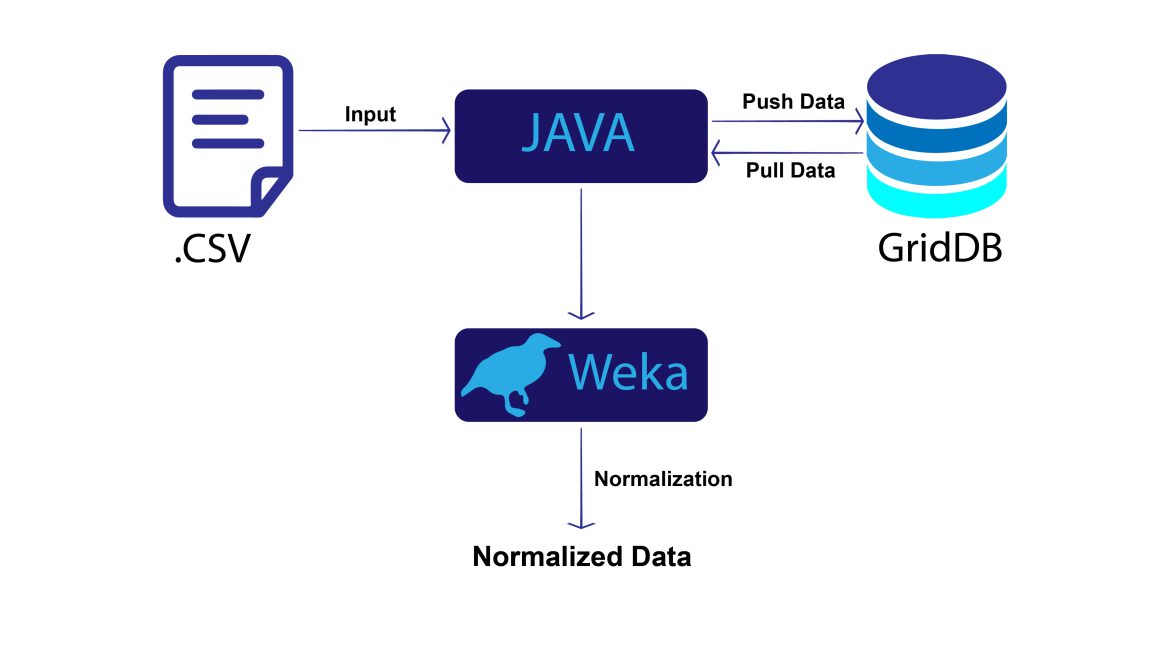
本ブログでは、JavaとGridDBを使用して機械学習用のデータ正規化を実演します。
本ブログのソースコードは、当社のGitHubページでご覧いただけます:https://github.com/griddbnet/Blogs
$ git clone https://github.com/griddbnet/Blogs.git --branch normalization始める前に、まず正規化について理解しておきましょう。
正規化とは?
正規化とは、機械学習において一般的に使用されるデータ準備のテクニックで、共通のスケールを使用してデータセット内の列の値を変更します。データセットにさまざまな特性が存在する場合、正規化が必要です。
このプロジェクトでは、以下のようなデータセット house.csv を使用します。
housesize,lotsize,bedrooms,granite,bathroom,sellingprice
3529,9191,6,0,0,205000
3247,10061,5,1,1,224900
4032,10150,5,0,1,197900
2397,14156,4,1,0,189900
2200,9600,4,0,1,195000
3536,19994,6,1,1,325000
2983,9365,5,0,1,230000データセットには、異なる範囲の数値が大量に含まれているため、データ分析操作が困難であることが分かります。
正規化により、列の値を0から1の範囲に収めるなど、共通の尺度で列の値を変更することで、このデータセットを簡素化することができます。以下のようなイメージです。
housesize,lotsize,bedrooms,granite,bathroom,sellingprice
0.571507,0.080533,0.5,1,1,224900
0.107533,0.459595,0,1,0,189900
0.729258,1,1,1,1,325000
0.725437,0,1,0,0,205000
1,0.088772,0.5,0,1,197900
0,0.03786,0,0,1,195000
0.427402,0.016107,0.5,0,1,230000sellingprice 列が変更されないことに気づくかもしれません。これは、分類器がどの変数が結果変数であるかを知る必要があるためです。
そのため、分類器に渡す前に、sellingprice 列をデータセットのクラスインデックスとして設定したのです。このことは、この記事の後半で実際に確認することになります。
次の式は、正規化を数学的に定義しています。
Xn = (X – Xmin) / (Xmax – Xmin)
Xn = 正規化された値。Xmin = 特徴の最小値。Xmax = 特徴の最大値。
正規化の種類
機械学習では、さまざまな種類の正規化が利用できます。しかし、以下のような種類が広く使用されています。
Min-Max スケーリング: この正規化では、各列の最大値から最小値を差し引いて、その値を範囲で割ります。 各新しい列は最小値が 0、最大値が 1 になります。
標準化スケーリング: Z-スコア正規化とも呼ばれるこの正規化では、変数をゼロに中心化し、分散を 1 に標準化します。 まず各オブザベーションの平均を差し引き、それを標準偏差で割ります。
理論についてはこれで十分です。実用的な内容に入りましょう。
正規化の使用方法
プロジェクトの設定
このプロジェクトでは、JavaとGridDBで基本的なレベルの正規化を実装します。プロジェクトの構成は以下のようになります。
このプロジェクトを実行するには、システムに次のものが必要です。 – Java(最新バージョン) – GridDB
必要なJARファイル
必要なJARファイルは「gridstore-5.5.0.jar」と「weka-3.7.0.jar」の2つです。ここで、「gridstore-5.5.0.jar」はGridDBの公式ライブラリ、「weka-3.7.0.jar」はデータ分析に利用する機械学習ライブラリです。
Weka JARは以下のURLからダウンロードしてください。
http://www.java2s.com/Code/Jar/w/weka.htm
gridstore.jarは、こちらからダウンロードしてください。
https://mvnrepository.com/artifact/com.github.griddb/gridstore-jdbc/5.5.0
インポートパッケージ
このプロジェクトでは、いくつかの基本的なJavaパッケージが必要です。
import java.util.Properties;
import java.util.Scanner;
import java.io.File;
import java.io.Reader;
import java.io.StringReader;GridDBに接続し操作を行うには、以下のパッケージを含める必要があります。
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;データ分析には、Wekaの以下のパッケージを含めます。
import weka.classifiers.Evaluation;
import weka.classifiers.functions.LinearRegression;
import weka.core.Instances;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Normalize;Wさて、これが最初のステップです。
次のステップに進みましょう。
データを格納するためのクラスの作成
このプロジェクトでは、GridDBコンテナにデータを格納します。そのため、コンテナのスキーマを静的クラスとして定義する必要があります。
static class House {
@RowKey int housesize;
int lotsize;
int bedrooms;
int granite;
int bathroom;
int sellingprice;
}静的クラス House は、RowKey housesize を持つ6つの整数型カラムで構成されます。
GridDB 接続の作成
スキーマクラスは準備できました。GridDBに接続する時が来ました。
GridDB接続を作成するには、GridDBインストールの認証情報を定義するPropertiesインスタンスを初期化する必要があります。次のコードを見てください。
Properties props = new Properties();
props.setProperty("notificationMember", "127.0.0.1:10001");
props.setProperty("clusterName", "myCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);GridDBのインストール状況に応じて、これらの接続情報を変更する必要があるかもしれません。
接続に成功したら、次にコレクションを作成します。
Collection coll = store.putCollection("House", House.class);ここでは、コンテナ House のコレクションオブジェクト coll を作成しました。
GridDBにデータをプッシュ
これでGridDBのスキーマが完成し、接続の準備が整いました。
それでは、いくつかのデータを入れてみましょう。
この目的のために、house.csvファイルからデータを取得し、GridDBにプッシュします。次のコードブロックがこのタスクを実行します。
File file1 = new File("house.csv");
Scanner scan = new Scanner(file1);
String data = scan.next();
while (scan.hasNext()){
String scanData = scan.next();
String dataList[] = scanData.split(",");
String housesize = dataList[0];
String lotsize = dataList[1];
String bedrooms = dataList[2];
String granite = dataList[3];
String bathroom = dataList[4];
String sellingprice = dataList[5];
House hs = new House();
hs.housesize = Integer.parseInt(housesize);
hs.lotsize = Integer.parseInt(lotsize);
hs.bedrooms = Integer.parseInt(bedrooms);
hs.granite = Integer.parseInt(granite);
hs.bathroom = Integer.parseInt(bathroom);
hs.sellingprice = Integer.parseInt(sellingprice);
coll.put(hs);
}コンテナにデータをプッシュするために、スキーマクラス House のオブジェクトを作成しました。
GridDB からデータを取得
GridDB コンテナからデータを取得し、分析できるようにしましょう。以下のコードを使用します。
Query query = coll.query("select *");
RowSet<house> rs = query.fetch(false);</house>GridDBからのクエリデータは一般的なSQLクエリと似ています。ここでは、select *クエリを使用して、GridDBコンテナからすべてのデータを取得しました。
これらのデータを次のステップで使用するために、文字列に保存します。
String datastr = "@RELATION house\n\n@ATTRIBUTE houseSize NUMERIC\n@ATTRIBUTE lotSize NUMERIC\n@ATTRIBUTE bedrooms NUMERIC\n@ATTRIBUTE granite NUMERIC\n@ATTRIBUTE bathroom NUMERIC\n@ATTRIBUTE sellingPrice NUMERIC\n\n@DATA\n";
while (rs.hasNext()) {
House hs = rs.next();
datastr = datastr + hs.housesize+","+hs.lotsize+","+hs.bedrooms+","+hs.granite+","+hs.bathroom+","+hs.sellingprice+"\n";
}文字列 datastr を arff ファイル構造で初期化していることに注目してください。
正規化前のデータがどのようなものか見てみましょう。
System.out.println("==== Before Normalization ===\n"+datastr);Weka インスタンスの作成
データの正規化には、Weka マシンラーニングライブラリを使用します。そのため、データを Weka インスタンスに変換する必要があります。
前回のステップで、データを文字列 datastr に格納したことを覚えていますか?
はい、その文字列を Weka インスタンスに渡します。
Reader dataString = new StringReader(datastr);
Instances dataset = new Instances(dataString);
dataset.setClassIndex(dataset.numAttributes()-1);上記のコードはWekaインスタンスを作成します。
正規化
データセットに正規化を実行してみましょう。
Normalize normalize = new Normalize();
normalize.setInputFormat(dataset);
Instances newdata = Filter.useFilter(dataset, normalize);次に、正規化後のデータの可視化を行います。
System.out.println("==== After Normalization ===\n"+newdata);最後に、正規化されたデータに線形回帰を適用しただけです。
LinearRegression lr = new LinearRegression();
lr.buildClassifier(newdata);
Evaluation lreval = new Evaluation(newdata);
lreval.evaluateModel(lr, newdata);
System.out.println(lreval.toSummaryString());プロジェクトについては以上です。テストしてみましょう。
コンパイルと実行
IDEを使用していない場合は、JARファイルをクラスパスに含める必要があります。
export CLASSPATH=$CLASSPATH:/Home/User/Download/gridstore.jar
export CLASSPATH=$CLASSPATH:/Home/User/Download/weka-3.7.0.jarこれらのパスは、お客様の設定によって異なる場合があります。
このコマンドを使用してコードをコンパイルできます。
javac NormalizationJava.java次にコードを実行します。
java NormalizationJava出力の表示
コードを実行すると、以下の出力が得られます。
==== Before Normalization ===
@RELATION house
@ATTRIBUTE houseSize NUMERIC
@ATTRIBUTE lotSize NUMERIC
@ATTRIBUTE bedrooms NUMERIC
@ATTRIBUTE granite NUMERIC
@ATTRIBUTE bathroom NUMERIC
@ATTRIBUTE sellingPrice NUMERIC
@DATA
3247,10061,5,1,1,224900
2397,14156,4,1,0,189900
3536,19994,6,1,1,325000
3529,9191,6,0,0,205000
4032,10150,5,0,1,197900
2200,9600,4,0,1,195000
2983,9365,5,0,1,230000
==== After Normalization ===
@relation house-weka.filters.unsupervised.attribute.Normalize-S1.0-T0.0
@attribute houseSize numeric
@attribute lotSize numeric
@attribute bedrooms numeric
@attribute granite numeric
@attribute bathroom numeric
@attribute sellingPrice numeric
@data
0.571507,0.080533,0.5,1,1,224900
0.107533,0.459595,0,1,0,189900
0.729258,1,1,1,1,325000
0.725437,0,1,0,0,205000
1,0.088772,0.5,0,1,197900
0,0.03786,0,0,1,195000
0.427402,0.016107,0.5,0,1,230000
Correlation coefficient 0.9945
Mean absolute error 4053.821
Root mean squared error 4578.4125
Relative absolute error 13.1339 %
Root relative squared error 10.51 %
Total Number of Instances 7
BUILD SUCCESSFUL (total time: 1 second)まとめ
以上で、GridDB を使用した Java での正規化の説明を終わります。
この記事では、より良い分析を行うためにデータセットに正規化を適用する方法を説明しました。前述のとおり、データセットにさまざまな特性が含まれる場合、正規化が役立ちます。
最後に、クエリ、コンテナ、および GridDB データベースを確実に閉じてください。
query.close();
coll.close();
store.close();ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb