この記事では、GridDB をデータベースとして使用し、Python で世界の人口データを可視化する方法を学びます。GridDB Python クライアントを使用して、GridDB データベースに接続し、世界人口の CSV データを GridDB に挿入し、そのデータを取得し、Python の matplotlib、pandas、seaborn ライブラリを使用して様々なビジュアライゼーションをプロットします。
**このブログのコードはGridDB Blogs Github repoのpopulation_analysisというブランチにあります。
前提条件
PythonアプリケーションをGridDBに接続する前に、GridDB CクライアントとGridDB Pythonクライアントをインストールする必要があります。GridDB Python Package Index (Pypi)の説明に従って、これらのクライアントをインストールしてください。
以下のスクリプトは、このブログのコードを実行するために必要なライブラリをインポートします。
import griddb_python as griddb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")世界人口データセットのインポートと前処理
Kaggleの世界人口データセットをPythonの様々な可視化の助けを借りて分析します。このデータセットは、1970年から2022年までの各国の世界人口統計を含むCSVファイルで構成されています。
CSVファイルをダウンロードし、以下のスクリプトを実行してデータセットをPandasのデータフレームにインポートします。world_population.csv`ファイルの場所によって、パスを更新してください。
dataset = pd.read_csv(r"/mnt/d/Datasets/world_population.csv")
print(dataset.shape)
dataset.head()Output:
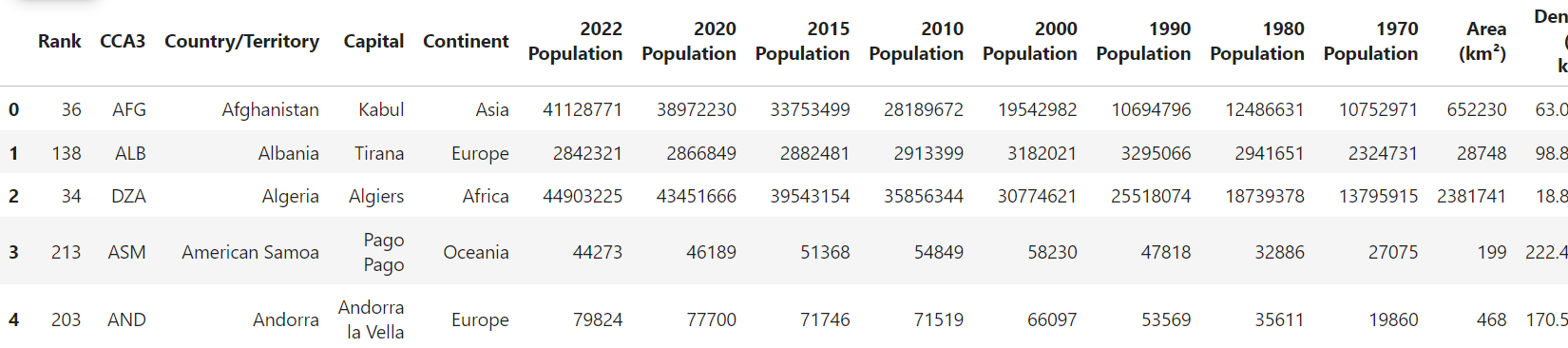
データセットは 234 行、17 列で構成されています。カラム名にはいくつかの特殊文字が含まれていますが、GridDB コンテナではカラム名に特殊文字を含めることができないため、これを削除する必要があります。
以下のスクリプトは、データセットのカラムの特殊文字をアンダースコアに置き換え、カラムのデータ型を表示します。
dataset.columns = dataset.columns.str.replace('[^a-zA-Z0-9]', '_', regex=True)
dataset.dtypesOutput:

入力カラムを GridDB 準拠のカラム型にマッピングする必要があるため、入力カラムの型を確認します。例えば、後述するように、GridDB コンテナにデータを挿入する前に、object 型を string 型に置き換える必要があります。
データセットの前処理を行いました。以下のステップでは、GridDB に接続し、CSV データを挿入します。
**Pandasのデータフレームを使用して、Pythonで直接データを可視化することができます。このブログではデモンストレーションのため、まず CSV データを GridDB コンテナに挿入し、挿入されたデータを Pandas dataframe に取得し、GridDB から取得したデータを使用してビジュアライゼーションをプロットします。
GridDB との接続の作成
接続を作成するには、以下のスクリプトのように StoreFactory クラスのオブジェクトを作成する必要があります。
次に、ファクトリーオブジェクトの get_store() メソッドに GridDB のホスト URL、クラスタ名、ユーザ名とパスワードの値を渡します。これで完了です。
接続が確立されていることを確認するには、get_container() メソッドを使用して任意のコンテナを取得します。接続に問題があれば、例外が発生します。
以下のスクリプトを実行してください。提供された出力が表示されれば、接続は成功しています。例外が発生した場合は、認証情報を確認し、GridDB サーバが起動していることを確認し、設定を確認してください。
factory = griddb.StoreFactory.get_instance()
DB_HOST = "127.0.0.1:10001"
DB_CLUSTER = "myCluster"
DB_USER = "admin"
DB_PASS = "admin"
try:
gridstore = factory.get_store(
notification_member = DB_HOST,
cluster_name = DB_CLUSTER,
username = DB_USER,
password = DB_PASS
)
container1 = gridstore.get_container("container1")
if container1 == None:
print("Container does not exist")
print("Successfully connected to GridDB")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))Output:
Container does not exist
Successfully connected to GridDB
世界の人口データをGridDBコンテナに格納する
GridDBコンテナは、テーブルのカラムが特定のデータ形式であることを期待します。詳細はGridDBのデータ型を参照してください。
コンテナを作成するには、まず ContainerInfo クラスのオブジェクトを作成し、コンテナ名、コンテナカラム、コンテナタイプ、およびブール値の 4 つのパラメータを渡します。
コンテナ・カラムはリストのリストでなければならず、入れ子になったリストにはそれぞれカラム名と対応するカラムの型が含まれます。今回のデータセットには時系列データがないので、コンテナの型を Collection に設定します。
以下のスクリプトでは、Pandas データフレームのカラムを GridDB のカラムタイプにマップする map_pandas_dtype_to_griddb() 関数を定義しています。このメソッドは必要に応じて変更することができます。
次に、コンテナ情報を格納する ContainerInfo クラスのオブジェクトを作成します。
# see all GridDB data types: https://docs.griddb.net/architecture/data-model/#data-type
def map_pandas_dtype_to_griddb(dtype):
if dtype == 'int64':
return griddb.Type.LONG
elif type == 'float64':
return griddb.Type.FLOAT
elif dtype == 'object':
return griddb.Type.STRING
# Add more column types if you want
else:
raise ValueError(f'Unsupported pandas type: {dtype}')
container_columns = []
for column_name, dtype in dataset.dtypes.items():
griddb_dtype = map_pandas_dtype_to_griddb(str(dtype))
container_columns.append([column_name, griddb_dtype])
container_info = griddb.ContainerInfo("PopulationStats",
container_columns,
griddb.ContainerType.COLLECTION, True)最後に、コンテナオブジェクトを作成するには、 put_container() メソッドを呼び出して、先ほど作成した container_info オブジェクトを渡します。
最後に、コンテナにレコードを挿入するには、入力データフレームの行を繰り返し処理し、各行を Python のリストに変換し、そのリストをコンテナオブジェクトに挿入します。
try:
cont = grid store.put_container(container_info)
for index, row in dataset.iterrows():
cont.put(row.tolist())
print("All rows have been successfully stored in the GridDB container.")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))Output:
すべての行が正常に GridDB コンテナに格納されました。
上記のメッセージのように、GridDB にデータが正常に挿入されました。
次に、GridDBコンテナからデータを読み込む方法を学びます。
GridDBコンテナからの世界人口データの取得
このセクションでは、GridDBコンテナから世界の人口データを取得し、次のセクションで様々なビジュアライゼーションを用いて分析します。
get_container() メソッドはGridDBからコンテナデータを取得します。コンテナオブジェクトの query メソッドでは、このコンテナに対して SQL クエリを実行できます。
以下のスクリプトでは、fetch() メソッドを使用して PopulationStats コンテナからすべてのデータを選択します。次に、fetch_rows() メソッドを使用してすべての行を取得し、Pandas データフレームとしてデータを返します。
population_container = gridstore.get_container("PopulationStats")
query = population_container.query("select *")
rs = query.fetch()
population_data = rs.fetch_rows()
print(population_data.shape)
population_data.head()Output:
GridDBのデータを使ってPythonで世界の人口データを視覚化する
GridDBに挿入したデータをPandasのデータフレームとして取り出すことに成功しました。次に、このデータフレームを使って世界人口の様々な側面を分析することができます。Pandas、Matplotlib、SeabornなどのPythonライブラリを使って様々な可視化をプロットすることができます。
いくつかの例を見てみましょう。
大陸別の世界人口の分析
アジアが世界で最も人口の多い大陸であることは既にご存知でしょう。しかし、アジアが世界の人口に占める割合をご存知でしょうか?この情報は、大陸別にすべての国の人口を合計し、各大陸の人口の割合を表示する円グラフを使って視覚化できます。
下のスクリプトは、世界の人口を大陸別に円グラフにしたものです。
population_by_continent = population_data.groupby('Continent')['2022_Population'].sum()
plt.figure(figsize=(6,6))
plt.pie(population_by_continent,
labels=population_by_continent.index,
autopct='%1.1f%%', startangle=140)
plt.title('World Population by Continent in 2022')
plt.show()Output:
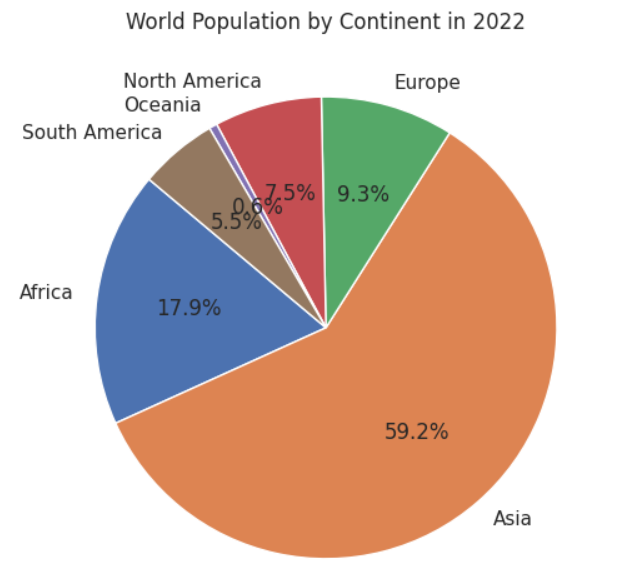
周知のように、アジア大陸は世界人口の約59%を占め、アフリカ、ヨーロッパがそれに続きます。
世界人口比率上位10カ国の可視化
もう一つの興味深い分析は、人口上位10カ国が世界人口にどれだけ貢献しているかということです。これを行うには、国や地域と、それらに対応する世界人口の割合を表示する棒グラフを作成することができます。
top_countries = population_data.sort_values('World_Population_Percentage', ascending=False).head(10)
plt.figure(figsize=(10, 8))
plt.barh(top_countries['Country_Territory'],
top_countries['World_Population_Percentage'],
color='skyblue')
plt.xlabel('% of world population')
plt.title('Top 10 Countries by World Population %')
plt.gca().invert_yaxis() # Ensure the largest value is at the top
plt.show()Output:
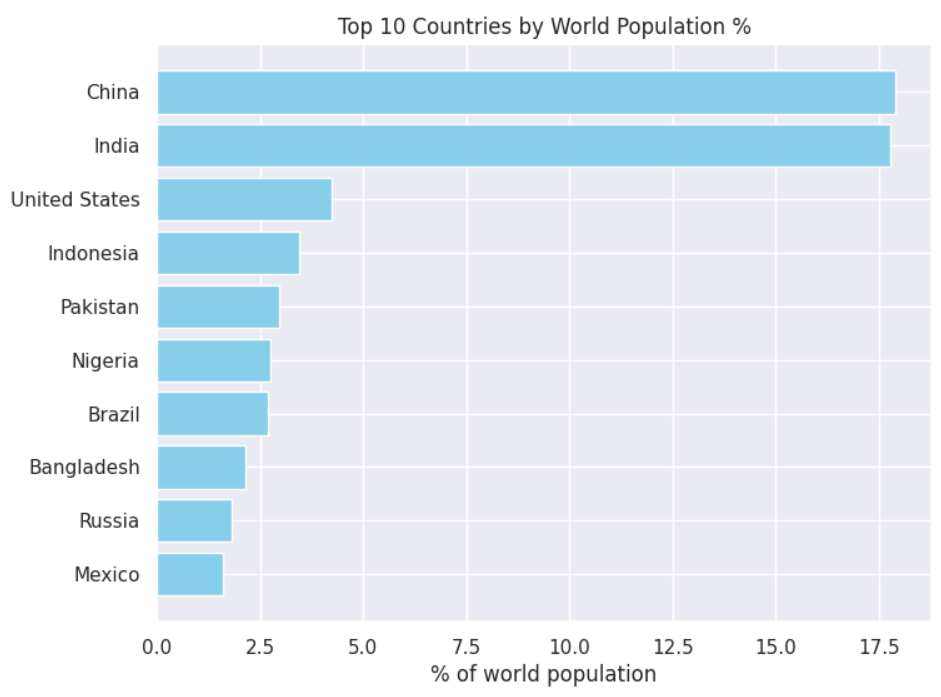
上記の出力は、中国とインドがそれぞれ世界人口の約17%を占めていることを示しています。つまり、地球上の3人に1人はインド人か中国人ということになります。
人口密度の高い国・地域トップ10の分析
総人口に加え、もうひとつ興味深い指標として人口密度があります。
これによって、ある国や地域がどれだけ混雑しているかがわかります。この情報を得るには、次のスクリプトのように、人口密度の高い国を棒グラフで表示してください。
top_density_countries = population_data.nlargest(10, 'Density__per_km__')
plt.figure(figsize=(8, 6))
sns.barplot(x='Country_Territory', y='Density__per_km__', data=top_density_countries)
plt.xticks(rotation=45)
plt.title('Top 10 Countries/Territories by Population Density per Sq-km')
plt.xlabel('Country')
plt.ylabel('Density (per km²)')
plt.show()Output:
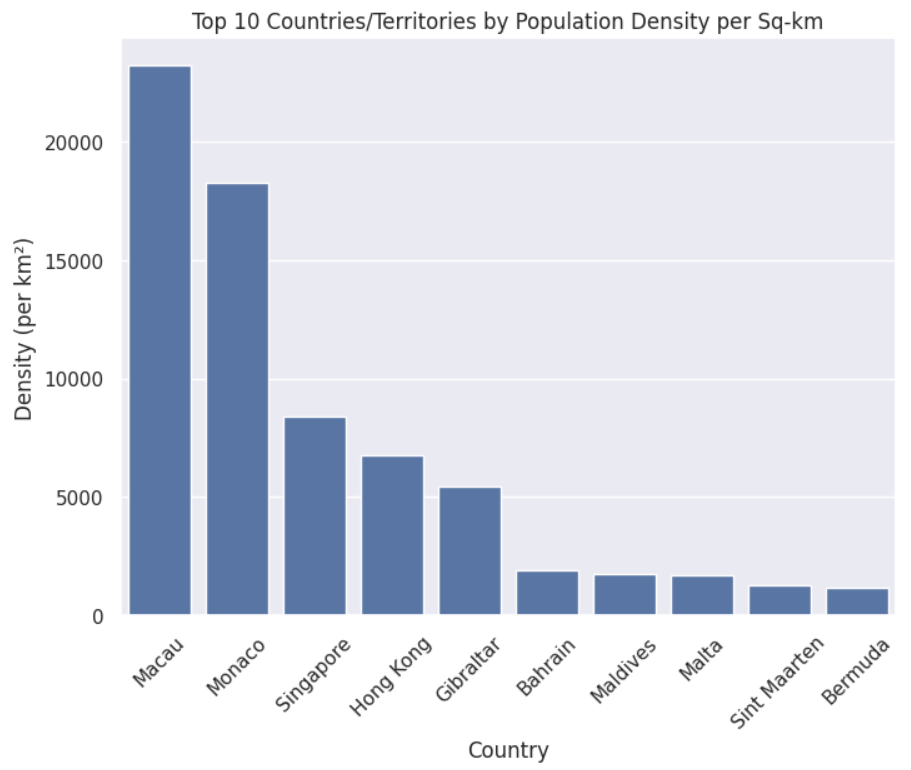
その結果、1平方キロメートル当たりの人口密度が最も高いのはマカオ(中国領)で、次いでモナコ、シンガポールとなっています。
ヨーロッパとアジアで最も人口密度の高い国トップ10
さらに掘り下げて、アジアとヨーロッパの2つの棒グラフをプロットし、これらの大陸で人口密度が最も高い上位10カ国/地域を表示してみましょう。
europe = population_data[population_data['Continent'] == 'Europe'].sort_values('Density__per_km__', ascending=False).head(10)
south_america = population_data[population_data['Continent'] == 'South America'].sort_values('Density__per_km__', ascending=False).head(10)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
axes[0].barh(europe['Country_Territory'], europe['Density__per_km__'], color='skyblue')
axes[0].set_title('Top 10 Densely Populated Countries/Territories in Europe')
axes[0].invert_yaxis()
axes[1].barh(south_america['Country_Territory'], south_america['Density__per_km__'], color='lightgreen')
axes[1].set_title('Top 10 Densely Populated Countries/Territories in South America')
axes[1].invert_yaxis()
plt.tight_layout()
plt.show()Output:
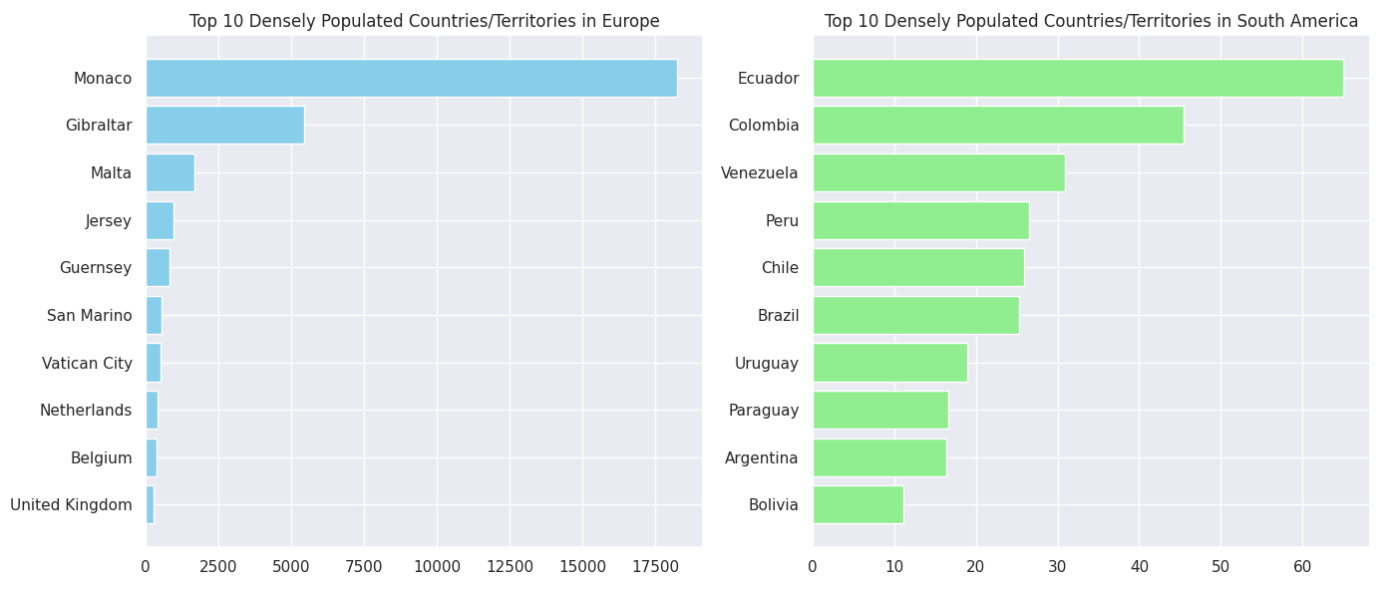
ご覧の通り、モナコはヨーロッパで最も人口密度の高い領土であり、エクアドルは南米で最も人口密度の高い国です。
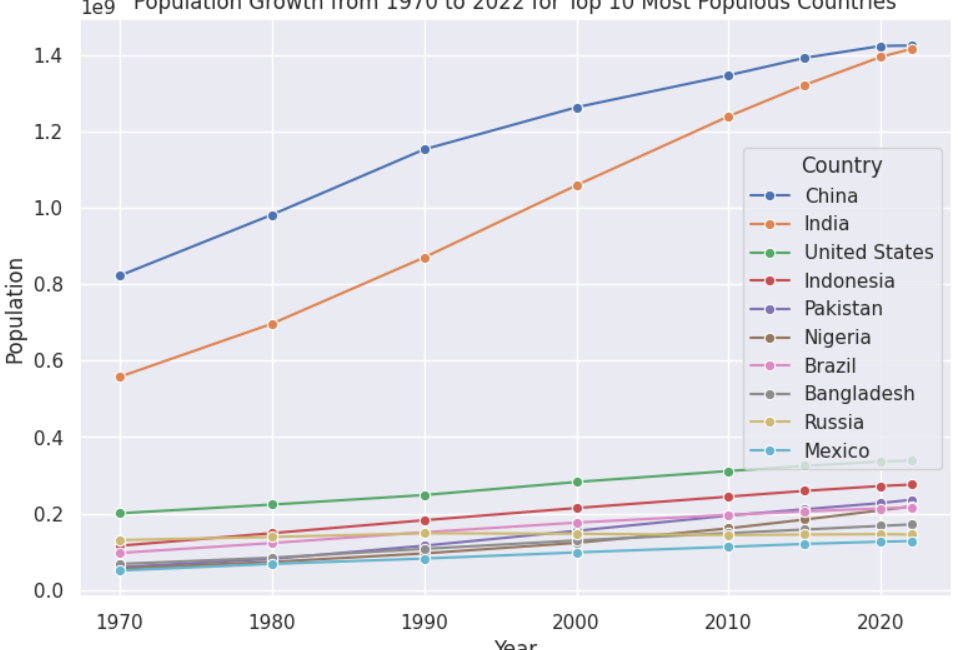
人口上位10カ国の1970年から2022年までの人口増加率
世界人口のもうひとつの興味深い側面は、人口増加率です。これは、人口をコントロールする必要がある国を特定するのに役立ちます。
例えば、次のスクリプトは、折れ線グラフを使って、1970年から2022年までの人口上位10カ国の人口増加率を示しています。
top_countries = population_data.sort_values(by='World_Population_Percentage', ascending=False).head(10)
data = pd.melt(top_countries,
id_vars=['Country_Territory'],
value_vars=['1970_Population', '1980_Population', '1990_Population', '2000_Population', '2010_Population', '2015_Population', '2020_Population', '2022_Population'],
var_name='Year',
value_name='Population')
data['Year'] = data['Year'].str.extract('(\d+)').astype(int)
plt.figure(figsize=(9, 6))
sns.line plot(x='Year',
y='Population',
hue='Country_Territory',
data=data, marker='o')
plt.title('Population Growth from 1970 to 2022 for Top 10 Most Populous Countries')
plt.legend(title='Country')
plt.show()Output:
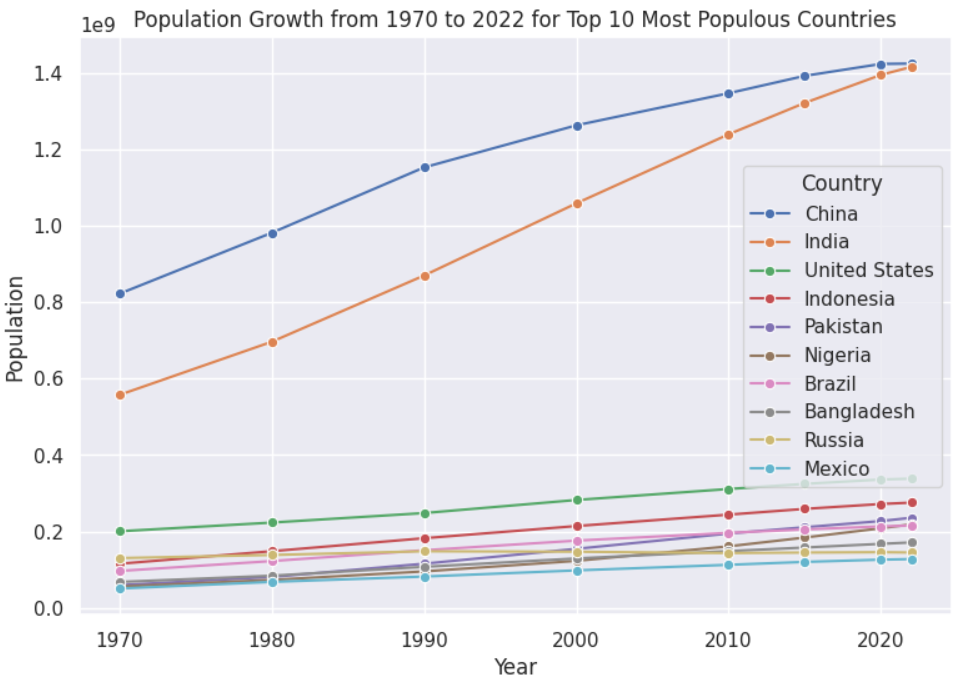
上記のアウトプットから、インドと中国の人口差は1970年には約2億人だったが、2022年末にはほとんど無視できるまでに縮まっていることがわかります。
以上が、世界人口データセットから得られた興味深い観察結果の一部です。同じ手法を使ってデータセットをさらに分析し、視覚化することで、よりエキサイティングな情報を抽出することができます。
SQL UPDATE QUERYを使ったGridDBデータの更新
データの挿入や取得に加えて、GridDBでは既存のデータを簡単に更新することができます。更新するには、更新したい行と列を選択し、選択したセルに更新値を代入します。
例えば、以下のスクリプトを使用して、Country_Territoryカラムに Afghanistan が含まれているときに Capital カラムの値を更新することができます。スクリプトは、まず Country_Territory カラムが Afghanistan と等しい行を選択し、次に Pandas データフレームを使用して Capital カラムのインデックスを選択する。次に、スクリプトは update() メソッドを使ってセルの値を更新します。最後に、コンテナの commit() 関数が GridDB 内のコンテナに変更をコミットします。
population_container.set_auto_commit(False)
query = population_container.query("SELECT * WHERE Country_Territory = 'Afghanistan'")
rs = query.fetch(True)
if rs.has_next():
data = rs.next()
capital_index = population_data.columns.get_loc('Capital')
data[capital_index] = 'Kabool'
rs.update(data)
population_container.commit()
print("Capital name updated successfully.")
query = population_container.query("select *")
rs = query.fetch()
population_data = rs.fetch_rows()
population_data.head()Output:
SQL DELETEクエリを使用したGridDBデータの削除
同様に、GridDB コンテナから行を削除するには、fetch() クエリが返すオブジェクトの remove() メソッドを使用します。以下のスクリプトでは、Continentカラムに値 Europe が含まれる行をすべて削除しています。
population_container.set_auto_commit(False)
query = population_container.query("SELECT * WHERE Continent = 'Europe'")
rs = query.fetch(True)
while rs.has_next():
data = rs.next()
rs.remove()
population_container.commit()
print("Records where Continent is 'Europe' have been successfully deleted.")
query = population_container.query("select *")
rs = query.fetch()
population_data = rs.fetch_rows()
population_data.head()Output:

結論
この記事では、GridDBをデータベースとして、Pythonを使って世界人口のデータセットを分析しました。さらに、PythonをGridDBデータベースに接続する方法を学びました。GridDBコンテナにCSVデータを挿入し、GridDBコンテナからPandasデータフレームにデータをフェッチする方法を学びました。
GridDBは非常にスケーラブルなオープンソースデータベースであり、NoSQLや従来のSQLクエリを使用して、あらゆる種類のデータを効率的に格納・取得することができます。GridDBデータベースは、IoTや時系列データセットの管理に非常にお勧めです。
このブログのJupyter NotebookはGithubにあります。
GridDBに関する質問や問い合わせがあれば、Stackoverflowの投稿を作成します。エンジニアが迅速に対応できるように、griddbタグを忘れずに使用してください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb