
デジタル化が進む現代において、私たちはソーシャルメディアからオンラインニュースサイトに至るまで、数多くのプラットフォームで膨大な量のニュース記事に常にさらされています。このような大量の情報の流入は、しばしば「ニュースの洪水」と呼ばれ、消費者と報道機関の双方にいくつかの課題をもたらしています。コンテンツの整理、情報の過多、時間のかかる手作業のタグ付けプロセス、非効率なコンテンツの発見と推奨など、これらの課題に対処することは、ユーザー体験とニュース消費全体の質を向上させるために不可欠です。
この問題に対する一つの解決策が、ニュースタギングを利用することです。これは、デジタルニュース領域で利用可能な豊富な情報を処理、整理、提示する上で重要な役割を担っています。無数のニュース記事に正確なトピックを手動でタグ付けすることは、圧倒的な時間と労力を要する作業です。
もし、ニュース記事をリアルタイムで効率的に処理できる自動コンテンツタギングシステムがあったらどうでしょうか。
このブログでは、自動化されたニュースタギングシステムを作成します。OpenAI、Node.js、GridDBの相乗効果で、デジタルニュース界に強力な自動ニュースタギングを実現する方法を掘り下げます。Node.jsでニュースデータを処理し、ChatGPTでニュースからタグを分析・抽出し、GridDBで情報を保存・検索します。最終的には、ニュースやタグをユーザーに提示することになります。
ニュース自動タグ付けシステムの概要
ChatGPTは、OpenAI社が開発した、人間のような文章を理解し生成することに長けた最先端の言語モデルです。Node.jsは、ChromeのV8 JavaScriptエンジンをベースに構築された人気のオープンソース実行環境で、開発者はスケーラブルで効率的なWebアプリケーションを作成することができる。GridDBは、時系列データや大規模なデータセットを扱うために設計された高性能なNoSQLデータベースで、データの自動パーティショニングや高可用性などの機能を備えています。

ChatGPT、Node.js、GridDBのフロー図では、マルチニュースのデータ取得、処理、コンテンツタギングを行うシステム全体のワークフローが示されています。この図は、よりよく理解するために、以下のステップに分解することができます。
-
データの取得: Node.jsを使用して、複数のニュースソースからデータを収集・取得します。
-
データ処理: データ取得後、Node.jsは関連情報の処理とフィルタリングを行い、さらに使用するための望ましい形式を確保する役割を果たします。
-
データの保存: 処理後、洗練されたデータは、高性能でスケーラブルなNoSQLデータベースであるGridDBに保存され、データの効率的な保存と検索が可能になります。
-
ChatGPTによるニュースタギング: 処理されたデータは、最先端のAI言語モデルであるChatGPTに供給されます。ChatGPTはデータを分析し、文脈と関連キーワードに基づいてコンテンツタグを生成します。
-
Reactでデータをユーザーに提示する: データの処理、保存、タグ付けが完了したら、それをアクセスしやすい、ユーザーフレンドリーなフォーマットで提示することが重要です。この場合、ユーザーインターフェイスを構築するための一般的なJavaScriptライブラリであるReactを活用し、ニュースとタグを表示するウェブベースのアプリケーションを作成します。
つまり、データの取得と処理にNode.js、データの保存にGridDB、ニュースのタグ付けにChatGPT、エンドユーザーにデータを提示するユーザーフレンドリーなインターフェースの作成にReactを採用し、包括的かつ効率的に複数のニュースデータを扱うシステムを表現したのが、今回のフロー図です。
フルプロジェクトインストールガイド
このプロジェクトのインストール手順は簡単です。まず、オペレーティングシステムにNode.js 18がインストールされていることを確認し、GridDBデータベースが動作可能であることを確認します。Ubuntu 20.04 では、systemctl を使って GridDB を確認することができます。
sudo systemctl status gridstoreこのコマンドでNode.jsのバージョンを確認します。
node --version問題がなければ、GitHubのリポジトリからニュースタグ付けプロジェクトをクローンします。
git clone git@github.com:junwatu/news-analysis-chatgpt-nodejs-griddb-code.git次に、プロジェクトの依存関係をインストールします。
cd news-analysis-chatgpt-nodejs-griddb-code
npm installこのプロジェクトを実行する前に、OpenAIのAPIキーを取得することが重要です。
OpenAIは新規アカウントに5ドルのスタータークレジットを付与しているので、このプロジェクトを完了させるのに十分な量のクレジットを持つことができます。APIを使用するには有料アカウントを設定する必要がありますが、そのコストは1,000トークンあたり0.002ドルと非常に低くなっています。1,000個のトークンは、平均的な単語の長さである4-5文字とスペース(1単語あたり5-6文字)に基づき、英語の約200-300単語に対応すると概算されます。
キーを取得するには、OpenAIのアカウントをサインアップして、指示に従ってAPIキーを取得します。
キーを取得したら、apps/server ディレクトリにある .env ファイルを編集します。
ini
OPENAI_API_KEY=<your_api_key><your_api_key>の部分を実際のOpenAI APIキーに置き換えてください。OpenAI API キーが設定されたので、プロジェクトの実行に進みます。
npx turbo start最後に、URL http://localhost:5137 に移動して、Webアプリケーションにアクセスします。
キーコンセプトと実践的なコード
ニュースタグの生成にChatGPTを使う
ChatGPTはGPT (Generative Pre-trained Transformer) アーキテクチャに基づく高度な人工知能言語モデルです。このモデルは、受け取った入力に基づいて人間のようなテキストを理解し、生成するように設計されています。質問に答えたり、会話をしたり、さまざまなスタイルや形式のテキストを生成したりと、さまざまなタスクを実行することが可能です。ChatGPTは、チャットボット、コンテンツ生成、翻訳など、さまざまなアプリケーションで広く使用されています。
ChatGPTは、自然言語処理のコアコンポーネントとして、ニュース記事の解析とタグの生成を担っています。
プロンプト
ChatGPTは自然言語理解が可能なため、ニュース記事からタグを生成するのはとんでもなく簡単です。私たちがすべきことは、それを要求することです!
プロンプトとは、言語モデルや機械学習システムが適切な出力を生成するように誘導するためのテキストです。プロンプトは、質問、コマンド、テキストなどさまざまな形式をとることができ、出力の正確さと関連性を高めるためには、適切に設計されたプロンプトが重要です。
ニュース記事からタグを生成するために、ChatGPTに望ましい出力を指定するプロンプトを提供することができます。例えば、JavaScriptの場合、プロンプトは次のような構造になっています。
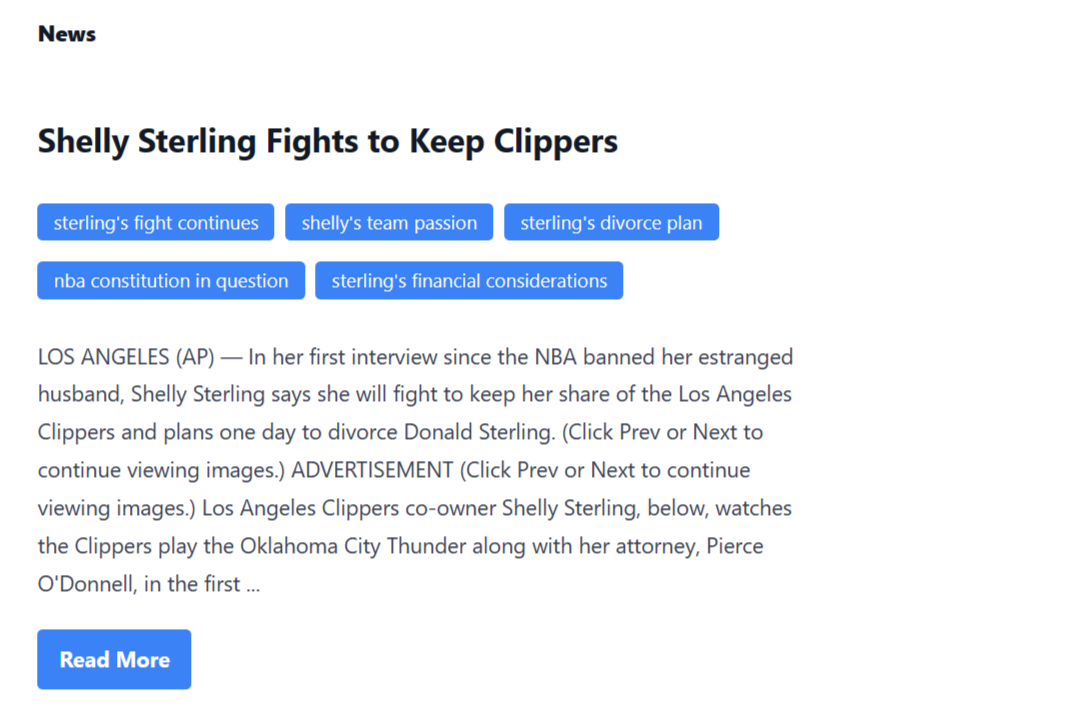
const prompt = `Generate five tags, less than 3 words, and give numbers for the tags from this news:\n\n${news}`;このプロンプトをChatGPTサイトの特定の「ニュース」記事に直接適用すると、5つのタグが得られます。

タグジェネレータコード
OpenAIは、ChatGPTモデルにアクセスするためのChat APIを提供しています。ここでは、ニュースからタグを生成するために gpt-3.5-turbo モデルを使用します。これはChatGPTのウェブサイトで利用されているものと同じモデルです。
import { Configuration, OpenAIApi } from "openai";
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
async function generateTagsFromNews(news) {
const prompt = `Generate five tags, less than 3 words, and give numbers for the tags from this news:\n\n${news}`;
try {
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
max_tokens: 2000,
messages: [{ role: "user", content: prompt }],
});
return completion.data.choices[0].message;
} catch (error) {
console.error("Error occurred while generating tags:", error);
// Handle the error as needed, or return a suitable error message
return "An error occurred while generating tags.";
}
}
export { generateTagsFromNews };Chat モデルに対する OpenAI API では、createChatCompletion 関数を利用しています。適切なプロンプトを作成することで、このモデルは優れた完了応答を生成することができます。
gpt-3.5-turbo モデルの max_tokens の上限は 4096 トークンであることを知っておくことが重要です。プロンプトがこの制限を超える場合、モデルの最大容量に収まるように、テキストを切り詰めたり、省略したり、その他の方法で凝縮する必要があります。
Node.jsによるデータ取得
Node.jsはウェブアプリケーションのバックボーンとして機能し、開発者はニュースデータを処理・管理するための高速でスケーラブル、かつ信頼性の高いシステムを構築することができるようになります。ノンブロッキング、イベント駆動型のアーキテクチャと豊富なパッケージエコシステムを持つNode.jsは、リアルタイムデータ処理やAPI統合などの複雑な機能を簡単に実装することが可能です。
最適なデータソースとしては、ニュースAPIを利用することが望ましいでしょう。しかし、このプロジェクトでは、ハギング・フェイスのウェブサイト huggingface.co からデータを取得することができます。
Hugging Faceは、自然言語処理(NLP)モデルやデータセットのための人気のあるプラットフォームです。
Multi-NewsはHugging Face上のデータセットで、サイトnewser.comのニュース記事とその記事を人間が書いた要約で構成されています。それぞれの要約は、編集者によって専門的に書かれています。
Node.jsでは、ネイティブの fetch 関数を使って簡単にデータセットを利用することができます。
async function fetchMultiNews() {
const url = "https://datasets-server.huggingface.co/first-rows?dataset=multi_news&config=default&split=train";
try {
const response = await fetch(url);
if (response.ok) {
const data = await response.json();
return data.rows
} else {
console.error('Error fetching dataset', response.statusText);
return response.statusText;
}
} catch (error) {
console.error('Error:', error);
throw new Error(error);
}
}
export { fetchMultiNews }Node.jsによるデータ処理
データ処理の主な目的は、ニュースデータの準備と整形を行い、コンテナGridDBに格納することです。
const newsData = await fetchMultiNews();
logger.info(`News Data: ${newsData.length}`);
const cont = await store.putContainer(conInfo)
const query = await cont.query("SELECT *");
const rowset = await query.fetch();
const results = [];
while (rowset.hasNext()) {
const row = rowset.next();
const rowData = { id: `${row[0]}`, news: row[1] };
results.push(rowData);
}
let newsDataSelected;
if (Array.isArray(results) && results.length == 0) {
logger.info('Database Empty...initialized!');
const newsDataObject = saveNewsData(newsData);
newsDataSelected = await generateData(newsDataObject)
} else {
const newsDataObject2 = formatData(newsData);
newsDataSelected = await generateData(newsDataObject2);
}上記のコードでは、GridDB のコンテナが空かどうかをチェックし、それに応じて取得したニュースデータを処理し、新しいデータを保存するか、既存のデータを読み込みます。コンテナが空の場合は、saveNewsData関数がニュースデータを保存します。
データ処理関数は、JavaScriptのオブジェクトをGridDBのコンテナに適した配列形式 [id, news] に変換する簡単な関数です。
function saveNewsData(newsData) {
const newsDataObject = {}
const newsDataArray = []
newsData.forEach((element, index) => {
const news = element?.row?.document;
newsDataObject[index + 1] = news;
newsDataArray.push([index, news]);
});
saveForEach(newsDataArray); //⚠️
return newsDataObject;
}GridDBによるデータの保存と管理
膨大な量のニュースデータを保存・管理するために、データストレージソリューションとしてGridDBが登場しました。GridDBは高性能で、水平スケーリングをサポートし、時系列データを扱うことができるため、ニュースのタグ付けに関わる大規模なデータセットを管理するのに理想的な選択肢です。さらに、GridDBの効率的なクエリとデータ検索機能により、アプリケーションは関連するコンテンツをユーザーに迅速に提供できます。
GridDB の MultiNews コンテナには、識別子 id とニュースの内容 news という、特定のタイプのデータを格納するための 2 つのフィールドがあります。コンテナは以下のJavaScriptコードで定義します。
const conInfo = new griddb.ContainerInfo({
'name': containerName,
'columnInfoList': [
["id", griddb.Type.INTEGER],
["news", griddb.Type.STRING]],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});GridDBコンテナにデータを保存するには、insert関数を使用します。この関数は data と container の 2 つの引数を取ります。dataはニュースデータのコレクションを含む配列で、containerはデータが保存されるGridDBコンテナのインスタンスを指します。以下、関数の内訳を紹介します。
function insert(data, container) {
try {
container.put(data);
return { ok: true };
} catch (err) {
console.log(`insert: ${err}`);
return { ok: false, error: err };
}
}データは [id, news] という形式で、GridDB コンテナに保存するために put 関数を使用します。
Node.js HTTPサーバ
HTTPサーバはNode.jsとExpress.jsで構築されており、プライマリルート /multinews を備えています。このルートは、ニュース id、ニュース newsデータ、ニュース tags、ニュース titleを返します。返されるデータはJSON形式であり、消費を単純化することができます。
サーバーレスポンスのJSONの例です。
{
"id": "18",
"news": "VATICAN CITY (Reuters) - Pope Francis, ...",
"tags": [
"youth voices",
"tighter gun laws",
"palm sunday service",
"young catholics",
"church transparency"
],
"title": "Pope Francis Urges Young People to Speak Up"
}ブラウザを開いてURL http://localhost:4000/multinews を直接入力すると、JSONのレスポンスが返ってきます!
React フロントエンドでデータを表示する
Reactは、特にシングルページのアプリケーションでユーザーインターフェイスを作成するために広く使用されているJavaScriptライブラリです。Reactは、ユーザーフレンドリーで、多くの開発者コミュニティがあり、効率的な仮想DOMの実装により優れたパフォーマンスを提供します。
このプロジェクトでは、ニュースデータを表示するためのコンポーネントは1つだけです。Newsコンポーネントは、Node.jsのHTTPサーバーからニュースデータを取得し、表示する役割を担っています。useState と useEffect フックを使用することで、コンポーネントの状態を簡単に管理することができます。
import React, { useState, useEffect } from 'react';
const [randomNews, setRandomNews] = useState({});
useEffect(() => {
fetchNews();
}, []);
const fetchNews = async () => {
console.log(SERVER_URL);
try {
const response = await fetch(SERVER_URL);
const data = await response.json();
setRandomNews(data);
setLoading(false);
} catch (error) {
console.error('Error fetching news:', error);
}
};Newsコンポーネントは、ページが再読み込みされるたびにJSONデータを取得し、ユーザーインターフェースを再レンダリングします。
<h2>{randomNews.title}</h2>
<ul className='px-0 left-0'>
{randomNews.tags.map((item, index) => (
<li key={index} className='inline-block bg-blue-500 text-white text-sm px-3 py-1 mr-2 mb-2 rounded' title='generated tag'>
{item}
</li>
))}
</ul>
<article className='text-left pb-5'>
{showFullNews ? randomNews.news : `${randomNews.news.substring(0, 500)}...`}
</article>
React、JavaScriptの配列mapメソッド、HTMLの<ul>と<li>、CSSを使って、簡単にタグを青いバッジとして表示することができます。
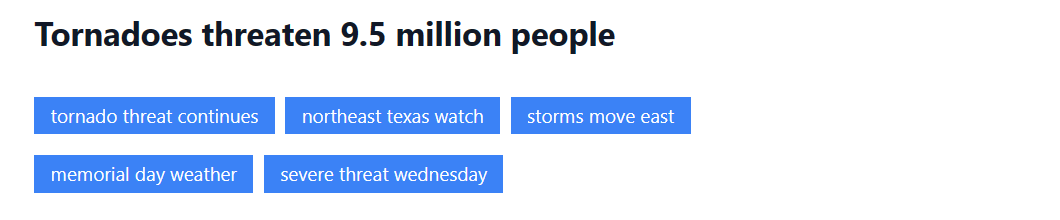
おすすめと提案
このプロジェクトを強化するための推奨事項と改善提案を紹介します。
- このプロジェクトは現在MVP(Minimum Viable Product)であり、改善の余地が十分にあることを念頭に置いてください。より正確で最新のユーザーエクスペリエンスを実現するために、ニュースデータをライブでリアルタイムに取得することを検討してください。
- OpenAI APIの利用状況を監視・管理するための管理者用ダッシュボードを導入すると良いです。この機能により、管理者は制限の設定、使用状況の追跡、アプリケーションの機能の制御を維持することができます。
- よりシームレスでユーザーフレンドリーな体験を提供するために、ページのリロードごとにランダムなニュース記事が表示される現在のシステムではなく、ページ分割されたニュース表示を実装します。ページネーションにより、ユーザーはより簡単にコンテンツを閲覧・移動することができ、より魅力的で楽しい体験を得ることができます。
- 生成されたタグをデータベースに保存し、ユーザーの検索やフィルタリングを強化します。
その他のリソースとリファレンス
このセクションでは、さらなる理解と探求のために役立つリソースとリファレンスを提供します。以下のリンクをご参照ください。
- GitHub上のプロジェクトのソースコード: プロジェクトのニュースタギングソースコードにアクセスできます。
- OpenAI Chat API Guide: ChatGPTモデルや他の会話型AIモデルとの対話方法を理解するために、OpenAI Chat APIドキュメントに飛び込んでみてください。
- OpenAI Chat APIリファレンス: OpenAI Chat API の詳細な API リファレンスにアクセスし、パラメータやレスポンスフォーマットなどを確認することができます。
- GridDBウェブサイト: 本プロジェクトで使用しているスケーラブルで高性能な分散データベースであるGridDBについて詳しく説明しています。
- Node.js Linux インストール: Node.jsをLinuxシステムにインストールするための手順を説明します。
- ChatGPT: 会話型AIの機能を試すのに最適なユーザーフレンドリーなインターフェースで、ChatGPTモデルの実験を行うことができます。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb