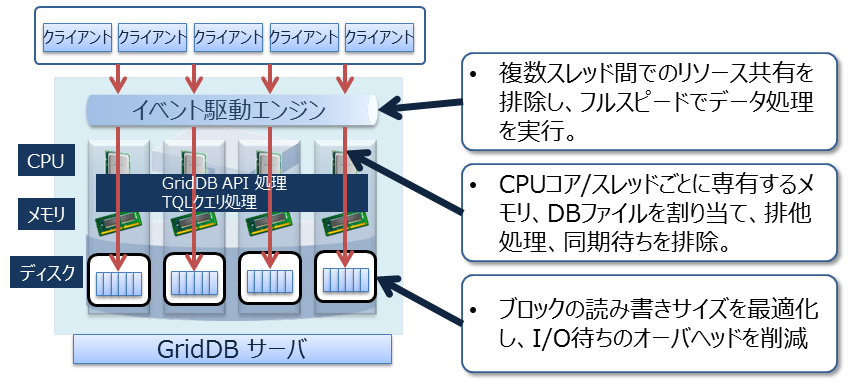
アーキテクチャ
また、GridDBでは、クライアントライブラリ側で初回アクセス時にデータ配置をキャッシュすることで、クライアントとノード間は直接アクセス可能です。データ配置やクラスタの動作状況を管理するマスタノードを介さず、直接目的とするデータにアクセスできるので、マスタノードへのアクセス集中や、通信コストを大幅に削減できます。
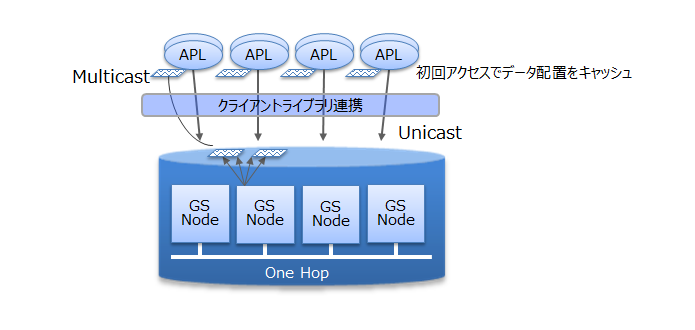
クライアントからのアクセス
- 並列に処理をする
1つの巨大なデータを複数ノードに分散配置(パーティショニング)したノード間、ノード内での並列処理と、少ないリソースで多くの要求を処理可能なイベント駆動エンジンで高速化を実現しています。
2.1.4 信頼性/可用性
クラスタ内でデータの複製(以降レプリカと呼びます)を作成しており、クラスタを構成するいずれかのノードに障害が発生した場合でもレプリカを使用することで処理を継続できます。ノード障害発生後のデータ再配置もシステムが自動的に行うため(自律的データ配置)、特別な運用操作は不要です。障害対象のノードに配置されていたデータはレプリカから復旧され、自動的に設定されたレプリカ数となるようにデータは再配置されます。
レプリカは、可用性の要求に応じて2重化、3重化など多重度の設定ができます。
各ノードはディスクを使用してデータ更新情報の永続化を行っており、クラスタシステムの全てに障害が発生しても、それまで登録、更新したデータ失うことはなく、復元することができます。
また、クライアントでもデータ配置管理情報のキャッシュを保有しているため、ノードの障害を検知すると自動的にフェイルオーバーし、レプリカを用いたデータアクセスを継続できます。
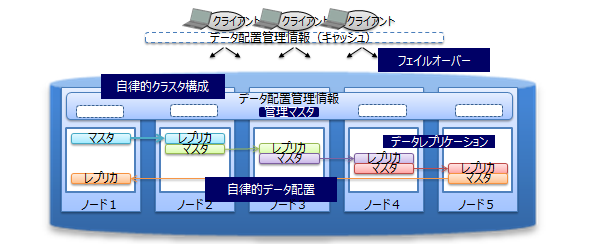
高可用性
2.2 GridDBの製品
GridDBには、以下の2つの製品があります。
- GridDB Standard Edition
- GridDB Advanced Edition
GridDB Advanced Edition(以下、GridDB AEと呼ぶ)は、GridDB Standard Edition(以下、GridDB SEと呼ぶ)のベース技術をそのまま活用し、さらにSQL処理エンジンを追加した製品です。両製品ともGridDBの特徴で説明した特徴を持ちます。
GridDB AEには、以下の2つの特徴が加わります。
-
ODBC/JDBC インターフェイス
- SQL92に準拠したSQLとともに標準に準拠したアプリケーションインターフェイスである、ODBC(C言語インターフェイス)とJDBC(Javaインターフェイス)を利用できます。
- ODBC/JDBCを利用することで、BI(Business Intelligence)ツールやETL(Extract Transfer Load)ツールからデータベースに直接アクセスすることもできます。
-
テーブルパーティショニング機能
- 巨大なテーブルを高速にアクセスするためのパーティショニング機能です。
- データを複数の部分に分割し、複数のノードに分散配置するため、テーブルから条件にマッチするデータを検索する処理やデータを取り出す処理の並列化が行え、データアクセスの高速化が実現できます。
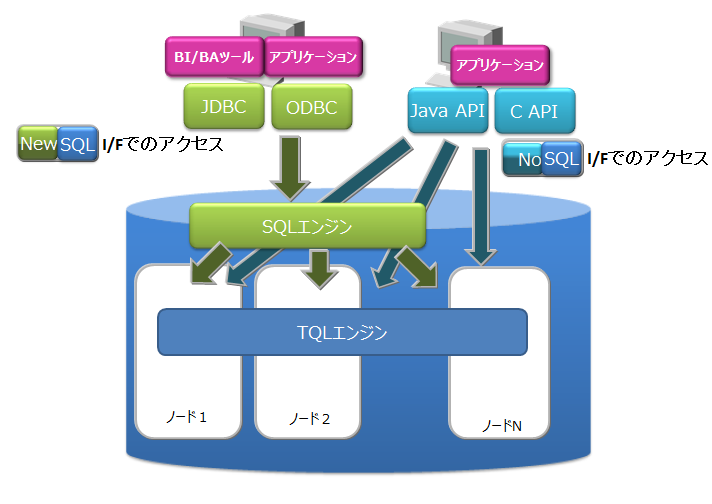
製品構成
それぞれの製品のインターフェイスの特徴は以下のとおりです。
-
GridDB SEのNoSQLインターフェイス(NoSQL I/F)
- NoSQL I/FのクライアントAPI(C言語、Java)は、ビッグデータを高速に一括処理する機能に重点を置いています。
- データ収集やキーバリューデータの高速なアクセス、TQLを用いた簡単な集計演算などを行う場合に利用します。
-
GridDB AEのNewSQLインターフェイス(NewSQL I/F)
- NewSQL I/FのODBCやJDBCは、既存アプリケーションとの連携やSQLを用いた開発生産性の向上に重点を置いています。
- BIツールなどを用いて収集したデータを分類し分析する場合に利用します。
GridDB AEでは、NoSQL I/FとNewSQL I/Fの両方を用途によって使い分けることができます。
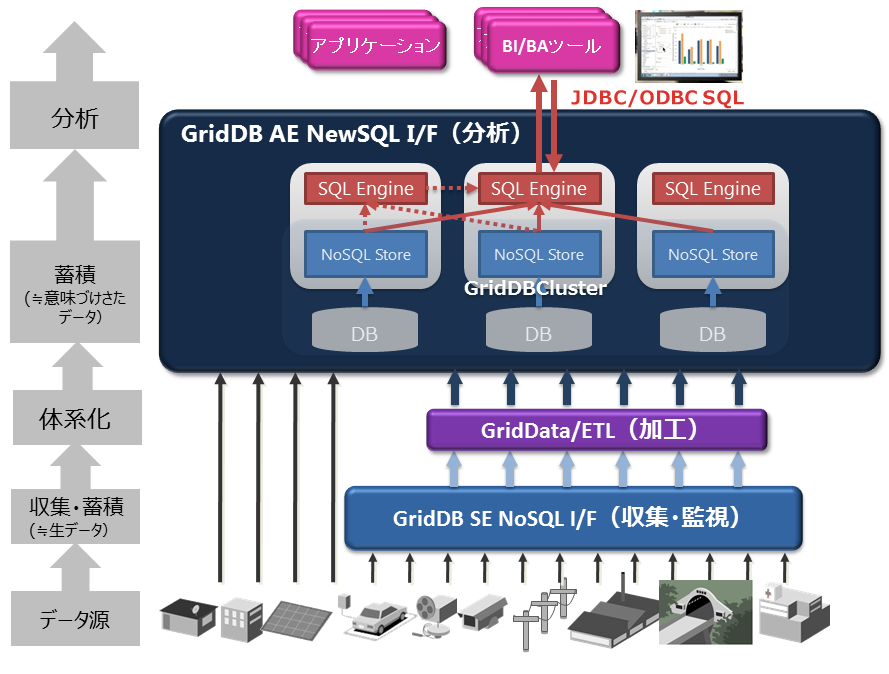
製品位置づけ
GridDB SEとGridDB AEのデータ構造は共通化されているため、GridDB AEではGridDB SEのデータをそのまま利用できます。
GridDB SEのみを利用する場合には考慮不要ですが、GridDB SEをGridDB AEに置き換える場合や、GridDB AEでNoSQL I/FとNewSQL I/Fを併用する場合は以下の仕様をあらかじめ理解してください。
- テーブルとコンテナの名称は、コンテナ名、テーブル名で一意の名称である必要があります。既存データベースファイルに移行する際は、コンテナと同じ名前のテーブルが存在するとエラーになります。
- GridDB SEとGridDB AEではデータベースやユーザ管理情報のデータ構造は共通です。
-
GridDB AEでは、
- GridDB SE NoSQL I/Fで作成したコンテナをテーブルとみなして、SQLでアクセスすることができます。
- ただし、GridDB SEで作成したデータは、NewSQL I/FのODBC/JDBCによるSQLでのデータ更新はできません。テーブルとしてのアクセスは参照のみです。
- コンテナデータは、NoSQL I/FのクライアントAPI(C言語、Java)を利用することで更新操作ができます。
3 GridDBの仕組み
GridDBのクラスタ動作のしくみやデータモデルについて説明します。
3.1 クラスタの構成
GridDBは複数ノードで構成されるクラスタで動作します。アプリケーションシステムからデータベースにアクセスするにはノードが起動されておりかつクラスタが構成(クラスタサービスが実行)されている必要があります。
クラスタは、ユーザが指定した構成ノード数のノードがクラスタへ参加することで構成され、クラスタサービスが開始されます。構成ノード数のノードがクラスタに参加するまでクラスタサービスは開始されず、アプリケーションからはアクセスできません。
ノード1台で動作させる場合にもクラスタを構成する必要があります。この場合構成ノード数を1台でクラスタを構成することになります。ノード1台で動作させる構成をシングル構成と呼びます。
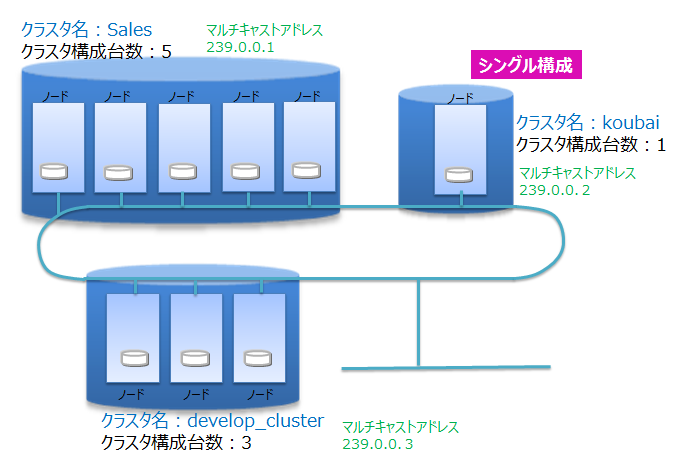
クラスタ名と構成ノード数
ネットワーク上にあるGridDBの多数のノードを用いて、正しく(意図したノードを用いて)クラスタが構成できるようにクラスタ名を用いて複数のクラスタを分離します。同じネットワーク上に複数のGridDBクラスタが構成できます。クラスタ名、構成ノード数、マルチキャストアドレスの設定が等しいノードでクラスタが構成されます。クラスタ名は、クラスタを構成するノード毎に保有する定義ファイルであるクラスタ定義ファイルに設定するとともにクラスタ構成する際のパラメータでも指示します。
マルチキャストを用いてクラスタを構成する方式を、マルチキャスト方式と呼びます。クラスタ構成方式については、クラスタ構成方式を参照してください。
以下にクラスタ構成の操作の流れを示します。
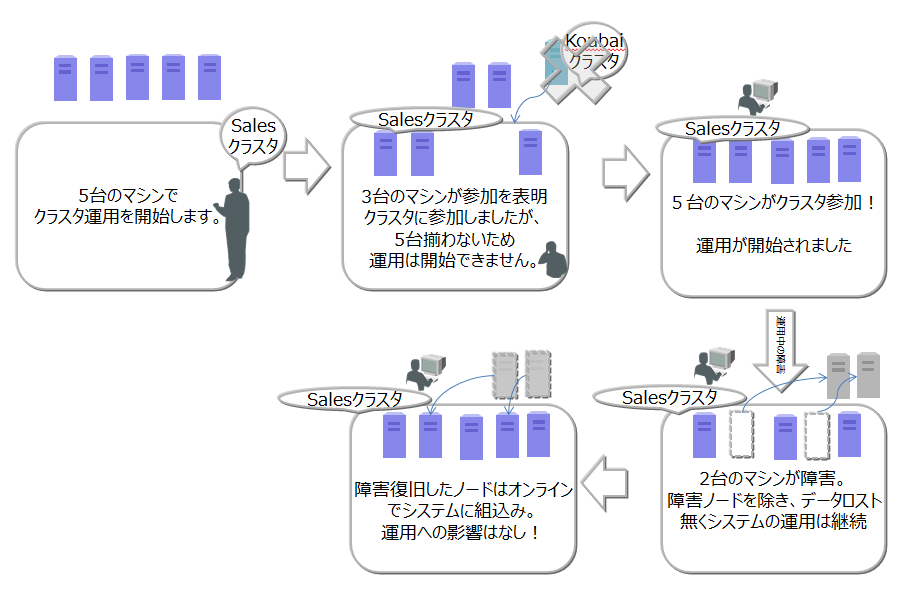
クラスタ構成の動作
ノードの起動、クラスタの構成には、運用コマンドのgs_startnode/gs_joinclusterコマンドやgs_shを用います。また、OS起動と同時にノードを起動し、クラスタを構成するサービス制御機能もあります。
クラスタを構成するには、クラスタに参加させるノードの数(構成ノード数)とクラスタ名をすべての参加ノードで一致させて指示する必要があります。
クラスタサービスは、クラスタでの運用を開始後に構成するノードに障害がありクラスタから切り離された場合でも、過半数のノードが参加している限りサービスは継続します。
過半数以上のノードさえ動作してればクラスタ運用は継続できるので、クラスタ運用中にメンテナンス等のために、オンラインでノード切り離したり、メンテナンス完了後に組込む操作ができます。さらには、システムを増強するためにノードを追加することもオンラインできます。
3.1.1 ノードのステータス
GridDBのステータスには、gs_statコマンドで確認できるnodeStatusとclusterStatusがあり、この2つのステータスでノードのステータスが決まります。
nodeStatusは、ノードの稼働状況を示し、clusterStatusは構成したクラスタにおける各ノードの役割を示します。クラスタに属する複数のノードのこれらのステータスによって、クラスタ全体のステータスが決まります。
-
ノードステータスの遷移
ノードステータスには、以下の図に示すステータスがあります。
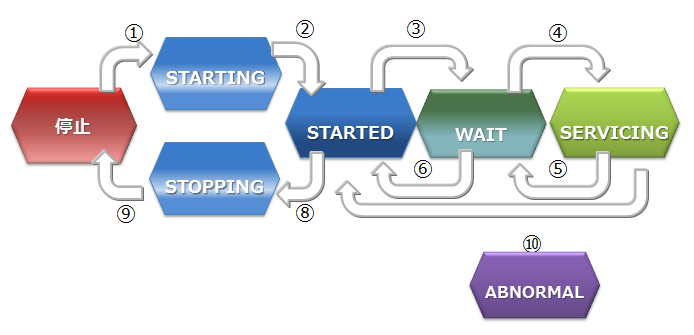
ノードステータス
- 【停止】状態は、ノードでGridDBサーバが起動されていない状態です。
- 【STARTING】状態は、ノードでGridDBサーバが起動処理中の状態です。前回の運転状態に応じて、データベースのリカバリ処理などの起動時の処理が行われます。クライアントからアクセスできるのは、gs_statコマンドやgs_shコマンドでのシステムの状態確認のみです。アプリケーションからのアクセスはできません。
- 【STARTED】状態は、ノードでGridDBサーバが起動されている状態です。ただし、クラスタには参加していないため、引き続きアプリケーションからのアクセスはできません。クラスタ構成をとるには、gs_joinclusterやgs_shのクラスタ操作コマンドででクラスタへの参加を指示します。
- 【WAIT】状態は、クラスタ構成待ちの状態です。ノードは、クラスタへの参加を通知しているが、構成ノード数のノードが足りておらず、ノード数が構成ノード数になるまで待ち状態となります。また、クラスタを構成するノードが過半数以下になり、クラスタのサービスが停止した際のノード状態も示します。
- 【SERVICING】状態は、クラスタが構成されており、アプリケーションからのアクセスが可能な状態です。ただし、ノード停止時の障害後の再起動などでパーティションのクラスタ間での同期処理が発生した場合アクセスが遅延することがあります
- 【STOPPING】状態は、ノードを停止指示後停止するまでの中間ステータスです。
- 【ABNORMAL】状態は、SERVICING状態もしくは、状態遷移の途中でノードがエラーを検出した際のステータスです。ABNORMAL状態となったノードは、自動的にクラスタから切り離されます。システムの動作情報を採取後、強制停止させ再起動させる必要があります。再起動することで、リカバリ処理が自動的に行われます。
-
状態遷移の説明ノードの状態遷移の契機となる事象を説明します。
ステータス遷移 状態遷移事象 説明 ① コマンド実行 gs_startnodeコマンド、gs_sh、サービス起動によるノード起動 ② システム リカバリ処理やデータベースファイルのロードが完了すると状態が自動遷移 ③ コマンド実行 gs_joincluster/gs_appendclusterコマンド、gs_sh、サービス起動によるクラスタ参加 ④ システム 構成ノード数のノードがクラスタに参加すると状態は遷移 ⑤ システム クラスタを構成する他のノードが障害等によりサービスから切り離され、構成ノード数が設定値の過半数を下回ったとき。 ⑥ コマンド実行 gs_leaveclusterコマンドやgs_shによりノードをクラスタから切り離す ⑦ コマンド実行 gs_leavecluster/gs_stopclusterコマンドやgs_shによりノードをクラスタから切り離す ⑧ コマンド実行 gs_stopnodeコマンド、gs_sh、サービス停止によるノード停止 ⑨ システム 終了処理が完了次第、サーバプロセスを停止 ⑩ システム システム障害により切り離された状態。この状態では一度ノードを強制的に停止する必要がある。 -
ノードステータスとnodeStatus、clusterStatus
gs_statコマンドを用いることでノードの稼働情報の詳細がjson形式のテキストで確認できます。gs_statの示すjsonのパラメータであるnodeStatusとclusterStatusとの関係は以下です。
ステータス /cluster/nodeStatus /cluster/clusterStatus STARTING INACTIVE SUB_CLUSTER STARTED INACTIVE SUB_CLUSTER WAIT ACTIVATINGまたはDEACTIVATING SUB_CLUSTER SERVICING ACTIVE MASTERまたはFOLLOWER STOPPING NORMAL_SHUTDOWN SUB_CLUSTER ABNORMAL ABNORMAL SUB_CLUSTER
3.1.2 クラスタのステータス
クラスタの稼働ステータスは各ノードの状態で決まり、そのステータスには稼働/中断/停止の3つのステータスがあります。
クラスタのサービスは、システムの初回構築時はユーザが指定したクラスタ構成するノード数(構成ノード数)のノードがすべてクラスタに参加した時点で開始されます。
初回のクラスタ構築時、クラスタを構成するノードがすべてクラスタに組み入れられておらず、クラスタ構成待ちの状態を【INIT_WAIT】と呼びます。構成ノード数のノードがクラスタに参加完了した時点で状態は自動遷移し稼働状態となります。
稼働状態には2つの状態があります。【STABLE】と【UNSTABLE】です。
-
【STABLE】状態
- 構成ノード数で指定したノードの数でクラスタが構成されており、サービスが提供できている安定した状態。
-
【UNSTABLE】状態
- 構成ノード数に満たない状態。
- 構成ノード数の過半数が稼働している限り、クラスタのサービスは継続します。
メンテナンスなどでノードをクラスタより切り離しても過半数が動作している限りクラスタは【UNSTABLE】状態で運用できます。
クラスタを構成するノードが、構成ノード数の半数以下となった場合、スプリットブレイン発生を防ぐためにクラスタは自動的サービスを中断します。この状態ではクラスタのサービスは中断した状態の【WAIT】状態となります。
-
スプリットブレインとは、
複数のノードを相互接続して1台のサーバのように動作させる密結合クラスタシステムにおいて、ハードウェアやネットワークの障害によりシステムが分断されたことを契機に、同じ処理を行なう複数のクラスタシステムが同時にサービスを提供してしまう動作をいいます。この状態で運用を継続した場合、複数のクラスタでレプリカとして保有するデータをマスタデータとして扱い動作してしまい、データの一貫性が取れない状態となってしまいます。
【WAIT】状態からクラスタサービスを再開するには、ノード追加操作でエラーの回復したノードや新規のノードをクラスタへ追加していき、再び構成ノード数のノードがクラスタに参加完了した時点で状態は【STABLE】状態となります。
クラスタを構成するノードの障害等でクラスタを構成するノード数が半数以下となり、クラスタの動作が中断した場合でも、ノード追加操作でエラーの回復したノードや新規のノードをクラスタへ追加していき過半数のノードがクラスタに参加した時点で自動的にクラスタのサービスは再開されます。
ただし、オペレータがメンテナンスなどの操作で意図的にgs_leaveコマンドを用いてノードをクラスタサービスから離脱させ、かつクラスタを構成するノード数が半数以下となった場合には、クラスタ追加でノードを追加していき過半数のノードがクラスタに参加した時点でもクラスタのサービスは再開されません。この場合、クラスタ構成ノード数に達するまでクラスタのサービスは再開されません。
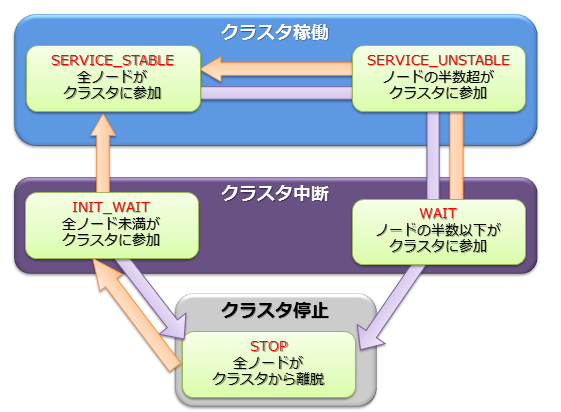
クラスタステータス
STABLE状態はgs_statの示すjsonのパラメータである、/cluster/activeCountと/cluster/designatedCountの値が等しい状態です。
%gs_stat -u admin/admin -s
{
"checkpoint": {
"archiveLog": 0,
:
:
},
"cluster": {
"activeCount":4, ★ クラスタ内で稼働中のノード
"clusterName": "test-cluster",
"clusterStatus": "MASTER",
"designatedCount": 4, ★ 構成ノード数
"loadBalancer": "ACTIVE",
"master": {
"address": "192.168.0.1",
"port": 10040
},
"nodeList": [ ★ クラスタを構成するマシンリスト
{
"address": "192.168.0.1",
"port": 10040
},
{
"address": "192.168.0.2",
"port": 10040
},
{
"address": "192.168.0.3",
"port": 10040
},
{
"address": "192.168.0.4",
"port": 10040
},
],
:
:
クラスタのステータスは、gs_shやgs_adminで確認できます。以下にgs_shでのクラスタステータスの確認例を示します。
% gs_sh gs> setuser admin admin gsadm //接続ユーザの設定 gs> setnode node1 192.168.0.1 10040 //クラスタを構成するノードの定義 gs> setnode node2 192.168.0.2 10040 gs> setnode node3 192.168.0.3 10040 gs> setnode node4 192.168.0.4 10040 gs> setcluster cluster1 test150 239.0.0.5 31999 $node1 $node2 $node3 $node4 //クラスタの定義 gs> startnode $cluster1 //クラスタを構成する全ノードの起動 gs> startcluster $cluster1 //クラスタ構成を指示 クラスタの開始を待っています。 クラスタが開始しました。 gs> configcluster $cluster1 ★クラスタのステータスを確認 Name : cluster1 ClusterName : test-cluster Designated Node Count : 4 Active Node Count : 4 ClusterStatus : SERVICE_STABLE ★安定状態 Nodes: Name Role Host:Port Status ------------------------------------------------- node1 M 192.168.0.1:10040 SERVICING node2 F 192.168.0.2:10040 SERVICING node3 F 192.168.0.3:10040 SERVICING node4 F 192.168.0.4:10040 SERVICING s> leavecluster $node2 ノードがクラスタから離脱するのを待っています。 ノードがクラスタから離脱しました。 gs> configcluster $cluster1 Name : cluster1 ClusterName : test150 Designated Node Count : 4 Active Node Count : 3 ClusterStatus : SERVICE_UNSTABLE ★不安定な状態 Nodes: Name Role Host:Port Status ------------------------------------------------- node1 M 192.168.0.1:10040 SERVICING //マスタノード node2 - 192.168.0.2:10040 STARTED node3 F 192.168.0.3:10040 SERVICING //フォロワノード node4 F 192.168.0.4:10040 SERVICING //フォロワノード
3.2 クラスタ構成方式
クラスタは、ネットワーク上に存在するノード同士がお互いを認識することで構成されます。ノードは、認識した他のノードのアドレスをリストとして持ちます。
GridDBは、アドレスリストを構成する方法がそれぞれ異なる3つのクラスタ構成方式を提供します。環境や利用ケースによってクラスタ構成方式を使い分けることができます。クラスタ構成方式によって、クライアントや運用ツールの接続方式も異なります。
クラスタ構成方式には、利用を推奨するマルチキャスト方式のほかに、固定リスト方式とプロバイダ方式があります。
固定リスト方式かプロバイダ方式を用いることで、マルチキャストが利用不可能な環境でのクラスタ構成、クライアント接続が可能になります。
-
マルチキャスト方式
- マルチキャストでノードのディスカバリを行い、アドレスリストを自動構成します。
-
固定リスト方式
- クラスタ定義ファイルに固定のアドレスリストを与えて起動することで、そのリストを利用します。
-
プロバイダ方式
- アドレスプロバイダが提供するアドレスリストを取得して利用します。
- アドレスプロバイダはWebサービスとして構成するか、静的コンテンツとして構成することができます。
方式の比較は以下のとおりです。
| 項目 | マルチキャスト方式(推奨) | 固定リスト方式 | プロバイダ方式 |
|---|---|---|---|
| 設定 | ・マルチキャストアドレス、ポート | ・ノード数分のIPアドレス:ポートのリスト | ・プロバイダURL |
| 利用ケース | ・マルチキャストが利用できる | ・マルチキャストが利用できない | ・マルチキャストが利用できない |
| ・正確にサイズ見積りが行える | ・サイズが見積れない | ||
| クラスタ動作 | ・一定時間間隔でノードの自動ディスカバリを行う。 | ・全ノードに同一のアドレスリストを設定する | ・アドレスプロバイダから一定時間間隔でアドレスリストを取得 |
| ・ノード起動時に1度だけそのリストを読み込む | |||
| メリット | ・ノード追加のためのクラスタ再起動不要 | ・リストの整合性チェックが行われるため、間違いが無い | ・ノード追加のためのクラスタ再起動不要 |
| デメリット | ・クライアント接続にマルチキャストを要する | ・ノード追加にクラスタ再起動が必要 | ・アドレスプロバイダの可用性確保が必要 |
| ・アプリ側の接続設定の更新も必要 |
3.3 データモデル
GridDBは、Key-Valueに似た独自のKey-Container型データモデルです。以下の特徴があります。
- Key-Valueをグループ化するコンテナというRDBのテーブルに似た概念を導入
- コンテナに対してデータ型を定義するスキーマ設定が可能。カラムにインデックスを設定可能。
- コンテナ内のロウ単位でトランザクション操作が可能。また、コンテナ単位でACIDを保証します。
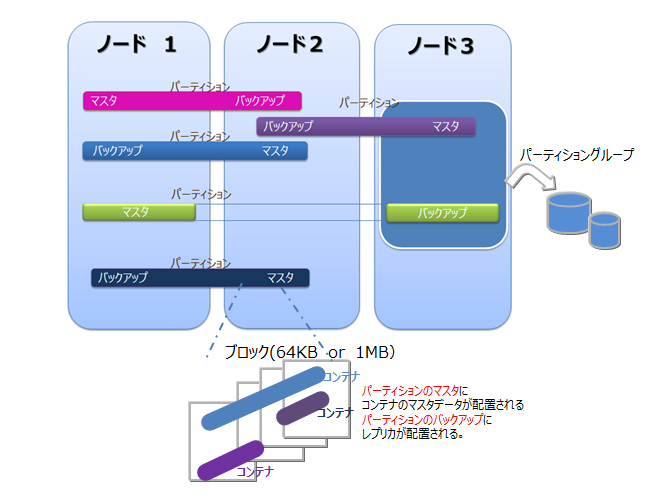
GridDBのデータは、ブロック、コンテナ、パーティション、パーティショングループという単位でデータ管理されています。
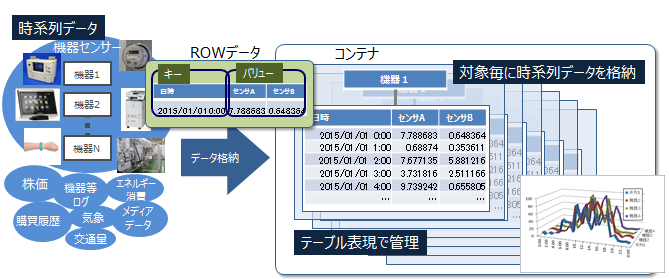
データモデル
GridDBのデータは、ブロック、コンテナ、テーブル、ロウ、パーティション、パーティショングループという単位でデータ管理されています。
-
ブロック
ブロックとは、ディスクへのデータ永続化処理(チェックポイントと以降よびます)のデータ単位であり、GridDBの物理的なデータ管理の最小単位です。
ブロックには複数のコンテナのデータが配置されます。ブロックサイズは、定義ファイル(クラスタ定義ファイル)で、GridDB初期起動前に設定サイズを64KB/1MBのどちらかから選択しできます。システムの実装メモリが少ない場合や、データの増加頻度が低い場合は、64KBを指定します。GridDBは、システムの初期起動とともにデータベースファイルが作成されるため、初期起動以降ブロックサイズの変更はできません。
-
コンテナ
コンテナは、複数のブロックで構成されます。コンテナは、利用者とのI/Fとなるデータ構造です。
コンテナには、コレクションと時系列という2つのデータタイプがあります。
-
テーブル
テーブルは、GridDB AEでのみ存在するコンテナの特別な形です。GridDB AEでSQLをI/Fとして操作することができます。
アプリケーションでデータを登録する前には必ず、コンテナやテーブルを作成しておく必要があります。コンテナやテーブルにデータを登録します。
-
ロウ
ロウは、コンテナやテーブルに登録される1行のデータ指します。コンテナやテーブルには複数のロウが登録されますが、データは同じブロックに配置されるわけではありません。登録・更新されるタイミングに応じて、パーティション内の適切なブロックに配置されます。
ロウには、通常複数データタイプのカラムがあります。
-
パーティション
パーティションは、1つ以上のコンテナやテーブルを含むデータ管理の単位です。
パーティションはクラスタ間でのデータ配置の単位であり、ノード間の負荷バランスを調整するためのデータ移動や、障害発生に備えたデータ多重化(レプリカ)管理のための単位です。データのレプリカはパーティション単位にクラスタを構成するノードに配置されます。
パーティション内のコンテナに対して更新操作ができるノードはオーナノードと呼ばれ1つのパーティションに対して1つのノードが割り当てられます。オーナノード以外でレプリカを保持するノードは、バックアップノードとなります。パーティションには、レプリカの数の設定値に応じてマスタデータと複数のバックアップデータがあります。
-
パーティショングループ
複数のパーティションをグルーピングしてまとめた単位をパーティショングループと呼びます。
パーティショングループの保持するデータがOSのディスクに保存される物理的なデータベースファイルとなります。パーティショングループは、ノードで実行するデータベース処理スレッドの並列度に応じた数で作成されます。
データ管理の単位
4 GridDBの機能
GridDBの提供するデータ管理の機能、データモデル特有の機能、提供する運用機能、さらにアプリケーション開発のためのインターフェイスについて説明します。
4.1 リソースの管理
GridDBのクラスタを構成するリソースには、メモリ上のデータベースのほかにディスク上に永続化されるリソースがあります。永続化リソースには、以下のものがあります。
-
データベースファイル
クラスタを構成するノードの保有するデータをディスクやSSDに書き込み永続化したファイル群です。データベースファイルは、チェックポイントファイルという定期的にメモリ上のデータベースが書き込まれるファイルとGridDBデータベースの更新の都度保存されるトランザクションログファイルを総称します。
-
チェックポイントファイル
パーティショングループがディスクに永続化されたファイルです。ノード定義ファイルのサイクル(/checkpoint/checkpointInterval)でメモリ上の更新情報が反映されます。ファイルのサイズはデータ容量に応じて拡張されます。一度拡張されたデータファイルのサイズは、コンテナやロウなどのデータを削除しても減少しません。なお、データ削除後の空き領域は再利用されます。
-
トランザクションログファイル
トランザクションの更新情報がログとしてシーケンシャルに保存されます。
-
定義ファイル
クラスタを構成する際のパラメータファイル(gs_cluster.json:以降クラスタ定義ファイルと呼ぶ)とクラスタ内でのノードの動作やリソースを設定するパラメータファイル(gs_node.json:以降ノード定義ファイルと呼ぶ)の2つがあります。またGridDBの管理ユーザのユーザ定義ファイルもあります。
-
イベントログファイル
GridDBサーバの動作ログが保管されます。エラーや警告などのメッセージが保管されます。
-
バックアップファイル
GridDBのデータファイルのバックアップデータが保持されます
これらのリソースは、GridDBホーム(環境変数GS_HOMEで指定されるパス)で配置を定義できます。初期インストール状態では、/var/lib/gridstoreディレクトリがGridDBホームで、このディレクトリの下に各リソースの初期データが配置されます。
初期の設定状態は以下です。
/var/lib/gridstore/ # GridDBホームディレクトリ
admin/ # 統合運用管理機能ホームディレクトリ
backup/ # バックアップディレクトリ
conf/ # 定義ファイルディレクトリ
gs_cluster.json # クラスタ定義ファイル
gs_node.json # ノード定義ファイル
password # ユーザ定義ファイル
data/ # データベースファイルディレクトリ
log/ # サーバイベントログ・運用ツールログディレクトリ
GridDBホームの設定は、OSユーザgsadmの.bash_profileファイルの設定で変更できます。GridDBホームを変更する場合は、上記ディレクトリのリソースも適宜移動してください。
.bash_profileファイルには、環境変数GS_HOMEとGS_LOGの2つの環境変数の設定がされています。
vi .bash_profile # GridStore specific environment variables GS_LOG=/var/lib/gridstore/log export GS_LOG GS_HOME=/var/lib/gridstore ★GridDBホームの変更 export GS_HOME
データベースディレクトリやバックアップディレクトリ、サーバイベントログディレクトリは、ノード定義ファイルの設定値を変更することでも変更できます。
複数のディスクドライブがあるシステムでは、ディスク障害時のバックアップデータの消失を防ぐため、必ず定義情報を変更してください。
クラスタ定義ファイルやノード定義ファイルで設定できる内容に関しましてはパラメータを参照してください。
4.2 ユーザ管理
GridDBのユーザには、インストール時に作成されるOSユーザとGridDBの運用/開発を行なうGridDBのユーザ(以降GridDBユーザと呼ぶ)の2種類があります。
4.2.1 OSユーザ
OSユーザは、GridDBの運用機能を実行できる権限を持つユーザであり、GridDBインストール時にgsadmというユーザが作成されます。以降このOSユーザをgsadmと呼びます。
GridDBのリソースはすべて、gsadmの所有物となります。また、GridDBの運用操作のコマンド実行はすべてgsadmで実行します。
運用操作では、GridDBサーバに接続し運用操作を実行できる権限を持ったユーザか否かの確認を行います。この認証は、GridDBユーザで行います。
4.2.2 GridDBユーザ
-
管理ユーザと一般ユーザ
GridDBのユーザには、管理ユーザと一般ユーザの2種類があり、利用できる機能に違いがあります。GridDBインストール直後には、デフォルトの管理ユーザとして、system、adminの2ユーザが登録されています。
管理ユーザは、GridDBの運用操作を行うために用意されたユーザであり、一般ユーザはアプリケーションシステムで利用するユーザです。
セキュリティの面から、管理ユーザと一般ユーザは利用用途に応じて使い分ける必要があります。
-
ユーザの作成
管理ユーザは、gsadmが登録削除することができ、その情報は、GridDBのリソースとして定義ファイルディレクトリのpasswordファイルに保存されます。管理ユーザは、OSのローカルファイルに保存/管理されるため、クラスタを構成する全ノードで同一の設定となるように、配置しておく必要があります。また、管理ユーザは、GridDBサーバ起動前に設定しておく必要があります。起動後に登録しても有効にはなりません。
一般ユーザは、管理ユーザがGridDBのクラスタ運用開始後に作成することができます。クラスタサービス開始前に一般ユーザの登録はできません。一般ユーザはGridDBのクラスタ構成後に作成し、GridDBデータベース内の管理情報として保持するため、クラスタに対して運用コマンドを用いて登録するのみです。
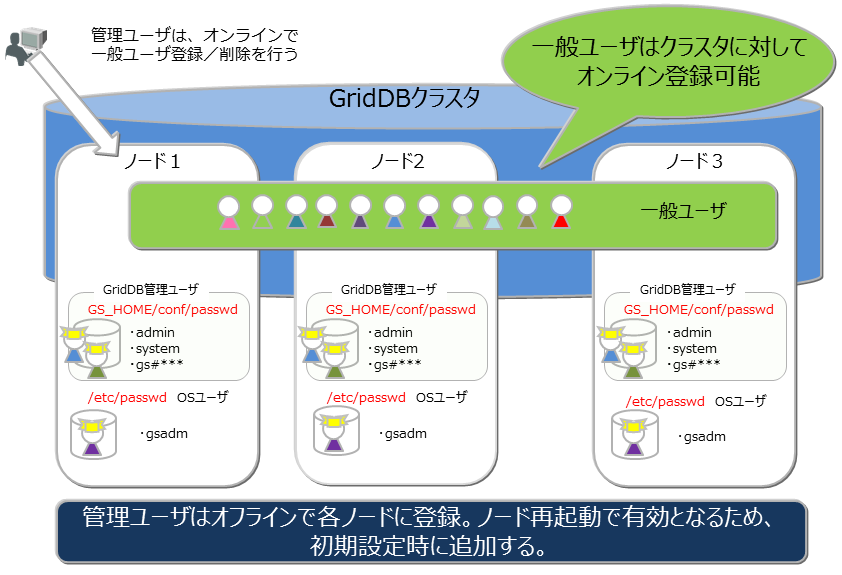
GridDBのユーザ
管理ユーザはクラスタ間での自動的な情報伝達は行われないため、定義ファイルのマスタ管理ノードを決めマスタ管理ノードからクラスタを構成する全ノードに配布管理するなどの運用管理を行い、全ノードで同じ設定とする必要があります。
-
ユーザ作成時の規則
ユーザ名には命名規則があります。
- 管理ユーザ:『gs#』で始まるユーザを指定します。『gs#』以降は英数字およびアンダースコアのみで構成します。大文字と小文字は同一として扱うため、gs#managerとgs#MANAGERは同時には登録できません。
- 一般ユーザ:英数字およびアンダースコアで指定します。但し、先頭文字に数字は指定できません。また、大文字と小文字は同一として扱うため、userとUSERは同時には登録できません。管理ユーザのデフォルトユーザである、system,adminは作成できません。
- パスワード:指定できる文字に制限はありません。
なお、ユーザ名およびパスワードに指定できる文字列は、64文字です。
4.2.3 利用できる機能
管理ユーザができる運用操作と一般ユーザができる操作を以下に示します。運用操作のうちGridDBユーザを用いずに、gsadmで実行可能なコマンドは◎印で明記します。
| 操作 | 操作詳細 | 利用する運用ツール | gsadm | 管理ユーザ | 一般ユーザ |
|---|---|---|---|---|---|
| ノード操作 | ノードの起動 | gs_startnode/gs_sh | ○ | × | |
| ノードの停止 | gs_stopnode/gs_sh | ○ | × | ||
| クラスタ操作 | クラスタの構築 | gs_joincluster/gs_sh | ○ | × | |
| クラスタへのノード増設 | gs_addcluster/gs_sh | ○ | × | ||
| クラスタからのノード離脱 | gs_leavecluster/gs_sh | ○ | × | ||
| クラスタの停止 | gs_stopcluster/gs_sh | ○ | × | ||
| ユーザ管理 | 管理ユーザ登録 | gs_adduser | ◎ | × | × |
| 管理ユーザの削除 | gs_deluser | ◎ | × | × | |
| 管理ユーザのパスワード変更 | gs_passwdコマンド | ◎ | × | × | |
| 一般ユーザの作成 | gs_sh | ○ | × | ||
| 一般ユーザの削除 | gs_sh | ○ | × | ||
| 一般ユーザのパスワード変更 | gs_sh | ○ | ○:本人のみ | ||
| データベース管理 | データベースの作成・削除 | gs_sh | ○ | × | |
| データベースへのユーザ割り当て/解除 | gs_sh | ○ | × | ||
| データ操作 | コンテナやテーブルの作成・削除 | gs_sh | ○ | ○:本人のDB内のみ | |
| コンテナやテーブルへのデータ登録 | gs_sh | ○ | ○:本人のDB内のみ | ||
| コンテナやテーブルの検索 | gs_sh | ○ | ○:本人のDB内のみ | ||
| コンテナやテーブルへの索引操作 | gs_sh | ○ | ○:本人のDB内のみ | ||
| バックアップ管理 | バックアップ作成 | gs_backup | ○ | × | |
| バックアップ管理 | バックアップリストア | gs_restore | ◎ | × | × |
| バックアップリスト | gs_backuplist | ○ | × | ||
| システムステータス管理 | システム情報の取得 | gs_stat | ○ | × | |
| パラメータ変更 | gs_paramconf | ○ | × | ||
| データインポート/ | システム情報の取得 | gs_import | ○ | ○:アクセスできる範囲 | |
| エクスポート | パラメータ変更 | gs_export | ○ | ○:アクセスできる範囲 |
4.2.4 データベースとユーザ
GridDBのクラスタデータベース(以降クラスタデータベース)を利用ユーザ単位にアクセスを分離することができます。分離する単位を データベース と呼びます。データベースは、クラスタデータベースの初期状態では以下のデータベースがあります。
-
public
- 管理ユーザ、一般ユーザのすべてがアクセスできるデータベースです。
- 接続先データベースを指定せずに接続した場合はこのデータベースが利用されます。
データベースはクラスタデータベースに複数作成することができます。データベースの作成、削除、ユーザへの割り当ては管理ユーザが行います。
データベース作成時の規則は以下に示すとおりです。
- クラスタデータベースに作成できるユーザ数、データベース数の上限は各々128個までです。
- データベース名に指定可能な文字列は、英数字およびアンダースコアです。但し、先頭文字に数字は指定できません。
- データベース名に指定できる文字列は、64文字です。
- データベース名命名時の大文字・小文字は保持されますが、大文字小文字同一視した場合に同一名となるデータベースは作成できません。
- デフォルトDBである「public」および「information_schema」は指定できません。
データベースにアクセスできるのは割り当てた一般ユーザと管理ユーザのみです。管理ユーザはすべてのデータベースにアクセスすることができます。データベースへ一般ユーザを割り当てる際、以下規則があります。
- 1データベースに割り当てられる一般ユーザは1ユーザのみ
- 1ユーザには複数のデータベースを割り当てることができる
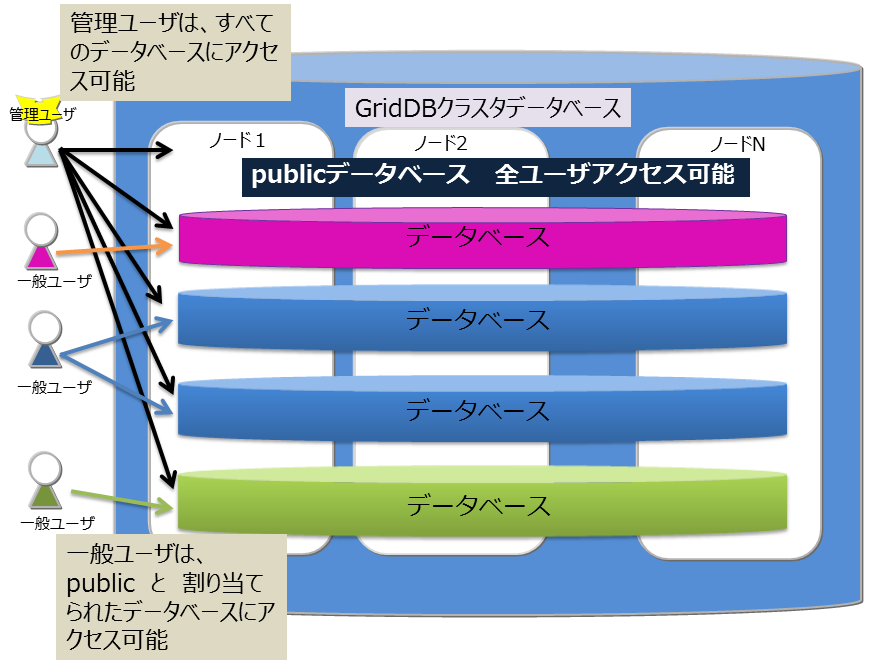
データベースとユーザ
データベース作成時の規則は以下に示すとおりです。
- クラスタデータベースに作成できるユーザ数、データベース数の上限は各々128個までです。
- 英数字およびアンダースコアで指定します。但し、先頭文字に数字は指定できません。また、大文字と小文字は同一として扱うため、databaseとDATABASEは同時には登録できません。
4.3 データ管理機能
GridDBにデータを登録し、検索するには、データを格納するコンテナやテーブル(GridDB AEのみ)を作成する必要があります。本節では、コンテナやテーブルに登録できるデータ型、データサイズ、索引やデータ管理の機能について説明します。
コンテナやテーブルもデータベースと同様の命名規則があります。
- 指定可能な文字列は、英数字およびアンダースコアです。但し、先頭文字に数字は指定できません。
- 命名時の大文字・小文字は保持されますが、大文字小文字同一視した場合に同一名となるコンテナ(テーブル)は作成できません。
4.3.1 コンテナのデータ型
コンテナには、2つのデータタイプがあります。
時々刻々発生するデータを発生した時刻とともに管理するのに適したデータタイプである 時系列コンテナ型 とさまざまなデータを管理する コレクション です。
コンテナにはスキーマを設定できます。
コンテナに登録できるデータ型は、基本的なデータ型である 基本型 と 配列型 があります。
- 基本型
コンテナに登録できる基本型のデータを説明します。基本型とは、他の型の組み合わせで表現できない、基本的な型です。データ型 説明 BOOL型 真または偽のいずれかの値 STRING型 Unicodeコードポイントを文字とする、任意個数の文字の列より構成 BYTE型 -2^{7}から2^{7}-1 (8ビット)の整数値 SHORT型 -2^{15}から2^{15}-1 (16ビット)の整数値 INTEGER型 -2^{31}から2^{31}-1 (32ビット)の整数値 LONG型 -2^{63}から2^{63}-1 (64ビット) の整数値 FLOAT型 単精度型(32ビット) IEEE754で定められた浮動小数点数 DOUBLE型 倍精度型(64ビット) IEEE754で定められた浮動小数点数 TIMESTAMP型 年月日ならびに時分秒からなる時刻を表す型。データベースに保持されるデータ形式はUTCで、精度はミリ秒 GEOMETRY型 空間構造を表すためのデータ型 BLOB型 画像や音声などのバイナリデータのためのデータ型 STRING型、GEOMETRY型、BLOB型は管理できるデータのサイズに以下の制限があります。制限値は、GridDBの定義ファイル(gs_node.json)のデータベースの入出力単位であるブロックサイズに応じて値が異なります。
型 ブロックサイズ(64KB) ブロックサイズ (1MB) STRING型 最大31KB (UTF-8エンコード相当) 最大128KB (UTF-8エンコード相当) GEOMETRY型 最大31KB (内部格納形式相当) 最大128KB (内部格納形式相当) BLOB型 最大127MB 最大1GB - 複合型
コンテナに登録できる、基本型の組み合わせで構成される型を定義します。 現バージョンでは配列型のみです。- 配列型
値の列を表します。基本型のデータの内、GEOMETRY型とBLOB型を除く基本型を配列型として、データを保持することができます。配列で保持できるデータ量の制限は、データベースのブロックサイズに応じて値が異なります。
型 ブロックサイズ(64KB) ブロックサイズ (1MB) 配列数 4000 65000 【メモ】
配列型カラムでは、TQLでの操作に以下の制約があります。
- 配列型カラムのi番目の値の比較はできますが、全要素に関する演算(集計演算)はできません。
※(例)columnAが配列型で定義されたとした場合
- select * where ELEMENT(0, columnA) > 0 のような配列内の要素を指定した比較はできます。但し、ELEMNTの"0"の部分に変数は指定できません。
- select SUM(columnA) のような集計計算はできません。
4.3.2 テーブルのデータ型
テーブルには以下の型をテーブル作成時のカラムの型として指定できます。
| データ型 | 説明 |
|---|---|
| BOOL型 | True/False |
| BYTE型 | -2^{7}から2^{7}-1 (8ビット)の整数値 |
| SHORT型 | -2^{15}から2^{15}-1 (16ビット)の整数値 |
| INTEGER型 | -2^{31}から2^{31}-1 (32ビット)の整数値 |
| LONG型 | -2^{63}から2^{63}-1 (64ビット)の整数値 |
| FLOAT型 | 倍精度型(64ビット) IEEE754で定められた浮動小数点数 |
| DOUBLE型 | 倍精度型(64ビット) IEEE754で定められた浮動小数点数 |
| TIMESTAMP型 | 年月日ならびに時分秒からなる時刻を表す型。データベースに |
| 保持されるデータ形式はUTCで、精度はミリ秒 | |
| STRING型 | Unicodeコードポイントを文字とする、任意個数の文字の列より構成 |
| BLOB型 | 画像や音声などのバイナリデータのためのデータ型 |
登録できるデータサイズの制限は以下の通りです。制限値は、GridDBの定義ファイル(gs_node.json)のデータベースの入出力単位であるブロックサイズに応じて値が異なります。
| 型 | ブロックサイズ(64KB) | ブロックサイズ (1MB) |
|---|---|---|
| STRING型 | 最大31KB (UTF-8エンコード相当) | 最大128KB (UTF-8エンコード相当) |
| BLOB型 | 最大127MB | 最大1GB |
4.3.3 GEOMETRY型(空間型)
空間型のデータは地図情報システムなどでよく利用されています。空間型のデータはコンテナにのみ指定できます。
GEOMETRY型には、WKT(Well-known text)を用いてデータを記述します。WKTは、地理空間に関する情報の標準化などを推進している非営利団体OGC(Open Geospatial Consortium)にて策定されています。GridDBでは、コンテナのカラムをGEOMETRY型に設定することで、WKTで記述された空間情報をカラムに格納できます。
GEOMETRY型には以下のWKT形式のデータを登録できます。
-
POINT
- 2次元または3次元の座標により生成される点。
- 記述例: POINT(0 10 10)
-
LINESTRING
- 2つ以上の点により表現される、2次元または3次元空間上の直線の集合。
- 記述例: LINESTRING(0 10 10, 10 10 10, 10 10 0)
-
POLYGON
- 直線の集合により表現される、2次元または3次元空間上の閉じた領域。POLYGONの頂点は反時計回りに指定します。POLYGON内に島をつくる場合、内部の点は時計回りで指定します。
- 記述例: POLYGON((0 0,10 0,10 10,0 10,0 0))、POLYGON ((35 10, 45 45, 15 40, 10 20, 35 10),(20 30, 35 35, 30 20, 20 30))
-
POLYHEDRALSURFACE
- 2次元または3次元の座標により生成される点
- 記述例: POLYHEDRALSURFACE (((0 0 0, 0 1 0, 1 1 0, 1 0 0, 0 0 0)), ((0 0 0, 0 1 0, 0 1 1, 0 0 1, 0 0 0)),((0 0 0, 1 0 0, 1 0 1, 0 0 1, 0 0 0)), ((1 1 1, 1 0 1, 0 0 1, 0 1 1, 1 1 1)),((1 1 1, 1 0 1, 1 0 0, 1 1 0, 1 1 1)),((1 1 1, 1 1 0, 0 1 0, 0 1 1, 1 1 1)) )
-
QUADRATICSURFACE
- 定義式f(X) = <AX, X> + BX + cにより表現される、3次元空間上の2次曲面。
GEOMETRY型を利用した演算は、APIやTQLで実行できます。
TQLでは2次元、3次元の空間を定義する空間生成関数と空間型データ間での演算の関数を提供します。TQLではコンテナ内のGEOMETRY型のカラムと指定した空間データで演算を行いその結果を以下のようにして得ることができます。
SELECT * WHERE ST_MBRIntersects(geom, ST_GeomFromText('POLYGON((0 0,10 0,10 10,0 10,0 0))'))
TQLで提供する関数の詳細は『GridDB APIリファレンス』(GridDB_API_Reference.html)を参照ください。
4.3.4 コンテナのロウキー(ROWKEY)
ROWKEYとは、コンテナのロウに設定する情報です。ROWKEYを設定したロウは一意性が保障されます。
ROWKEYはロウの先頭カラムに設定できます。(GridDBではカラムを0番から数えるため、カラム番号0に設定されます。)
-
時系列コンテナの場合
- ROWKEYは、TIMESTAMP型です。
- 指定は必須です。
-
コレクションの場合
- ROWKEYは、STRING、INTEGER、LONG、TIMESTAMPのいずれかの型のカラムです。
- 指定は必須ではありません。
ROWKEYに設定したカラムには、カラムの型に応じてあらかじめ既定された、デフォルトの索引が設定されます。
現バージョンでは、ROWKEYに指定できるSTRING、INTEGER、LONG、TIMESTAMPのすべての型のデフォルトの索引はTREE索引です。
4.3.5 コンテナの索引
コンテナのカラムに対し索引を作成することで、条件付き検索が高速に処理できます。
索引タイプにはハッシュ索引(HASH)、ツリー索引(TREE)、空間索引(SPATIAL)の3種類があり、ハッシュ索引は、コンテナ内のクエリでの検索時の等価検索で利用します。ツリー索引は、等価検索のほかに、範囲(より大きい/等しい、より小さい/等しいなど)を含む参照に利用します。
設定できる索引はコンテナのタイプやカラムのデータ型に応じて異なります。
-
HASH索引
- 等価検索を高速に行えますが、ロウをシーケンシャル(逐次的)に読み込んでいくような検索には向いていません。
-
コレクションにおける次に示す型のカラムに対して設定できます。 時系列コンテナには設定できません。
- STRING
- BOOL
- BYTE
- SHORT
- INTEGER
- LONG
- FLOAT
- DOUBLE
- TIMESTAMP
-
TREE索引
- 等価検索のほかに、範囲(より大きい/等しい、より小さい/等しいなど)を含む参照に利用します。
-
時系列コンテナにおけるロウキーと対応するカラムを除く、任意種別のコンテナにおける次に示す型のカラムに対して使用できます。
- STRING
- BOOL
- BYTE
- SHORT
- INTEGER
- LONG
- FLOAT
- DOUBLE
- TIMESTAMP
-
空間索引
- コレクションにおけるGEOMETRY型カラムに対してのみ使用できます。空間検索を高速に行う場合に指定します。
コンテナに作成できる索引の数に制限はありませんが、索引の作成は慎重に設計する必要があります。索引は、設定されたコンテナのロウに対して挿入、更新、または削除の各操作が実行されると更新されます。したがって、頻繁に更新されるロウのカラムに多数の索引を作成すると、挿入、更新、または削除の各操作でパフォーマンスに影響ができます。
索引は以下のようなカラムに作成します。
- 頻繁に検索されたり、ソートされたりするカラム
- TQLのWHERE節の条件で頻繁に使用されるカラム
- カーディナリティの高い(重複した値があまり含まれない)カラム
4.3.6 テーブルの索引
テーブルのカラムにも索引を設定できます。索引の種別の指定はなく、ツリー索引となります。
4.3.7 時系列コンテナ
高頻度で発生するセンサなどのデータ管理のために、メモリを最大限有効利用するデータ配置アルゴリズム(TDPA:Time Series Data Placement Algorithm)に従いデータ配置処理します。時系列コンテナでは、内部データを周期性で分類しながらメモリ配置します。アフィニティ機能でヒント情報を与えるとさらに配置効率が上がります。時系列コンテナのデータは、必要に応じてディスクに追い出しながら、ほぼゼロコストで有効期限切れのデータを解放しています。
時系列コンテナは、TIMESTAMP型のROWKEYを持ちます。
- 期限解放機能
時系列タイプのデータには、データの保持期限を設定し、設定した期限を超えた時点でデータを解放(削除)する期限解放機能の動作設定ができます。設定はコンテナ作成時に、期限の単位と期限、データ解放時の分割数を指定します。作成済みの時系列コンテナの設定を変更することはできません。
期限の単位として設定できるのは、日/時間/分/秒/ミリ秒 の単位です。年単位、月単位の指定はできません。有効期限超過の判定に使用される現在時刻は、GridDBの各ノードの実行環境に依存します。したがって、ネットワークの遅延や実行環境の時刻設定のずれなどにより、クライアントの時刻よりGridDBのノードの時刻が進んでいる場合、期限切れ前のロウにアクセスできなくなる場合や、逆にクライアントの時刻のみ進んでいる場合は、期限切れロウにアクセスできる場合があります。
意図しないロウの喪失を避けるために、最低限必要な期間よりも大きな値を設定することを推奨します。期限切れのロウは、検索や更新といったロウ操作の対象から外れ、存在しないものとみなされます。
期限切れのロウの物理的な削除は、有効期間に対する分割数(データ解放時の分割数)の単位で行われます。
たとえば、有効期限が720日で分割数指定が、36の場合、データアクセスは720日経過したデータには即座に行われなくなりますが、削除は720日から20日経過する都度行われます。物理的データ削除は20日分まとめて行なわれます。
分割数はコンテナの作成時に指定します。
- 圧縮機能
時系列コンテナは、データを圧縮して保持することができます。圧縮オプションの指定はコンテナ作成時に指定します。データを圧縮することでメモリ使用効率を上げることができます。ただし、圧縮オプションが設定されているコンテナに対しては、以下に示すロウ操作を行えませんので注意してください。
- 指定ロウの更新
- 指定ロウの削除
- 指定時刻より新しい時刻のロウが存在する場合の、ロウの新規作成
圧縮オプションには次の指定ができます。
- HI :誤差あり間引き圧縮方式であることを示します。
- NO :無圧縮であることを示します。
- SS :誤差なし間引き圧縮方式であることを示します。
それぞれのオプションの内容は以下のとおりです。
- 誤差あり間引き圧縮(HI)
誤差あり間引き圧縮(HI)では、前回まで及び直後に登録したデータと同じ傾斜を表すロウは省かれます。同じ傾斜かを判定する条件はユーザが指定できます。
指定されたカラムが条件を満たし、それ以外のカラムの値が前回のデータと同じ場合のみロウデータは省かれます。条件の指定には、誤差の幅(Width)で指定します。
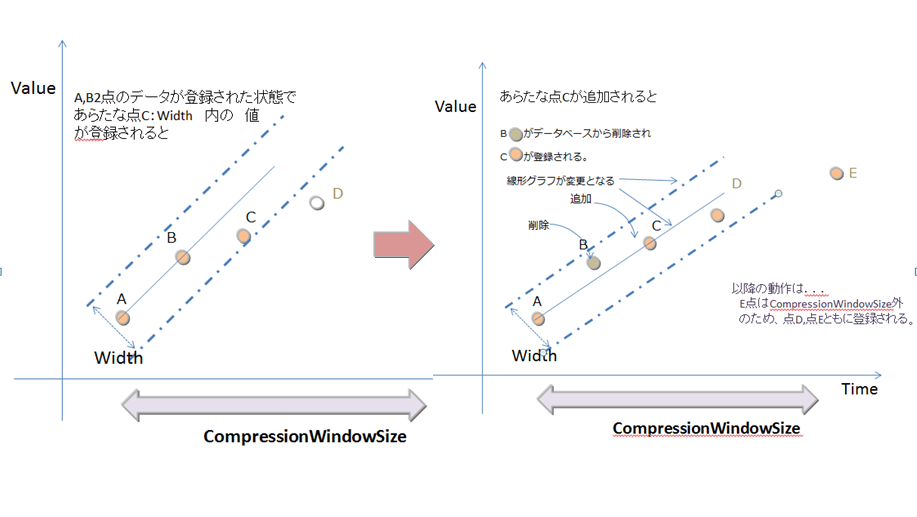
時系列コンテナの圧縮
圧縮の指定を設定できるデータタイプは以下です。
- LONG
- INTEGER
- SHORT
- BYTE
- FLOAT
- DOUBLE
圧縮は不可逆圧縮のため、間引き圧縮で間引かれたデータをデータ登録時のままの値で復元することはできません。
省かれたデータはinterpolate(補完)やsample(サンプリング)処理の際に、指定された誤差の範囲内で復元できます。
- 誤差なし間引き圧縮(SS)
誤差なし間引き圧縮(SS)では、直前及び直後に登録したロウと同じデータを持つロウは省かれます。省かれたデータはinterpolateやsample処理の際に、誤差を発生することなく復元できます。
- 時系列コンテナの演算
時系列コンテナには、コンテナに対する集計演算に加え、時間補正を行った演算があります。-
集計演算コンテナに対する集計演算では、開始・終了時刻指定を指定して、ロウ集合または特定のカラムに対し集計演算を行います。
集計演算で用意されている関数には以下があります
-
AVG(column)
平均を求める演算
-
COUNT(*)
標本数、すなわち対象ロウの個数を求める演算
-
MAX(column)
最大値を求める演算
-
MIN(column)
最小値を求める演算
-
STDDEV(column)
標準偏差を求める演算
-
SUM((column)
合計を求める演算
-
VARIANCE(column)
分散を求める演算
-
AVG(column)
-
時系列コンテナ特有の集計演算
時系列コンテナでは、採取したデータの時間間隔でデータに重みをつけて計算します。つまり、時間間隔が長い場合、長時間その値が続いたことを想定した計算となります。時系列コンテナの集計演算は以下で行います。
- TIME_AVG ・・・重み付きで平均を求める演算
検索の条件に合致した各ロウについて、前後それぞれの時刻のロウとの中間時刻間の期間を特定の単位で換算したものを、重み付け値として使用します。条件で指定した時刻のロウのみが存在しない場合は、存在しないロウの代わりに条件に指定した時刻の直前、直後のロウを用いて重みづけ計算をします。
計算の詳細イメージを図示します。
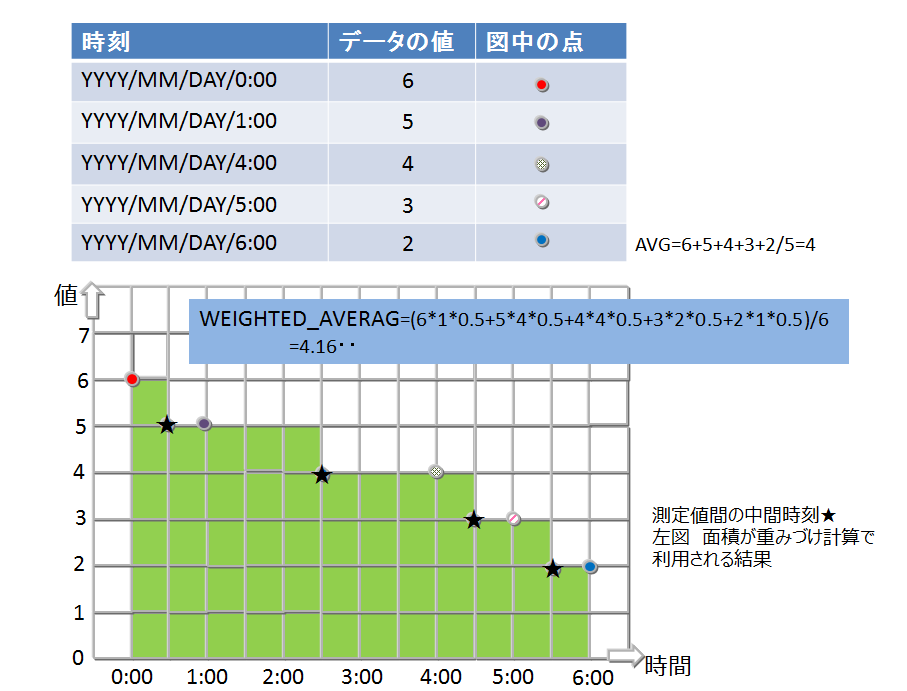
重みづけの集計演算(TIME_AVG)
-
集計演算コンテナに対する集計演算では、開始・終了時刻指定を指定して、ロウ集合または特定のカラムに対し集計演算を行います。
4.3.8 時系列コンテナ選択・補間演算
時刻データは、収集されるデータの内容や収集タイミングにより想定した時刻より多少の時間のずれが発生することがあります。したがって時刻データをキーにして検索する際にも、指定した時刻周辺のデータが取得できる機能が必要です。
時系列コンテナを検索し、指定したロウを取得するための以下のような関数があります。
-
TIME _NEXT(*, timestamp)
指定の時刻と同一またはその直後の時刻を持つ1つのロウを選択します。
-
TIME_NEXT_ONLY(*, timestamp)
指定の時刻の直後の時刻を持つ1つのロウを選択します。
-
TIME_PREV(*, timestamp)
指定の時刻と同一またはその直前の時刻を持つ1つのロウを選択します。
-
TIME_PREV_ONLY(*, timestamp)
指定の時刻の直前の時刻を持つ1つのロウを選択します。
また、実体のロウのカラムの値を補間演算で計算するための以下のような関数があります。
-
TIME_INTERPOLATED(column, timestamp)
指定の時刻に関して、一致するロウの指定のカラムの値、または、隣接する前後のロウの指定カラムの値を線形補間して得られた値を求めます。
-
TIME_SAMPLING(*|column, timestamp_start, timestamp_end, interval, DAY|HOUR|MINUTE|SECOND|MILLISECOND)
開始・終了時刻を指定して、特定範囲のロウ集合をサンプリングします。
サンプリング位置の時刻は、開始時刻に対し非負整数倍のサンプリング間隔を加えた時刻のうち、終了時刻と同じかそれ以前のもののみです。
各サンプリング位置の時刻と一致するロウが存在する場合は該当ロウの値を使用します。存在しない場合は補間された値を使用します。
4.3.9 アフィニティ機能
アフィニティとは、関連のあるデータを結びつける機能です。GridDBには、アフィニティ機能としてデータアフィニティとノードアフィニティの2つの機能があります。
- データアフィニティ機能
データアフィニティとは、関連の強いデータを同じブロックに配置し、データアクセスの局所化を図ることでメモリヒット率を高めるための機能です。メモリヒット率を高めることで、データアクセス時のメモリミスヒットを減らし、スループットを高めることができます。データアフィニティを利用することで小メモリマシンでもメモリを有効活用して動作させることができます。データアフィニティの設定はコンテナ作成時にコンテナのプロパティとしてヒント情報を与えます。ヒント情報は、コンテナ名の命名規則と同様に指定できる文字に制限があります。同じヒント情報があるデータをできるだけ同じブロックに配置します。
データアフィニティのヒントはデータの更新頻度や参照頻度で分けて設定します。たとえば、監視システムにおいて、分単位、日単位、月単位、年単位にデータをサンプリングしたり参照したりするシステムにおいて、以下のような利用方法でシステムのデータが登録・参照・更新される場合のデータ構造を考えます。
- 監視機器から分単位のデータが送信され、監視機器単位に作成したコンテナにデータを保存
- 日単位のデータレポート作成のため、一日分のデータの集計を分単位データから行い、日単位コンテナに保存
- 月単位のデータレポート作成のため、日単位コンテナのデータの集計を行い、月単位コンテナに保存
- 年単位のデータレポート作成のため、月単位コンテナのデータの集計を行い、年単位コンテナに保存
- カレントの使用量(分単位、日単位)は常に表示パネルに更新表示する。
GridDBでは、コンテナ単位にブロックを占有するのではなく、ブロックには時刻の近いデータが配置されます。したがって、2.の日単位コンテナを参照し、月単位の集計を行い集計時間をROWKEYとする3.のデータと分単位の1.のデータが 同一ブロックに保存される可能性があります。
メモリが小さく監視データがすべてメモリに収まらない大容量データで4.の年単位の集計処理を行なう場合、ブロックが分断して配置された3.のデータをメモリに配置するために常時必要な1.のデータがメモリから追い出されるなど、直近でないデータの読み込みにより監視したいデータがスワップアウトされる状況が発生します。
この場合データアフィニティで、分単位、日単位、月単位などコンテナのアクセス頻度に沿ったヒントをコンテナに与えることで、アクセス頻度の低いデータと高いデータをデータ配置時に別ブロックに分離します。
このように、データアフィニティ機能によってアプリケーションの利用シーンに合わせたデータ配置ができます。
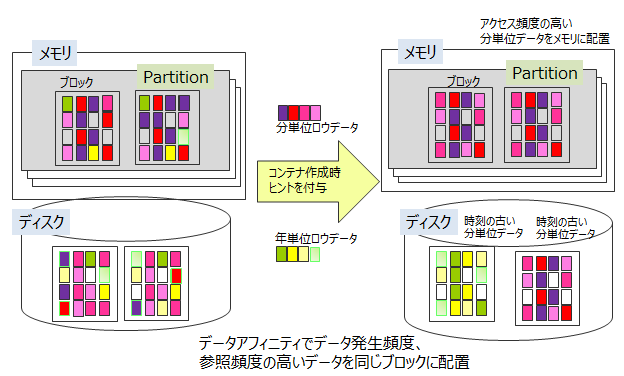
データアフィニティ
- ノードアフィニティ機能
ノードアフィニティとは、関連の強いコンテナやテーブルを同じノードに配置し、データアクセス時のネットワーク負荷を減少させるための機能です。GridDB SEのTQLではコンテナデータのJOIN操作はありませんが、GridDB AEのSQLではテーブルのJOIN操作が記述できます。テーブルのJOIN時にクラスタの別ノードに配置されたテーブルのネットワークアクセスでの負荷を減少させることができます。また、複数ノードを用いた並列処理ができなくなるため、ターンアラウンド時間の短縮には効果がない反面、ネットワーク負荷の減少によりスループットが上がる可能性があります。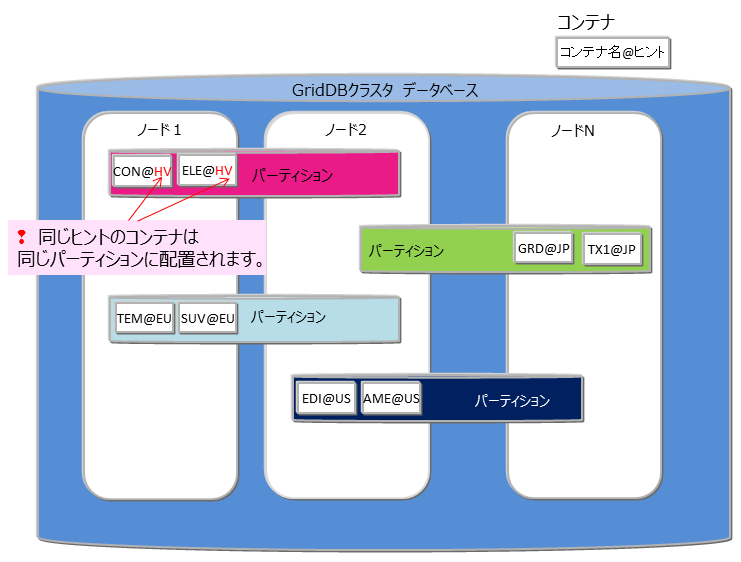
ノードアフィニティによるコンテナ/テーブルの配置
ノードアフィニティ機能を利用するには、コンテナ作成時にコンテナ名にヒント情報を与えます。ヒント情報が同一のコンテナは同一のパーティションに配置されます。コンテナ名を以下のように指定します。
- コンテナ名@ノードアフィニティヒント情報
ノードアフィニティのヒント情報の命名もコンテナ名の命名規則と同様です。
4.3.10 テーブルパーティショニング (GridDB AEのみ)
複数ノードで動作するGridDBのアプリケーションを高速化するには、処理するデータをできるだけメモリに配置することが重要です。データ登録数が多い巨大なテーブルデータでは、テーブルを複数のノードに分散配置することで、複数ノードのメモリを有効に利用し、巨大テーブルをインメモリで処理することができます。テーブルパーティショニングの方法には一般のRDBでは、レンジパーティショニング、ハッシュパーティショニング、コンポジットパーティショニングなどがありますが、GridDBではハッシュパーティショニングをサポートしています。テーブルパーティショニングで分割された個々のデータはGridDBのパーティションにテーブル用のコンテナが作成されて配置されます。
-
ハッシュパーティショニング
ハッシュ値 (HASH) に基づいてGridDBのパーティションに均等に配置されます。パーティションに分割することで、耐障害性のためのレプリカ作成や、負荷に応じたデータ再配置も行えます。
また、高い頻度でデータ登録を行うアプリケーションシステムでの利用では、テーブルの末尾にアクセスが集中し、待ち時間が発生する場合があります。ハッシュ分割を行うことでに「複数のテーブル終端」が用意されるため、アクセスを分散するためにも利用できます。
テーブルパーティションでは、パーティションキーにするカラムと分割数Nを指定することで、1~N の整数を返すハッシュ関数が定義され、その返値に基づいて分割を行います。
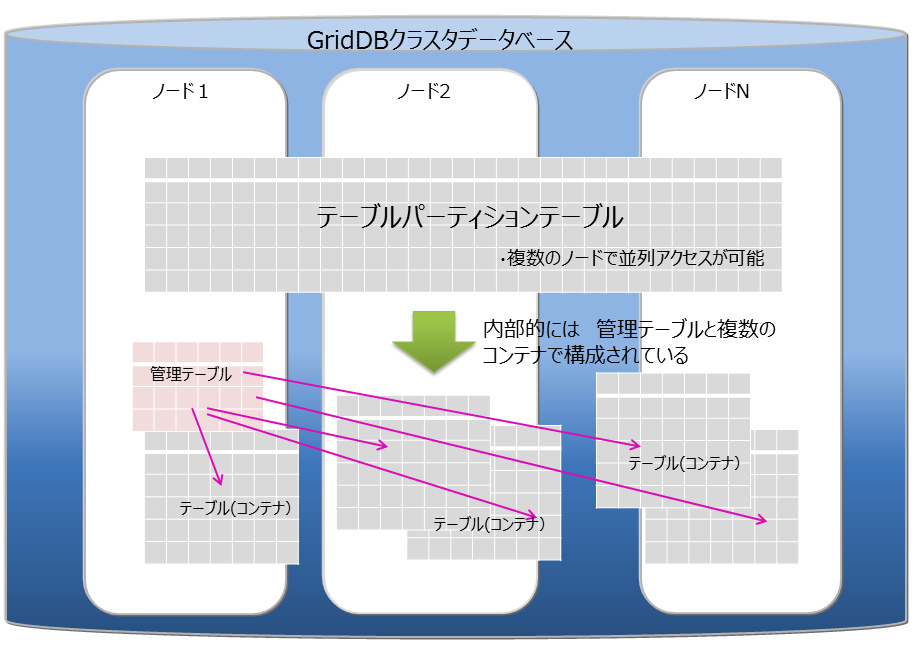
テーブルパーティショニング
4.3.11 データブロック圧縮
GridDBは、メモリ上のデータをデータベースファイルに書き込むことで、メモリサイズに依存しない大容量化を実現できますが、ストレージのコストは増加します。データブロック圧縮機能は、データベースファイル(チェックポイントファイル)を圧縮することで、データ量に伴って増加するストレージコストの削減を支援する機能です。特に、HDDと比べ要領単価が高いフラッシュメモリをより効率的に活用できます。
- 圧縮方法
メモリ上のデータをデータベースファイル(チェックポイントファイル)に書き出す際に、GridDBの書き出し単位であるブロック毎に圧縮操作を行います。圧縮により空いた領域は、Linuxのファイルブロック割り当て解除処理を行うため、ディスク使用量を削減できます。
- サポート環境
データブロック圧縮はLinuxの機能を利用しているため、Linuxカーネルバージョンとファイルシステムに依存します。データブロック圧縮のサポート環境は以下です。
- OS: RHEL / CentOS 7.2
- ファイルシステム:XFS
- ファイルシステムのブロックサイズ:4KB
※上記以外の環境でデータブロック圧縮を有効にした場合、GridDBノードの起動に失敗します。
- 設定方法
GridDBノードごとに圧縮機能を設定します。
-
ノード定義ファイル(gs_node.json)の/datastore/storeCompressionModeに以下の文字列を設定します。
- 圧縮機能を無効にする場合:NO_COMPRESSION(既定値)
- 圧縮機能を有効にする場合:COMPRESSION
- GridDBノード起動時(再起動時)に設定を適用します。
- GridDBノードを再起動することで、圧縮機能の動作を有効/無効に変更することができます。
注意点は以下です。
- データブロック圧縮の対象は、チェックポイントファイルのみです。トランザクションログファイル、バックアップファイル、およびGridDBのメモリ上のデータは圧縮しません。
- データブロック圧縮により、チェックポイントファイルはスパースファイルになります。
- 圧縮機能を有効に変更しても、すでにチェックポイントファイルに書き込み済みのデータは圧縮できません。
-
ノード定義ファイル(gs_node.json)の/datastore/storeCompressionModeに以下の文字列を設定します。
4.4 トランザクション処理
GridDBではコンテナ単位のトランザクション処理をサポートし、トランザクションの特性として一般的に言われるACID特性をサポートしています。以下にトランザクション処理でサポートしている機能の詳細を説明していきます。
4.4.1 トランザクションの開始と終了
コンテナに対して、ロウの検索・更新などの操作を行なったときに新たなトランザクションが開始されデータの更新結果を確定(コミット)または破棄(アボート)した時に終了します。
【メモ】
-
コミットとは、処理中のトランザクションの情報を確定し、データを永続化させる処理です。
- GridDBではコミット処理でトランザクションの更新したデータがトランザクションログとして保管され、保持していたロックが解放されます。
-
アボートとは、トランザクションの処理途中のデータをすべてロールバック(処理を取り消す)する処理です。
- GridDBでは処理途中のデータはすべて破棄され、保持していたロックも解放されます。
トランザクションの初期の動作はautocommit(自動コミット)に設定されています。
autocommitでは、アプリケーションからのコンテナに対する更新(データの追加、削除、変更)操作開始毎に新たなトランザクションが開始され、操作終了とともに自動的にコミットされます。autocommitをオフにすることで、アプリケーションからの要求に応じたタイミングでトランザクションのコミット、アボートを指示できます。
トランザクションのライフサイクルは、トランザクションのコミットやアボートによる完了とともにタイムアウトによるエラー終了があります。トランザクションがタイムアウトによりエラー終了した場合、そのトランザクションはアボートされます。トランザクションのタイムアウトは、トランザクションが開始してからの経過時間です。トランザクションのタイムアウト時間は、定義ファイル(gs_node.json)で初期値が設定されていますが、アプリケーション単位にGridDBに接続する際のパラメータとして指定することもできます。
4.4.2 トランザクションの一貫性レベル
トランザクションの一貫性レベルにはimmediate consistencyとeventual consistencyの2種類があります。この指定はアプリケーションごとにGridDBに接続する際のパラメータとして指定することもできます。デフォルトはimmediate consistencyです。
- immediate consistency:ンテナに対する他のクライアントからの更新結果は、該当トランザクションの完了後即座に反映されます。そのため、常に最新の内容を参照します。
- eventual consistency:コンテナに対する他のクライアントからの更新結果は、 該当トランザクションが完了した後でも反映されていない場合があります。 そのため、古い内容を参照する能性があります。
immediate consistencyは更新操作、読み取り操作で有効です。eventual consistencyは読み取り操作でのみ有効です。常に最新の結果を読み取る必要のないアプリケーションではeventual consistencyを指定すると読み取り性能が向上します。
4.4.3 トランザクションの隔離レベル
データベースの内容は常に整合性が保たれている必要があります。複数のトランザクションを同時実行させたとき、一般に以下の現象が課題として挙がります。
- ダーティリード
トランザクションが書き込んだコミットされていないデータを、別のトランザクションで読み込んでしまう現象です。
- 反復不能読み取り
トランザクション内で以前読み込んだデータを再読み込みできなくなる現象です。トランザクション内で以前読み込んだデータを再度読み込もうとしても、別のトランザクションがそのデータを更新、コミットしたために、以前のデータが読み込めなくなります(更新後の新しいデータを読み込むことになります)。
- ファントムリード
トランザクション内で以前得られた問い合わせの結果が得られなくなる現象です。トランザクション内で以前実行した問い合わせを再実行しても、別のトランザクションがその問い合わせ条件を満たすデータを変更、追加し、コミットしたために、同じ条件で問い合わせを実行しても、以前の結果が得られなくなります(更新後のデータを得ることになります)。
GridDBでは、トランザクションの隔離レベルとして『 READ_COMMITTED 』をサポートしています。READ_COMMITTEDでは、確定した最新データを常に読み取ります。
トランザクションを実行する場合、他のトランザクションからの影響を受けないように配慮する必要があります。隔離レベルは実行トランザクションを他のトランザクションからどの程度隔離するか( どの程度整合性を保てるか) を示す指標であり、4つのレベルがあります。
4つの隔離レベル及びそれに対して同時実行時の課題であげた現象が起こる可能性は以下のとおりです。
| 隔離レベル | ダーティリード | 反復不能読み取り | ファントムリード |
|---|---|---|---|
| READ_UNCOMMITTED | 発生の可能性あり | 発生の可能性あり | 発生の可能性あり |
| READ_COMMITTED | 安全 | 発生の可能性あり | 発生の可能性あり |
| REPEATABLE_READ | 安全 | 安全 | 発生の可能性あり |
| SERIALIZABLE | 安全 | 安全 | 安全 |
READ_COMMITEDでは、以前読み込んだデータを再度読み込んだ場合に、以前のデータとは異なるデータを得たり、問い合わせを再実行した場合に、同じ検索条件で問い合わせを実行しても異なる結果を得てしまうことがあります。これは前回の読み込み後に、別のトランザクションによって更新、コミットが行われ、データが更新されたためです。
GridDBでは、MVCCによって、更新中のデータを隔離しています。
4.4.4 MVCC
READ_COMMITTEDを実現するために、「MVCC(Multi-Version Concurrency Control:多版型同時実行制御方式)」を採用しています。
MVCCとは、各トランザクションがデータベースに対して問い合わせるときに、別のトランザクションが更新中の最新のデータでなく、更新前のデータを参照して処理を行う方式です。更新前のデータを参照してトランザクションを並行実行できるため、システムのスループットが向上します。
実行中のトランザクションの処理がコミットすると、他のトランザクションも最新のデータを参照できます。
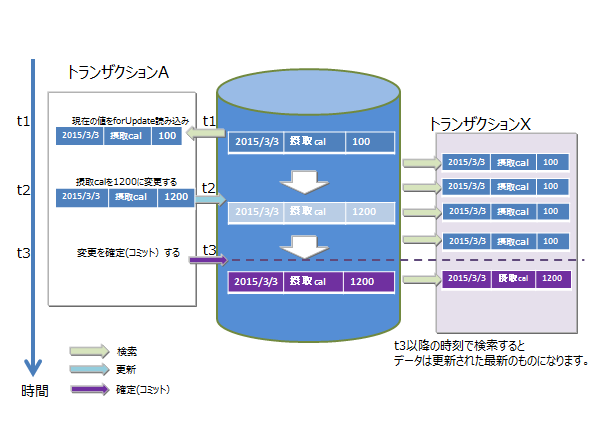
MVCC
4.4.5 ロック
コンテナに対する複数トランザクションからの更新処理要求競合時の一貫性を保つため、データのロック機構があります。
ロックの粒度は、コンテナの種別に応じて異なります。またロックの範囲は、データベースへの操作の種別に応じて異なります。
- ロックの粒度
- 時系列コンテナは時々刻々発生するデータを保持するデータ構造であり、特定の時刻のデータが更新されるケースは少ない
- コレクションデータはRDBのテーブルと同様にデータを管理するため、既存のROWデータが更新されるケースがある
というコンテナのユースケース分析に基づき、GridDBではロックの粒度(最小単位)を以下にしています。更新が比較的多いコレクションは、並列実行性を高めるためロックの粒度はROW単位です。
- コレクション・・・ROW単位でロックします。
-
時系列コンテナ・・・ROW集合でロックされます。
- ロウ集合とは時系列コンテナは、ブロックをいくつかに分割したデータ処理の単位に複数のロウを配置します。このデータ処理の単位をロウ集合とよびます。コレクションでのロック粒度よりもデータ粒度が荒いですが、大量に発生する時系列コンテナを高速に処理するためのデータの管理の単位です。
時系列コンテナと比較し、ランダムな更新が比較的多いコレクションは、並列実行性を高めるためロックの粒度はロウ単位にしています。
- データベース操作によるロック範囲
コンテナへの操作にはデータの登録、削除のみならず、データ構造の変更に伴うスキーマ変更や、アクセス高速化のための索引作成などの操作があります。コンテナの特定のロウ1件単位の操作、全体への操作でロックの範囲は異なります。-
コンテナ単位のロック相当
- 索引操作(createIndex/dropIndex)
- コンテナ削除
- スキーマ変更
-
ロック粒度に従ったロック
- insert/update/remove
- get(forUpdate)
ロウへのデータ操作ではロック粒度に沿ったロックを確保します。
ロック確保で競合した場合、先行したトランザクションがコミットもしくはロールバック処理で実行が完了しロックを解放するまで、後続のトランザクションはロック確保待ちとなります。
ロック確保待ちは、トランザクションの実行完了以外では、タイムアウトでも解消されます。
-
コンテナ単位のロック相当
4.4.6 データ永続化
コンテナやテーブルに登録・更新されたデータは、ディスクやSSDに永続化され、ノード障害発生時のデータ消失から保護されます。メモリ上の更新データをブロック単位にデータベースファイルに定期的に保存するチェックポイント処理と、データ更新に同期して更新データをシーケンシャルにトランザクションログファイルに書き込むトランザクションログ処理の2つの処理があります。
トランザクションログの書き込みには、以下のいずれかをノード定義ファイルに設定できます。
- 0: SYNC
- 1以上の整数値: DELAYED_SYNC
"SYNC"では、更新トランザクションのコミット・アボートごとに、ログ書き込みを同期的に行います。"DELAYED_SYNC"では、更新時のログ書き込みを、更新タイミングとは関係なく、指定秒数毎に遅延して行います。デフォルト値は"1(DELAYED_SYNC 1秒)"です。
"SYNC"を指定するとノード障害発生時に最新の更新内容を消失する可能性が低くなりますが更新が多いシステムでは性能に影響します。
一方"DELAYED_SYNC"を指定すると、更新性能は向上しますがノード障害発生時ディスクに書き込まれていない更新内容があるとそれらが失われます。
クラスタ構成でレプリカ数が2以上の場合は、他ノードにレプリカを持つため"DELAYED_SYNC"設定でも1ノード障害時に最新の更新内容を失う可能性は低くなります。更新頻度が高く、性能が要求される場合には、"DELAYED_SYNC"を設定することも考慮してください。
チェックポイントでは、更新ブロックをデータベースファイルに更新します。チェックポイント処理は、ノード単位に設定したサイクルで動作します。チェックポイントのサイクルはノード定義ファイルのパラメータで設定します。初期値は、1200秒(20分)です。
チェックポイントの実行サイクルの数値を上げることで、ディスクへの永続化を夜間に実施するなど比較的時間に余裕がある時間帯に設定することができます。一方サイクルを長くした場合に、システム処理外でノードを再起動した際にロールフォワードすべきトランザクションログファイルが増え、リカバリ時間が増えるという欠点もあります。
チェックポイント実行時に更新のあったデータは、チェックポイントの書き込みブロックとは別のメモリにプールし、保持します。チェックポイントを高速に行うにはチェックポイントの並列実行を設定します。並列実行を設定した場合、トランザクションの同時実行数と同じ数まで並列で処理されます。
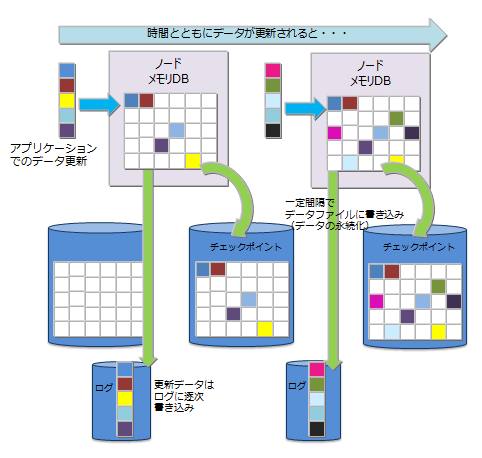
チェックポイント
4.4.7 タイムアウト処理
タイムアウトは、NoSQL I/F、NewSQL I/Fで設定できる内容が異なります。
- NoSQL I/Fのタイムアウト
NoSQL I/Fでは、アプリケーション開発者に通知されるタイムアウトには2種類のタイムアウトがあります。アプリケーションの処理時間の制限に関するトランザクションタイムアウトと障害発生時の回復処理のリトライ時間に関するフェイルオーバータイムアウトの2つです。-
トランザクションタイムアウト(transactionTimeout)
処理対象のコンテナにアクセスを開始してからタイマが開始され、指定した時間を超えるとタイムアウトが発生します。
長時間更新ロックを保有するトランザクション(更新モードで検索し、ロックを保持したまま解放しないアプリケーション)や長時間大量の結果セットを保持するトランザクション(長時間、クラスタシステムのメモリを解放しないアプリケーション)などからロックやメモリを解放するために用意されたタイムアウト時間です。トランザクションタイムアウトに達したらアプリケーションはアボートされます。
トランザクションタイムアウトは、ノード定義ファイルで指定するほかにクラスタ接続時のパラメータで、アプリケーションで指定することもできます。なお、アプリケーションでの指定が優先されます。トランザクションタイムアウトの設定値のデフォルトは0秒です。0秒はタイムアウト指定がないことを意味します。長時間トランザクション発生の監視をするためには、システムの要件に合わせてタイムアウト時間を設定してください。
-
フェイルオーバータイムアウト(failoverTimeout)
クラスタを構成するノードに障害が発生したとき、ノードに接続しているクライアントが代替えノードに接続する際のエラーリトライ時のタイムアウト時間です。リトライ処理で新たな接続先が見つかった場合、クライアントアプリケーションにはエラーは通知されません。デフォルト値は5分です。クラスタ接続時のパラメータで、アプリケーションで指定することもできます。フェイルオーバータイムアウトは、初期接続時のタイムアウトにも利用されます。
トランザクションタイムアウト、フェイルオーバータイムアウトともにJava APIやC APIでGridDBオブジェクトを用いてクラスタに接続する際に設定できます。詳細は『GridDB APIリファレンス』(GridDB_API_Reference.html)を参照ください。
-
トランザクションタイムアウト(transactionTimeout)
- NewSQL I/Fのタイムアウト
NewSQL I/Fでは、ログイン(接続)タイムアウト、ネットワーク応答タイムアウト、クエリタイムアウトの3種類のタイムアウトがあります。-
ログイン(接続)タイムアウト
クラスタに初期接続する際のタイムアウトです。初期設定は5分に設定されていますが、アプリケーションインターフェイスのDriverManagerで変更可能です。
-
ネットワーク応答タイムアウト
クライアントとクラスタ間の応答監視でのタイムアウトです。現バージョンでは、タイムアウトは5分であり、タイムアウト時間の変更はできません。
クライアントからの通信で15秒間サーバが無応答の場合にはリトライし、5分間応答がない場合タイムアウトとなります。長時間のクエリ処理中にタイムアウトとなることはありません。
-
クエリタイムアウト
実行するクエリ単位にタイムアウト時間を設定できます。初期設定ではタイムアウト時間は設定されていません。(長時間のクエリ実行を許容しています。)長時間クエリの監視をするために、システムの要件に合わせてタイムアウト時間を設定してください。設定は、アプリケーションインターフェイスのstatementで設定できます。
-
ログイン(接続)タイムアウト
4.4.8 レプリケーション機能
クラスタを構成する複数のノード間では、ユーザが設定したレプリケーション数に従って、パーティション単位にデータのレプリカが作成されます。
データのレプリカを分散ノード間で保持することで、ノード障害が発生しても、ノンストップで処理を継続できます。クライアントAPIでは、ノードの障害を検出すると自動的にレプリカを保持する別ノードにアクセスを切り替えます。
レプリケーション数のデフォルト値は2で、複数ノードのクラスタ構成で動作した場合、データが2重化されます。
コンテナに更新があると多重化されたパーティションのうち、オーナノード(レプリカのマスタを持つノード)が更新されます。
その後オーナノードから更新内容がバックアップノードに反映されますが、その方法は2つあります。
- 非同期レプリケーション
更新処理のタイミングと同期せずにレプリケーションを行います。準同期レプリケーションに対して更新性能に優れますが、可用性では劣ります。
- 準同期レプリケーション
更新処理のタイミングで同期的にレプリケーションを行いますが、レプリケーション完了の待ち合わせは行いません。可用性の面ではすぐれますが、性能面では劣ります。
可用性よりも性能を重視する場合は非同期レプリケーションに、可用性を重視する場合は準同期レプリケーションに設定してください。
【メモ】レプリケーション数の設定は、クラスタ定義ファイル(gs_cluster.json)の/cluster/replicationNumで設定します。レプリケーションの同期設定は、クラスタ定義ファイル(gs_cluster.json)の/transaction/replicationModeで設定します。
4.5 トリガ機能
トリガ機能とは、コンテナのロウデータへの操作(追加/更新もしくは削除)が行われた際に、自動的に通知する機能です。アプリケーションシステムでデータベースの更新をポーリングして監視する必要はなく、事象の通知をうけることができます。
アプリケーションシステムへの通知方法は、以下の2種類です。
- Java Messaging Service(JMS)
- REST
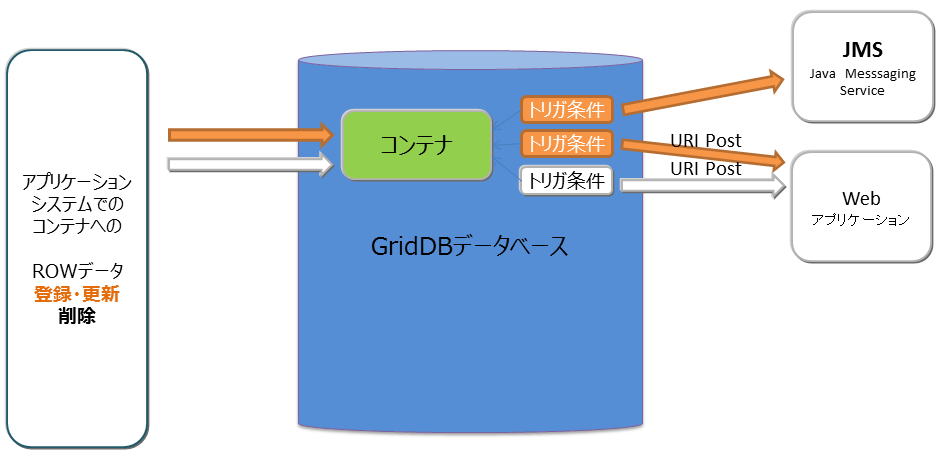
トリガ機能の動作
トリガ発生時、操作対象のロウデータのカラムデータもアプリケーションに通知することができます。どのカラムのデータを通知するかは、コンテナへのトリガ設定時に指定します。また、1つのコンテナに複数のトリガを指定することもできます。
トリガ設定で指定できる項目は以下です。
- 通知事象条件(追加/更新もしくは削除)
- 通知方法(JMSもしくはREST)
- 通知カラム
4.6 障害処理機能
GridDBでは、クラスタを構成する各ノードでデータのレプリカを保持するため、単一点故障に対してのリカバリは不要です。GridDBでは障害発生時には以下のような動作を行ないます。
- 障害発生時、障害ノードはクラスタから自動的に離脱する。
- 離脱した障害ノードに代わり、バックアップノードへのフェイルオーバーが行われる。
- 障害によりノード台数が減少するため、自律的にパーティションの再配置を行う(レプリカも配置する)。
障害の回復したノードはオンラインでクラスタ運用に組み込むことができます。障害によりUNSTABLEな状態となったクラスタには、gs_joinclusterコマンドを用いてノードを組み込めます。ノード組込みにより、自律的にパーティションの再配置が行われノードのデータ、負荷バランスが調整されます。
このように単一故障の場合には、リカバリのための事前の準備は不要ですが、シングル構成で運用する場合や、クラスタ構成においても複数の障害が重なった場合にはリカバリの操作が必要です。
クラウド環境で稼働させる場合、物理的なディスクの障害やプロセッサ障害で意図せずともクラスタを構成する複数ノードの障害、複数ノードでのデータベース障害といった多重障害となるケースがあります。
4.6.1 障害の種類と処置
発生する障害と対処方法の概要を以下の表に示します。
ノード障害とは、プロセッサ障害やGridDBのサーバプロセスのエラーによりノードが停止した状況、データベース障害とは、ディスクに配置したデータベースへのアクセスでエラーが発生した状況を指します。
| GridDBの構成 | 障害の種類 | 動作と処置 |
|---|---|---|
| シングル構成 | ノード障害 | アプリケーションからアクセスはできなくなりますが、ノードの障害要因を |
| 取り除き再起動するだけで処理が完了したトランザクションのデータは | ||
| リカバリされます。ノード障害が長期化した際は、別ノードでのリカバリを | ||
| 検討します。 | ||
| シングル構成 | データベース障害 | アプリケーションでエラーを検出するため、バックアップしたデータから |
| データベースファイルを復旧します。バックアップ時点に復旧されます。 | ||
| クラスタ構成 | 単一ノード障害 | アプリケーションにはエラーが隠ぺいされ、レプリカのあるノードで処理が |
| 継続できます。障害が発生したノードでのリカバリ操作は不要です。 | ||
| クラスタ構成 | 複数ノード障害 | レプリカのオーナ/バックアップの双方のパーティションが障害対象ノード |
| に存在する場合、対象パーティションにアクセスができませんが、クラスタ | ||
| は正常に稼働します。ノードの障害要因を取り除き再起動するだけで処理が | ||
| 完了したトランザクションのデータはリカバリされます。ノードの障害が | ||
| 長期化する場合は別ノードでのリカバリを検討します。 | ||
| クラスタ構成 | 単一データベース障害 | 単一ノードでのデータベース障害は、クラスタを構成する他のノードで |
| データアクセスが継続するため、異なるディスクにデータベース配置先を | ||
| 変更し、ノードを再起動するだけでリカバリされます。 | ||
| クラスタ構成 | 複数データベース障害 | レプリカで復旧できないパーティションは最新のバックアップデータから |
| バックアップ採取時点にリカバリさせる必要があります。 |
4.6.2 クライアントフェイルオーバー
クラスタ構成で運用している際にノード障害が発生した場合、障害ノードに配置されているパーティション(コンテナ)にはアクセスできません。この時、クライアントAPI内で自動的にバックアップノードに接続し直し処理を継続するクライアントフェイルオーバー機能が動作します。クライアントAPI内で自動的に障害対策を行うため、アプリケーション開発者はノードのエラー処理を意識する必要がありません。
しかし、複数のノードの同時障害やネットワーク障害などにより、アプリケーション操作対象にアクセスできずエラーになることもあります。
エラー発生後のリカバリではアクセス対象のデータに応じて以下の点を考慮する必要があります。
- 時系列コンテナやロウキーが定義されているコレクションの場合失敗した操作またはトランザクションを再実行すればリカバリできます。
- ロウキーが定義されていないコレクションの場合DBの内容チェックをした上で、再実行する必要があります。
【メモ】
アプリケーションでのエラー処理を単純化するために、コレクションを使う場合はロウキーの定義を推奨します。単一のカラム値での一意化ができない場合で、複数のカラム値で一意化できる場合は、複数カラムの値を連結した値を持つカラムをロウキーにし、データの一意に識別できるようにすることを推奨します。
4.6.3 バックアップの種類
データベース障害やアプリケーションの誤動作によるデータ破壊に備えるために、定期的なバックアップの採取が必要です。バックアップ運用は、サービスレベルの要求やシステムのリソースに応じて対処方法を選択する必要があります。
GridDBの提供するバックアップの種類には以下のものがあります。利用するバックアップの種類に応じて復旧できる時点が異なります。
| バックアップ種別 | バックアップの動作 | 復旧時点 |
|---|---|---|
| フルバックアップ | 現在利用中のデータベースをノード定義ファイルで指定したバックアップディレクトリにオンラインでバックアップします。 | フルバックアップ採取時点 |
| 差分・増分バックアップ | 現在利用中のデータベースをノード定義ファイルで指定したバックアップディレクトリにオンラインでバックアップし、以降のバックアップでは、バックアップ後の更新ブロックの差分増分のみをバックアップします。 | 差分増分バックアップ採取時点 |
| 自動ログバックアップ | 現在利用中のデータベースをオンラインで指定したディレクトリにバックアップするとともに、トランザクションログファイルの書き込みと同じタイミングでトランザクションログも自動で採取します。トランザクションログファイルの書き込みタイミングは、ノード定義ファイルの/dataStore/logWriteModeの値に従います。 | 最新トランザクションの更新時点 |
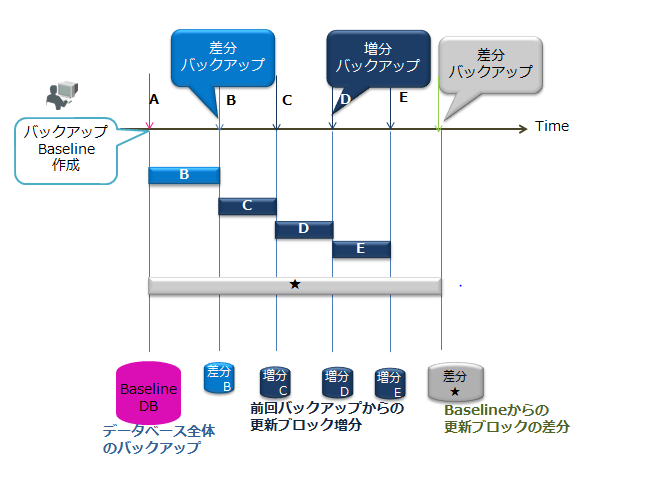
差分・増分バックアップ
バックアップの具体的な採取方法や、発生した障害に対するリカバリ方法については、『GridDB バックアップガイド』(GridDB_BackupGuide.html)を参照ください。
4.6.4 イベントログ機能
イベントログは、GridDBノード内部で発生した例外などのイベント情報に関するメッセージやシステム稼働情報を記録するログです。
イベントログは、環境変数GS_LOGで示すディレクトリにgridstore-%Y%m%d-n.logというファイル名で作成されます(例: gridstore-20150328-5.log)。ファイルはノードの再起動もしくはログ出力サイズが一定量を超えた場合に切り替わります。
イベントログの出力形式は以下です。
-
(日付時刻) (ホスト名) (スレッド番号) (ログレベル) (カテゴリ) [(エラー・トレース番号):(エラー・トレース番号名)](メッセージ) <(base64詳細情報: サポートサービスにて問題点分析用の詳細情報)>
エラー・トレース番号名で発生した事象のが概要が判ります。また、エラー・トレース番号を用いてトラブルシューティングガイドで問題点への対策を検索できます。以下にイベントログの出力例を示します。
2014-11-12T10:35:29.746+0900 TSOL1234 8456 ERROR TRANSACTION_SERVICE [10008:TXN_CLUSTER_NOT_SERVICING] (nd={clientId=2, address=127.0.0.1:52719}, pId=0, eventType=CONNECT, stmtId=1) <Z3JpZF9zdG9yZS9zZXJ2ZXIvdHJhbnNhY3Rpb25fc2VydmljZS5jcHAgQ29ubmVjdEhhbmRsZXI6OmhhbmRsZUVycm9yIGxpbmU9MTg2MSA6IGJ5IERlbnlFeGNlcHRpb24gZ3JpZF9zdG9yZS9zZXJ2ZXIvdHJhbnNhY3Rpb25fc2VydmljZS5jcHAgU3RhdGVtZW50SGFuZGxlcjo6Y2hlY2tFeGVjdXRhYmxlIGxpbmU9NjExIGNvZGU9MTAwMDg=>
イベントログの出力レベルはgs_logconfコマンドを用いてオンラインで変更できます。障害情報の詳細を分析する際には、オンラインで変更します。ただし、オンラインでの変更は一時的なメモリ上での変更のため、ノードの再起動でも設定を有効とするような恒久的設定にするには、クラスタを構成する各ノードのノード定義ファイルのtrace項目を設定する必要があります。
イベントログの出力の初期設定は以下です。設定状況はgs_logconfコマンドで確認できます。
$ gs_logconf -u admin/admin
{
"levels": {
"CHECKPOINT_FILE": "ERROR",
"CHECKPOINT_SERVICE": "INFO",
"CHUNK_MANAGER": "ERROR",
"CHUNK_MANAGER_IODETAIL": "ERROR",
"CLUSTER_OPERATION": "INFO",
"CLUSTER_SERVICE": "ERROR",
"COLLECTION": "ERROR",
"DATA_STORE": "ERROR",
"DEFAULT": "ERROR",
"EVENT_ENGINE": "WARNING",
"IO_MONITOR": "WARNING",
"LOG_MANAGER": "WARNING",
"MAIN": "WARNING",
"MESSAGE_LOG_TEST": "ERROR",
"OBJECT_MANAGER": "ERROR",
"RECOVERY_MANAGER": "INFO",
"REPLICATION_TIMEOUT": "WARNING",
"SESSION_TIMEOUT": "WARNING",
"SYNC_SERVICE": "ERROR",
"SYSTEM": "UNKNOWN",
"SYSTEM_SERVICE": "INFO",
"TIME_SERIES": "ERROR",
"TRANSACTION_MANAGER": "ERROR",
"TRANSACTION_SERVICE": "ERROR",
"TRANSACTION_TIMEOUT": "WARNING",
"TRIGGER_SERVICE": "ERROR"
}
}
4.7 データアクセス
GridDBのデータにアクセスするには、GridDB SEのクライアントAPI(Java、C言語)もしくはGridDB AEの場合はJDBCやODBCを用いてアプリケーションを開発する必要があります。データアクセスでは、コンテナやテーブルがクラスタデータベースのどこに配置されているかの位置情報を意識する必要はなく、GridDBのクラスタデータベースに接続するだけでアクセスができます。コンテナがクラスタを構成するどのノードに配置されているのかをアプリケーションシステムが意識する必要はありません。
GridDBのAPIでは、クラスタデータベースへの初期接続時、ノード情報(パーティション)とともにコンテナの配置ヒント情報をクライアント側に保持(キャッシュ)します。
アプリケーションが利用するコンテナが切り替わる度に配置されているノードを探す処理のためクラスタにアクセスする必要はなく、コンテナを保持するノードに直に接続して処理をするため、通信のオーバヘッドを最小限としています。
GridDBではリバランス処理により、コンテナ配置は動的に変わりますが、クライアントキャッシュは定期的に更新されるため、コンテナの位置は透過です。たとえ定期的な更新とリバランスのタイミングがずれや障害によりクライアントからのアクセスでノードがミスヒットした時でも、自動的に再配置情報を取得して処理を継続します。
4.7.1 TQL とSQL
データベースのアクセス言語として、GridDB SEではTQLを、GridDB AEではSQL-92準拠のSQLをサポートしています。
-
TQLとは
GridDB SEのために用意した簡易SQLです。サポート範囲は限定されており、コンテナを単位として検索、集計演算などの機能をサポートします。TQLはGridDB SEのクライアントAPI(Java、C言語)を用いて利用します。
-
SQLとは
ISOで言語仕様の標準化が行われており、GridDBではSQL-92に準拠したデータの操作や定義を行うための、インターフェイスをサポートします。SQLはGridDB AEのODBC/JDBCを用いて利用します。
TQLの詳細は『GridDB APIリファレンス』(GridDB_API_Reference.html)、SQLの詳細は『GridDB Advanced Edition SQLリファレンス』(GridDB_AE_SQL_Reference.pdf)を参照ください。
4.7.2 API
GridDBの提供するAPIのうち特徴的な機能を説明します。NoSQL I/Fでは、時々刻々発生するイベント情報を高速に処理するためのインターフェイスを用意しています。
大量に発生するイベントを発生の都度データベースサーバに送信していると、ネットワークへの負荷が高くなりシステムのスループットがあがりません。通信回線帯域が狭い場合特に顕著な影響がでます。NoSQL I/Fでは複数のコンテナに対する複数のROWの登録や、複数のコンテナへの複数の問い合わせ(TQL)を1リクエストで処理するためのマルチ処理が用意されています。頻繁にデータベースサーバにアクセスしないため、システム全体のスループットがあがります。
以下に例を挙げます。
-
マルチプット(multiput)
複数のセンサのイベント情報をデータベースに登録する処理として、センサ名毎にコンテナを用意します。センサ名とセンサの時系列イベントのロウ配列を作り、複数のセンサ分まとめたリスト(Map)を作成します。このリストデータを1回のAPI呼び出しでGridDBのデータベースに登録します。
マルチ登録処理のAPIでは、複数クラスタからなるGridDBのノードに対して、1個以上のコンテナをまとめて要求を行うことで通信処理を効率化します。また、マルチ登録処理では、トランザクション実行時のMVCCは行わず、高速に処理します。
multiputでは、トランザクションのコミットは、autocommitとなります。1件単位にデータが確定されます。
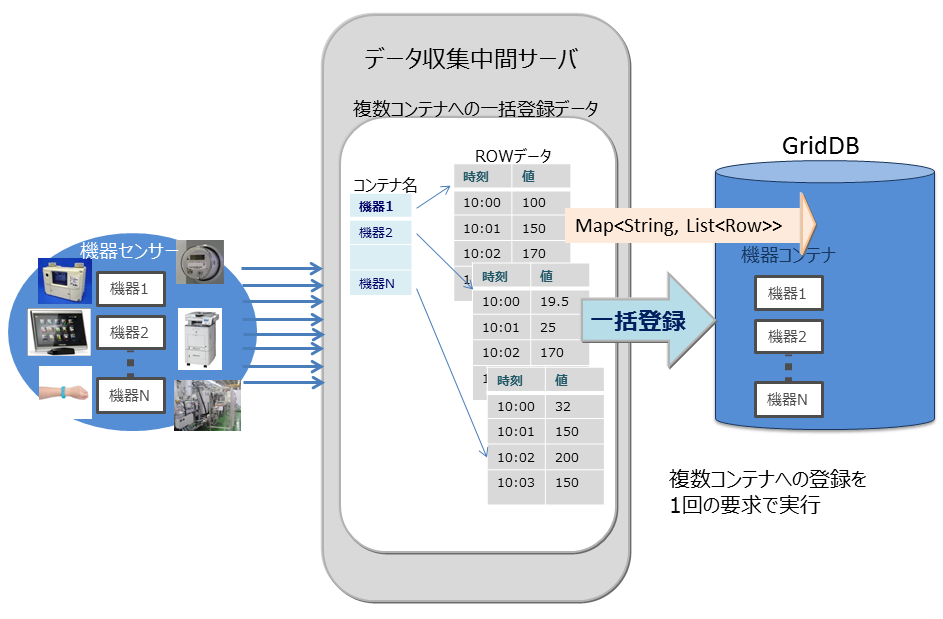
multiput処理
-
マルチクエリ(fetchAll)
センサのイベント情報を集計する処理などでセンサへのクエリ問い合わせを複数実行するのではなく、1つの問い合わせで実行することができます。たとえば、センサから取得したデータの一日の最大値、最小値、平均値などの集計結果の取得や、最大値や最小値をもつロウ集合や特定の条件に合致するロウ集合といったロウ集合のデータ取得を最適化します。
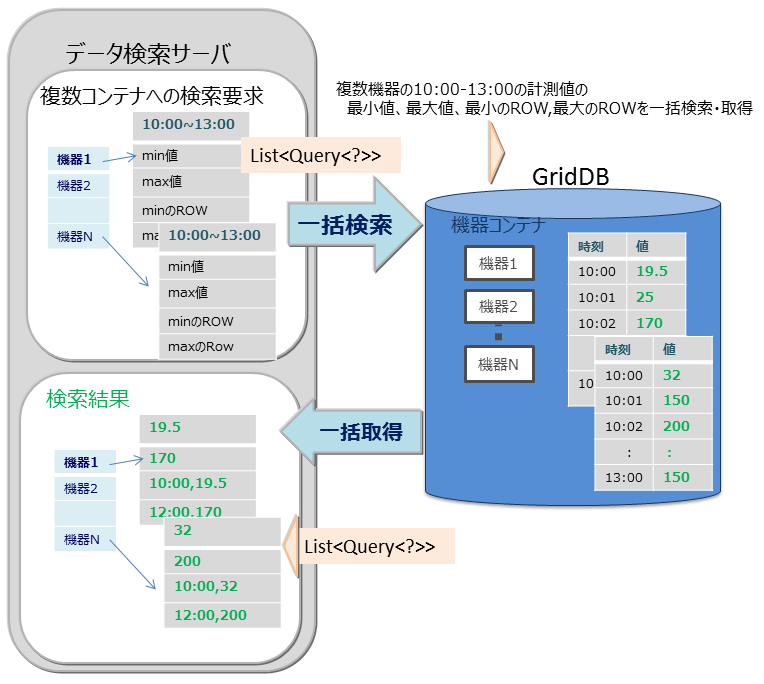
fetchAll処理
-
マルチゲット(multiget)
センサのイベント情報を取得する処理などで複数機器のRowkeyを指定した一括データ取得ができます。RowKeyPredicateオブジェクトにデータ取得の条件を設定し、複数の機器のデータを一括で取得します。
RowKeyPredicateオブジェクトでは以下の2形式のいずれかで取得条件を設定します。
- 取得範囲の指定
- 指定した個別の値
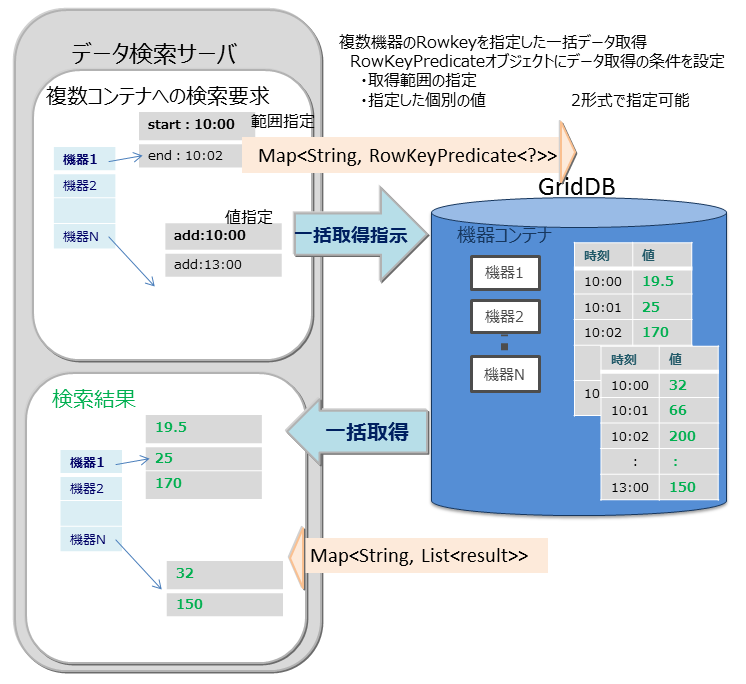
multiget処理
4.8 運用機能
GridDBの運用機能には以下の機能があります。本節では機能の概要を説明します。運用機能の詳細は『GridDB 運用管理ガイド』(GridDB_OperationGuide.html)を参照ください。
4.8.1 サービス制御
OSの起動と同時にGridDBをサービスを動作させるサービス制御機能があります。
GridDBのサービスは、RPMでインストール直後からサービスが有効となっています。サービスが有効となっているため、OS起動と同時にGridDBのサーバが起動され、OS停止時はサーバが停止されます。
OSの監視やデータベースソフトウェアの動作を含めたミドルウェアやアプリケーションの運用を統合化したインターフェイスを用いる場合、サービス制御の機能を用いるのかもしくは運用コマンドを利用するのか、サービスの起動停止の他MWとの依存性も検討する必要があります。
初期状態のGridDBサービスは以下のとおり、OSのランレベル3,4,5で動作します。
# /sbin/chkconfig --list|grep gridstore gridstore 0:off 1:off 2:off 3:on 4:on 5:on 6:off
サービス実行時のパラメータについては、運用管理ガイドを参照して設定してください。
なお、サービス制御を用いない場合、以下のようにすべてのランレベルでサービスを無効にします。
# /sbin/chkconfig gridstore off
4.8.2 運用コマンド
GridDBの運用動作を指示するコマンドには以下があります。GridDBの運用コマンドはすべてgs_で始まります。
| 種類 | コマンド | 機能 |
|---|---|---|
| ノード操作 | gs_startnode | ノードの起動 |
| gs_stopnode | ノードの停止 | |
| クラスタ操作 | gs_joincluster | クラスタを構成する際に使用。指定ノードをクラスタ構成へ参加させる |
| gs_leavecluster | メンテナンス等でクラスタから特定ノードを切り離す際に利用。切り離したノードに配置されているパーティションは再配置(リバランス)される | |
| gs_stopcluster | クラスタを構成する全ノードをクラスタから切り離す。全ノードを停止する際に利用する。ノード切り離しに伴うパーティションのリバランスは発生しない | |
| gs_config | クラスタを構成するノードの情報を取得 | |
| gs_stat | ノードやクラスタの稼働情報や性能情報を情報取得 | |
| gs_appendcluster | STABLE状態のクラスタに対してノードを増設する際に利用 | |
| gs_failovercluster | クラスタのフェイルオーバーを手動で通知する。データロストを許容してサービスを開始する際にも利用 | |
| gs_partition | パーティションのクラスタ内での配置(マスタ/バックアップ)情報や更新情報を取得 | |
| 管理ユーザ操作 | gs_adduser | 管理ユーザの登録 |
| gs_deluser | 管理ユーザの削除 | |
| gs_passwd | 管理ユーザのパスワードの変更 | |
| ログ情報 | gs_logs | ノードのメモリに保持する最新のログ情報の表示 |
| gs_logconf | イベントログ出力レベル表示と変更 | |
| バックアップ/リストア | gs_backup | バックアップの取得指示 |
| gs_backuplist | バックアップデータ確認 | |
| gs_restore | バックアップデータのリストア | |
| インポート/エクスポート | gs_import | ディスクに保持しているコンテナやデータベースのexportデータを指定インポート |
| gs_export | コンテナやデータベースを指定して、ディスク上にデータをCSV形式またはzip形式でエクスポート | |
| 保守 | gs_paramconf | 稼働パラメータ表示とパラメータのオンライン変更。変更はメモリ制限の2つのみ。 |
4.8.3 統合運用管理機能
統合運用管理機能(gs_admin)はGridDBのクラスタ運用機能を統合したWebアプリケーションです。gs_adminは直観的なインターフェイスで、クラスタの稼働情報を1画面で把握すること(ダッシュボード画面)やクラスタを構成する個々のノードへの起動停止操作や性能情報の確認などができます。
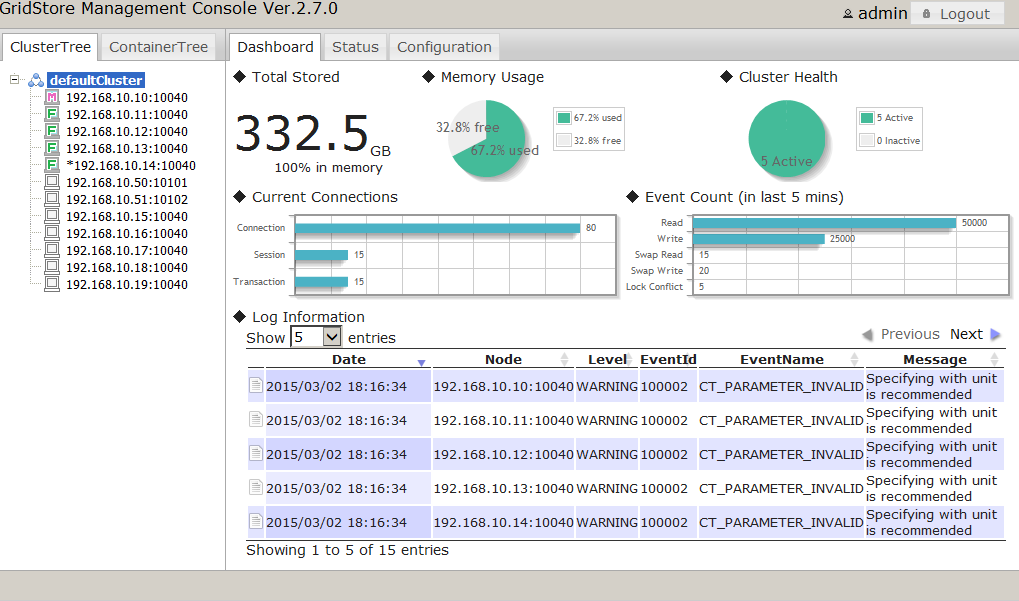
gs_admin ダッシュボード画面
gs_adminは、上記運用操作とともに、開発を支援する以下の機能もサポートしておりシステムの開発段階でも有効に利用できます。
- データベースの作成・削除、ユーザの割り当て
- コンテナの作成・削除・検索
- 索引やトリガの作成・削除
- コンテナ内データのTQLでの検索
- SQLの実行
4.8.4 gs_sh
GridDBのクラスタ操作やデータ操作のためのコマンドラインインターフェイスです。運用コマンドが個別のノードに対して操作するのに対して、クラスタを構成するノードに一括した処理を行なうインターフェイスを提供しています。また、ユーザ管理操作に加え、データベース、コンテナやテーブルの作成、TQLやSQLにより検索などのデータ操作も提供します。
gs_shは、対話形式でサブコマンドを指定して処理を実行する起動方法と、一連の操作をサブコマンドで記載したスクリプトファイルをバッチで実行する動作の2つの起動方法があります。バッチスクリプトを利用することで、システム構築の省力化や開発時の動作検証の自動化などができます。
gs_shでは独自の変数定義機能を持っており、ノードやクラスタへの操作も予め変数定義した操作対象への指示で実行できます。
//対話形式 $ gs_sh //サブコマンド「version」の実行 gs> version //バッチ形式 コマンドの引数にサブコマンドを記載したファイルを指定する $gs_sh test.gsh
サブコマンドでは以下の操作ができます。
| 種類 | サブコマンド | 機能 | 補足 |
|---|---|---|---|
| ノード操作 | startnode | [起動] ノードの起動。クラスタを構成する全ノードを一括起動し、起動完了の待ち合わせも可能 | |
| stopnode | [停止] ノードの停止。クラスタを構成する全ノードを一括停止ができる | ||
| クラスタ操作 | joincluster | [参加] クラスタ構成への参加。クラスタを構成する全ノードを一括でクラスタへ参加させる | |
| leavecluster | [離脱] クラスタ構成から、指定したノードを離脱 | ||
| stopcluster | [離脱] クラスタを構成する全ノードをクラスタから離脱 | ||
| config | [表示] 指定したノードの保持するクラスタ構成情報取得 | ||
| configcluster | [表示] クラスタ全体の構成情報を取得 | ||
| appendcluster | [追加] STABLEな状態なクラスタクラスタへのノード増設 | ||
| ログ情報 | logs | [表示] 指定ノードのログの表示 | |
| logconf | [変更] 指定ノードのメッセージログ出力レベル変更 | ||
| 接続 | connect | [接続] クラスタ、データベースへの接続 GridDB AEの場合、NoSQL I/FとNewSQL I/Fの2種類の接続を保持し、TQL,SQLの双方が利用可能 | |
| disconnect | [切断] クラスタから切断 | ||
| データベース管理 | createdatabase | [作成] データベースの作成 | |
| dropdatabase | [削除] データベースの削除 | ||
| getcurrentdatabase | [表示] カレントDB名表示 | ||
| showdatabase | [表示] データベースとアクセスできる一般ユーザの表示 | ||
| 一般ユーザ管理 | createuser | [作成] 一般ユーザの作成 | |
| dropuser | [削除] 一般ユーザの削除 | ||
| setpassword | [変更] 一般ユーザのパスワード変更 本人での変更および管理者は一般ユーザを指定して変更可能 | ||
| showuser | [表示] 一般ユーザを表示 | ||
| アクセス権 | grant | [設定] データベースにアクセスできる一般ユーザを割り当てる | |
| revoke | [剥奪] データベースにアクセスできる一般ユーザの権限を剥奪 | ||
| - | [表示] | アクセス権のデータベースへの付与状況の情報表示は、showdatabaseを用いる | |
| コンテナ | createcontainer | [作成] コンテナをあらかじめスキーマ定義したjsonファイルを用いて作成 | |
| createcollection | [作成] コレクションを作成 ただし、スキーマが限定される。 | 簡易スキーマのみ対応 複雑なスキーマはcreatecontainerを利用する | |
| createtimeseries | [作成] 時系列コンテナを作成 ただし、スキーマが限定される。 | ||
| dropcontainer | [削除] コンテナを削除 | ||
| showcontainer | [表示] コンテナの一覧を表示 | ||
| テーブル【GridDB AEのみ】 | showtable | [表示] テーブルを表示する 作成・削除はSQLで実施 | |
| 索引 | createindex | [作成] コンテナのカラムを指定してインデックスを作成 | |
| dropindex | [削除] | ||
| - | [表示] コンテナ表示に含まれる | ||
| トリガ | - | [作成] | コンテナ作成時にJSONにトリガ情報を記載する |
| droptrigger | [削除] コンテナから指定したトリガ名のトリガを削除 | ||
| showtrigger | [表示] コンテナに設定されたトリガの情報 | ||
| 検索 | tql | [実行 ] TQL文でNoSQLデータ(コレクションと時系列コンテナ)を検索 | connectでNoSQL I/Fに接続できているときのみ動作可能 |
| get/getnoprint | [取得] TQLおよびSQLの結果取得 取得件数を指定する | ||
| tqlexplain | [取得] TQLの実行計画取得 | ||
| sql【GridDB AEのみ】 | [実行]SQL文実行 | ||
| ログ情報 | logs | [表示]ノードのメモリに保持する最新のログ情報の表示 | |
| logconf | [変更]イベントログ出力レベル表示と変更 | ||
| 複合操作 | getcsv | [出力] TQLおよびSQLの検索結果のファイル出力 |
4.8.5 性能・統計情報
GridDBの性能・統計情報は、運用コマンドのgs_statを利用して確認できます。gs_statはクラスタで共通の情報とノード独自の性能情報・統計情報を表示します。
gs_statコマンドでの出力のうち、performance構造が、性能・統計情報に関連する項目です。
-bash-4.1$ gs_stat -u admin/admin -s 192.168.0.1:10040
{
:
"performance": {
"batchFree": 0,
"checkpointFileSize": 65536,
"checkpointFileUsageRate": 0,
"checkpointMemory": 2031616,
"checkpointMemoryLimit": 1073741824,
"checkpointWriteSize": 0,
"checkpointWriteTime": 0,
"currentTime": 1428024628904,
"numConnection": 0,
"numTxn": 0,
"peakProcessMemory": 42270720,
"processMemory": 42270720,
"recoveryReadSize": 65536,
"recoveryReadTime": 0,
"storeDetail": {
"batchFreeMapData": {
"storeMemory": 0,
"storeUse": 0,
"swapRead": 0,
"swapWrite": 0
},
"batchFreeRowData": {
"storeMemory": 0,
"storeUse": 0,
"swapRead": 0,
"swapWrite": 0
},
"mapData": {
"storeMemory": 0,
"storeUse": 0,
"swapRead": 0,
"swapWrite": 0
},
"metaData": {
"storeMemory": 0,
"storeUse": 0,
"swapRead": 0,
"swapWrite": 0
},
"rowData": {
"storeMemory": 0,
"storeUse": 0,
"swapRead": 0,
"swapWrite": 0
}
},
"storeMemory": 0,
"storeMemoryLimit": 1073741824,
"storeTotalUse": 0,
"swapRead": 0,
"swapReadSize": 0,
"swapReadTime": 0,
"swapWrite": 0,
"swapWriteSize": 0,
"swapWriteTime": 0,
"syncReadSize": 0,
"syncReadTime": 0,
"totalLockConflictCount": 0,
"totalReadOperation": 0,
"totalRowRead": 0,
"totalRowWrite": 0,
"totalWriteOperation": 0
},
:
}
性能・統計情報に関連する情報を説明します。storeDetail構造は、内部のデバッグ情報のため説明は省きます。
-
種別は以下を示します
- CC:クラスタ全体の現在の値
- c:指定ノードの現在の値
- CS:クラスタ全体のサービス開始後の累積値
- s:ノード全体のサービス開始後の累積値
- CP:クラスタ全体のサービス開始後のピーク値
- p:ノード全体のサービス開始後のピーク値
-
監視すべき事象数値を確認し、運用を継続するにあたり検討すべき項目を示します。
出力パラメータ 種別 説明 監視すべき事象 checkpointFileSize c チェックポイントファイルサイズ(バイト) checkpointFileUsageRate c チェックポイントファイル利用率 checkpointMemory c チェックポイント用checkpointメモリ量(バイト) checkpointMemoryLimit c チェックポイント用checkpointMemoryLimit設定(バイト) checkpointWriteSize s チェックポイント処理CPファイルライトサイズ(バイト) checkpointWriteTime s チェックポイント処理CPファイルライト時間 currentTime c 現在時刻 numConnection c 現在のコネクション数。トランザクション処理で使用している接続数であり、クラスタ処理で使用している接続数は 含まれない。クライアントの数+保有するパーティション*レプリカ数 の値となる。 ログの監視でコネクション不足が発生している場合はノード構成のconnectionLimitの値を見直します。 numSession c 現在のセッション数 numTxn c 現在のトランザクション数 peakProcessMemory p プロセス最大使用メモリ量(バイト) storememoryの値を含め、GridDBサーバの利用 したメモリのピーク値 peakProcessMemory、processMemoryがノードの実装メモリより大きくOSのスワップが発生している場合、メモリの追加や一時的に storememoryLimitの値を下げるなどの検討が必要 processMemory c プロセス使用メモリ量(バイト) recoveryReadSize s リカバリ処理でチェックポイントファイルを読み込んだサイズ(バイト) recoveryReadTime s リカバリ処理でチェックポイントファイルを読み込んだ時間 storeMemory c インメモリデータベースでの使用メモリ量(バイト) storeMemoryLimit c インメモリデータベースでの使用メモリ量制限(バイト) storeTotalUse c データベースファイル内のデータ容量を含めたノードが保有する全データ容量(バイト) swapRead s スワップリード発生回数 swapReadSize s スワップ処理ファイルリードサイズ(バイト) swapReadTime s スワップ処理ファイルリード時間 swapWrite s スワップライト発生回数 swapWriteSize s スワップ処理ファイルライトサイズ(バイト) swapWriteTime s スワップ処理ファイルライト時間 syncReadSize s 同期処理CPファイルリードサイズ(バイト) syncReadTime s 同期処理CPファイルリード時間 totalLockConflictCount s ロウロック競合発生回数 totalReadOperation s 検索処理回数 totalRowRead s 登録更新処理回数 totalRowWrite s ロウ読み出し回数 totalWriteOperation s ロウ書き込み回数
5 パラメータ
GridDBの動作を制御するパラメータについて説明します。GridDBのパラメータにはノードの設定情報や利用できるリソースなどの設定を行うノード定義ファイルとクラスタの動作設定を行うクラスタ定義ファイルがあります。定義ファイルの項目名と初期状態での設定値とパラメータの意味を説明します。
設定値の単位は以下のように指定します。
- バイトサイズは、次の単位を指定可能: TB、GB、MB、KB、B、T、G、M、K、またはこれらの小文字表記。特に記載のない限り、単位の省略はできません。
- 時間は、次の単位を指定可能: h、min、s、ms。特に記載のない限り、単位の省略はできません。
5.1 クラスタ定義ファイル(gs_cluster.json)
クラスタ定義ファイルは、クラスタを構成する全ノードで同一の設定にしておく必要があります。partitionNum,storeBlockSizeパラメータはデータベースの構造を決める重要なパラメータのため、システム構築後にGridDBを起動後は値の変更ができません。
クラスタ名は、V2.7より必須設定のパラメータとなっています。
■/var/lib/gridstore/conf/gs_cluster.json (初期状態)
{
"dataStore":{
"partitionNum":128,
"storeBlockSize":"64k"
},
"cluster":{
"clusterName":"",
"replicationNum":2,
"notificationAddress":"239.0.0.1",
"notificationPort":20000,
"notificationInterval":"5s",
"heartbeatInterval":"5s",
"loadbalanceCheckInterval":"180s"
},
"sync":{
"timeoutInterval":"30s"
},
"transaction":{
"notificationAddress":"239.0.0.1",
"notificationPort":31999,
"notificationInterval":"5s",
"replicationMode":0,
"replicationTimeoutInterval":"10s"
},
"sql":{ //NewSQL I/F のみ
"notificationAddress":"239.0.0.1", //NewSQL I/F のみ
"notificationPort":41999, //NewSQL I/F のみ
"notificationInterval":"5s" //NewSQL I/F のみ
}
}
クラスタ定義ファイルの各設定項目の意味を以下に説明します。
初期状態で含まれていない項目も項目名を追加することでシステムに認識させることができます。変更の欄ではパラメータの変更可否と変更タイミングを示します
- 変更不可 :ノードを一度起動したのちは変更はできません。変更したい場合データベースを初期化する必要があります。
- 起動 :クラスタを構成する全ノードを再起動することで、変更できます。
- オンライン:オンライン稼働中にパラメータを変更できます。ただし、変更内容は永続化されないため、定義ファイルの内容を手動で変更する必要があります。
| GridDBの構成 | 初期値 | パラメータの意味 と 制限値 | 変更 |
|---|---|---|---|
| /notificationAddress | 239.0.0.1 | マルチキャストアドレスの標準設定です。cluster,transactionの同じ名前のパラメータが省略された場合本設定が有効になります。異なる値が設定されている場合、個別設定のアドレスが有効です。 | 起動 |
| /dataStore/partitionNum | 128 | パーティション数を構成するクラスタ台数で分割配置できる公倍数で指定します。 整数: 1以上、10000以下で指定します。 | 変更不可 |
| /dataStore/storeBlockSize | 64KB | ディスクI/Oのサイズを指定します。64KB、1MBのどちらかが指定できます。 データの発生頻度を想定し、設定します。サーバ起動後は変更できません。 | 変更不可 |
| /cluster/clusterName | なし | クラスタを識別するための名称を指定します。必須入力のパラメータです。 | 起動 |
| /cluster/replicationNum | 2 | レプリカ数。レプリカ数が2の場合、パーティションが2重化。 | 起動 |
| /cluster/notificationAddress | 239.0.0.1 | クラスタ構成用マルチキャストアドレス | 起動 |
| /cluster/notificationPort | 20000 | クラスタ構成用マルチキャストポート ポート番号として指定可能な範囲の値を指定します。 | 起動 |
| /cluster/notificationInterval | 5秒 | クラスタ構成用マルチキャスト周期 1s以上、2^31s未満の値を指定します。 | 起動 |
| /cluster/heartbeatInterval | 5秒 | クラスタ間でのノードの生存確認チェック周期(ハートビート周期) 1s以上、2^31s未満の値を指定します。 | 起動 |
| /cluster/loadbalanceCheckInterval | 180秒 | クラスタを構成するノード間の負荷バランス調整のため、バランス処理を実施するか否かのデータ採取周期 1s以上、2^31s未満、単位省略時は秒 | 起動 |
| /cluster/notificationMember | なし | クラスタ構成方式を固定リスト方式にする際に、アドレスリストを指定します。 | 起動 |
| /cluster/notificationProvider/url | なし | クラスタ構成方式をプロバイダ方式にする際に、アドレスプロバイダのURLを指定します。 | 起動 |
| /cluster/notificationProvider/updateInterval | 5秒 | アドレスプロバイダからリストを取得する間隔を指定します。1s以上、2^31s未満の値を指定します。 | 起動 |
| /sync/timeoutInterval | 30秒 | クラスタ間のデータ同期時のタイムアウト時間 タイムアウトが発生した場合、システムの負荷が高い、障害発生などの可能性があります。 1s以上、2^31s未満の値を指定します。 | 起動 |
| /transaction/notificationAddress | 239.0.0.1 | クライアントが初期に接続するマルチキャストアドレスです。クライアントにはマスタノードが通知されます。 | 起動 |
| /transaction/notificationPort | 31999 | クライアントが初期に接続するマルチキャストポートです。1s以上、2^31s未満の値を指定します。 | 起動 |
| /transaction/notificationInterval | 5秒 | クライアントへのマスタ通知用マルチキャスト周期。1s以上、2^31s未満の値を指定します。 | 起動 |
| /transaction/replicationMode | 0 | トランザクションでデータ更新時のデータの同期(レプリケーション)方法を指定します。文字列または整数で、 "ASYNC"または0(非同期)、"SEMISYNC"または1(準同期)を指定します。 | 起動 |
| /transaction/replicationTimeoutInterval | 10秒 | トランザクションが準同期レプリケーションでデータを同期する際のノード間通信のタイムアウト時間を指定します。1s以上、2^31s未満の値を指定します。 | 起動 |
| /sql/notificationAddress | 239.0.0.1 | JDBC/ODBCクライアントが初期に接続するマルチキャストアドレスです。クライアントにはマスタノードが通知されます。 | 起動 |
| /sql/notificationPort | 41999 | JDBC/ODBCクライアントが初期に接続するマルチキャストポートです。1s以上、2^31s未満の値を指定します。 | 起動 |
| /sql/notificationInterval | 5秒 | JDBC/ODBCクライアントへのマスタ通知用マルチキャスト周期。1s以上、2^31s未満の値を指定します。 | 起動 |
5.2 ノード定義ファイル(gs_node.json)
クラスタを構成するノードのリソースを初期設定します。オンライン運用では、配置されているリソース、アクセス頻度などから、オンラインで値を変更できるパラメータもあります。逆に一度設定すると変更できない値(concurrency)もありますので注意してください。
■/var/lib/gridstore/conf/gs_node.json (初期状態)
{
"dataStore":{
"dbPath":"data",
"backupPath":"backup",
"storeMemoryLimit":"1024MB",
"storeWarmStart":false,
"concurrency":1,
"logWriteMode":1,
"persistencyMode":"NORMAL",
"affinityGroupSize":4
},
"checkpoint":{
"checkpointInterval":"1200s",
"checkpointMemoryLimit":"1024MB",
"useParallelMode":false
},
"cluster":{
"servicePort":10010
},
"sync":{
"servicePort":10020
},
"system":{
"servicePort":10040,
"eventLogPath":"log"
},
"sql":{ //NewSQL I/F のみ
"servicePort":20001, //NewSQL I/F のみ
"connectionLimit":5000, //NewSQL I/F のみ
"concurrency":5 //NewSQL I/F のみ
},
"transaction":{
"servicePort":10001,
"connectionLimit":5000
},
"trace":{
"default":"LEVEL_ERROR",
"dataStore":"LEVEL_ERROR",
"collection":"LEVEL_ERROR",
"timeSeries":"LEVEL_ERROR",
"chunkManager":"LEVEL_ERROR",
"objectManager":"LEVEL_ERROR",
"checkpointFile":"LEVEL_ERROR",
"checkpointService":"LEVEL_INFO",
"logManager":"LEVEL_WARNING",
"clusterService":"LEVEL_ERROR",
"syncService":"LEVEL_ERROR",
"systemService":"LEVEL_INFO",
"transactionManager":"LEVEL_ERROR",
"transactionService":"LEVEL_ERROR",
"transactionTimeout":"LEVEL_WARNING",
"triggerService":"LEVEL_ERROR",
"sessionTimeout":"LEVEL_WARNING",
"replicationTimeout":"LEVEL_WARNING",
"recoveryManager":"LEVEL_INFO",
"eventEngine":"LEVEL_WARNING",
"clusterOperation":"LEVEL_INFO",
"ioMonitor":"LEVEL_WARNING"
}
}
ノード定義ファイルの各設定項目の意味を以下に説明します。
初期状態で含まれていない項目も項目名を追加することでシステムに認識させることができます。変更の欄ではパラメータの変更可否と変更タイミングを示します
- 変更不可 :ノードを一度起動したのちは変更はできません。変更したい場合データベースを初期化する必要があります。
- 起動 :クラスタを構成する全ノードを再起動することで、変更できます。
- オンライン:オンライン稼働中にパラメータを変更できます。ただし、変更内容は永続化されないため、定義ファイルの内容を手動で変更する必要があります。
ディレクトリの指定は、フルパスもしくは、GS_HOME環境変数からの相対パスで指定します。相対パスは、GS_HOMEの初期ディレクトリが基点となります。GS_HOMEの初期設定ディレクトリは、/var/lib/gridstoreです。
| GridDBの構成 | 初期値 | パラメータの意味 と 制限値 | 変更 |
|---|---|---|---|
| /serviceAddress | なし | cluster,transaction,syncの各サービスアドレスの初期値を設定。3項目のアドレスを設定せずに本アドレスの設定のみで各サービスアドレスの初期値を設定できる。 | 起動 |
| /dataStore/dbPath | data | データベースファイルの配置ディレクトリ指定をフルパスもしくは、相対パスで指定する。 | 起動 |
| /dataStore/backupPath | backup | バックアップファイル配置ディレクトリパスを指定。 | 起動 |
| /dataStore/storeMemoryLimit | 1024MB | データ管理用メモリ上限。 | オンライン |
| /dataStore/concurrency | 1 | 並列度 | 不可 |
| /dataStore/logWriteMode | 1 | ログ書き出しモード・周期 -1または0の場合トランザクション終了時にログ書き込み、1以上2^31未満の場合、秒単位の周期でログ書き込み | 起動 |
| /dataStore/persistencyMode | 1(NORMAL) | 永続化モードでは、データ更新時の更新ログファイルの保持期間を指定するものです。1(NORMAL)、2(RETAINING_ALL_LOGS) のいずれかを指定。"NORMAL" は、チェックポイントにより、不要になったトランザクションログファイルは削除されます。"RETAINING_ALL_LOGS"は、全てのトランザクションログファイルを残します。デフォルト値は"1(NORMAL)"。 | 起動 |
| /dataStore/storeWarmStart | false(無効) | 再起動時にチャンクメモリ上限までインメモリ化するかを指定。 | 起動 |
| /dataStore/affinityGroupSize | 4 | アフィニティグループ数 | 起動 |
| /dataStore/storeComperssionMode | NO_COMPRESSION | データブロック圧縮モード | 起動 |
| /checkpoint/checkpointInterval | 1200秒 | メモリ上のデータ更新ブロックを永続化するチェックポイント処理の実行周期 | 起動 |
| /checkpoint/checkpointMemoryLimit | 1024MB | チェックポイント専用書き出しメモリ上限 ※チェックポイント中に更新トランザクションがある場合に必要となるメモリ領域を上限値までプール。 | オンライン |
| /checkpoint/useParallelMode | false(無効) | チェックポイントを並列実行するかどうかを指定。※並列スレッド数は並列度(concurrency)と同じ数になります。 | 起動 |
| /checkpoint/checkpointCopyInterval | 100ms | データの更新や追加が行われたブロックをチェックポイント処理でディスクに出力する際の出力処理間隔 | 起動 |
| /cluster/serviceAddress | 上位のserviceAddressに従う | クラスタ構成用待ち受けアドレス | 起動 |
| /cluster/servicePort | 10010 | クラスタ構成用待ち受けポート | 起動 |
| /sync/serviceAddress | 上位のserviceAddressに従う | クラスタ間でデータ同期のための受信アドレスを指定。 | 起動 |
| /sync/servicePort | 10020 | データ同期用待ち受けポート | 起動 |
| /system/serviceAddress | 上位のserviceAddressに従う | 運用コマンド用待ち受けアドレス | 起動 |
| /system/servicePort | 10040 | 運用コマンド用待ち受けポート | 起動 |
| /system/eventLogPath | log | イベントログファイル配置ディレクトリパス | 起動 |
| /transaction/serviceAddress | 上位のserviceAddressに従う | トランザクション処理用待ち受けアドレス | 起動 |
| /transaction/servicePort | 10001 | トランザクション処理用待ち受けポート | 起動 |
| /transaction/connectionLimit | 5000 | トランザクション処理接続数上限 | 起動 |
| /transaction/transactionTimeoutLimit | 0秒 | トランザクションタイムアウト上限。0秒の時、タイムアウトは発生しません。 | 起動 |
| /sql/servicePort | 210001 | NewSQL I/Fアクセスの処理用待ち受けポート | 起動 |
| /sql/connectionLimit | 5000 | NewSQL I/Fアクセスの処理接続数上限 | 起動 |
| /sql/concurrency | 5 | 同時実行スレッド数 | 起動 |
6 用語一覧
GridDBで利用する用語を一覧で解説します。
| 用語 | 意味 |
|---|---|
| ノード | GridDBでデータ管理を行う個々のサーバプロセスを指します。 |
| クラスタ | 一体となってデータ管理を行う、1つ、もしくは複数のノードの集合を指します。 |
| マスタノード | クラスタ管理処理を行うノードです。 |
| フォロワノード | クラスタに参加している、マスタノード以外のノードです。 |
| 構成ノード数 | GridDBクラスタを構成するノード数を指定します。GridDBが初回に起動する際に、クラスタが成立する閾値として用いられます。(構成ノード数のノードがクラスタに参加することでクラスタサービスが開始されます。) |
| 有効ノード数 | GridDBクラスタを構成するノードの内、クラスタに組み込まれた稼働中のノードの数。 |
| ブロック | ブロックとは、ディスクへのデータ永続化処理(チェックポイントと以降よびます)のデータ単位であり、GridDBの物理的なデータ管理の最小単位です。ブロックには複数のコンテナのデータが配置されます。ブロックサイズは、定義ファイル(クラスタ定義ファイル)で、GridDB初期起動前に設定サイズを64KB/1MBのどちらかから選択しできます。システムの実装メモリが少ない場合や、データの増加頻度が低い場合は、64KBを指定します。 |
| パーティション | コンテナを配置するデータ管理の単位です。クラスタ間でのデータ配置の最小単位であり、ノード間の負荷バランスを調整するため(リバランス)や、障害発生時のデータ多重化(レプリカ)管理のためのデータ移動や複製の単位です。 |
| パーティショングループ | 複数のパーティションをまとめたグループであり、ディスクに永続化される際のファイルシステム上のデータファイルに相当します。1つのパーティショングループに1つのチェックポイントファイルが対応します。パーティショングループは、ノード定義ファイルの並列度(/dataStore/concurrency)の数分作成されます。 |
| ロウ | コンテナやテーブルに登録される1行のデータ指します。コンテナやテーブルには複数のロウが登録されます。ロウには、複数データタイプのカラムが作成されます。 |
| コンテナ | 利用者とのI/Fとなるデータ構造です。ロウの集合を管理する入れ物です。コレクションと時系列コンテナの2種類のデータタイプが存在します。 |
| コレクション | 一般の型のキーを持つロウを管理するコンテナの1種です。 |
| 時系列コンテナ | 時刻型のキーを持つロウを管理するコンテナの1種です。時系列のデータを扱う専用の機能を持ちます。 |
| テーブル | テーブルは、GridDB AEでのみ存在するコンテナの特別な形です。GridDB AEでSQLをI/Fとして操作することができます。 |
| データベースファイル | クラスタを構成するノードの保有するデータをディスクやSSDに書き込み永続化したファイル群です。データベースファイルは、チェックポイントファイルという定期的にメモリ上のデータベースが書き込まれるファイルとGridDBデータベースの更新の都度保存されるトランザクションログファイルを総称します。 |
| チェックポイントファイル | パーティショングループがディスクに書き込まれたファイルです。 ノード定義ファイルのサイクル(/checkpoint/checkpointInterval)でメモリ上の更新情報が反映されます。 |
| トランザクションログファイル | トランザクションの更新情報がログとして逐次保存されます。 |
| LSN(Log Sequence Number) | パーティションごとに割り当てられる、トランザクションでの更新時の更新ログシーケンス番号を示します。 クラスタ構成のマスタノードは、各ノードが保持している全パーティションのLSNのうちの最大数(MAXLSN)を保持しています。 |
| レプリカ | 複数のノードにパーティションを多重化配置することを指します。レプリカには更新されるマスタデータであるオーナと参照に利用されるバックアップがあります。 |
| オーナノード | パーティション内のコンテナに対して更新操作ができるノードです。複製されたコンテナのうち、マスタとなるコンテナを記録しているノードです。 |
| バックアップノード | 複製されたコンテナのうち、レプリカコンテナを記録しているノードです。 |
| 定義ファイル | クラスタを構成する際のパラメータファイル(gs_cluster.json:以降クラスタ定義ファイルと呼ぶ)とクラスタ内でのノードの動作やリソースを設定するパラメータファイル(gs_node.json:以降ノード定義ファイルと呼ぶ)の2つがあります。またGridDBの管理ユーザのユーザ定義ファイルもあります。 |
| イベントログファイル | GridDBサーバの動作ログが保管されます。エラーや警告などのメッセージが保管されます。 |
| OSユーザ(gsadm) | GridDBの運用機能を実行できる権限を持つユーザであり、GridDBインストール時にgsadmというOSのユーザが作成されます |
| 管理ユーザ | 管理ユーザは、GridDBの運用操作を行うために用意されたGridDBのユーザです。 |
| 一般ユーザ | アプリケーションシステムで利用するユーザです。 |
| ユーザ定義ファイル | 管理ユーザが登録されるファイルです。初期インストールではsystem,adminの2つの管理ユーザが登録されています。 |
| クラスタデータベース | GridDBのクラスタシステムでアクセスできるデータベース全体を総称します。 |
| データベース | クラスタデータベースに作成される、論理的なデータ管理の単位です。クラスタデータベース内にデフォルトではpublicというデータベースが作成されています。新規にデータベースを作成し、一般ユーザに利用権限をあたえることで、ユーザ毎のデータ分離が実現できます。 |
| フルバックアップ | 現在利用中のクラスタデータベースをノード定義ファイルで指定したバックアップディレクトリにオンラインでバックアップします。 |
| 差分・増分バックアップ | 現在利用中のクラスタデータベースをノード定義ファイルで指定したバックアップディレクトリにオンラインでバックアップし、以降のバックアップでは、バックアップ後の更新ブロックの差分増分のみをバックアップします。 |
| 自動ログバックアップ | 現在利用中のクラスタデータベースをオンラインで指定したディレクトリにバックアップするとともに、トランザクションログファイルの書き込みと同じタイミングでトランザクションログも自動で採取します。トランザクションログファイルの書き込みタイミングは、ノード定義ファイルの/dataStore/logWriteModeの値に従います。 |
| フェイルオーバ― | 稼働中のクラスタに障害が発生した際に、バックアップノードがその機能を自動的に引き継ぎ、処理を続行する仕組みです。 |
| クライアントフェイルオーバー | 稼働中のクラスタに障害が発生した際、クライアント側のAPIで障害時のリトライ処理としてバックアップノードに自動的に接続し直し、処理を続行する仕組みです。 |
| テーブルパーティショニング | データ登録数が多い巨大なテーブルデータを複数のノードに分散配置することで、複数ノードのメモリを有効に利用し、かつ複数ノードのプロセッサの並列実行を可能とし、巨大テーブルのアクセスを高速化するための機能 |
| データアフィニティ | コンテナ内のデータの関連の強いデータを同じブロックに配置し、データアクセスの局所化を図ることでメモリヒット率を高めるための機能です。 |
| ノードアフィニティ | 関連の強いコンテナやテーブルを同じノードに配置し、データアクセス時のネットワーク負荷を減少させるための機能です |
7 システムの制限値
| ブロックサイズ | 64KB | 1MB |
|---|---|---|
| 文字列型/空間型のデータサイズ | 31KB | 128KB |
| BLOB型のデータサイズ | 127MB | 1GB |
| 配列長 | 4000個 | 65000個 |
| カラム数 | 1024個 | 1024個 |
| 線形補完圧縮の対象カラム数 | 100個 | 100個 |
| コンテナ名のサイズ | 約16KB | 約128KB |
| カラム名のサイズ | 256Byte | 256Byte |
| パーティションサイズ | 約64TB | 約1PB |
| クラスタ名 | 64文字 | 64文字 |
| 一般ユーザ名 | 64文字 | 64文字 |
| データベース名 | 64文字 | 64文字 |
| パスワード | 64文字 | 64文字 |
| ユーザ数 | 128個 | 128個 |
| データベース数 | 128個 | 128個 |
| トリガー名のサイズ | 256Byte | 256Byte |
| トリガのURL | 4KB | 4KB |
| アフィニティグループ数 | 10000 | 10000 |
| データアフィニティ文字列の長さ | 8文字 | 8文字 |
| 解放期限付き時系列コンテナの分割数 | 160 | 160 |
| GridDBノードが管理する通信バッファのサイズ | 約2GB | 約2GB |
-
文字列型、コンテナ名、カラム名、トリガ名、トリガのURL
- 制限値はUTF-8エンコード相当
-
空間型
- 制限値は内部格納形式相当