
人工ニューラルネットワークとは?
人工ニューラルネットワーク(ANN)は機械学習のサブセットであり、深層学習アルゴリズムの中核をなすものです。その構造は人間の脳にヒントを得ており、生物学的なニューロンが互いに信号を送り合う方法を模倣しています。
ANNは、入力層、隠れ層、出力層を含むノード層で構成されています。各ノードは別のノードに接続され、重みと閾値が関連付けられています。特定のノードの出力が指定された閾値を超えると、そのノードが活性化され、データがネットワークの次の層に転送されます。そうでない場合は、次の層にデータは転送されません。
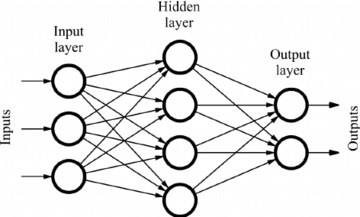
ニューラルネットワークのプログラマーは、データを使ってモデルを訓練し、時間をかけてその精度を高めていく必要があります。学習アルゴリズムの精度が微調整されると、予測のための強力なツールとなります。
データをGridDBに書き込む
今回は、ある銀行の顧客定着率アップのお手伝いをします。銀行を去る可能性が最も高い顧客を予測するニューラルネットワークモデルを実装します。使用するデータセットは、銀行の顧客の様々な詳細、例えばクレジットスコア、銀行残高、クレジットカードを持っているかどうか、アクティブかどうか、推定給与、などです。

データセットには全部で14の属性があります。CSVファイルからデータを読み込んで、GridDBに格納します。まず、これに使用するライブラリを全てインポートしましょう。
import java.io.IOException;
import java.util.Properties;
import java.util.Collection;
import java.util.Scanner;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowSet;
import java.io.File;このデータは Churn_Modelling.csv という名前の CSV ファイルに保存されています。このデータをGridDBコンテナに格納するので、コンテナスキーマを表現する静的クラスを作成します。
public static class BankCustomers {
@RowKey String rowNumber;
String surname, geography, gender, tenure, hasCrCard, isActiveMember;
int customerId, creditScore, age, numOfProducts, exited;
Double balance, estimatedSalary;
} 上記のクラスはSQLのテーブルに似ていて、変数がテーブルのカラムを表しています。
いよいよGridDBへの接続を確立します。GridDBのインストール情報を含むPropertiesインスタンスを作成します。
Properties props = new Properties();
props.setProperty("notificationAddress", "239.0.0.1");
props.setProperty("notificationPort", "31999");
props.setProperty("clusterName", "defaultCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);GridDB のインストール環境に合わせて、上記の内容を変更してください。
次に、BankCustomersコンテナを選択します。
Collection<String, BankCustomers> coll = store.putCollection("col01", BankCustomers.class);コンテナのインスタンスが作成され、collという名前が付けられました。このインスタンスはコンテナを参照する際に使用します。
それでは、CSV ファイルからデータを読み込んで、GridDB コンテナに格納します。以下のコードを使用します。
File file1 = new File("Churn_Modelling.csv");
Scanner sc = new Scanner(file1);
String data = sc.next();
while (sc.hasNext()){
String scData = sc.next();
String dataList[] = scData.split(",");
String rowNumber = dataList[0];
String customerId = dataList[1];
String surname = dataList[2];
String creditScore = dataList[3];
String geography = dataList[4];
String gender = dataList[5];
String age = dataList[6];
String tenure = dataList[7];
String balance = dataList[8];
String numOfProducts = dataList[9];
String hasCrCard = dataList[10];
String isActiveMember = dataList[11];
String estimatedSalary = dataList[12];
String exited = dataList[13];
BankCustomers bc = new BankCustomers();
bc.rowNumber = rowNumber;
bc.customerId = Integer.parseInt(customerId);
bc.surname = surname;
bc.creditScore = Integer.parseInt(creditScore);
bc.geography = geography;
bc.gender = gender;
bc.age = Integer.parseInt(age);
bc.tenure = tenure;
bc.balance = Double.parseDouble(balance);
bc.numOfProducts = Integer.parseInt(numOfProducts);
bc.hasCrCard = hasCrCard;
bc.isActiveMember = isActiveMember;
bc.estimatedSalary = Double.parseDouble(estimatedSalary);
bc.exited =Integer.parseInt(exited);
coll.append(bc);
}このコードは、CSVファイルからデータを読み込み、bcという名前のオブジェクトを作成しました。そしてこのオブジェクトはコンテナに追加されました。
GridDBからデータを取得する
これで、GridDBからデータを引き出すことができます。次のコードはその方法を示しています。
Query<bankcustomers> query = coll.query("select *");
RowSet<bankcustomers> rs = query.fetch(false);
RowSet res = query.fetch();select *ステートメントは、GridDBコンテナに格納されているすべてのデータを選択するのに役立ちます。
データの前処理
データセットにはカテゴリ変数があるため、ニューラルネットワークに与える前に変換します。データセットの最後のフィールドであるExitedは、顧客が銀行を去ったか否かを示しています。値 1 は顧客が銀行を出たことを示すので、この属性が出力ラベルとなります。
最初の3つの属性、すなわちRowNumber、CustomerId、Surnameは決定要因ではないので無視することができます。この結果、検討対象となる属性は10個となり、出力ラベルが決定されます。
GeographyとGenderの値は数値ではないので、数字に変換する必要があります。Gender ラベルはバイナリ値、つまり 0 か 1(男性/女性)にマッピングされます。Geography には複数の値があるので、1つのホットエンコーディングを使用して数値にエンコードすることにします。
DeepLearning4j(DL4J)ライブラリを使用して、このデータセットのスキーマを定義し、スキーマを変換処理に投入します。その後、エンコードと変換を経て、データを取得することができます。
まず、使用する追加ライブラリ一式をインポートしましょう。
import org.datavec.api.records.reader.RecordReader;
import org.datavec.api.records.reader.impl.transform.TransformProcessRecordReader;
import org.datavec.api.records.reader.impl.csv.CSVRecordReader;
import org.datavec.api.split.FileSplit;
import org.datavec.api.transform.TransformProcess;
import org.deeplearning4j.api.storage.StatsStorage;
import org.datavec.api.transform.schema.Schema;
import org.deeplearning4j.datasets.datavec.RecordReaderDataSetIterator;
import org.deeplearning4j.datasets.iterator.DataSetIteratorSplitter;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.ui.api.UIServer;
import org.deeplearning4j.ui.storage.InMemoryStatsStorage;
import org.deeplearning4j.ui.stats.StatsListener;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.NormalizerStandardize;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.learning.config.Adam;
import org.nd4j.linalg.io.ClassPathResource;
import org.nd4j.linalg.lossfunctions.impl.LossMCXENT;
import org.slf4j.LoggerFactory;
import org.slf4j.Logger;
import java.util.Arrays;
そして、以下のコードでスキーマを実装することができます。
private static Schema createSchema() {
final Schema scm = new Schema.Builder()
.addColumnString("rowNumber")
.addColumnInteger("customerId")
.addColumnString("surname")
.addColumnInteger("creditScore")
.addColumnCategorical("geography", Arrays.asList("France","Germany","Spain"))
.addColumnCategorical("gender", Arrays.asList("Male","Female"))
.addColumnsInteger("age", "tenure")
.addColumnDouble("balance")
.addColumnsInteger("numOfProducts","hasCrCard","isActiveMember")
.addColumnDouble("estimatedSalary")
.addColumnInteger("exited")
.build();
return scm;
}これでデータのスキーマができたので、変換処理に渡すことができるようになりました。次のコードはこれを示しています。
private static RecordReader dataTransform(RecordReader reader, Schema scm){
final TransformProcess transformation = new TransformProcess.Builder(scm)
.removeColumns("rowNumber","customerId","surname")
.categoricalToInteger("gender")
.categoricalToOneHot("geography")
.removeColumns("geography[France]")
.build();
final TransformProcessRecordReader transformationReader = new TransformProcessRecordReader(reader,transformation);
return transformationReader;
}このエンコーディングは geography ラベルをバイナリ値を持つ複数のカラムに変換する。例えば、データセットに3つの国がある場合、それらは3つの列にマッピングされ、それぞれの列が国の値を表すことになります。
また、ダミー変数の罠を避けるために、1つのカテゴリ変数を削除しました。削除された変数は、他のカテゴリに対する基本カテゴリになるはずです。我々は France を削除したので、他の国の値を示すためのベースとして機能します。
データをトレーニングセットとテストセットに分割する
トレーニングデータセットはニューラルネットワークモデルの学習に使用され、テストデータセットはモデルがどの程度学習されたかを検証するために使用されます。以下は、データを分割するためのコードです。
private static RecordReader generateReader(File file) throws IOException, InterruptedException {
final RecordReader reader = new RecordReader();
reader.initialize(new FileSplit(res));
reader.initialize(res);
final RecordReader transformationReader=applyTransform(reader,createSchema());
return transformationReader;
}入力と出力のラベルを定義する
次に、入力ラベルと出力ラベルを定義します。変換後のデータは13カラムになるはずです。これは、インデックスが0から12まであることを意味しています。最後の列が出力ラベルで、それ以外の列が入力ラベルです。
また、データセットのバッチサイズも決めておくと良いです。バッチサイズは、データセットからニューラルネットワークに転送されるデータの量を定義します。そのために、以下のようにDataSetIteratorを作成します。
final int labIndex=11;
final int numClasses=2;
final int batchSize=8;
final INDArray weightArray = Nd4j.create(new double[]{0.57, 0.75});
final RecordReader reader = generateReader(res);
final DataSetIterator iterator = new RecordReaderDataSetIterator.Builder(reader,batchSize)
.classification(labIndex,numClasses)
.build();データスケーリング
ニューラルネットワークに与えるデータのラベルは、互いに比較可能であるべきです。今回のケースでは、balanceとestimated salaryのラベルの大きさが他のラベルよりも大き過ぎます。もしデータをそのまま使うと、この2つのラベルは予測を行う際に他のラベルの影響を隠してしまう可能性があります。
この問題を解決するために、以下のコードに示すように、特徴スケーリングを用いることにします。
final DataNormalization normalization = new NormalizerStandardize();
normalization.fit(iterator);
iterator.setPreProcessor(normalization);
final DataSetIteratorSplitter iteratorSplitter = new DataSetIteratorSplitter(iterator,1250,0.8);この時点で、ニューラルネットワークにデータを投入する準備が整いました。
ニューラルネットワークを定義する
いよいよニューラルネットワークの構成を定義します。入力層に追加するニューロンの数、隠れ層の構造と接続、出力層、各層で使用する活性化関数、オプティマイザ関数、出力層の損失関数を定義することになります。
以下のコードがそれを示しています。
final MultiLayerConfiguration config = new NeuralNetConfiguration.Builder()
.weightInit(WeightInit.RELU_UNIFORM)
.updater(new Adam(0.015D))
.list()
.layer(new DenseLayer.Builder().nIn(11).nOut(6).activation(Activation.RELU).dropOut(0.9).build())
.layer(new DenseLayer.Builder().nIn(6).nOut(6).activation(Activation.RELU).dropOut(0.9).build())
.layer(new DenseLayer.Builder().nIn(6).nOut(4).activation(Activation.RELU).dropOut(0.9).build())
.layer(new OutputLayer.Builder(new LossMCXENT(weightArray)).nIn(4).nOut(2).activation(Activation.SOFTMAX).build())
.build();なお、オーバーフィッティングを避けるために、入力層と出力層の間にドロップアウトを追加しています。また、アンダーフィッティングを避けるため、ニューロンの10%のみをドロップアウトしています。また、入力の数は11、出力の数は1に設定しました。
また、ネットワークの出力層にはシグモイド活性化関数を使用しました。また、計算する誤差率とともに損失関数を指定しました。この場合、実際の出力と期待される出力との差の二乗和を計算することになります。対応する損失関数は binary cross-enthropy です。
モデルを学習させる
まずはコンパイルして、モデルを初期化しましょう。
final UIServer ui = UIServer.getInstance();
final StatsStorage stats = new InMemoryStatsStorage();
final MultiLayerNetwork multiNetwork = new MultiLayerNetwork(config);
multiNetwork.init();
multiNetwork.setListeners(new ScoreIterationListener(100),
new StatsListener(stats));
ui.attach(stats);fit() メソッドを呼び出して、ニューラルネットワークのモデルを学習させましょう。
multiNetwork.fit(iteratorSplitter.getTrainIterator(),100);DL4Jが提供するEvaluationクラスを使って、モデル結果の評価をしてみましょう。
final Evaluation ev = multiNetwork.evaluate(iteratorSplitter.getTestIterator(),Arrays.asList("0","1"));
System.out.println(ev.stats());結果は混同行列の形で表示されます。
予測をする
ニューラルネットワークモデルを実際に動かして見たいと思います。ある顧客が銀行を辞めるかどうかを予測することにします。
テストデータセットには出力ラベルがないので、新しいスキーマを作成しなければなりません。前に定義したスキーマからラベルを削除すれば良いです。新しいスキーマは以下のようなものです。
private static Schema createSchema() {
final Schema scm = new Schema.Builder()
.addColumnString("rowNumber")
.addColumnInteger("customerId")
.addColumnString("surname")
.addColumnInteger("creditScore")
.addColumnCategorical("geography", Arrays.asList("France","Germany","Spain"))
.addColumnCategorical("gender", Arrays.asList("Male","Female"))
.addColumnsInteger("age", "tenure")
.addColumnDouble("balance")
.addColumnsInteger("numOfProducts","hasCrCard","isActiveMember")
.addColumnDouble("estimatedSalary")
.build();
return scm;
}これで、予測結果をINDArrayとして返すAPI関数を作成することができました。
public static INDArray predictedOutput(File inputFile, String modelPath) throws IOException, InterruptedException {
final File file = new File(modelPath);
final MultiLayerNetwork net = ModelSerializer.restoreMultiLayerNetwork(file);
final RecordReader reader = generateReader(inputFile);
final NormalizerStandardize normalizerStandardize = ModelSerializer.restoreNormalizerFromFile(file);
final DataSetIterator iterator = new RecordReaderDataSetIterator.Builder(reader,1).build();
normalizerStandardize.fit(iterator);
iterator.setPreProcessor(normalizerStandardize);
return net.output(iterator);
}次に、コードのコンパイルと実行を行います。
コードのコンパイルと実行
まず、gsadm ユーザでログインします。作成した .java ファイルを GridDB の bin フォルダに移動し、以下のパスに配置する。
/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin
次に、Linux端末で以下のコマンドを実行し、gridstore.jarファイルのパスを設定します。
export CLASSPATH=$CLASSPATH:/home/osboxes/Downloads/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin/gridstore.jar次に、以下のコマンドを実行して .java ファイルをコンパイルします。
javac BankRetention.java以下のコマンドを実行して生成された .class ファイルを実行します。
java BankRetentionニューラルネットワークは、顧客が銀行を離れる確率を予測します。確率が0.5(50%)以上であれば、不満を持っている顧客であることを示しています。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb