
はじめに
最近のブログで、手動のバウンディングボックスを使った地理空間データのクエリについて紹介しました。今回のブログでは、同じデータセット・クエリと、バウンディングボックスの代わりにGeoHashesを使用してクエリを実行します。
GeoHashとは、地球上の地域を表す英数字のエンコードです。符号のビット数が多いほど、より正確なエリアを規定しています。1桁の長さのGeoHashは約2500kmをカバーし、8桁の長さのGeoHashは約20mをカバーします。例えば、9q のGeoHashはカリフォルニア州とアメリカ西部の大部分をカバーしていますが、カリフォルニア州内のサンフランシスコ ・サンノゼのベイエリアは 9qb, 9qc, 9q8, 9q9 と複数のGeoHashにまたがっています。
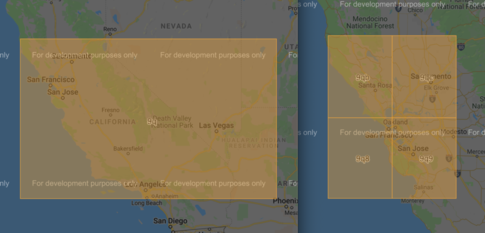
GeoHashは、このような様々なツールを使って簡単に視覚化することができます。
Java spatial4j GeoHashUtils
Geospatialアプリのインジェスト部分では、Javaを使用してNew York Open DataのCrime Complaint CSVファイルを読み込み、GridDBにロードしています。Java用のGeoHash実装はいくつかありますが、今回は最大の開発者コミュニティで最も普及していると思われるspatial4jのGeoHashUtilsを使ってデモンストレーションをします。以前のIngestツールからの変更点は単純で、緯度と経度をコンテナ名に操作する代わりに、6桁のGeohashを使用します。
String cName = "geo_"+GeohashUtils.encodeLatLon(c.Latitude, c.Longitude, 6);また、colum schemaにGEOHASHカラムが追加され、12桁の完全なGeoHashが格納されます。
c.GEOHASH=GeohashUtils.encodeLatLon(c.Latitude, c.Longitude);Pythonと近接Hashを使ったクエリ
開発者がより機能的なアプリケーションを実装できるように、GeoHashを実装・利用するライブラリは数多くあります。その一つが Proximityhash で、これは指定された点を中心とした円を、指定された半径で覆うようなGeoHashのリストを作成します。Proximityhash には、何桁のGeoHashを作成するかを示す精度の引数と、検索点の半径内に完全に収まっている場合に、より少ない、より精度の低いGeoHashを返す圧縮の引数があります。
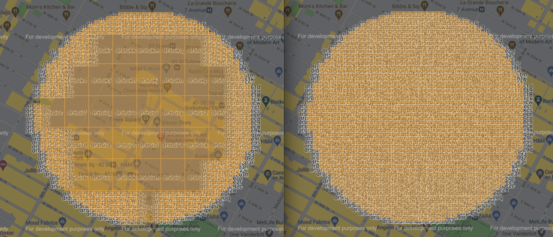
Proximityhashを使って、先ほど読み込んだデータを照会します。まず、どのコンテナに照会するかを把握するために6桁のGeoHashのリストを取得し、次に各コンテナに照会するGeoHashのリストを取得します。
radius_hashes = proximityhash.create_geohash(lat, lon, distance, 8, georaptor_flag=True).split(',')
container_hashes = proximityhash.create_geohash(lat, lon, distance, 6, georaptor_flag=False).split(',')次に、すべてのコンテナを反復処理して、次のようなTQL文を作成します。 SELECT * where geohash LIKE 'XXXXXXX%' or geohash LIKE 'YYYYYYY%' ....
クエリの最適化も行われており、クエリ対象のコンテナ内にあるGeoHashのみがTQL文に追加されます。
retval=[]
for container in container_hashes:
ts = gridstore.get_container("geo_"+container)
tql = "SELECT * WHERE "
orstmt=""
for geohash in radius_hashes:
if geohash.startswith(container):
tql = tql + orstmt + "geohash LIKE '"+geohash+"%'"
orstmt=" OR "
if orstmt != "":
try:
query = ts.query(tql)
rs = query.fetch(False)
while rs.has_next():
data = rs.next()
retval.append(data)
except:
passパフォーマンス
精度の異なるGeoHashを使ったクエリのパフォーマンスを、以前のブログで紹介した地理空間クエリの手動バウンディングボックスを使った方法と比較しました。
| 概要 | GeoHash数 | 時間(秒) |
|---|---|---|
| 手動バウンディングボックス | 0.005 | |
| 7桁 GeoHash | 59 | 0.007 |
| 8桁 GeoHash | 1522 | 0.15 |
| 8桁 圧縮GeoHash | 468 | 0.030 |
同じレベルの精度であれば、GeoHashの方がわずかに遅いだけであることが分かります。
まとめ
GeoHashは、データを手動で操作する必要がなく、他の方法に比べてパフォーマンスの低下が少ない、地理空間データの問い合わせに使用できる簡単な実装方法です。このブログに関する詳細なソースコードは、GridDB.net’s GitHubにあります。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb