
GridDB Cloud v2.0 の紹介
GridDB Cloud v2.0 が正式にリリースされ、新たに無料プランが追加されました。ただし現在のところ GridDB Cloud v2.0 無料プランの提供は日本国内在住者のみとなっています。その他の地域にお住まいの方々は無料プランが利用できるようになるまで今しばらくお待ちください。
サインアップ方法
GridDB Cloud の無料トライアルを希望する場合はこちらから申し込みができます。 https://www.global.toshiba/jp/products-solutions/ai-iot/griddb/product/griddb-cloud.html
GridDB Cloud のファーストステップ
GridDB Cloud インスタンスは、HTTP リクエストを介して通信することができます。GridDB とやり取りするために必要なすべてのアクションは、異なる URL、パラメータ、メソッド、ペイロードボディを持つ HTTP リクエストを策定し発行する必要があります。
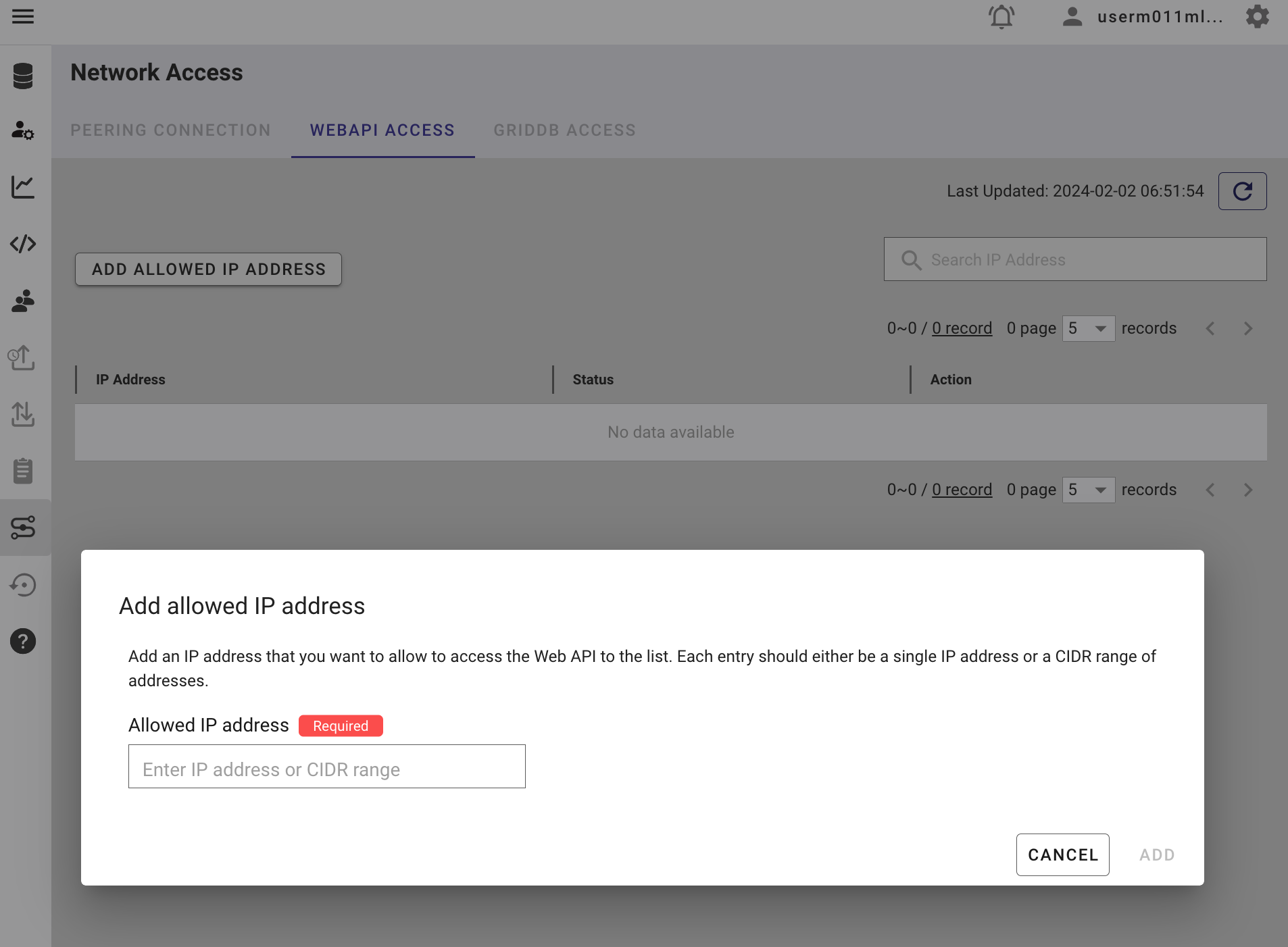
IP アドレスのホワイトリスト化
GridDB Cloud 管理ダッシュボードのネットワーク設定で、公開 IP アドレスをホワイトリストに登録してください。
GridDB ユーザとデータベースアクセス
次に GridDB ユーザを新規作成します。サイドパネルから「GridDBユーザ」と書かれたアイコンをクリックします。このページから データベースユーザの作成 をクリックします。このユーザ名とパスワードは、Basic 認証の Authorization ヘッダとして HTTP リクエストに付加されます。ユーザー名とパスワードの組み合わせは、コロンで区切って64進数でエンコードする必要があります。例えば、admin:admin は、YWRtaW46YWRtaW4= になります。
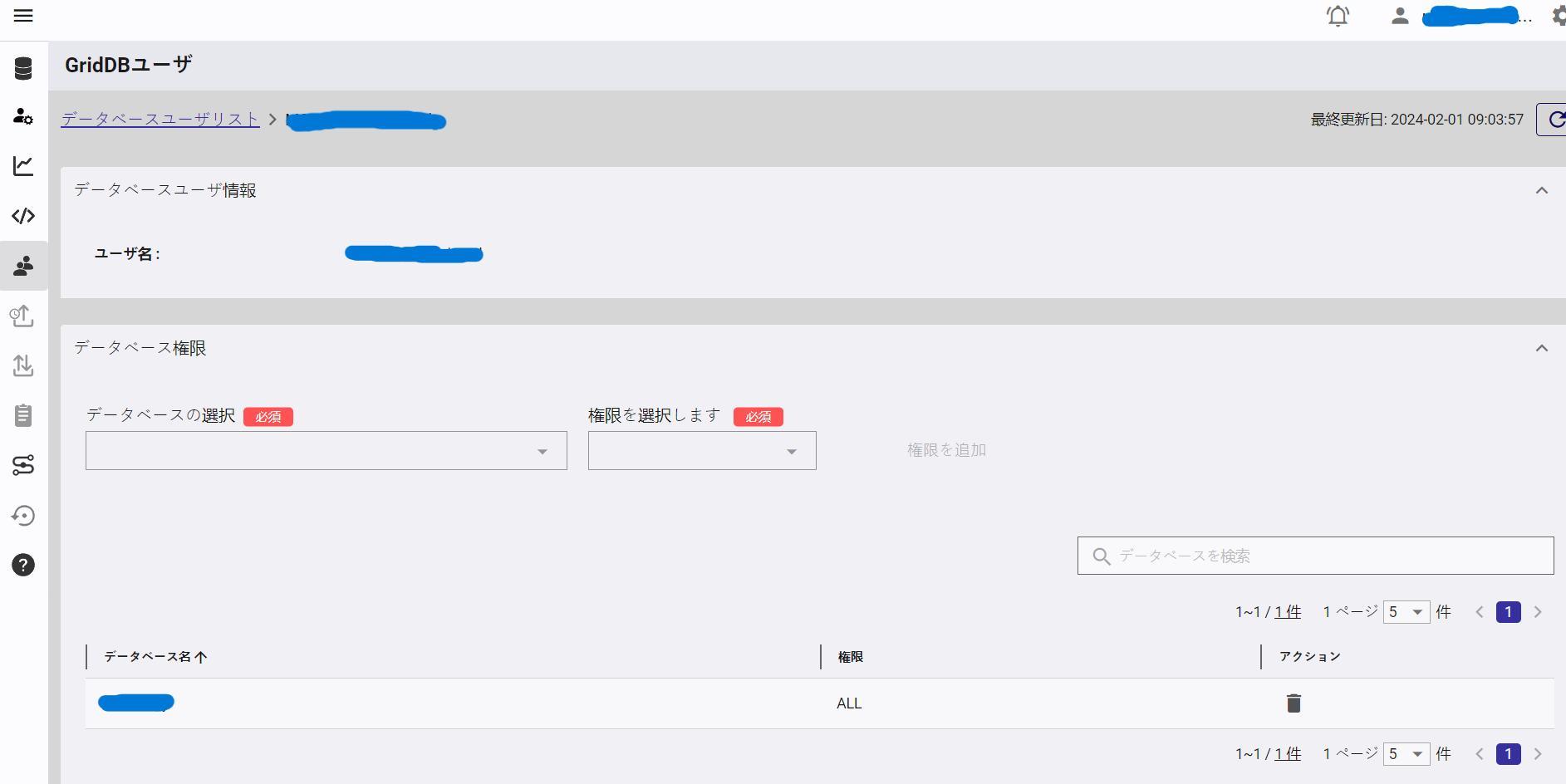
新しいユーザを作成したら、データベースへのアクセス権も付与する必要があります。「GridDBユーザ」ページのユーザ一覧からユーザをクリックし、データベースへのアクセス権 (READ または ALL) を付与します。これで実際の HTTP リクエストの実行に移ることができます。
GridDB 接続の確認
まず GridDB インスタンスに接続できるかどうかを確認します。
接続URLエンドポイントの確認
Web API は base url を使用し、これをベースにリクエストを作成します。ベース URL は以下のようになります。 https://cloud<number>.griddb.com/griddb/v2/
接続が存在することを確認するには、ベース URL に /:cluster/dbs/:database/checkConnection を追加します。サーバにデータを送り返さないので HTTP の GET メソッドを使用します。
最後に、HTTP リクエストのヘッダに basic authentication を含める必要があります。そのためには base64 にエンコードされたユーザー名とパスワードを含める必要があります。最終的には以下に示すような URL になります。 https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/checkConnection
この URL は、データベースと通信するためのあらゆるインターフェースで使用することができます。
cURL リクエスト
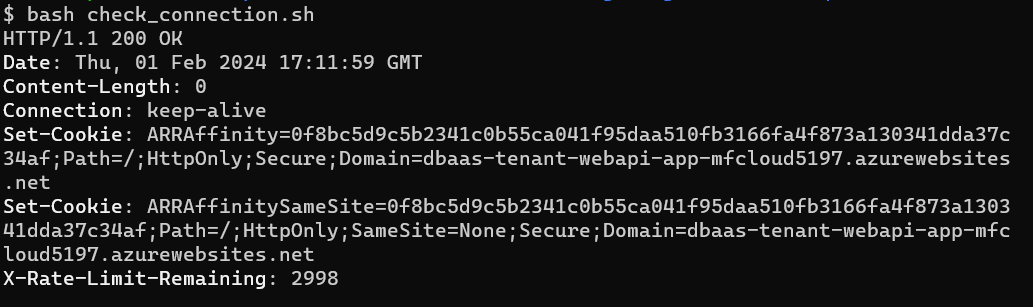
cURLで接続をチェックするには、以下のコマンドを使うことができます (check_connection.sh)。
curl -i –location ‘https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/checkConnection’ \ –header ‘Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs’
GET リクエストなので、認証ヘッダーを追加するだけでよいです。これを実行すると HTTP レスポンスとして 200 が返ってくるはずです。もし 401 (unauthorized) が返ってきたら、GridDB ユーザの認証情報を確認してください。403 (forbidden) と表示された場合は IP アドレスがクラウドのファイアウォールを通過できるか確認してください。
Python リクエスト
同じリクエストを Python で書いてみましょう。
# check_connection.py
import requests
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/checkConnection"
payload = {}
headers = {
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.status_code)Node.js リクエスト
Node.js だと以下のようになります。
//checkConnection.js
const request = require('request');
const options = {
'method': 'GET',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/checkConnection',
'headers': {
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
}
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log("Response Status Code: ", response.statusCode);
});最初のコンテナの作成:時系列とコレクション
接続がしっかりと確立されたので、最初のコンテナ (コレクションと時系列) を作成することができます。詳しくは GridDB データモデル を参照してください。
URL 接尾辞は /:cluster/dbs/:database/containers のようになります。このリクエストは、時々多くのデータを必要とし、大きな範囲を持つことがあるため、HTTP の POST メソッドが必要となります。
リクエストの本文では、コンテナ名、コンテナタイプ、行キーが存在するかどうか (bool)、スキーマを要求します。まず HTTP リクエストのコンテキスト外の構造を見てみましょう。また、リクエストのヘッダーに JSON 型のデータペイロードを送信することを含める必要があります。'Content-Type: application/json' のようにします。
時系列コンテナ
ここでは、コンテナタイプを TIME_SERIES とし、最初のカラムを timestamp 型としています。行キーセクションもありますが、これはオプションです。時系列コンテナでは、行キーはデフォルトで常にタイムスタンプになります。
{
"container_name": "device1",
"container_type": "TIME_SERIES",
"rowkey": true,
"columns": [
{
"name": "ts",
"type": "TIMESTAMP"
},
{
"name": "co",
"type": "DOUBLE"
},
{
"name": "humidity",
"type": "DOUBLE"
},
{
"name": "light",
"type": "BOOL"
},
{
"name": "lpg",
"type": "DOUBLE"
},
{
"name": "motion",
"type": "BOOL"
},
{
"name": "smoke",
"type": "DOUBLE"
},
{
"name": "temp",
"type": "DOUBLE"
}
]
}これでリクエストを作成するときにこれをボディにアタッチするだけで、新しいコンテナが作成されるはずです。成功すればステータスコード 201 (Created) が返ってくるはずです。
cURL
#create_container.sh
curl -i -X POST --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '{
"container_name": "device1",
"container_type": "TIME_SERIES",
"rowkey": true,
"columns": [
{
"name": "ts",
"type": "TIMESTAMP"
},
{
"name": "co",
"type": "DOUBLE"
},
{
"name": "humidity",
"type": "DOUBLE"
},
{
"name": "light",
"type": "BOOL"
},
{
"name": "lpg",
"type": "DOUBLE"
},
{
"name": "motion",
"type": "BOOL"
},
{
"name": "smoke",
"type": "DOUBLE"
},
{
"name": "temp",
"type": "DOUBLE"
}
]
}'Python
#create_container.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers"
payload = json.dumps({
"container_name": "device1",
"container_type": "TIME_SERIES",
"rowkey": True,
"columns": [
{
"name": "ts",
"type": "TIMESTAMP"
},
{
"name": "co",
"type": "DOUBLE"
},
{
"name": "humidity",
"type": "DOUBLE"
},
{
"name": "light",
"type": "BOOL"
},
{
"name": "lpg",
"type": "DOUBLE"
},
{
"name": "motion",
"type": "BOOL"
},
{
"name": "smoke",
"type": "DOUBLE"
},
{
"name": "temp",
"type": "DOUBLE"
}
]
})
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.status_code)Node.js
//createContainer.js
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify({
"container_name": "device1",
"container_type": "TIME_SERIES",
"rowkey": true,
"columns": [
{
"name": "ts",
"type": "TIMESTAMP"
},
{
"name": "co",
"type": "DOUBLE"
},
{
"name": "humidity",
"type": "DOUBLE"
},
{
"name": "light",
"type": "BOOL"
},
{
"name": "lpg",
"type": "DOUBLE"
},
{
"name": "motion",
"type": "BOOL"
},
{
"name": "smoke",
"type": "DOUBLE"
},
{
"name": "temp",
"type": "DOUBLE"
}
]
})
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log("Response Status Code: ", response.statusCode);
});コレクションコンテナ
ではコレクションコンテナを作成しましょう。コレクションコンテナは時系列カラムを必要としません(ただし時系列カラムを作ることは許可されます)。また rowkey を true に設定する必要もありません。以下に例を挙げます。
cURL
#create_collection.sh
curl -i -X POST --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '{
"container_name": "deviceMaster",
"container_type": "COLLECTION",
"rowkey": true,
"columns": [
{
"name": "equipment",
"type": "STRING"
},
{
"name": "equipmentID",
"type": "STRING"
},
{
"name": "location",
"type": "STRING"
},
{
"name": "serialNumber",
"type": "STRING"
},
{
"name": "lastInspection",
"type": "TIMESTAMP"
},
{
"name": "information",
"type": "STRING"
}
]
}'Python
#create_collection.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers"
payload = json.dumps({
"container_name": "deviceMaster",
"container_type": "COLLECTION",
"rowkey": True,
"columns": [
{
"name": "equipment",
"type": "STRING"
},
{
"name": "equipmentID",
"type": "STRING"
},
{
"name": "location",
"type": "STRING"
},
{
"name": "serialNumber",
"type": "STRING"
},
{
"name": "lastInspection",
"type": "TIMESTAMP"
},
{
"name": "information",
"type": "STRING"
}
]
})
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.status_code)Node.js
//createCollection.js
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify({
"container_name": "deviceMaster",
"container_type": "COLLECTION",
"rowkey": true,
"columns": [
{
"name": "equipment",
"type": "STRING"
},
{
"name": "equipmentID",
"type": "STRING"
},
{
"name": "location",
"type": "STRING"
},
{
"name": "serialNumber",
"type": "STRING"
},
{
"name": "lastInspection",
"type": "TIMESTAMP"
},
{
"name": "information",
"type": "STRING"
}
]
})
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.statusCode);
});GridDB Cloud による CRUD (Create、Read、Update、Delete)
次に Create、Read、Update、Delete の各コマンドについて説明します。
行データの追加 (Create)
すでにいくつかのコンテナを作成しましたが、それらのコンテナに対してデータを追加するために、行データを作成します。
行データは、コンテナの中に直接追加することができます。URL の接尾辞は以下のようになります。 /:cluster/dbs/public/containers/:container/rows
行データをコンテナに PUT するには、HTTP の PUT メソッドを使用する必要があります。先ほどと同様にコンテンツが JSON であることを指定し、リクエストボディーに行データを含める必要があります。
一度に複数の行を追加することもできますが、ペイロードの形式を行数に合わせて変更し、最後の行の末尾にカンマを付けないようにする必要があります。
それでは、device1 コンテナに行を追加してみましょう。
[
["2024-01-09T10:00:01.234Z", 0.003551, 50.0, false, 0.00754352, false, 0.0232432, 21.6],
["2024-01-09T11:00:01.234Z", 0.303551, 60.0, false, 0.00754352, true, 0.1232432, 25.3],
["2024-01-09T12:00:01.234Z", 0.603411, 70.0, true, 0.00754352, true, 0.4232432, 41.5]
]もちろん、行のスキーマがコンテナのスキーマと一致していることも確認する必要があります。もし一致していなければ、エラーメッセージとステータスコード 400 (Bad Request) が表示されます。
cURL
https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers
#add_rows.sh
curl --location --request PUT 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/device1/rows' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
["2024-01-09T10:00:01.234Z", 0.003551, 50.0, false, 0.00754352, false, 0.0232432, 21.6],
["2024-01-09T11:00:01.234Z", 0.303551, 60.0, false, 0.00754352, true, 0.1232432, 25.3],
["2024-01-09T12:00:01.234Z", 0.603411, 70.0, true, 0.00754352, true, 0.4232432, 41.5]
]'Python
#add_rows.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/device1/rows"
payload = json.dumps([
[
"2024-01-09T10:00:01.234Z",
0.003551,
50,
False,
0.00754352,
False,
0.0232432,
21.6
],
[
"2024-01-09T11:00:01.234Z",
0.303551,
60,
False,
0.00754352,
True,
0.1232432,
25.3
],
[
"2024-01-09T12:00:01.234Z",
0.603411,
70,
True,
0.00754352,
True,
0.4232432,
41.5
]
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("PUT", url, headers=headers, data=payload)
print(response.text)Node.js
//addRows.js
var request = require('request');
var options = {
'method': 'PUT',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/device1/rows',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
[
"2024-01-09T10:00:01.234Z",
0.003551,
50,
false,
0.00754352,
false,
0.0232432,
21.6
],
[
"2024-01-09T11:00:01.234Z",
0.303551,
60,
false,
0.00754352,
true,
0.1232432,
25.3
],
[
"2024-01-09T12:00:01.234Z",
0.603411,
70,
true,
0.00754352,
true,
0.4232432,
41.5
]
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});コンテナのクエリー (Read)
コンテナにデータを書き込んだ後は、コンテナから読み込みを行います。URL 接尾辞は前とまったく同じで、/:cluster/dbs/:database/containers/:container/rows ですが、今回は POST メソッドを使います。これらのリクエストでサーバーが期待するデータは、行データがどのように返されるかを期待するものです。例えば、行数の制限、オフセット、任意の条件、ソート方法などを選択することができます。そのボディは以下のようになります。
{
"offset" : 0,
"limit" : 100,
"condition" : "temp >= 30",
"sort" : "temp desc"
}このリクエストを作成する際の 1 つの注意点は、POST リクエストなのでリクエストの本文に 何か を送る必要があるということです。上記のどのパラメータでもかまいませんが制限を含めるのが最も簡単でサーバの負担を減らすという利点もあります。
成功すれば、ステータスコード 200 (OK) とリクエストされたデータを含むボディを持つサーバーからのレスポンスが返ってくるはずです。
#query_container.sh
{
"columns": [
{
"name": "ts",
"type": "TIMESTAMP",
"timePrecision": "MILLISECOND"
},
{
"name": "co",
"type": "DOUBLE"
},
{
"name": "humidity",
"type": "DOUBLE"
},
{
"name": "light",
"type": "BOOL"
},
{
"name": "lpg",
"type": "DOUBLE"
},
{
"name": "motion",
"type": "BOOL"
},
{
"name": "smoke",
"type": "DOUBLE"
},
{
"name": "temp",
"type": "DOUBLE"
}
],
"rows": [
[
"2024-01-09T12:00:01.234Z",
0.603411,
70.0,
true,
0.00754352,
true,
0.4232432,
41.5
]
],
"offset": 0,
"limit": 100,
"total": 1
}cURL
curl -i -X POST --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/device1/rows' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '{
"offset" : 0,
"limit" : 100,
"condition" : "temp >= 30",
"sort" : "temp desc"
}'Python
#query_container.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/device1/rows"
payload = json.dumps({
"offset": 0,
"limit": 100,
"condition": "temp >= 30",
"sort": "temp desc"
})
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Node.js
//queryContainer.js
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/device1/rows',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify({
"offset": 0,
"limit": 100,
"condition": "temp >= 30",
"sort": "temp desc"
})
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});
行の更新 (Update)
行データを追加することも更新と言えますが、(コンテナに rowkey があれば)行データを直接更新することもできます。その仕組みは、rowkey が true に設定されているコンテナに行データをプッシュし、コンテナにすでに存在する rowkey を持つ行データを送信すると、プッシュされた新しい情報で行データが更新されるというものです。
データを追加するために一度 deviceMaster コレクションコンテナにデータをプッシュし、行データを更新するためにもう一度データをプッシュします。
まず行データを作成しましょう。
[
["device1", "01", "CA", "23412", "2023-12-15T10:45:00.032Z", "working"]
]では HTTP リクエストを作ってみましょう。
cURL
#update_collection.sh
curl -i --location --request PUT 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/deviceMaster/rows' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
["device1", "01", "CA", "23412", "2023-12-15T10:45:00.032Z", "working"]
]'Python
#update_collection.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/deviceMaster/rows"
payload = json.dumps([
[
"device1",
"01",
"CA",
"23412",
"2023-12-15T10:45:00.032Z",
"working"
]
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("PUT", url, headers=headers, data=payload)
print(response.text)Node.js
//updateCollection.js
var request = require('request');
var options = {
'method': 'PUT',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/deviceMaster/rows',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
[
"device1",
"01",
"CA",
"23412",
"2023-12-15T10:45:00.032Z",
"working"
]
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});行の更新
このデータを使って、最初の値 (rowkey、デバイス名) 以外の値を変更すると、そのデバイスのメタデータが更新され、コンテナ内の行が維持されます。
curl -i --location --request PUT 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/deviceMaster/rows' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
["device1", "01", "NY", "23412", "2023-12-20T10:45:00.032Z", "working"]
]'ここでは、場所と最終検査の時間を変更しています。ダッシュボードを見ると、値が更新されています。
行の削除 (Delete)
行を削除するには、適切な HTTP メソッド (Delete) を使用し、有効な行キーとコンテナをサーバに送信します。デバイスマスターの行を削除してみましょう。
リクエストのボディはこのようになります。この中に複数の行キーを追加して、複数の行を一度に削除することができます。
[
"device1"
]cURL
#delete_row.sh
curl -v --location --request DELETE 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/deviceMaster/rows' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
"device1"
]'Python
#delete_row.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/deviceMaster/rows"
payload = json.dumps([
"device1"
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("DELETE", url, headers=headers, data=payload)
print(response.status_code)Node.js
//deleteRow.js
var request = require('request');
var options = {
'method': 'DELETE',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/deviceMaster/rows',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
"device1"
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.statusCode);
});時系列コンテナの行の削除
時系列コンテナの行を削除することもできます。前述のように、時系列コンテナではタイムスタンプが常に行キーになるので、ここではタイムスタンプを追加するだけで、それらの行は削除されます。
#delete_container.sh
curl --location --request DELETE 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers/device1/rows' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
"2024-01-09T10:00:01.234Z",
"2024-01-09T12:00:01.234Z"
]'TQL
次に TQL クエリを実行してみましょう。TQL は GridDB の特殊なクエリ言語です。
簡単なクエリを実行してみよう。まず URL は以下のようになります。
base url + /:cluster/dbs/:database/tql
リクエストの本文には、コンテナ名の後にクエリ文が必要です。一度に複数のコンテナにクエリを実行することもできます。
[
{"name" : "deviceMaster", "stmt" : "select * limit 100", "columns" : null},
{"name" : "device1", "stmt" : "select * where temp>=24", "columns" : ["temp", "co"]},
]そして、これが上記のクエリに対するレスポンスです。
[
{
"columns": [
{
"name": "equipment",
"type": "STRING"
},
{
"name": "equipmentID",
"type": "STRING"
},
{
"name": "location",
"type": "STRING"
},
{
"name": "serialNumber",
"type": "STRING"
},
{
"name": "lastInspection",
"type": "TIMESTAMP",
"timePrecision": "MILLISECOND"
},
{
"name": "information",
"type": "STRING"
}
],
"results": [
[
"device1",
"01",
"NY",
"23412",
"2023-12-20T10:45:00.032Z",
"working"
]
],
"offset": 0,
"limit": 100,
"total": 1,
"responseSizeByte": 31
},
{
"columns": [
{
"name": "temp",
"type": "DOUBLE"
},
{
"name": "co",
"type": "DOUBLE"
}
],
"results": [
[
25.3,
0.303551
],
[
41.5,
0.603411
]
],
"offset": 0,
"limit": 1000000,
"total": 2,
"responseSizeByte": 32
}
]cURL
#tql.sh
curl -i -X POST --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/tql' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '
[
{"name" : "deviceMaster", "stmt" : "select * limit 100", "columns" : null},
{"name" : "device1", "stmt" : "select * where temp>=24", "columns" : ["temp", "co"]}
]
'Python
#tql.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/tql"
payload = json.dumps([
{
"name": "deviceMaster",
"stmt": "select * limit 100",
"columns": None
},
{
"name": "device1",
"stmt": "select * where temp>=24",
"columns": [
"temp",
"co"
]
}
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Node.js
//tql.js
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/tql',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
{
"name": "deviceMaster",
"stmt": "select * limit 100",
"columns": null
},
{
"name": "device1",
"stmt": "select * where temp>=24",
"columns": [
"temp",
"co"
]
}
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});SQL
TQL に加えて、GridDB と GridDB Cloud には SQL 機能もあります。ただし、GridDB Cloud の SQL 機能は結果の読み込み (SELECT) と一部の行の更新 (UPDATE) に限定されています。
SQL SELECT
base url + /:cluster/dbs/:database/sql
[
{"type" : "sql-select", "stmt" : "SELECT * FROM deviceMaster"},
{"type" : "sql-select", "stmt" : "SELECT temp, co FROM device1 WHERE temp>=24"}
]これは TQL に非常に似ていますが、”通常” の SQL 文と同じように、クエリ自体からコンテナ名を呼び出します。
これがレスポンスボディです。
[
{
"columns": [
{
"name": "equipment",
"type": "STRING"
},
{
"name": "equipmentID",
"type": "STRING"
},
{
"name": "location",
"type": "STRING"
},
{
"name": "serialNumber",
"type": "STRING"
},
{
"name": "lastInspection",
"type": "TIMESTAMP",
"timePrecision": "MILLISECOND"
},
{
"name": "information",
"type": "STRING"
}
],
"results": [
[
"device1",
"01",
"CA",
"23412",
"2023-12-15T10:45:00.032Z",
"working"
]
],
"responseSizeByte": 47
},
{
"columns": [
{
"name": "temp",
"type": "DOUBLE"
},
{
"name": "co",
"type": "DOUBLE"
}
],
"results": [
[
25.3,
0.303551
],
[
41.5,
0.603411
]
],
"responseSizeByte": 32
}
]cURL
#sql_select.sh
curl -i -X POST --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
{"type" : "sql-select", "stmt" : "SELECT * FROM deviceMaster"},
{"type" : "sql-select", "stmt" : "SELECT temp, co FROM device1 WHERE temp>=24"}
]
'Python
#sql_select.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql"
payload = json.dumps([
{
"type": "sql-select",
"stmt": "SELECT * FROM deviceMaster"
},
{
"type": "sql-select",
"stmt": "SELECT temp, co FROM device1 WHERE temp>=24"
}
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Node.js
//sqlSelect.js
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
{
"type": "sql-select",
"stmt": "SELECT * FROM deviceMaster"
},
{
"type": "sql-select",
"stmt": "SELECT temp, co FROM device1 WHERE temp>=24"
}
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});SQL SELECT GROUP BY RANGE
SQL Select を使っているので、GridDB の Group By Range も使えます。詳しくはこちらのブログ Exploring GridDB’s Group By Range Functionality を参照してください。
クエリを作成し、時間ごとにグループ化します。
[
{"type" : "sql-select", "stmt" : "SELECT temp, co FROM device1 WHERE ts > TO_TIMESTAMP_MS(1594515625984) AND ts < TO_TIMESTAMP_MS(1595040779336) GROUP BY RANGE (ts) EVERY (1, HOUR)"}
]cURL
#sql_select_groupby.sh
curl -i --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
{"type" : "sql-select", "stmt" : "SELECT temp, co FROM device1 WHERE ts > TO_TIMESTAMP_MS(1594515625984) AND ts < TO_TIMESTAMP_MS(1595040779336) GROUP BY RANGE (ts) EVERY (1, HOUR)"}
]
'Python
# sql_select_groupby.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql"
payload = json.dumps([
{
"type": "sql-select",
"stmt": "SELECT temp, co FROM device1 WHERE ts > TO_TIMESTAMP_MS(1594515625984) AND ts < TO_TIMESTAMP_MS(1595040779336) GROUP BY RANGE (ts) EVERY (1, HOUR)"
}
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)SQL Insert
ベースとなる URL は SELECT と同じですが ‘update’ を追加する必要があります。
base url + /:cluster/dbs/:database/sql/update
[
{"stmt" : "insert into deviceMaster(equipment, equipmentID, location, serialNumber, lastInspection, information) values('device2', '02', 'MA', '34412', TIMESTAMP('2023-12-21T10:45:00.032Z'), 'working')"}
]cURL
#sql_insert.sh
curl -i -X POST --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql/update' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
{"stmt" : "insert into deviceMaster(equipment, equipmentID, location, serialNumber, lastInspection, information) values('\''device2'\'', '\''02'\'', '\''MA'\'', '\''34412'\'', TIMESTAMP('\''2023-12-21T10:45:00.032Z'\''), '\''working'\'')"}
]'Python
#sql_insert.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql/update"
payload = json.dumps([
{
"stmt": "insert into deviceMaster(equipment, equipmentID, location, serialNumber, lastInspection, information) values('device2', '02', 'MA', '34412', TIMESTAMP('2023-12-21T10:45:00.032Z'), 'working')"
}
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Node.js
//sqlInsert.js
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql/update',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
{
"stmt": "insert into deviceMaster(equipment, equipmentID, location, serialNumber, lastInspection, information) values('device2', '02', 'MA', '34412', TIMESTAMP('2023-12-21T10:45:00.032Z'), 'working')"
}
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});SQL Update
ベース URL は上記と同じですが ‘update’ を追加する必要があります。
base url + /:cluster/dbs/:database/sql/update
[
{"stmt" : "update deviceMaster set location = 'LA' where equipmentID = '01'"}
]このコマンドでは、前述の NoSQL の方法と同様に Update を行うことができます。既存の行を更新することも、コンテナを更新して新しい行を追加することもできます。
cURL
#sql_update.sh
curl -i -X POST --location 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql/update' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
{"stmt" : "update deviceMaster set location = '\''LA'\'' where equipmentID = '\''01'\''"}
]'Python
#sql_update.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql/update"
payload = json.dumps([
{
"stmt": "update deviceMaster set location = 'LA' where equipmentID = '01'"
}
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Node.js
//sqlUpdate.js
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/sql/update',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
{
"stmt": "update deviceMaster set location = 'LA' where equipmentID = '01'"
}
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});コンテナのドロップ
コンテナのドロップも可能です。
base url + /:cluster/dbs/:database/containers
リクエストのボディには、1 つまたは複数のコンテナ名を含めることができます。
[
"deviceMaster"
]成功した場合、ステータスコード 204 (No Content) が表示されます。
cURL
#delete_container.sh
curl -i --location --request DELETE 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs' \
--data '[
"deviceMaster"
]'Python
#delete_container.py
import requests
import json
url = "https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers"
payload = json.dumps([
"deviceMaster"
])
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
'User-Agent': 'PostmanRuntime/7.29.0'
}
response = requests.request("DELETE", url, headers=headers, data=payload)
print(response.status_code)Node.js
//deleteContainer.js
var request = require('request');
var options = {
'method': 'DELETE',
'url': 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/containers',
'headers': {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs'
},
body: JSON.stringify([
"deviceMaster"
])
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.statusCode);
});CSV データの取り込み
次に CSV データの取り込みを見てみましょう。Kaggle から IoT データを取り込みます。生ファイルはこちらのウェブサイトからダウンロードできます。 https://www.kaggle.com/datasets/garystafford/environmental-sensor-data-132k
device1 コンテナにデータを取り込むための Python スクリプトを以下に示します。
すでに device1 コンテナを作成しているので、スクリプト内でコンテナを作成する必要はありませんが、念のため記述しておきます。
#data_ingest.py
import pandas as pd
import numpy as np
import json
import requests
from datetime import datetime as dt, timezone
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
"User-Agent":"PostmanRuntime/7.29.0"
}
base_url = 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/'
data_obj = {
"container_name": "device1",
"container_type": "TIME_SERIES",
"rowkey": True,
"columns": []
}
input_variables = [
"ts","co","humidity","light","lpg","motion","smoke","temp"
]
data_types = [
"TIMESTAMP", "DOUBLE", "DOUBLE", "BOOL", "DOUBLE", "BOOL", "DOUBLE","DOUBLE"
]
for variable, data_type in zip(input_variables, data_types):
column = {
"name": variable,
"type": data_type
}
data_obj["columns"].append(column)
# Create Container
url = base_url + 'containers'
r = requests.post(url, json = data_obj, headers = headers)これだけなら簡単です。
次に、実際にデータを取り込んでみましょう。そのために Pandas ライブラリを使い、CSV ファイルを読み込みます。Pandas ライブラリを使えば、CSV データの特定のカラムをターゲットにして簡単に変換し、インジェストできるようにすることもできます。
最後に、CSV ファイルは 8 メガバイトを超えるので、データをチャンクに分割してクラウドに送信します。これが残りのコードです。
iot_data = pd.read_csv('iot_telemetry_data.csv')
#2023-12-15T10:25:00.253Z
iot_data['ts'] = pd.to_datetime(iot_data['ts'], unit='s').dt.strftime("%Y-%m-%dT%I:%M:%S.%fZ")
print(iot_data["ts"])
iot_data = iot_data.drop('device', axis=1)
#print(iot_data.dtypes)
iot_subsets = np.array_split(iot_data, 20)
# Ingest Data
url = base_url + 'containers/device1/rows'
for subset in iot_subsets:
#Convert the data in the dataframe to the JSON format
iot_subsets_json = subset.to_json(orient='values')
request_body_subset = iot_subsets_json
r = requests.put(url, data=request_body_subset, headers=headers)
print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
print('_______________',r.text,'___________')
print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
if r.status_code > 299:
print(r.status_code)
break
else:
print('Success for chunk')
スクリプトを実行すると、アップロードされた各チャンクについて、何行が正常に更新されたかという成功メッセージが表示されるはずです。これが完了すると、HTTP リクエストクエリやポータルから device1 をチェックアウトできるようになります。
データ分析
最後に、簡単な分析をしてみましょう。IoT データにクエリを発行し、そのデータを使って簡単な分析とグラフ化を行います。
#data_analysis.py
import pandas as pd
import numpy as np
import requests
import plotly.express as px
from IPython.display import Image
# ts object
# co float64
# humidity float64
# light bool
# lpg float64
# motion bool
# smoke float64
# temp float64
headers = {
'Content-Type': 'application/json',
'Authorization': 'Basic TTAxMU1sd0MxYS1pc3JhZWw6aXNyYWVs',
"User-Agent":"PostmanRuntime/7.29.0"
}
base_url = 'https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/B2xcGQJy/'
sql_query1 = (f"""SELECT * from device1 WHERE co < 0.0019050147565559603 """)
url = base_url + 'sql'
request_body = '[{"type":"sql-select", "stmt":"'+sql_query1+'"}]'
data_req1 = requests.post(url, data=request_body, headers=headers)
myJson = data_req1.json()
dataset = pd.DataFrame(myJson[0]["results"],columns=[myJson[0]["columns"][0]["name"],myJson[0]["columns"][1]["name"],myJson[0]["columns"][2]["name"],
myJson[0]["columns"][3]["name"],myJson[0]["columns"][4]["name"],myJson[0]["columns"][5]["name"],myJson[0]["columns"][6]["name"],myJson[0]["columns"][7]["name"]])
print(dataset)
lowest_col = dataset.sort_values('co', ascending=False).head(20000)
scatter_plot = px.scatter(lowest_col, x='ts', y='co', size='co', color='co',
color_continuous_scale='plasma', hover_name='co')
# Customize the plot
scatter_plot.update_layout(
title='Data Analysis',
xaxis_title='CO2 Emissions',
yaxis_title='Time'
)
scatter_plot.update_layout(template='plotly_dark')
# Show the plot
scatter_plot.show()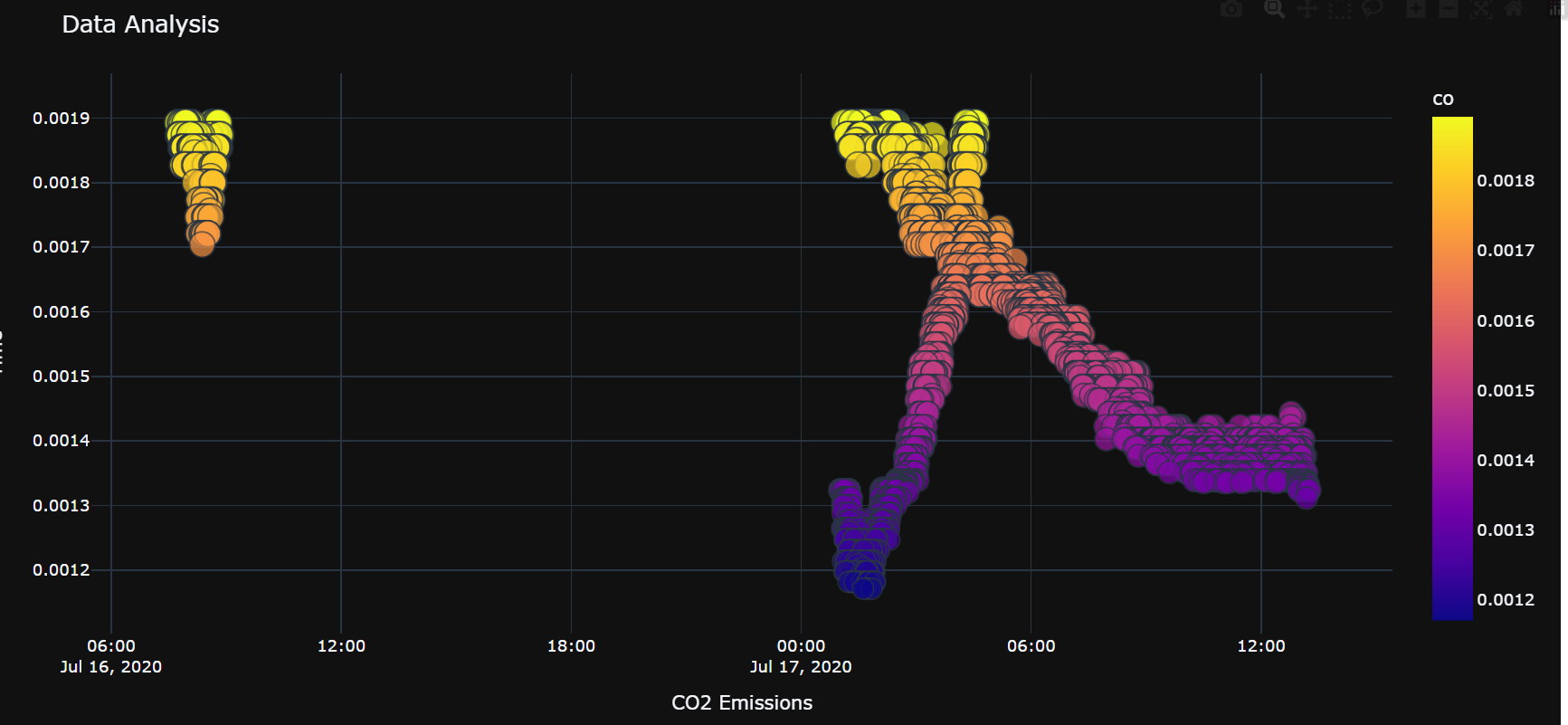
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb