データサイエンティストたちによく使われるプログラミング言語Rは、データセットの統計解析を行うための言語です。一般的に、大規模なデータセットを分析する際には、データをバックアップする高速なデータベースを使用することが大きなメリットをもたらします。そこで、GridDBの出番となります。
このブログでは、Rで大規模なデータセットを取り込み、その状態で様々なSQLクエリを実行し、データセットからどのような情報が得られるかを見ていきます。その後に、R言語はデータのグラフ化に優れているため、gplotを使って結果をプロットしてみます。
目次
- はじめに
- データセットを選択する
- hoopRでプレイバイプレイデータを取り込む
- プレイバイプレイデータを解析する
- 分析のためのその他のアイディア
- まとめ
はじめに
このブログと同様に行うには、以下のようにレポをクローンしてください。
$ git clone -b r_analysis git@github.com:griddbnet/Project.git前提条件
以下のものが必要となります。
- GridDB
- R
- An R IDE like RStudio
操作手順
操作手順は以下の通りです。
- レポをクローンする
-
必要なライブラリーをインストールする
- install.packages(“RJDBC”,dep=TRUE)
- install.packages(“rJava”)
- install.packages(“hoopR”)
- install.packages(“nflreadr”)
- install.packages(“devtools”, dep=TRUE)
- devtools::install_github(“abresler/nbastatR”)
- install.packages(‘stringr’)
- install.packages(‘dplyr’)
- install.packages(‘ggplot2’)
- install.packages(‘lubridate’)
- install.packages(‘ggalt’)
-
Ingestのコードを実行する(
ingest.R) -
クエリコードを実行する(
query.R)
データセットを選択する
非常に大きなデータセットを選んだ方が、様々な方法を取ることができます。このブログでは、スポーツという少し変わった方向性のデータを選びました。hoopRライブラリを使用して、2002年から最新のシーズンまでのNBAの全シーズンのプレイバイプレイデータを取り込みます。今回は、すべてのシーズンを取り込む必要はないと思われたので、最新のシーズンのみを取り込み、そこから分析を行うことにしました。
hoopRでプレイバイプレイデータを取り込む
データセットを取り込むために、まず、稼働中のGridDBサーバに接続します。
JDBCでGridDBに接続する
前述したように、サーバーへの接続にはJDBCを利用することにします。幸いなことに、プログラミング言語RでJDBC経由で直接接続できるパッケージとしてRJDBCがあります。このパッケージを利用すると、JDBCの認証情報を入力するだけで、GridDBとの接続を行うことができます。接続が完了したら、DBI 接続を使用して GridDB インスタンスに sql クエリを発行することができるようになります。
接続を行うには、適切なライブラリをインポートし、GridDB JDBC file を含む認証情報を入力する必要があります。
library(RJDBC)
drv <- JDBC("com.toshiba.mwcloud.gs.sql.Driver",
"/usr/share/java/gridstore-jdbc-5.0.0.jar")
#identifier.quote = "`")
conn <- dbConnect(drv, "jdbc:gs://127.0.0.1:20001/myCluster/public", "admin", "admin")全ての内容が正しければ、conn変数にGridDBへのDBI接続が設定されます。これで、次のデータセットの取り込みに移ります。
JDBCでデータを取り込む
プレイバイプレイデータを取り込むために、hoopRの組み込み関数を利用します。ライブラリの関数 load_nba_pbp はまさに必要なもので、DBI接続をパラメータの1つとして受け取り、特定の年のデータをDB接続にロードします。ソースコードを見ると、データは .csv と .rds ファイル形式で、hoopR の GitHub リポジトリから直接利用できることがわかります。
そこで、GitHub から直接ファイルを読み込んで、データが完成するまで一行ずつ取り込んでいきます。RJDBC API を使うと、.dbWritetable を呼び出すだけで、テーブルの作成を含む SQL 文の作成を代行してくれます。
loader <- rds_from_url
urls <- paste0("https://raw.githubusercontent.com/sportsdataverse/hoopR-data/main/nba/pbp/rds/play_by_play_2022.rds")
p <- NULL
out <- lapply(urls, progressively(loader, p))
out <- rbindlist_with_attrs(out)
out$type_abbreviation <- NULL
for (i in 1:nrow(out)) {
RJDBC::dbWriteTable(conn, "nba_pbp_2022", out[i, ], append = TRUE )
}GitHubから直接ファイルを読み込み、一行ずつ、約60万行のデータを取り込みます。これが終わると、2022年NBAの最新シーズンのあらゆる側面を、いくつかのクエリで分析することができます。
プレイバイプレイデータを分析する
データを分析するには、見たいデータを返すSQLクエリを作成します。まず、データセットに含まれるすべてのカラムを見てみましょう。
Columns:
No Name Type CSTR RowKey
------------------------------------------------------------------------------
0 shooting_play STRING
1 sequence_number STRING
2 period_display_value STRING
3 period_number INTEGER
4 home_score INTEGER
5 coordinate_x INTEGER
6 coordinate_y INTEGER
7 scoring_play STRING
8 clock_display_value STRING
9 team_id STRING
10 type_id STRING
11 type_text STRING
12 away_score INTEGER
13 id DOUBLE
14 text STRING
15 score_value INTEGER
16 participants_0_athlete_id STRING
17 participants_1_athlete_id STRING
18 participants_2_athlete_id STRING
19 season INTEGER
20 season_type INTEGER
21 game_id INTEGER
22 away_team_id INTEGER
23 away_team_name STRING
24 away_team_mascot STRING
25 away_team_abbrev STRING
26 away_team_name_alt STRING
27 home_team_id INTEGER
28 home_team_name STRING
29 home_team_mascot STRING
30 home_team_abbrev STRING
31 home_team_name_alt STRING
32 home_team_spread DOUBLE
33 game_spread DOUBLE
34 home_favorite STRING
35 game_spread_available STRING
36 qtr INTEGER
37 time STRING
38 clock_minutes INTEGER
39 clock_seconds DOUBLE
40 half STRING
41 game_half STRING
42 lag_qtr DOUBLE
43 lead_qtr DOUBLE
44 lag_game_half STRING
45 lead_game_half STRING
46 start_quarter_seconds_remaining INTEGER
47 start_half_seconds_remaining INTEGER
48 start_game_seconds_remaining INTEGER
49 game_play_number INTEGER
50 end_quarter_seconds_remaining DOUBLE
51 end_half_seconds_remaining DOUBLE
52 end_game_seconds_remaining DOUBLE
53 period INTEGERこの情報を表示するために、GridDB CLI’s showcontainer コマンドを使用しました。showcontainer nba_pbp_2022 とします。
関連するデータポイントを選択する
もちろん、分析には多くの方向性がありますが、最も視覚的に楽しいデータポイントの1つは、シュートの成功と失敗をプロットすることです。データポイントの結果を、適切な文脈のためにNBAのコートに似せてプロットすることができれば、さらによいでしょう。幸運なことに、この試みに役立つ列がいくつかあります。座標x、座標y、スコア値、シューティングプレイ、参加者0_アスリートID、およびタイプIDです。
これらの列を使用すると、特定の選手、特定の試合、特定のチームのさまざまなプレーの座標を取得することができます。特に、type_idは多くの異なるイベントタイプに対応できることがわかります。例えば、type_idが132であれば、「ステップバックジャンプショット」に特化して検索することができます。例えば、特に最近は ジェームス・ハーデン選手 が怪我に悩まされているため、最近のステップバックジャンプショットリーダーとしては、ルカ・ドンチッチ選手 が思い浮かびます。
これが正しいかどうかを確認するには、 SQL クエリを実行します。まず、シェルでこのクエリを実行し、データの結果に問題がなければ、データをプロットする作業に移りましょう。
データセットへのクエリ
まず、両選手によるステップバックの試行回数を取得してみましょう。SQLクエリを作成します。SELECT COUNT(*) FROM nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '3945274' AND type_id = '132' このクエリは、ルカ選手がステップバックジャンプショットを試みたすべてのインスタンスを検索します。このクエリを実行すると、ルカ選手のステップバックジャンプショットの試行回数が450回という驚異的な数字が表示されます。しかし、このデータセットにはポストシーズンのすべてが含まれており、彼はプレイオフの第3戦にも参加したので、このメトリックのボリュームが比較的大きいことに注意してください。
もし、ハーデン選手に対して同じクエリを実行すれば、ハーデン選手がこのムーブを広めたプレーヤーであるにもかかわらず、試行回数はより小さくなるのではないでしょうか。このクエリを実行してみましょう。SELECT COUNT(*) FROM nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '3992' AND type_id = '132' と入力します。349件の結果が得られ、最後に試行したのはイースタンカンファレンスセミファイナル第6戦のマイアミ・ヒート戦での敗戦でした。
しかし、総試行回数を見る代わりに、このタイプのショットをより多く「行った」のは誰かを知りたいとしたらどうなるでしょうか?そのためには、2以上のscore_valueをクエリに追加すればよいのです。SELECT COUNT(*) FROM nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '3945274' AND type_id = '132' AND score_value >= 2 のようになります。このクエリを両選手に対して実行すると、ハーデン選手のステップバックショットは122/349、ルカ選手は175/450、つまり、ハーデン選手のステップバックショットが~35%に対し、ルカ選手は~39%で、ルカ選手が新しいステップバックキングと言えるかもしれません。
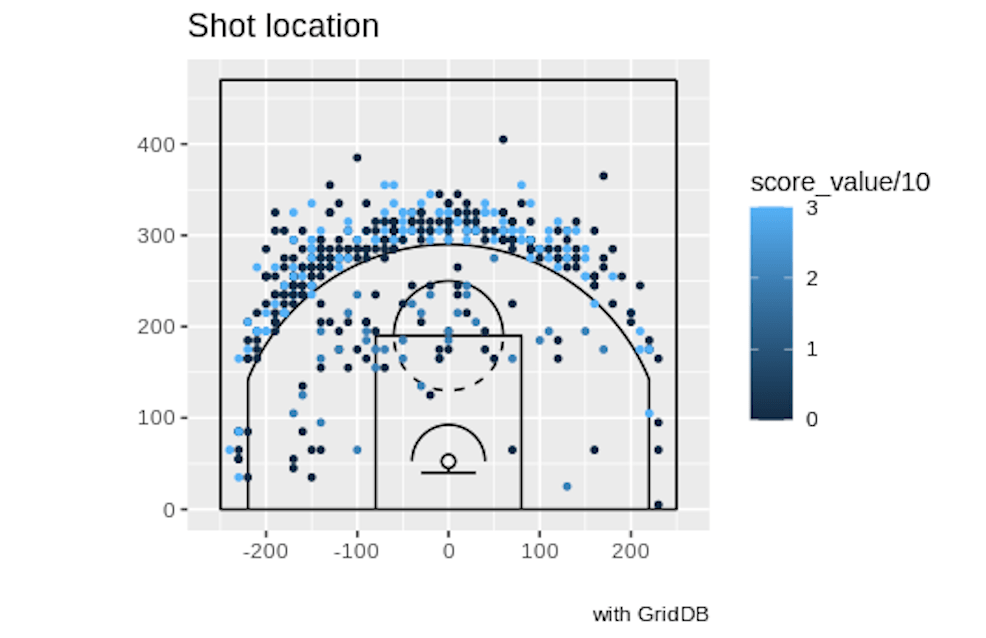
そのチャートはこのようになります。
データセットを可視化する
ルカ選手はステップバック・ジャンプショットでより良いショットを、より多くの試行回数で決めていることがわかりました。ルカ選手がコートのどこでこれらのショットを試みたか、そしてそれを成功させたかを視覚化できたら素晴らしいと思いませんか?先に述べたように、プレイバイプレイデータには、特定のイベントが発生した場所の座標が含まれています。したがって、すべてのステップバックジャンプショットの座標を直接クエリで抽出することができます。次に、これらの値をNBAのコートのようなものにプロットしてみましょう。
この偉業を達成するために、ballr ライブラリによって作られたコートを借りることができます。ggplotでコートを描くことができたら、コートが期待するものに合わせて座標を変更し、イベントの正確な位置をすべてNBAハーフコートに可視化することができます。
queryString <- "select coordinate_x, coordinate_y from nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '3945274' AND type_id = '132'"
rs <- dbGetQuery(conn, queryString )
source("https://raw.githubusercontent.com/toddwschneider/ballr/master/plot_court.R")
source("https://raw.githubusercontent.com/toddwschneider/ballr/master/court_themes.R")
plot_court() # created the court_points object we need
court_points <- court_points %>% mutate_if(is.numeric,~.*10)
rs <- rs %>% mutate_if(is.numeric,~.*10)最後のステップとして、すべてのデータポイントを court_points に直接プロットします。
DBcourt <-
ggplot(rs, aes(x=coordinate_x-250, y=coordinate_y+45)) +
scale_fill_manual(values = c("#00529b","#cc4b4b"),guide='none')+
geom_path(data = court_points,
aes(x = x, y = y, group = desc),
color = "black")+
coord_equal()+
geom_point(aes(fill="TRUE",color=score_value/10),size=1) +
xlim(-260, 260)+
labs(title="Shot location",x="",
y="",
caption = "with GridDB")
print(DBcourt)このコードでは、ルカ選手のステップバックジャンパーの座標をプロットしています。成功したものはより明るい青色で、失敗したものはほぼ黒色で表示されます。小さなコートに450のデータポイントをプロットしているので、少し乱雑ですが、彼がシーズンを通してどのような成績を収めたか、雰囲気をつかむことができると思います。
分析のためのその他のアイディア
もちろん、ステップバックジャンパーの分析は、これだけのデータがあればできることのほんの一端に過ぎません。他にも例えば、第4クォーターのシュート数を見て、「クラッチネス」を推定することもできます。これだけのデータがあれば、可能性は無限大です。
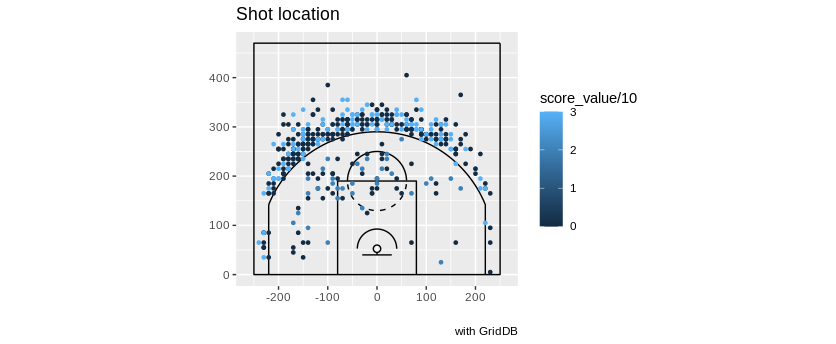
ここでは、様々な選手に対して作成できる簡単なショットチャートの例をいくつか紹介します。まず、ステファン・カリー選手の今シーズンの全メイドバスケットを見て、それをチャートにしてみましょう。
queryString <- "select coordinate_x, coordinate_y from nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '3975' AND score_value >= 2"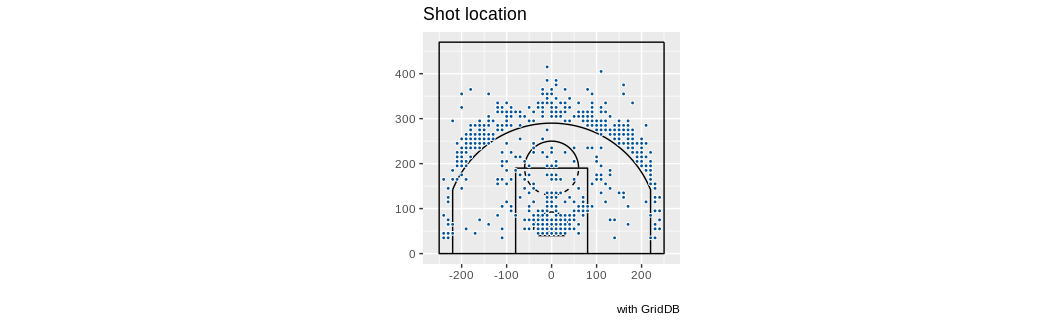
あるいは、ヤニス・アデトクンボ選手で試してみましょう。
queryString <- "select coordinate_x, coordinate_y from nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '3032977' AND score_value >= 2"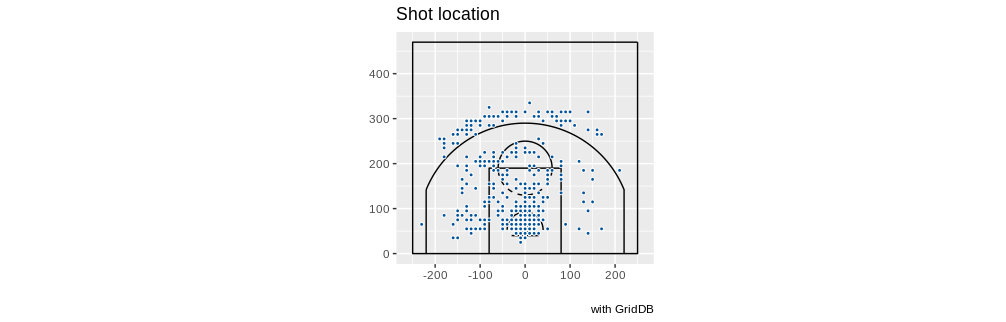
クレイ・トンプソン選手の場合は以下のようになります。
queryString <- "select coordinate_x, coordinate_y from nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '6475' AND score_value >= 2"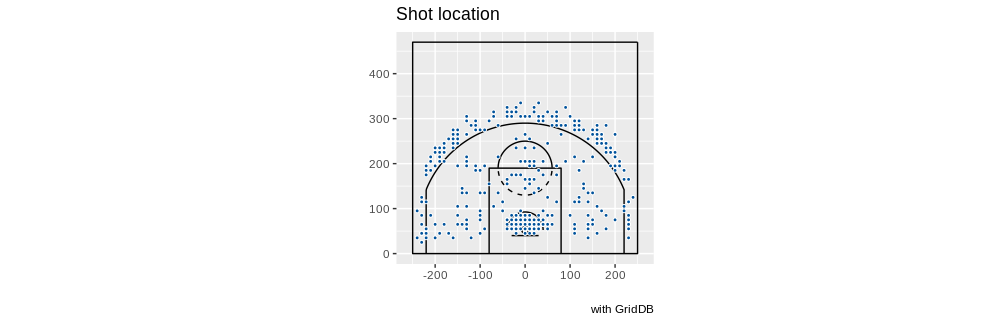
レブロン・ジェームス選手は以下の通りです。
queryString <- "select coordinate_x, coordinate_y from nba_pbp_2022 WHERE shooting_play = 'TRUE' AND participants_0_athlete_id = '1966' AND score_value >= 2"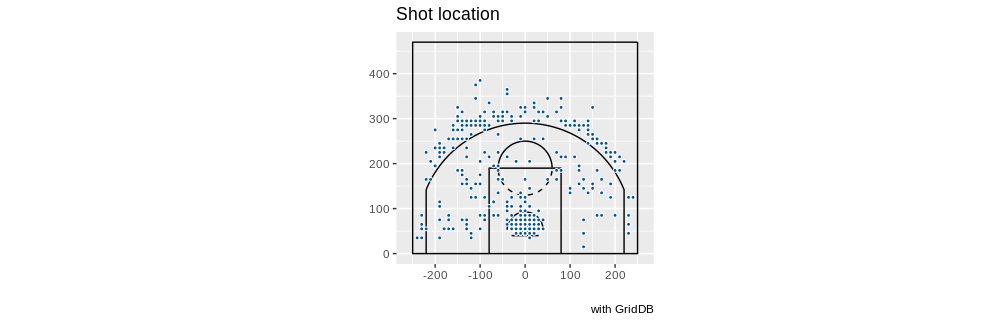
まとめ
このように、RでGridDBを使用して、非常に大きなデータセットを照会したり、当該データセットを可視化したりすることができます。ぜひ使ってみてください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb