本記事では、GridDBに対してCRUD(Create、Read、Update、Delete)操作を行うための自然言語クエリの使用方法を説明します。PythonのLangChainモジュールとOpenAI GPT-4o LLM(自然言語クエリをGridDBクエリに変換し、GridDB上でさまざまな操作を行うための大規模言語モデル)を使用します。
GridDBは、大量のリアルタイムデータを処理するように設計された堅牢なNoSQLデータベースです。スケーラビリティに優れ、高度なインメモリ処理機能と効率的な時系列データ管理機能を提供します。これらの機能により、GridDBはIoT(モノのインターネット)やビッグデータアプリケーションに最適です。
ソースコードとJupyter Notebook
ソースコード(Jupyter Notebook)は、GitHubのリポジトリから入手できます。
$ git clone https://github.com/griddbnet/Blogs.git --branch crud_with_langchain前提条件
PythonアプリケーションをGridDBに接続するには、GridDB CクライアントとGridDB Pythonクライアントをインストールする必要があります。これらのクライアントのインストール手順については、GridDB Python Package Index (Pypi)ページを参照してください。
自然言語クエリをGridDBクエリに変換するために、OpenAI GPT-4oという大規模言語モデル(LLM)を使用します。GPT-4oモデルを使用するには、OpenAIのアカウントを作成し、APIキーを取得する必要があります。最後に、LangChainフレームワークからOpenAI APIにアクセスするために、以下のライブラリをインストールする必要があります。
!pip install langchain
!pip install langchain-core
!pip install langchain-openai注:GPT-4oを使用したくない場合は、LangChainがサポートする他のLLMを使用することもできます。対応するライブラリをインストールする必要があることを除いて、プロセスは同じです。
以下のスクリプトは、このブログのコードを実行するために必要なライブラリをインポートします。
import griddb_python as griddb
import pandas as pd
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List, DictGridDBとの接続の作成
最初のステップは、GridDBとの接続を作成することです。そのためには、get_instance() メソッドを使用してGridDB StoreFactory インスタンスを作成する必要があります。次に、データベースホスト、クラスタ名、管理者、パスワードを get_store() メソッドに渡す必要があります。このメソッドは、GridDBのCRUD操作を実行するために使用できるGridDBストアオブジェクトを返します。次のスクリプトは、GridDB 接続を作成し、ランダムなコンテナを取得することでテストします。
factory = griddb.StoreFactory.get_instance()
DB_HOST = "127.0.0.1:10001"
DB_CLUSTER = "myCluster"
DB_USER = "admin"
DB_PASS = "admin"
try:
gridstore = factory.get_store(
notification_member = DB_HOST,
cluster_name = DB_CLUSTER,
username = DB_USER,
password = DB_PASS
)
container1 = gridstore.get_container("container1")
if container1 == None:
print("Container does not exist")
print("Successfully connected to GridDB")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))出力:
Container does not exist
Successfully connected to GridDB接続が確立されたら、以降のセクションで説明するように、LangChainフレームワークを使用して自然言語クエリを実行し、GridDB上でCRUD操作を行うことができます。
LangChainを使用した自然言語コマンドによるデータの挿入
前述のとおり、OpenAI GPT-4o LLM を使用して自然言語クエリを解析し、GridDB クエリに変換します。 これを行うには、ChatOpenAI クラスのオブジェクトを作成し、OpenAI API キー、温度、モデル名を渡す必要があります。
温度を高くすると、モデルの創造性が高まります。 しかし、モデルにはより正確な結果を出力させたいので、ここでは温度を 0 に設定します。
llm = ChatOpenAI(api_key="YOUR_OPENAI_API_KEY",
temperature = 0,
model_name = "gpt-4o")
自然言語クエリをGridDBクエリに変換するために、以下のアプローチを採用します。
1.自然言語クエリから、LLMを使用して、GridDBクエリを実行するために必要なエンティティを抽出します。 2.これらのエンティティをGridDBクエリに埋め込み、GridDBに対するCRUD操作を実行します。これらの値を自然言語クエリからエンティティとして抽出するには、まずPydanticの BaseModel 子クラスを作成し、これらのエンティティを属性として追加します。クラスの属性の記述に基づいて、LLMは自然言語クエリから抽出したデータをこれらの属性に格納します。以下のスクリプトは、挿入エンティティを抽出するためのpydantic InsertData クラスを作成します。
class InsertData(BaseModel):
column_names: List[str]= Field(description="All the column names from the structured data")
column_types: List[str] = Field(description="All the column types from the structured data")
column_values: List[List[str]] = Field(description="All the column values from the structured data")
container_name: str = Field(description="Name of container extracted from the user query")次に、自然言語から抽出すべき情報をLLMに伝えるLangChainチェーンを作成します。with_structured_output()メソッドを使用し、先に作成したInsertData pydanticクラスを渡します。LLMは、InsertDataクラスで説明されている属性で構成された辞書を返します。
system_command = """ You are an expert who extracts structure from natural language queries that must be converted to database queries.
Parse the user input query and extract the container name and column names along with their types from the user query and the user records.
The types should be parsed as STRING, LONG, FLOAT, INTEGER
"""
user_prompt = ChatPromptTemplate.from_messages([
("system", system_command ),
("user", "{input}")
])
insert_chain = user_prompt | llm.with_structured_output(InsertData)LLMをテストするために、データベースにデータを挿入する自然言語クエリを作成してみましょう。このクエリを、前のスクリプトで作成した insert_chain に渡し、抽出されたエンティティを表示します。
user_query = """
Insert the following student records into the student_data container.
Name = Michael
Age = 10
Gender = Male
Grade = A
Name = Sara
Age = 11
Gender = Female
Grade = C
Name = Nick
Age = 9
Gender = Male
Grade = B
"""
user_data = insert_chain.invoke({"input": user_query})
print(user_data.column_names)
print(user_data.column_types)
print(user_data.column_values)
print(user_data.container_name)出力:

上記の出力から、LLMがエンティティを正常に抽出したことがわかります。
残りの処理は単純です。抽出したエンティティを、GridDBコンテナにデータを挿入するスクリプトに埋め込みます。
以下のスクリプトでは、2つのヘルパー関数を定義しています。convert_list_of_types()関数は、抽出した文字列カラムの型をGridDBカラムの型に変換します。
同様に、LLMによって抽出されたカラム値は文字列形式です。しかし、これらの値の一部は整数です。文字列値を整数形式に変換してカラムタイプに一致させます。try_convert_to_int()関数がこれを行います。
str_to_griddb_type = {
"LONG": griddb.Type.LONG,
"INTEGER": griddb.Type.INTEGER,
"STRING": griddb.Type.STRING,
"FLOAT": griddb.Type.FLOAT,
# Add other types as needed
}
# Function to convert a list of string types to GridDB types
def convert_list_of_types(type_list):
try:
return [str_to_griddb_type[type_str] for type_str in type_list]
except KeyError as e:
raise ValueError(f"Unsupported type string: {e.args[0]}")
def try_convert_to_int(value):
try:
return int(value)
except ValueError:
return value
自然言語クエリをGridDBのデータ挿入クエリに変換する準備が整いました。これを行うには、以下のスクリプトで示すように、insert_records()関数を定義します。この関数は、自然言語クエリを受け取り、LangChainのGPT-4o LLMを使用してクエリからエンティティを抽出し、エンティティをGridDBクエリに埋め込み、データをGridDBに挿入します。
def insert_records(query):
user_data = insert_chain.invoke({"input": query})
container_name = user_data.container_name
column_names = user_data.column_names
column_values = user_data.column_values
column_values = [[try_convert_to_int(item) for item in sublist] for sublist in column_values]
column_types = user_data.column_types
griddb_type = convert_list_of_types(column_types)
container_columns = []
for column_name, dtype in zip(column_names, griddb_type):
container_columns.append([column_name, dtype])
container_info = griddb.ContainerInfo(container_name,
container_columns,
griddb.ContainerType.COLLECTION, True)
try:
cont = gridstore.put_container(container_info)
for row in column_values:
cont.put(row)
print("All rows have been successfully stored in the GridDB container.")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))
insert_records(user_query)出力:
すべての行がGridDBコンテナに正常に格納されました。
上記のメッセージが表示された場合、データは正常に挿入されています。次に、このデータの選択方法を見てみましょう。
データの選択
自然言語クエリを使用してデータを抽出するプロセスも同様です。pydanticクラスを作成して、自然言語クエリからコンテナ名と抽出クエリを抽出します。LangChainチェーンを作成し、LLMにユーザーコマンドをSQLクエリに変換するよう指示します。
次のスクリプトは、これらのステップを実行します。
class SelectData(BaseModel):
container_name: str = Field(description="the container name from the user query")
query:str = Field(description="natural language converted to SELECT query")
system_command = """
Convert user commands into SQL queries for Griddb.
"""
user_prompt = ChatPromptTemplate.from_messages([
("system", system_command),
("user", "{input}")
])
select_chain = user_prompt | llm.with_structured_output(SelectData)次に、自然言語のクエリを受け取り、LLM を使用して SELECT クエリに変換し、GridDB からレコードを取得する関数 select_records を定義します。
def select_records(query):
select_data = select_chain.invoke(query)
container_name = select_data.container_name
select_query = select_data.query
result_container = gridstore.get_container(container_name)
query = result_container.query(select_query)
rs = query.fetch()
result_data = rs.fetch_rows()
return result_data
select_records("Give me student records from student_data container where Age is greater than or equal to 10")出力: 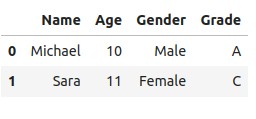
上記の出力から、LLMがWHERE句を含むSELECTクエリを生成し、Ageカラムの値が10以上である学生レコードのみを取得していることが分かります。
データの更新
自然言語でレコードを更新する方法も同じです。pydantic クラス UpdateData を作成し、コンテナ名、選択するレコード、カラム名、更新する値を抽出します。
次に、LLMにレコードの更新に必要なエンティティを取得させる update_chain を作成します。
class UpdateData(BaseModel):
container_name: str = Field(description="the container name from the user query")
select_query:str = Field(description="natural language converted to SELECT query")
column_name: str = Field(description="name of the column to be updated")
column_value: str = Field(description="Column value to be updated")
system_command = """
Convert user commands into SQL query as follows. If the user enters an Update query, return the following:
1. The name of the container
2. A SELECT query to query records in the update statement.
3. The name of the column to be updated.
4. The new value for the column.
"""
user_prompt = ChatPromptTemplate.from_messages([
("system", system_command),
("user", "{input}")
])
update_chain = user_prompt | llm.with_structured_output(UpdateData)そこで、自然言語によるユーザの問い合わせをレコードの更新用GridDBクエリに変換する関数 update_records() を定義します。
def update_records(query):
update_data = update_chain.invoke(query)
result_container = gridstore.get_container(update_data.container_name)
result_container.set_auto_commit(False)
query = result_container.query(update_data.select_query)
rs = query.fetch(True)
select_data = select_records(f"Select all records from {update_data.container_name}")
if rs.has_next():
data = rs.next()
column_index = select_data.columns.get_loc(update_data.column_name)
data[column_index] = int(update_data.column_value)
rs.update(data)
result_container.commit()
print("record updated successfully.")
update_records("Update the age of the students in the student_data container to 11 where Age is greater than or equal to 10")
You can select the following records to see if the data has been updated.
select_records(f"Select all records from student_data container")出力: 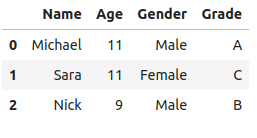
上記の出力は更新されたレコードを示しています。
データの削除
最後に、レコードを削除するプロセスも同様です。自然言語によるユーザーのクエリから削除するコンテナとレコードを抽出するpydanticのDeleteDataクラスを作成します。
LLMにユーザーが削除したいレコードを取得するselect文を返すよう指示するdelete_chainを作成します。
例えば、次のスクリプトを実行すると、学生の年齢が10歳以上の学生レコードを削除するためのselectクエリが返されます。
class DeleteData(BaseModel):
select_query:str = Field(description="natural language converted to SELECT query")
container_name: str = Field(description="the container name from the user query")
system_command = """
Given a user natural language query, return an SQL select statement which selects the records that user wants to delete
"""
user_prompt = ChatPromptTemplate.from_messages([
("system", system_command),
("user", "{input}")
])
delete_chain = user_prompt | llm.with_structured_output(DeleteData)
result_chain = delete_chain.invoke("Delete all records from student_data container whose Age is greater than 10")
print(result_chain)
出力:
select_query='SELECT * FROM student_data WHERE Age > 10' container_name='student_data'
次に、自然言語クエリを受け入れ、delete_chain を使用してレコードを削除するエンティティを抽出し、GridDB からレコードを削除する delete_records() メソッドを定義します。
def delete_records(query):
update_data = update_chain.invoke(query)
result_container = gridstore.get_container(update_data.container_name)
result_container.set_auto_commit(False)
query = result_container.query(update_data.select_query)
rs = query.fetch(True)
while rs.has_next():
data = rs.next()
rs.remove()
result_container.commit()
print("Records deleted successfully")
delete_records("Delete all records from student_data container whose Age is greater than 10")
すべてのレコードを選択して、レコードが削除されたかどうかを確認できます。
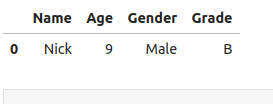
select_records(f"Select all records from student_data container")出力:
まとめ
本記事では、LangChainフレームワークとOpenAI GPT-4o LLMを使用した自然言語クエリでGridDBのCRUD操作を行う方法を学びました。PythonをGridDBに接続し、GridDBコンテナにデータを挿入し、自然言語コマンドを使用してレコードの選択、更新、削除を行う方法を調べました。GridDBは、大量のリアルタイムデータを効率的に管理するように設計された、拡張性の高いオープンソースデータベースです。IoTや時系列データの処理に優れており、高度なインメモリ処理能力を必要とするアプリケーションに最適です。
GridDBに関するご質問やお問い合わせは、Stack Overflowに投稿してください。当社のエンジニアが迅速に対応できるよう、griddbタグを使用してください。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.