
はじめに
電子メールのスパム分類では、ある電子メールがスパムかそうでないかを判断することがタスクとなります。これは主に件名やメッセージに含まれるキーワードによって判断されますが、簡単にはいかない場合もあり、メールの追加部分を考慮する必要があります。この問題を解決する一つの方法は、スパムメールと非スパムメールの例を収集し、機械学習モデルを訓練することです。
ここでは、4000通以上のスパム(1)、非スパム(0)のメールを含むデータセットを使用します。
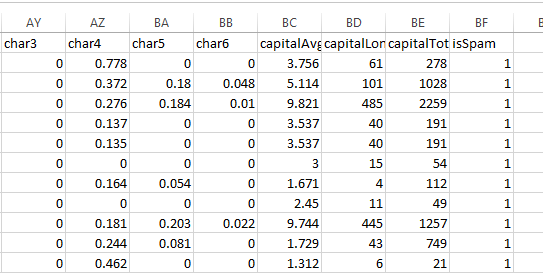
データセットはCSV形式です。各メールは、メール内の特定の単語の出現頻度を表す48個の特徴量を持ちます。6つの特徴は特定の文字の出現頻度を、3つの特徴は大文字の出現頻度を、そして最後の特徴はスパム/非スパムラベルを示すものです。電子メールはスパムか非スパムに分類されるので、これは2値分類のタスクと言えます。
バイナリ分類器を構築するために、以下のステップに従います。
ステップ1: CSVデータをGridDBに移動します。
Step 2: GridDBのデータを読み込んで、インメモリデータセットを作成します。
Step 3:バイナリ分類を行うためのニューラルネットワークモデルを作成します。
Step 4:読み込んだデータセットを用いて、ニューラルネットワークモデルの学習を行います。
Step 5:学習したモデルの性能をテストします。
各種パッケージを読み込む
まずは、使用するパッケージを読み込むことから始めましょう。
import java.io.IOException;
import java.util.Collection;
import java.util.Properties;
import java.util.Scanner;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;GridDBにデータを書き込む
CSVデータは spam.csv という名前のファイルに格納されている。このデータをGridDBコンテナに格納することが目的です。コンテナスキーマを表現する静的クラスを作成しましょう。
public static class Emails{
@RowKey String word1;
String word2,word3,word4,word5,word6,word7,word8,word9,word10,word11,word12,word13,word14,word15,word16,word17,word18,word19,word20,word21,word22,word23,word24,word25,word26,word27,word28,word29,word30,word31,word32,word33,word34,word35,word36,word37,word38,word39,word40,word41,word42,word43,word44,word45,word46,word47,word48,char1,char2,char3,char4,char5,char6,capitalAvg,capitalLongest,capitalTotal,isSpam;
}上記のクラスは、SQLのテーブルに似たGridDBコンテナを作成し、58カラムを持つようにします。
これで、GridDBインスタンスに接続できるようになりました。GridDBのインスタンスを作成し、GridDBのインストール情報を取得します。
Properties props = new Properties();
props.setProperty("notificationAddress", "239.0.0.1");
props.setProperty("notificationPort", "31999");
props.setProperty("clusterName", "defaultCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);ここでは、Emailsコンテナを選択して作業してみましょう。
Collection<String, Emails> coll = store.putCollection("col01", Emails.class);上記のコードでは、Emails コンテナのインスタンスを作成し、coll という名前を付けています。この名前は、コンテナを参照する際に使用します。
それでは、spam.csv ファイルからデータを読み込んで、GridDB に格納しましょう。
File file1 = new File("spam.csv");
Scanner sc = new Scanner(file1);
String data = sc.next();
while (sc.hasNext()){
String scData = sc.next();
String dataList[] = scData.split(",");
String word1 = dataList[0];
String word2 = dataList[1];
String word3 = dataList[2];
String word4 = dataList[3];
String word5 = dataList[4];
String word6 = dataList[5];
String word7 = dataList[6];
String word8 = dataList[7];
String word9 = dataList[8];
String word10 = dataList[9];
String word11 = dataList[10];
String word12 = dataList[11];
String word13 = dataList[12];
String word14 = dataList[13];
String word15 = dataList[14];
String word16 = dataList[15];
String word17 = dataList[16];
String word18 = dataList[17];
String word19 = dataList[18];
String word20 = dataList[19];
String word21 = dataList[20];
String word22 = dataList[21];
String word23 = dataList[22];
String word24 = dataList[23];
String word25 = dataList[24];
String word26 = dataList[25];
String word27 = dataList[26];
String word28 = dataList[27];
String word29 = dataList[28];
String word30 = dataList[29];
String word31 = dataList[30];
String word32 = dataList[31];
String word33 = dataList[32];
String word34 = dataList[33];
String word35 = dataList[34];
String word36 = dataList[35];
String word37 = dataList[36];
String word38 = dataList[37];
String word39 = dataList[38];
String word40 = dataList[39];
String word41 = dataList[40];
String word42 = dataList[41];
String word43 = dataList[42];
String word44 = dataList[43];
String word45 = dataList[44];
String word46 = dataList[45];
String word47 = dataList[46];
String word48 = dataList[47];
String char1 = dataList[48];
String char2 = dataList[49];
String char3 = dataList[50];
String char4 = dataList[51];
String char5 = dataList[52];
String char6 = dataList[53];
String capitalAvg =dataList[54];
String capitalLongest = dataList[55];
String capitalTotal = dataList[56];
String isSpam = dataList[57];
Emails emails = new Emails();
emails.word1 =word1;
emails.word2 =word2;
emails.word3 =word3;
emails.word4 =word4;
emails.word5 =word5;
emails.word6 =word6;
emails.word7 =word7;
emails.word8 =word8;
emails.word9 =word9;
emails.word10 =word10;
emails.word11 =word11;
emails.word12 =word12;
emails.word13 =word13;
emails.word14 =word14;
emails.word15 =word15;
emails.word16 =word16;
emails.word17 =word17;
emails.word18 =word18;
emails.word19 =word19;
emails.word20 =word20;
emails.word21 =word21;
emails.word22 =word22;
emails.word23 =word23;
emails.word24 =word26;
emails.word27 =word27;
emails.word28 =word28;
emails.word29 =word29;
emails.word30 =word30;
emails.word31 =word31;
emails.word32 =word32;
emails.word33 =word33;
emails.word34 =word34;
emails.word35 =word35;
emails.word36 =word36;
emails.word37 =word37;
emails.word38 =word38;
emails.word39 =word39;
emails.word41 =word41;
emails.word42 =word42;
emails.word43 =word43;
emails.word44 =word44;
emails.word45 =word45;
emails.word46 =word46;
emails.word47 =word47;
emails.word48 =word48;
emails.char1 = char1;
emails.char2 = char2;
emails.char3 = char3;
emails.char4 = char4;
emails.char5 = char5;
emails.char6 = char6;
emails.capitalAvg = capitalAvg;
emails.capitalLongest = capitalLongest;
emails.capitalTotal = capitalTotal;
emails.isSpam = isSpam;
coll.append(emails);
}emailというオブジェクトを作成し、GridDBコンテナに追加しています。
GridDBからデータを取得する
以下のコードで、GridDBからデータを取り出します。
Query<emails> query = coll.query("select *");
RowSet<emails> rs = query.fetch(false);
RowSet res = query.fetch();select *は、コンテナに格納されているすべてのデータを選択するのに役立ちます。
バイナリ分類器のビルド
まず、バイナリ分類器を構築するために必要なすべての Java ライブラリをインポートしましょう。
import deepnetts.data.DataSets;
import deepnetts.eval.Evaluators;
import deepnetts.data.norm.MaxNormalizer;
import javax.visrec.ml.eval.EvaluationMetrics;
import deepnetts.net.layers.activation.ActivationType;
import deepnetts.net.loss.LossType;
import deepnetts.net.FeedForwardNetwork;
import deepnetts.util.DeepNettsException;
import java.io.IOException;
import javax.visrec.ml.classification.BinaryClassifier;
import javax.visrec.ml.ClassificationException;
import javax.visrec.ml.data.DataSet;
import deepnetts.data.MLDataItem;
import javax.visrec.ri.ml.classification.FeedForwardNetBinaryClassifier;これで、フィードフォワードニューラルネットワークを使った2値分類器を構築することができます。以下はそのためのコードです。
DataSet emailsDataSet= DataSets(res, 57, 1, true);
// create a feed forward neural network using builder
FeedForwardNetwork nn = FeedForwardNetwork.builder()
.addInputLayer(57)
.addFullyConnectedLayer(15)
.addOutputLayer(1, ActivationType.SIGMOID)
.lossFunction(LossType.CROSS_ENTROPY)
.build();フィードフォワードニューラルネットワークは、グラフとして表現できる機械学習アルゴリズムです。
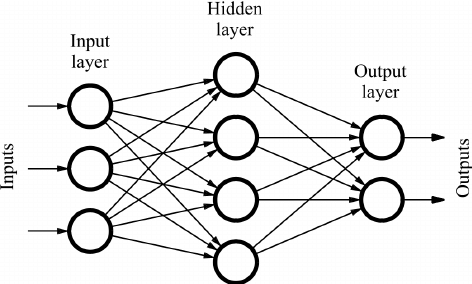
グラフの各ノードは、入力を変換するための計算を行います。各ノードは、その前のノードから受け取った入力に関数を適用し、次のノードに送信します。上のコードでは、activation関数としてsigmoidを使用しています。ノードはlayerと呼ばれるグループに編成されます。
データをトレーニングセットとテストセットに分割する
目標は、メールデータセットのサブセットを使って機械学習モデルを学習し、データセットのもう一つのサブセットを使ってモデルの精度をテストすることです。そこで、データをトレーニングセットとテストセットの2つに分割します(60%がトレーニング用、40%がテスト用)。
以下のコードで、データを2つのセットに分割することができます。
// split the data
DataSet[] trainTestData = emailsDataSet.split(0.6, 0.4);
// Normalize the data
MaxNormalizer norm = new MaxNormalizer(trainTestData[0]);
norm.normalize(trainTestData[0]); // normalize the training set
norm.normalize(trainTestData[1]); // normalize the test set
DataSet trainingSet = trainTestData[0];
DataSet testSet = trainTestData[1];なお、上記のコードでは、データを分割した後、正規化しています。
ニューラルネットワークの学習
データの学習が終わったので、いよいよニューラルネットワークのモデルを学習します。フィードフォワードニューラルネットワークは、バックプロパゲーションアルゴリズムを使用して学習させます。Deep Netts APIでは、このアルゴリズムをBackpropagation Trainerクラスで実装しています。このクラスの NeuralNetwork.getTrainer() メソッドを使用して、親ネットワークのトレーニングに使用されるトレーナーのインスタンスを作成します。また、最大エポック数(トレーニングセットを通過する回数)や学習率など、アルゴリズムのパラメータを設定します。
以下のコードを使用します。
// configure the trainer
nn.getTrainer().setMaxError(0.03f)
.setMaxEpochs(10000)
.setLearningRate(0.001f);
// start the training
nn.train(trainingSet);実行すると、このようなコードが返されます。
Epoch:1, Time:72ms, TrainError:0.66057104, TrainErrorChange:0.66057104, TrainAccuracy: 0.6289855
Epoch:2, Time:18ms, TrainError:0.6435114, TrainErrorChange:-0.017059624, TrainAccuracy: 0.65072465
Epoch:3, Time:17ms, TrainError:0.6278175, TrainErrorChange:-0.015693903, TrainAccuracy: 0.6786232
Epoch:4, Time:14ms, TrainError:0.60796565, TrainErrorChange:-0.019851863, TrainAccuracy: 0.726087
Epoch:5, Time:15ms, TrainError:0.58832765, TrainErrorChange:-0.019638002, TrainAccuracy: 0.74746376このように、モデルは各エポックの結果を返す。
分類器のテスト
新しいメールをスパムかそうでないかに分類するとき、分類器が正確な結果を与えることを確認する必要があります。そのため、テストを行う必要があります。
分類器は、モデルの学習に使用されていないテストデータを使用してテストされます。分類の正誤を計算したり、分類器を理解するための他の指標を計算したりします。
次のコードは、分類器をテストするのに役立ちます。
EvaluationMetrics metrics = Evaluators.evaluateClassifier(nn, testSet);
System.out.println(metrics);このコードでは、分類器の精度、正確さ、再現性、F1Scoreなどの指標を返します。
学習済みモデルの利用
学習した分類器を使って、新しいメールを分類する必要があります。次のコードはそのデモです。
// create a binary classifier using the trained network
BinaryClassifier bc = new FeedForwardNetBinaryClassifier(nn);
// get the test email as an array of features
float[] testEmail = testSet.get(0).getInput().getValues();
// get the probability score that the email is spam
Float output = bc.classify(testEmail);
System.out.println("Spam probability: "+output);学習したネットワークをラップするために、FeedForwardNetBinaryClassifierクラスを使用しました。BinaryClassifierはバイナリ分類器の入力を指定するためにジェネリックを使用するインターフェースで、この例ではメールの特徴量の配列になります。テストデータセットから分類するメールを、メールの特徴量の配列として渡しました。この配列は、バイナリ分類器のclassify メソッドに渡されます。
コードのコンパイルと実行
gsadmユーザでログインします。作成した.javaファイルを GridDB のbin フォルダに移動し、以下のパスに配置する。
/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin
次に、Linux端末で以下のコマンドを実行し、gridstore.jarファイルのパスを設定します。
export CLASSPATH=$CLASSPATH:/home/osboxes/Downloads/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin/gridstore.jar次に、以下のコマンドを実行して .java ファイルをコンパイルします。
javac EmailSpamFilter.java以下のコマンドを実行して生成された.classファイルを削除してください。
java EmailSpamFilterその結果、そのメールがスパムである確率を示す確率スコアが表示されます。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb