
OpenAIに代表されるAI技術の進歩により、これまで手動では面倒すぎて実行できなかったタスクを自動化できるようになってきました。その一例が動画要約です。従来、動画コンテンツの要約は主に人間の視覚と聴覚に頼っていました。しかし、GPT-4やWhisperなどのAIモデルにより、このタスクを自動化できるようになりました。
OpenAI、Node.js、React、GridDBといった技術を活用します。本ブログでは、動画をアップロードし、その内容の要約を受け取るための基本的なWebアプリケーションを作成する方法を学びます。
はじめに
ソースコードは以下から入手できます。 $ git clone https://github.com/griddbnet/Blogs --branch voice_summarizer
このプロジェクトは Ubuntu 20.04 LTS で実行されています。このプロジェクトを実行するために必要な必須のスタック要件は以下の通りです。
OpenAI キー
OpenAI のサービスにアクセスするには、有効なキーが必要です。こちらのリンクにアクセスし、新しい OpenAI キーを作成してください。
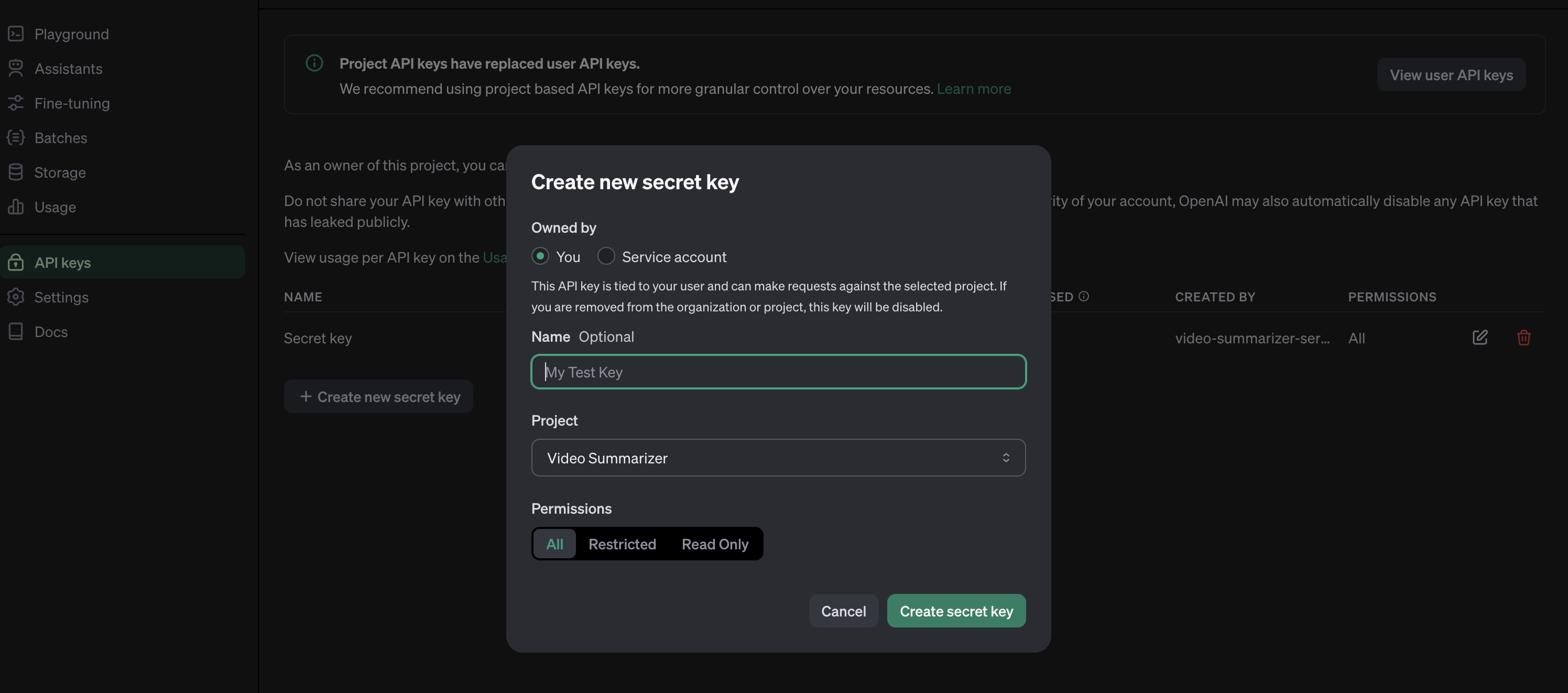
OpenAIキーはプロジェクトベースなので、まずOpenAIプラットフォームでプロジェクトを作成する必要があります。また、プロジェクトで使用するモデルを有効にする必要があります。このプロジェクトでは、gpt-4oとwhisperモデルが必要です。
OpenAIキーは .env ファイルに保存され、.gitignore に追加することでバージョン管理に含めないようにします。
Node.js
このプロジェクトはNode.jsプラットフォーム上で実行されます。こちらからインストールする必要があります。この プロジェクトでは、パッケージマネージャー nvm とNode.js v16.20.2 LTSバージョンを使用します。
# installs nvm (Node Version Manager)
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
# download and install Node.js
nvm install 16
# verifies the right Node.js version is in the environment
node -v # should print `v16.20.2`
# verifies the right NPM version is in the environment
npm -v # should print `8.19.4``Node.jsとGridDBデータベースを接続するには、GridDB CクライアントとNodeアドオンAPIを使用して開発されたNode.jsバインディングであるgridb-node-api npmパッケージが必要です。
FFmpeg
このプロジェクトでは、fluent-ffmpeg npmパッケージを使用します。このパッケージを使用するには、システムにFFmpegがインストールされている必要があります。Ubuntuの場合は、次のコマンドでインストールできます。
sudo apt update
sudo apt install ffmpegインストールに関するより詳しい情報は、FFmpeg公式ウェブサイトをご覧ください。
GridDB
動画サマリーと動画データを保存するために、GridDBデータベースを使用します。詳しいインストール方法はガイドをご覧ください。ここではUbuntu 20.04 LTSを使用します。
GridDBを起動し、サービスが実行されていることを確認します。次のコマンドを使用します。
sudo systemctl status gridstore実行していない場合は、このコマンドでデータベースを実行してみてください。
sudo systemctl start gridstoreプロジェクトを実行する
ソースコードを取得する
プロジェクトを実行するには、このリポジトリからコードをクローンする必要があります。
ソースコードを取得するには、このコマンドを実行します。
git clone https://github.com/junwatu/video-summarizer-nodejs-griddb.gitディレクトリを app フォルダに変更し、プロジェクトの依存関係をインストールするには、次のコマンドを使用します。
cd video-summarizer-nodejs-griddb
npm install.env の設定
このプロジェクトでは、いくつかの環境変数が必要です。 env.example ファイルを .env ファイルにコピーします。
cp .env .example .envこのファイルの環境変数を入力する必要があります。
OPENAI_API_KEY=sk-....
VITE_API_URL=http://localhost:3000VITE_API_URL 環境変数を変更するたびにプロジェクトを再起動する必要があることに注意してください。
プロジェクトの開始
プロジェクトを実行するには、次のコマンドを実行します。
npm run start:buildウェブアプリを開く
ブラウザでウェブアプリを開きます。デフォルトのURLは http://localhost:3000 です。任意の動画をアップロードします。処理を早く行うには短い動画をアップロードすることをお勧めします。test/video フォルダ内の動画を使用することもできます。動画の長さにもよりますが、処理には1分ほどかかります。 
仕組み
このプロジェクトまたはウェブアプリのユーザーフローは、ウェブアプリを開き、動画をアップロードし、処理を待ち、要約結果を受け取るというものです。アップロードされたユーザー動画の要約には、OpenAIのGPT-4oとWhisperモデルを使用します。OpenAIのモデルは動画を直接処理できないため、このプロジェクトでは2つのモデルが必要となります。ただし、画像や音声ファイルの処理は可能です。一方、Node.jsでは、動画を画像と音声ファイルに分離するために、fluent-ffmpegというnpmパッケージを使用します。
これらは、OpenAIモデルに動画を入力して要約処理を行う前に、動画に対して行う主な準備ステップです。
1. 動画の処理
動画をそのままAPIに送ることはできないが、フレームをサンプリングして画像として提供すれば、GPT-4oは動画を理解できる。このタスクでは、以前のGPT-4 Turboモデルよりも高い性能を発揮する。
この関数 extractFrames() は、動画ファイルから画像を抽出し、frames フォルダに保存する。
export function extractFrames(videoPath, secondsPerFrame, outputFolder) {
return new Promise((resolve, reject) => {
const frameRate = 1 / secondsPerFrame
const framePattern = path.join(outputFolder, 'frame-%03d.png')
ffmpeg(videoPath)
.outputOptions([`-vf fps=${frameRate}`])
.output(framePattern)
.on('end', () => {
fs.readdir(outputFolder, (err, files) => {
if (err) {
reject(err)
} else {
const framePaths = files.map(file => path.join(outputFolder, file))
resolve(framePaths)
}
})
})
.on('error', reject)
.run()
})
}関数 extractFrames において、パラメータ secondsPerFrame は、動画から抽出したいフレーム間の間隔を定義します。具体的には、secondsPerFrame は、抽出される各フレームの間隔を何秒にするかを決定します。
以下にその仕組みを示します。
フレームレートの計算:フレームレートは、secondsPerFrame の逆数として計算されます。つまり、frameRate = 1 / secondsPerFrame となります。これは、次のことを意味します。
secondsPerFrameが 1 の場合、フレームレートは毎秒 1 フレームとなります。secondsPerFrameが 0.5 の場合、フレームレートは毎秒 2 フレームとなります。- secondsPerFrame が 2 の場合、フレームレートは毎秒 0.5 フレーム(2 秒に 1 フレーム)となります。
2. 画像処理
GPT-4oモデルは画像を直接処理し、画像に基づいてインテリジェントなアクションを取ることができます。画像は2つの形式で提供できます。 * Base64 Encoded * URL
このプロジェクトでは、画像に base64 エンコードを使用します。関数 imageToBase64() は各画像ファイルを読み込み、base64 エンコード画像に変換します。
export function imageToBase64(imagePath) {
return new Promise((resolve, reject) => {
fs.readFile(imagePath, (err, data) => {
if (err) {
reject(err)
} else {
const base64String = data.toString('base64')
resolve(base64String)
}
})
})
}3. 音声抽出
より良い文脈要約を行うために、OpenAIモデルに音声を追加することができます。ビデオから音声を抽出するには、npmのfluent-ffmpegも使用できます。音声結果はmp3形式で、audioディレクトリに保存されます。
// Function to extract audio from video
export function extractAudio(videoPath, audioPath) {
return new Promise((resolve, reject) => {
ffmpeg(videoPath)
.output(audioPath)
.audioBitrate('32k')
.on('end', resolve)
.on('error', reject)
.run()
})
}4. 音声の書き起こし
音声を抽出した後、音声認識モデルWhisperを使用して音声をテキストに書き起こす必要があります。
async function transcribeAudio(filePath) {
try {
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream(filePath),
model: 'whisper-1'
})
return transcription.text
} catch (error) {
throw new Error(`Transcription failed: ${error.message}`)
}
}transcribeAudio() は、whisper-1 AIモデルを使用してオーディオファイルをテキストに変換します。この音声テキスト変換モデルの動作の詳細については、こちらをご覧ください。
ビデオ処理、画像処理、および音声抽出用のコードは、ファイル libs/videoProcessing.js にあります。
ビデオ要約プロセス
ビデオ要約は、ビデオの視覚および音声の書き起こし要素を同時にモデルに入力することで作成されます。これらの両方の入力を提供することで、モデルはビデオ全体を一度に把握できるため、より正確な要約を作成できると期待されます。
// Generate a summary with visual and audio transcription
import OpenAI from "openai";
const openai = new OpenAI({
// eslint-disable-next-line no-undef
apiKey: process.env.OPENAI_API_KEY
});
async function createVideoSummarization(frames, audioTranscription) {
const frameObjects = frames.map(x => ({
type: 'image_url',
image_url: {
url: `data:image/jpg; base64, ${x}`,
detail: 'low'
}
}));
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [{
role: "system",
content: "You are generating a video summary. Please provide a summary of the video. Respond in Markdown."
}
,
{
role: "user",
content: [{
type: 'text',
text: "These are the frames from the video."
}
,
...frameObjects,
{
type: 'text',
text: `The audio transcription is: ${audioTranscription}`
}
],
}
,
],
temperature: 0,
});
console.log(response.choices[0].message.content);
return response;
}
export { createVideoSummarization }content` パラメータは配列であり、テキストや画像を含めることができます。 動画の要約、画像フレームの追加、より適切な文脈のための音声テキストの転写などのプロンプトを追加することができます。 パラメータの詳細については、Chat API のドキュメントを参照してください。
ビデオの概要をGridDBに保存
ビデオの概要、ビデオのファイルパス、および音声の書き起こしを保存するために、GridDBデータベースが利用されています。これらのデータを保存するコードは、griddbservices.jsファイル内にあります。
export async function saveData({ filename, audioTranscription, summary }) {
const id = generateRandomID();
const videoFilename = String(filename);
const audioToText = String(audioTranscription);
const videoSummary = String(summary);
const packetInfo = [parseInt(id), videoFilename, audioToText, videoSummary];
const saveStatus = await GridDB.insert(packetInfo, collectionDb);
return saveStatus;
}ここでは3つの重要な分野があります。
| パラメータ | タイプ | 説明 |
|---|---|---|
ファイル名 |
String | ビデオファイル名. |
音声文字起こし |
String | 動画の音声を書き起こしたもの。 |
まとめ |
String | 動画コンテンツの概要。 |
saveData関数は、GridDBにデータを保存するためのラッパーです。データを実際に保存するコードは、libs/griddb.cjs` ファイルにあります。
すべてのサマリーを取得
すべてのサマリーデータは、/summaries ルートでアクセスできます。デフォルトのURLは次のとおりです。
http://localhost:3000/summariesレスポンスはJSONデータであり、プロジェクトにさらなる機能や拡張が必要な場合、クライアント側で簡単に処理できます。
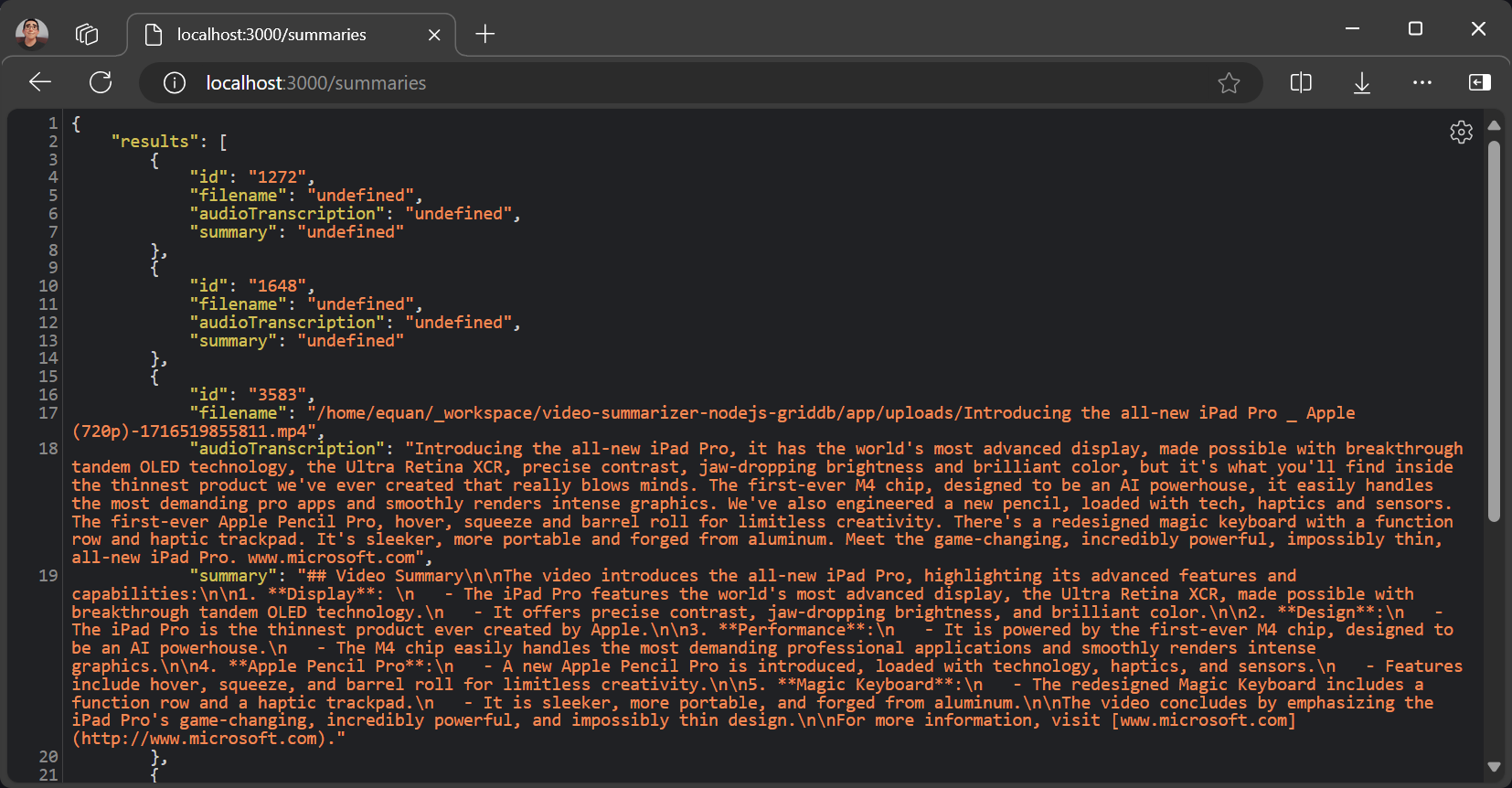
制限
このプロジェクトはプロトタイプであり、動画の長さが5分を超えないMP4動画でテストされています。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.