
AIツールの台頭により、プレゼンテーションスライドの作成を含む多くの手作業を自動化することができます。開発者は、OpenAIの言語モデルとNode.jsを活用することで、スライドコンテンツをプログラムで生成できます。この自動化は確実に時間を節約します。コンテンツ生成にOpenAIを使い、オーケストレーションにNode.jsを使うことで、説得力があり情報量の多いプレゼンテーションの作成プロセスを楽に効率化することができます。
この投稿では、OpenAIのアシスタントAPIモデルを使ってスライド・コンテンツの作成を自動化し、Node.jsを使ってスライド・ドキュメントを作成し、GridDBを使ってスライド情報を保存します。
プロジェクトの実行
このGitHubリポジトリからソースコードをクローンします。
git clone https://github.com/griddbnet/Blogs.git --branch slidesこのプロジェクトを実行するには、Node.jsとGridDBもインストールする必要があります。必要なソフトウェアがインストールされている場合は、ディレクトリを apps プロジェクトのディレクトリに変更してから、依存関係をすべてインストールします:
cd apps
npm install .envファイルを作成し、すべての環境変数を.env.example` ファイルからコピーします。このプロジェクトには OpenAI キーが必要です。キーの取得方法については このセクション を参照してください。
OPENAI_API_KEY=sk-proj-secret
VITE_APP_URL=http://localhost:3000VITE_APP_URL`を必要に応じて変更し、次のコマンドを実行してプロジェクトを実行することができます:
npm run start:build次にブラウザを開き、アプリのURLにアクセスします。データサンプルを選択し、Create Slideボタンをクリックします。
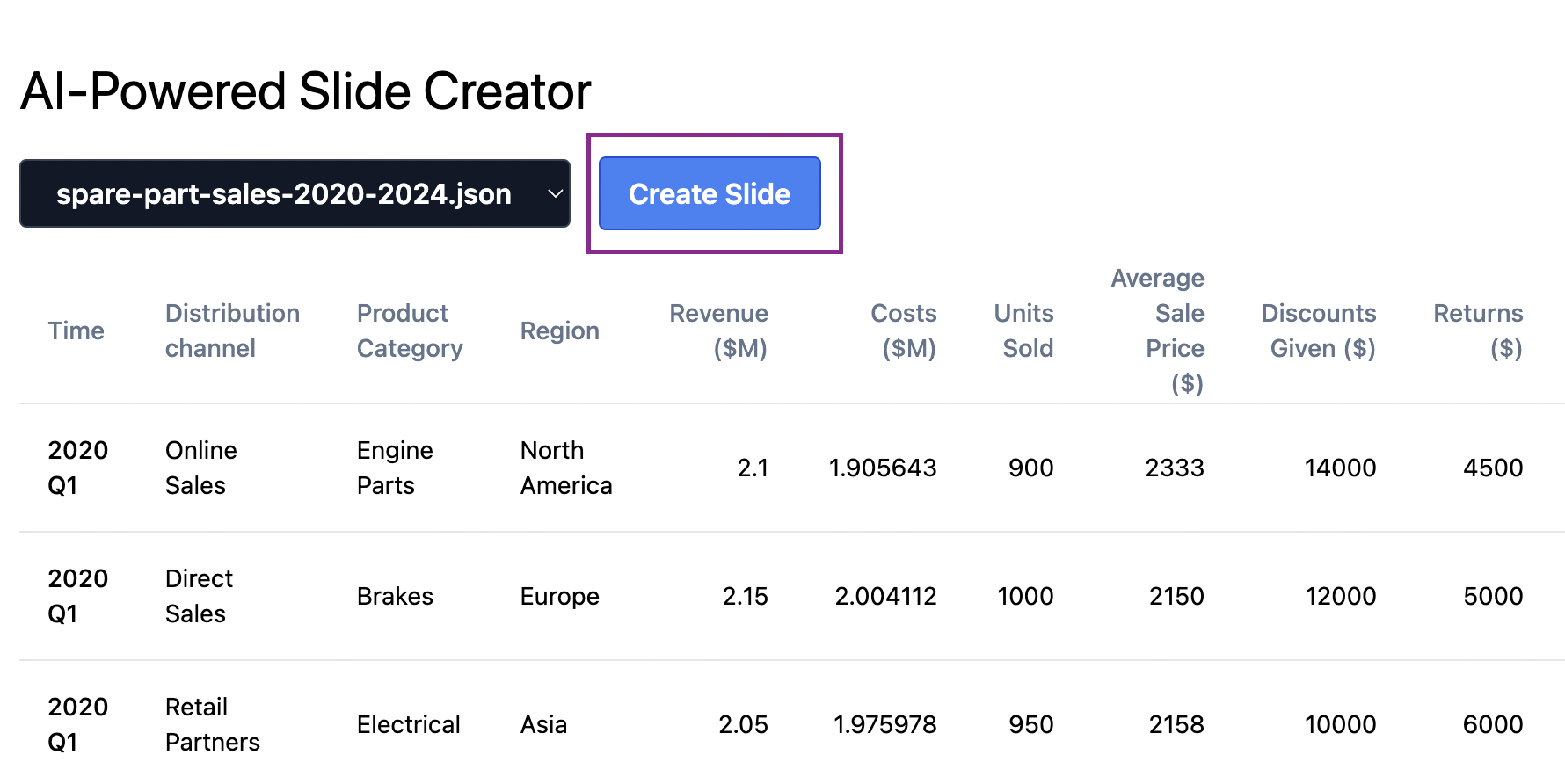
スライドプレゼンテーションが正常に作成されると、ダウンロードリンクが提供されます。
はじめに
1. Node.jsのインストール
このプロジェクトはNode.jsプラットフォーム上で動作します。こちらからインストールする必要があります。このプロジェクトでは、nvm パッケージマネージャと Node.js v16.20.2 LTS バージョンを使用します。
# installs nvm (Node Version Manager)
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
# download and install Node.js
nvm install 16
# verifies the right Node.js version is in the environment
node -v # should print `v16.20.2`
# verifies the right NPM version is in the environment
npm -v # should print `8.19.4``Node.jsとGridDBデータベースを接続するには、gridb-node-api npmパッケージが必要です。
2. GridDBのセットアップ
GridDBデータベースを使用して、レシピと栄養分析を保存します。詳しいインストール方法はguideを参照してください。ここではUbuntu 20.04 LTSを使用します。
GridDBを起動し、サービスが実行されているか確認します。以下のコマンドを使用してください:
sudo systemctl status gridstore実行されていない場合は、このコマンドでデータベースを実行してみてください:
sudo systemctl start gridstore3. OpenAIキーの設定
OpenAIのキーはプロジェクト単位なので、まずOpenAIプラットフォームでプロジェクトを作成する必要があります。
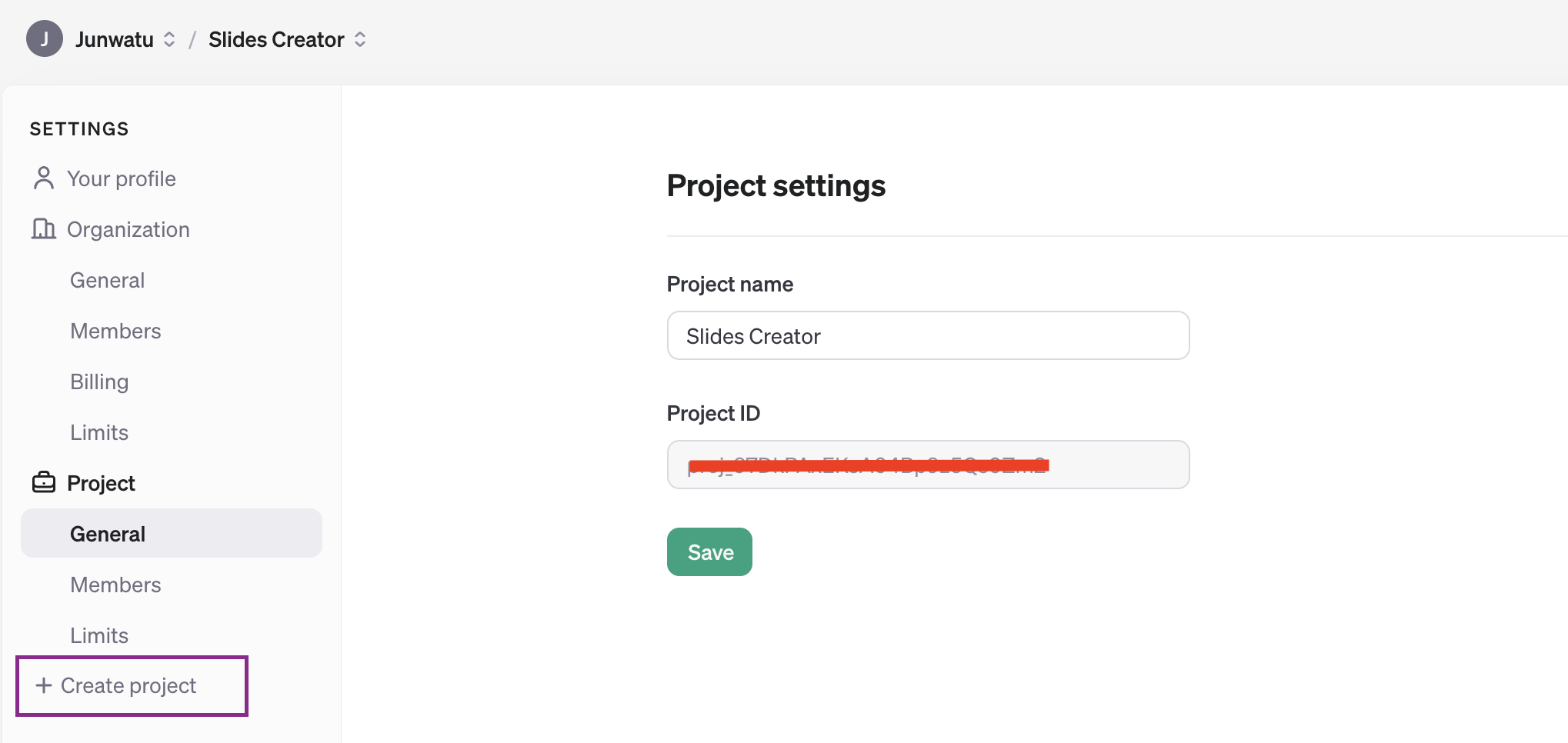
OpenAIのサービスにアクセスするには、有効なキーが必要です。このリンクにアクセスし、新しい OpenAI キーを作成します。
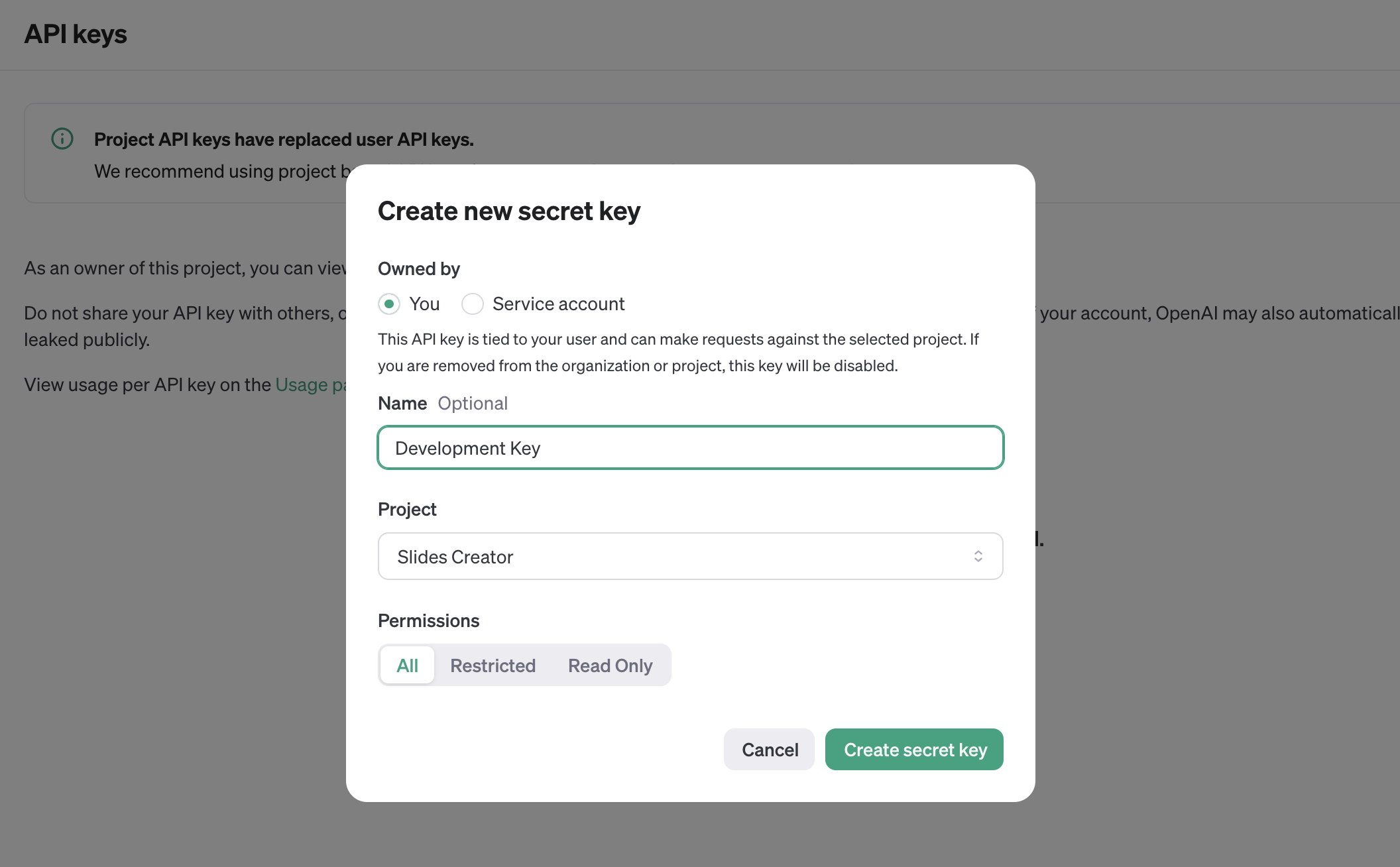
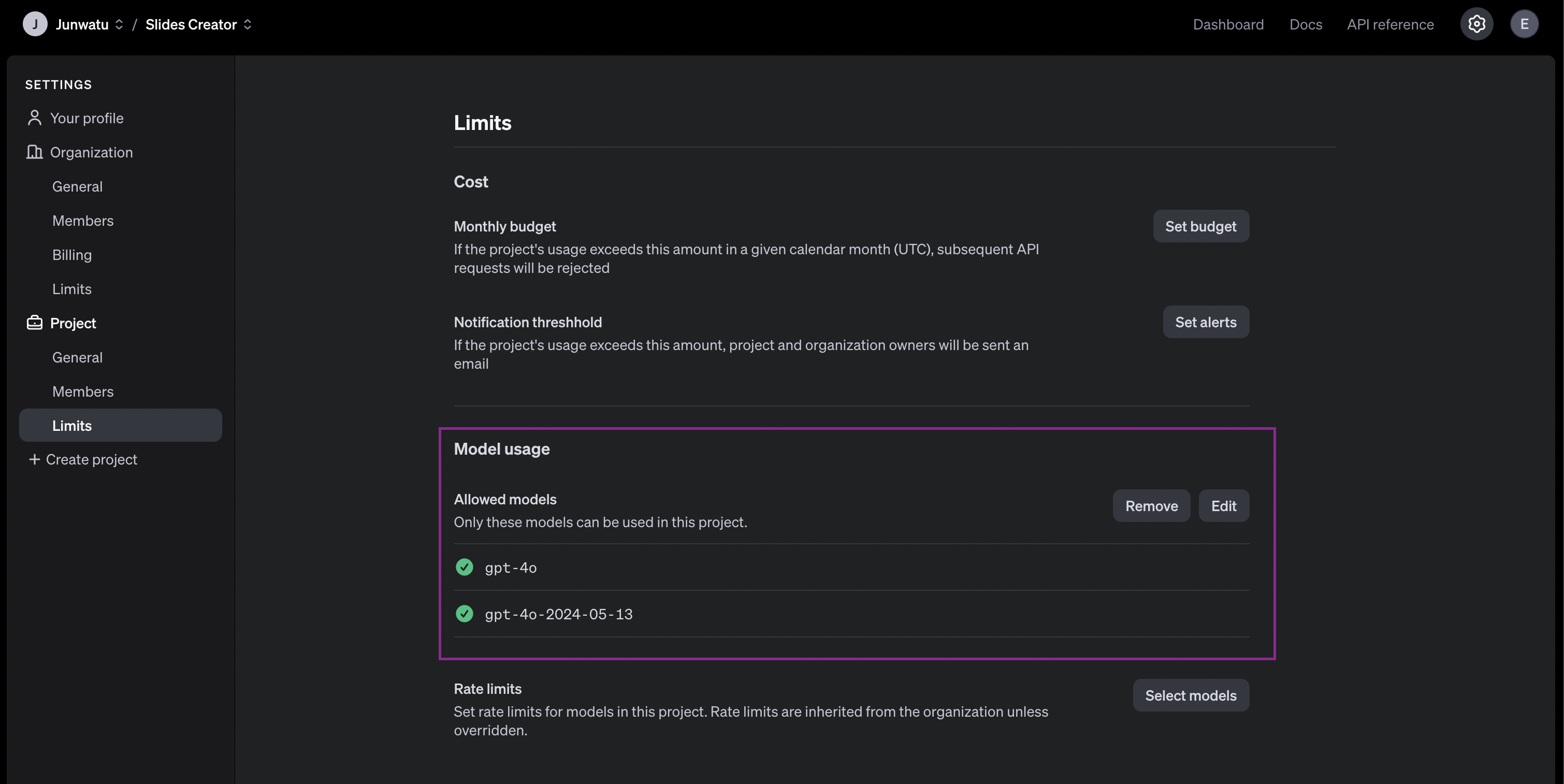
プロジェクトで使用するモデルを有効にする必要もある。このプロジェクトでは、gpt-4oモデルが必要です。プロジェクトの設定で、有効にするモデルを選択します。
.envファイルにOpenAIのキーを保存し、.gitignore`に追加してバージョン管理に含めないようにします。
4. AIアシスタントのセットアップ
このプロジェクトにはAIアシスタントが必要です。プロジェクトのダッシュボードに行き、新しいアシスタントを作成します。
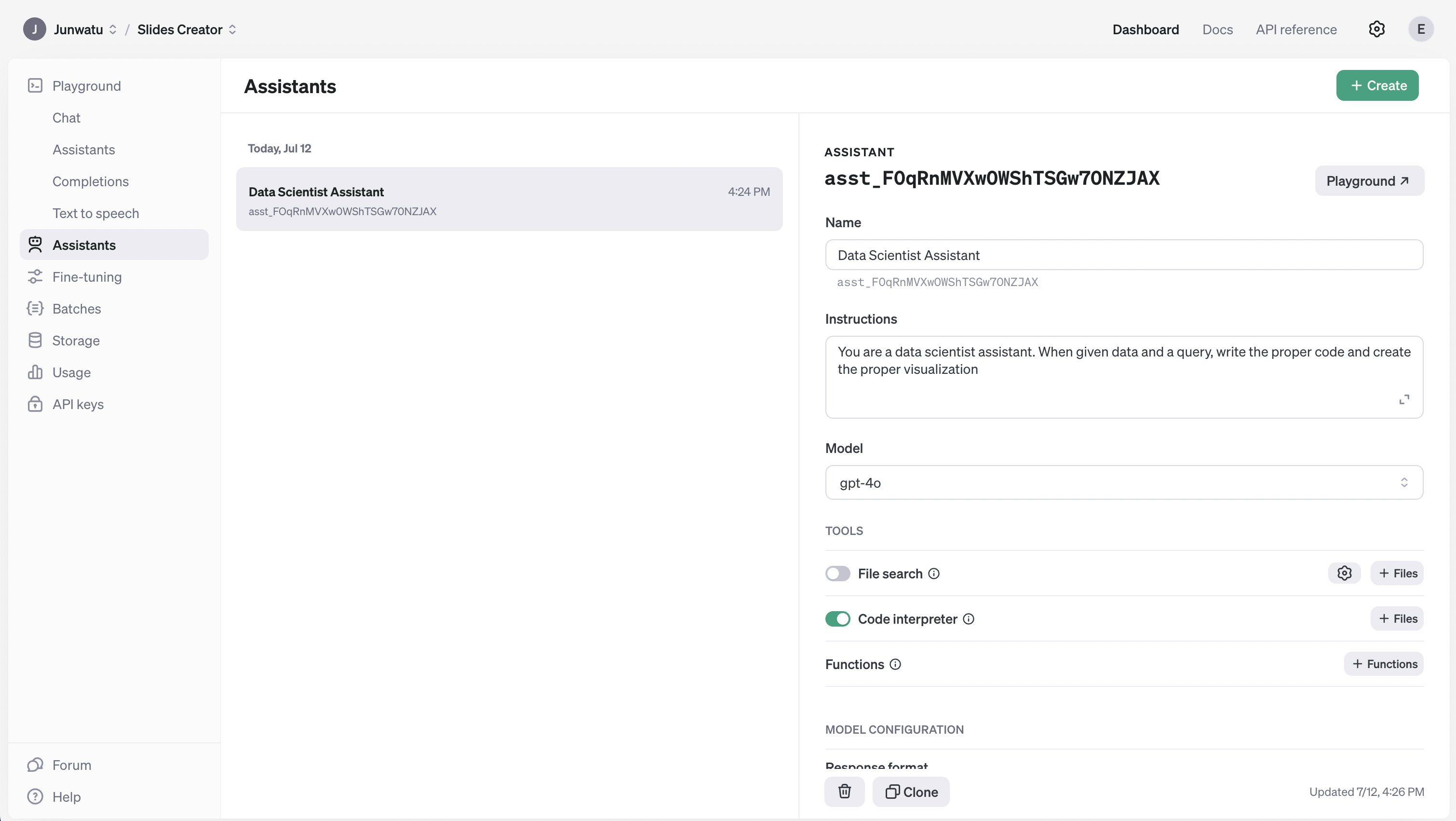
Instruction**フィールドに注意を払う必要があります。これはこのアシスタントに使われる命令です:
You are a data scientist assistant. When given data and a query, write the proper code and create the proper visualization.これはアシスタントがサンドボックス環境でコードを実行できるようになり、プロンプトがコードを実行できるようになることを意味します。この機能の詳細については、こちらをクリックしてください。
AIアシスタント作成後、アシスタントIDをコピーする必要があります。このIDは、あなたがアシスタントにメッセージを送信できるコード内の参照として使用されます。
const dataScienceAssistantId = "asst_FOqRnMVXw0WShTSGw70NZJAX"データの例
このプロジェクトでは、自動車のスペアパーツ販売のJSONデータサンプルを使用します。データは data ディレクトリにあります。これは2020年から2024年までのスペアパーツ販売データです:
[
{
"Year": 2020,
"Quarter": "Q1",
"Distribution channel": "Online Sales",
"Revenue ($M)": 2.10,
"Costs ($M)": 1.905643,
"Customer count": 190,
"Time": "2020 Q1",
"Product Category": "Engine Parts",
"Region": "North America",
"Units Sold": 900,
"Average Sale Price ($)": 2333,
"Discounts Given ($)": 14000,
"Returns ($)": 4500,
"Customer Satisfaction Rating": 8.2,
"Salesperson": "SP120",
"Marketing Spend ($)": 18000
},
{
"Year": 2020,
"Quarter": "Q1",
"Distribution channel": "Direct Sales",
"Revenue ($M)": 2.15,
"Costs ($M)": 2.004112,
"Customer count": 200,
"Time": "2020 Q1",
"Product Category": "Brakes",
"Region": "Europe",
"Units Sold": 1000,
"Average Sale Price ($)": 2150,
"Discounts Given ($)": 12000,
"Returns ($)": 5000,
"Customer Satisfaction Rating": 8.0,
"Salesperson": "SP121",
"Marketing Spend ($)": 19000
},
...
{
"Year": 2024,
"Quarter": "Q2",
"Distribution channel": "Direct Sales",
"Revenue ($M)": 3.15,
"Costs ($M)": 2.525112,
"Customer count": 390,
"Time": "2024 Q2",
"Product Category": "Brakes",
"Region": "Europe",
"Units Sold": 1500,
"Average Sale Price ($)": 2095,
"Discounts Given ($)": 22000,
"Returns ($)": 17000,
"Customer Satisfaction Rating": 9.1,
"Salesperson": "SP144",
"Marketing Spend ($)": 38000
}
]理想的には、データはユーザーインターフェース経由でアップロードされるべきです。しかし、このプロジェクトでは簡単のため、データサンプルのドロップダウンからデータサンプルを選択すると、データが直接処理されます。
**OpenAIはどうやってファイルを直接処理するのですか?
答えは、まずデータサンプルファイルを手動でアップロードする必要があります。プロジェクトのダッシュボードに行き、ファイルをアップロードします。
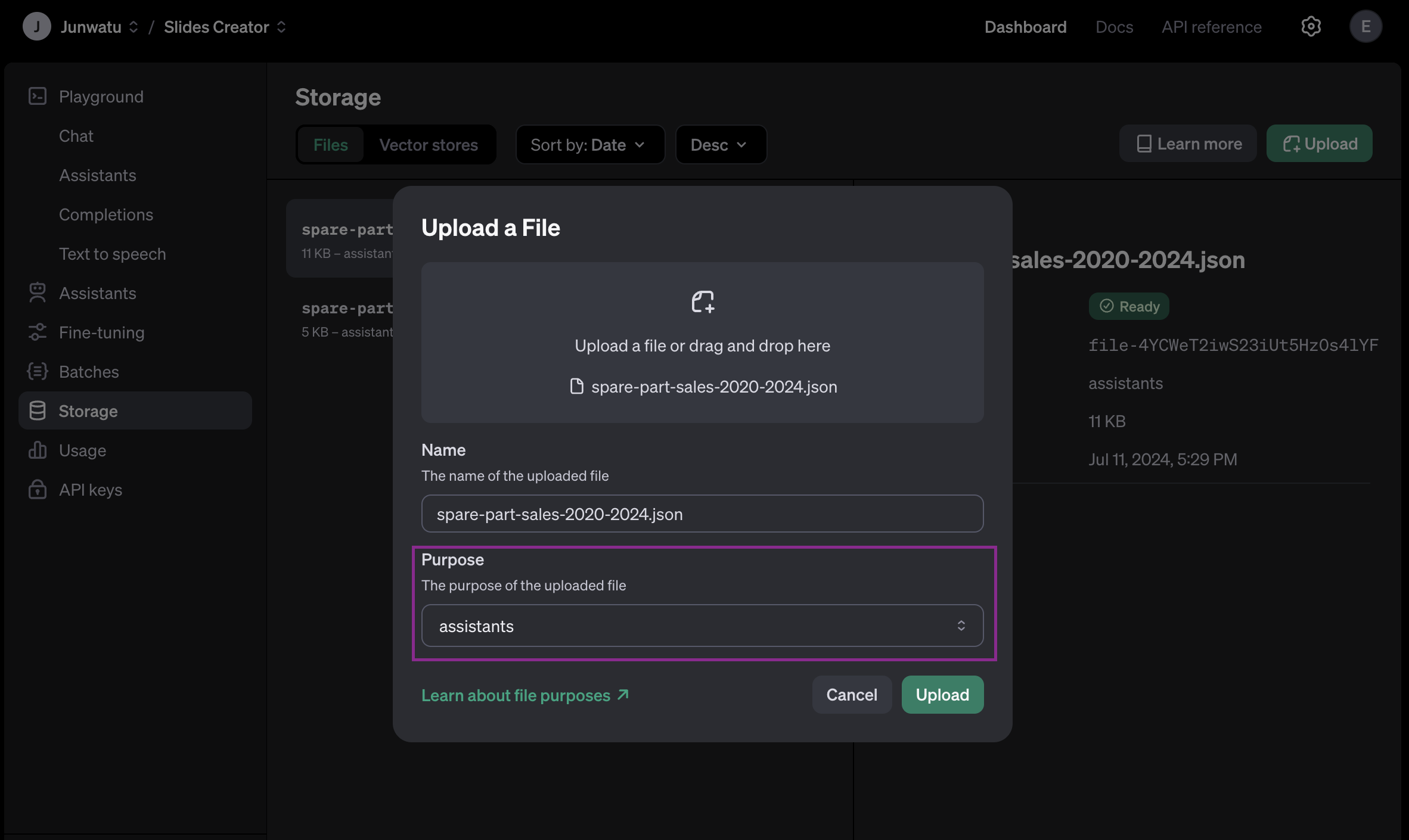
アップロードするファイルの目的に注意する必要があります。このプロジェクトでは、データサンプルファイルはアシスタントファイルとして使用されます。
後で、これらのファイルIDは、ユーザーがドロップダウンからデータサンプルを選択したときに、どのファイルが使用されるかを識別するために使用されます。
コンテンツの生成
ユーザーがデータサンプルを選択し、Create Slideボタンをクリックします。アシスタントAPIがコンテンツスライド用の画像とテキストを生成します。スライドコンテンツを生成するためのコードで重要なステップは次のとおりです:
1. データサンプルの分析
OpenAIは選択されたデータサンプルを分析し、四半期ごと、年度ごとに利益を計算し、プロットを視覚化します。
このプロセスのプロンプトは次のとおりです:
const analyzeDataPrompt = "Calculate the profit (revenue minus cost) by quarter and year, and visualize as a line plot across the distribution channels, where the colors of the lines are green, light red, and light blue"And this code will process the prompt and the selected file (see fileId)
const thread = await openai.beta.threads.create({
messages: [
{
"role": "user",
"content": analyzeDataPrompt,
"attachments": [
{
file_id: fileId,
tools: [{ type: "code_interpreter" }]
}
]
}
]
});このコードから、プロット画像を取得することができます。これはpublicディレクトリに保存され、スライドのコンテンツで使用されます。
2. 箇条書きの生成
AIアシスタントはデータに対する洞察を与え、箇条書きを生成します。これは、AIにデータに関する2つの洞察を与えるように指示するプロンプトです:
const insightPrompt = `Give me two medium-length sentences (~20-30 words per sentence) of the most important insights from the plot you just created, and save each sentence as an item in one array. Give me a raw array, no formatting, no commentary. These will be used for a slide deck, and they should be about the 'so what' behind the data.`3. インサイトタイトルの生成
最後のステップは、インサイトのタイトルを生成することです。これはそのためのプロンプトです:
const titlePrompt = "Given the plot and bullet point you created, come up with a very brief title only for a slide. It should reflect just the main insights you came up with."スライドコンテンツを生成するための完全なコードは、libs/ai.jsファイルにあります。
スライドの生成
このプロジェクトではPptxGenJSパッケージを使用してスライドを生成します。libs/pptx.js`ファイルに完全なコードがあります。
これはAIが生成したスライド情報の準備ができたときに createPresentation() 関数を呼び出すコードです。
//...
if (bulletPointsSummary.status === "completed") {
const message = await openai.beta.threads.messages.list(thread.id)
const dataVisTitle = message.data[0].content[0].text.value
presentationOptions = {
title: slideTitle,
subtitle: slideSubtitle,
dataVisTitle: dataVisTitle,
chartImagePath: path.join(__dirname, "public", `${filename}`),
keyInsights: "Key Insights:",
bulletPoints: bulletPoints,
outputFilename: path.join(__dirname, 'public', pptxFilename)
};
try {
createPresentation(presentationOptions)
} catch (error) {
console.log(error)
}
}
//...生成されたプレゼンテーションファイルは public ディレクトリにそれぞれユニークな名前で保存されることに注意してください。
スライド情報
スライド情報を保存するために、GridDBデータベースを使用する。以下はデータベースフィールドのドキュメントです:
| Field Name | Type | Description |
|---|---|---|
| id | INTEGER | 各レコードの一意な識別子。これはコンテナの主キーであり、エントリごとに一意でなければなりません。 |
| title | STRING | スライドのメインタイトル。スライドの内容を要約した短い説明的なタイトルです。 |
| subtitle | STRING | 副題や小見出しは、主題に関連する追加的な文脈や簡単な説明を提供します。 |
| chartImage | STRING | ビジュアルなデータ表現をリンクするために使用される、スライドに関連付けられたチャートの画像のURLまたはパス。 |
| bulletPoints | STRING | スライドの重要な情報やハイライトを要約した箇条書きを含む文字列。各箇条書きは通常、特殊文字または改行で区切られます。 |
| pptx | STRING | スライドを含むプレゼンテーションファイルをリンクするために使用されます、スライドを含むPowerPointファイル(.pptx)のURLまたはパス。 |
griddbservices.jsとlibs/griddb.js`ファイルはすべてのスライド情報をデータベースに保存する役割を担っています。
サーバのルート
Node.jsサーバーはクライアントのためにいくつかのルートを提供します。これはルートの完全なドキュメントです:
| Method | Route | Description |
|---|---|---|
| GET | / |
「dist」フォルダから「index.html」ファイルを配信します 。 |
| GET | /create/:fileId |
AIアシスタントを起動してファイルを処理し、プレゼンテーションを作成します。保存状況とPPTXファイル名を返します。 |
| GET | /metadata |
data ディレクトリから metadata.json ファイルを読み込みます。 |
| GET | /data/files |
data ディレクトリ内のすべての JSON ファイル名をリストアップします。 |
| GET | /data/files/:filename |
data ディレクトリから特定の JSON ファイルを読み込みます。 |
| GET | /slides |
データベースからすべてのスライドデータを取得します。 |
最も重要なルートは/create/:fileIdで、AIアシスタントがデータサンプルを分析し、プレゼンテーションを作成し、すべてのスライド情報をデータベースに保存するトリガーとなります。
app.get('/create/:fileId', async (req, res) => {
const fileId = req.params.fileId
try {
const result = await aiAssistant(fileId)
if (result.status === "completed") {
const {
title: titlePptx,
subtitle: subtitlePptx,
dataVisTitle: dataVisTitlePptx,
chartImage: chartImagePptx,
bulletPoints: bulletPointsPptx,
outputFilename: pptxFile
} = result.data
const saveDataStatus = await saveData({ titlePptx, subtitlePptx, dataVisTitlePptx, chartImagePptx, bulletPointsPptx, pptxFile })
res.json({
save: saveDataStatus,
data: result.data,
pptx: result.pptx
})
} else {
res.status(500).json({
error: 'Task not completed', status: result.status
})
}
} catch (error) {
console.error('Error in AI Assistant:', error)
res.status(500).json({ error: 'Error in AI Assistant', details: error.message })
}
})aiAssistant()関数はデータサンプルを分析し、スライドに関するすべての情報を返すプレゼンテーションを作成し、saveData()`関数を使用してそれらのスライド情報をGridDBデータベースに保存します。
すべてのスライドデータを取得するには、/slidesルートにアクセスするだけで、データベースに保存されたすべてのスライドデータが返されます。
ユーザーインターフェース
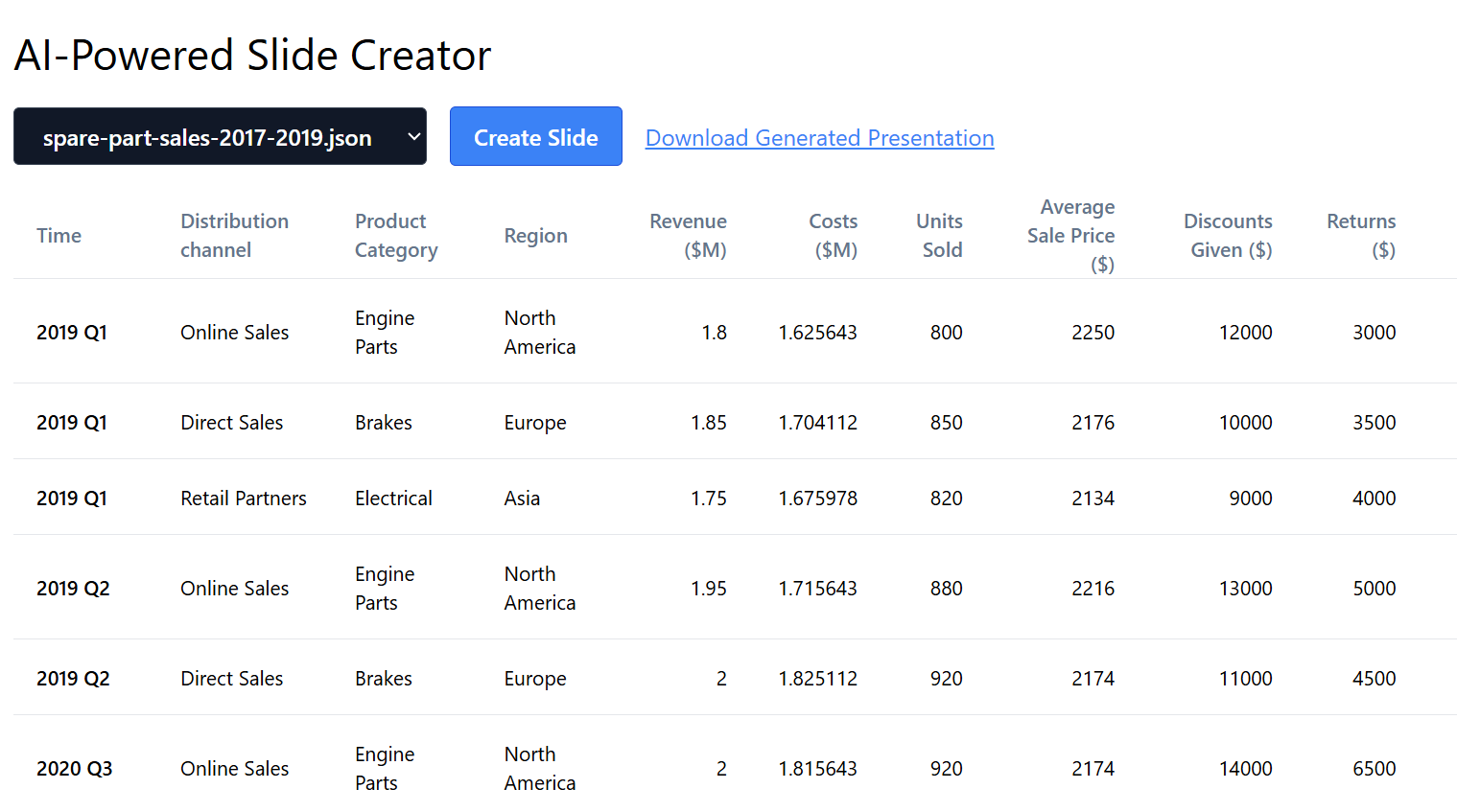
メイン・ユーザー・インターフェースは2つのコンポーネントで構成されています:
- データ・ドロップダウン: データサンプルを選択します。
- スライドボタンの作成: プレゼンテーション作成のトリガー
- 生成されたプレゼンテーション・リンクのダウンロード: プレゼンテーションファイル
.pptxのダウンロードリンクです。
さらなる強化
これは静的なデータサンプルによるプロトタイププロジェクトです。本番環境では、データをアップロードし、プロンプトをカスタマイズするためのより良いユーザーインターフェイスを提供することが理想的です。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.