
売上予測とは、過去のデータに基づいて、ある期間の将来の売上を予測する処理です。予測は、多くの企業の収益性を左右する貴重なツールであるため、習得すべき重要なスキルです。予測は、企業の計画や方向性を導くのに役立ちます。自己回帰統合移動平均(ARIMA)、季節自己回帰統合移動平均(SARIMA)、ベクトル数(VAR)など、世の中にはいくつかの方法が存在します。今回は、Kerasを使ってLSTM(Long Short-term Memory)モデルを実装してみます。LSTMは、フィードバックループに頑健なニューラルネットワークの一種です。
リカレントニューラルネットワークの主な問題点として、時間の経過とともに、隠れ状態に保持されている情報が過負荷になることが挙げられます。LSTMは、ステップからステップへ持続する追加の隠れ状態を維持することで、オーバーロードを軽減します。LSTMの詳細はこちらを参照してください。GridDBはスケーラブルで信頼性が高いので、ニューラルネットワークの学習や推論に最適なデータベースとして利用できます。GridDBのインストールは簡単で、こちらに詳しい説明があります。Python-GridDBクライアントを確認するには、こちらのビデオを参照してください。
LSTM
セットアップ
まずはGridDBをセットアップしましょう
Ubuntu 20.04でGridDB Python Clientのセットアップを行います。
- GridDBのインストール
こちらからdebをダウンロードし、インストールします。
- C言語のクライアントをインストールする
こちらからUbuntuをダウンロードし、インストールします。
- 必要機材のインストール
1) Swig コンソール
wget https://github.com/swig/swig/archive/refs/tags/v4.0.2.tar.gz
tar xvfz v4.0.2.tar.gz
cd swig-4.0.2
./autogen.sh
./configure make2) pythonクライアントのインストール
wget
https://github.com/griddb/python_client/archive/refs/tags/0.8.4.zip
unzip . 0.8.4.zip 対応するpythonのバージョンに対応するpython-devがインストールされていることを確認してください。この記事では、python 3.8を使用します。
3) 正しい場所を指定する必要があります。
export CPATH=$CPATH:<python header file directory path>
export LIBRARY_PATH=$LIBRARY_PATH:<c client library file directory path>
</c></python>また、こちらのように、DockerでGridDBを利用することも可能です。
Python ライブラリ
次に、Pythonのライブラリをインストールします。plotly、numpy、keras、tensorflow、pandasのインストールは、pip installで簡単にできます。
pip install keras
pip install numpy
pip install tensorflow
pip install plotly
pip install pandas 予測
ステップ1:データセットのダウンロード
このKaggleプロジェクトからデータをダウンロードすることができます。このデータセットには、Order Info, Sales, Customer, Shippingなどが含まれており、Segmentation, customer analytics, clusteringなどに利用することができます。今回は売上予測に使うので、売上と注文の日付のみを対象としています。月次の売上を予測します。
ステップ2: ライブラリのインポート
import numpy as np
import pandas as pd
import plotly.offline as pyoff
import plotly.graph_objs as go
ステップ3:データの読み込みと処理
データの読み込み
data=pd.read_csv('/content/sales_data_sample.csv', encoding='cp1252') 上記で使用したエンコードオプションに注意してください。
また、GridDBを使用してこのデータフレームを取得することも可能です。
特徴量のエンコーディング
まず、月単位でデータを照合する。各日付を月初にseするだけです。そして、その月の平均売上を算出します。すべての日に売上があるわけではないことに注意してください。
data['ORDERDATE'] = pd.to_datetime(data['ORDERDATE'])
data['ORDERDATE'] = data['ORDERDATE'].dt.year.astype('str') + '-' + data['ORDERDATE'].dt.month.astype('str') + '-01'
data['ORDERDATE'] = pd.to_datetime(data['ORDERDATE'])
data = data.groupby('ORDERDATE').SALES.mean().reset_index()
次に、売上高をプロットしてみます。データには、特に11月頃に季節性があることがわかります。
plot_data = [
go.Scatter(
x=data['ORDERDATE'],
y=data['SALES'],
)
]
plot_layout = go.Layout(
title='Monthly Sales'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig) 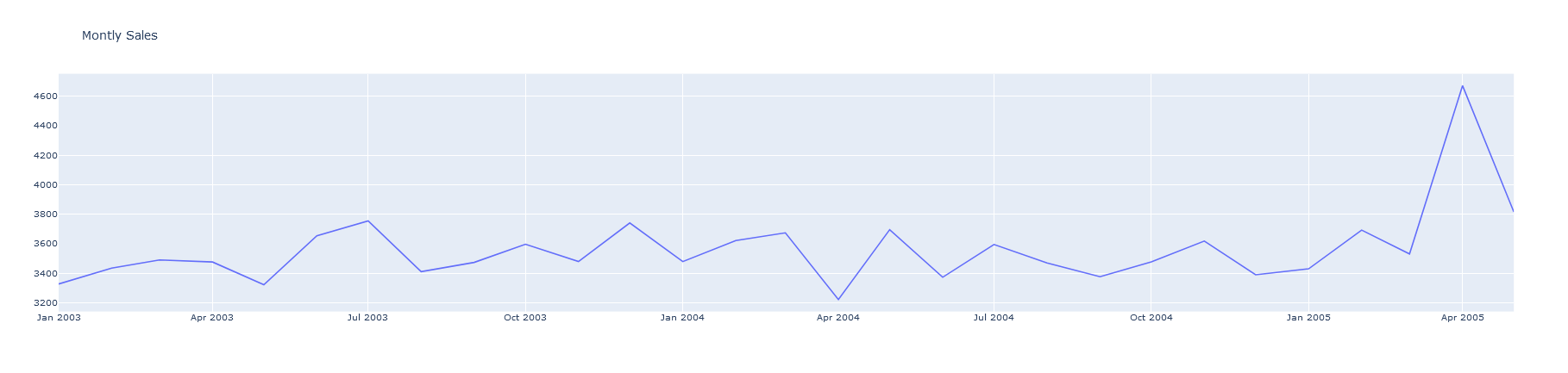
次に、売上高の差の列を追加し、ヌルを削除します。ヌルは最後の値だけで、その差は作れないのでヌルになります。ラグを設定することで、モデルは直近の売上だけでなく、それ以前の売上からも学習することができます。
df_supervised = data.copy()
df_supervised['prev_sales'] = df_supervised['SALES'].shift(1)
df_supervised['diff'] = (df_supervised['SALES'] - df_supervised['prev_sales'])
df_supervised = df_supervised.drop(['prev_sales'],axis=1)
for inc in range(1,3):
field_name = 'lag_' + str(inc)
df_supervised[field_name] = df_supervised['diff'].shift(inc)
#drop null values
df_supervised = df_supervised.dropna().reset_index(drop=True)
データを検証用と訓練用に分割する
次に、データをテストとトレーニングに分けます。テストには、過去6ヶ月のデータを使用しました。
from sklearn.preprocessing import MinMaxScaler
df_model = df_supervised.drop(['SALES','ORDERDATE'],axis=1)
#split train and test set
train_set, test_set = df_model[0:-6].values, df_model[-6:].values
また、データのスケーリングも行います。テストセットとトレーニングセットを別々にスケーリングすることに注意してください。これは、訓練セットとテストセットが独立したままであるようにするためです。
#apply Min Max Scaler
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(train_set)
# reshape training set
train_set = train_set.reshape(train_set.shape[0], train_set.shape[1])
train_set_scaled = scaler.transform(train_set)
# reshape test set
test_set = test_set.reshape(test_set.shape[0], test_set.shape[1])
test_set_scaled = scaler.transform(test_set) X_train, y_train = train_set_scaled[:, 1:], train_set_scaled[:, 0:1]
X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test, y_test = test_set_scaled[:, 1:], test_set_scaled[:, 0:1]
X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1]) ステップ4: 予測
次に、予測処理を開始します。
初期化
まずKerasでLSTMモデルを作成します。そのためにLSTMレイヤーを使用します。
# define the keras model
from keras.models import Sequential
from keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(4, batch_input_shape=(1, X_train.shape[1], X_train.shape[2]), stateful=True))
model.add(Dense(1)) トレーニング
次に、モデルをコンパイルします。損失としてmean_squared_errorを使用し、精度で評価します。
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy']) 次に、100エポック分のモデルの学習を行います。
history=model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1, shuffle=False) Epoch 72/100
20/20 [==============================] - 0s 2ms/step - loss: 0.1302 - accuracy: 0.0000e+00
Epoch 73/100
20/20 [==============================] - 0s 2ms/step - loss: 0.1287 - accuracy: 0.0000e+00
Epoch 74/100
20/20 [==============================] - 0s 2ms/step - loss: 0.1272 - accuracy: 0.0000e+00
Epoch 75/100
20/20 [==============================] - 0s 2ms/step - loss: 0.1258 - accuracy: 0.0000e+00
Epoch 76/100
20/20 [==============================] - 0s 2ms/step - loss: 0.1244 - accuracy: 0.0000e+00 評価と予測
最後に、テストセットを評価し、予測値を再スケールして、グランドトゥルースとともにプロットします。
y_pred = model.predict(X_test,batch_size=1)
y_pred = y_pred.reshape(y_pred.shape[0], 1, y_pred.shape[1])
pred_test_set = []
for index in range(0,len(y_pred)):
pred_test_set.append(np.concatenate([y_pred[index],X_test[index]],axis=1))
pred_test_set = np.array(pred_test_set)
pred_test_set = pred_test_set.reshape(pred_test_set.shape[0], pred_test_set.shape[2])
pred_test_set_inverted = scaler.inverse_transform(pred_test_set)
result_list = []
sales_dates = list(data[-7:].ORDERDATE)
act_sales = list(data[-7:].SALES)
for index in range(0,len(pred_test_set_inverted)):
result_dict = {}
result_dict['pred_value'] = int(pred_test_set_inverted[index][0] + act_sales[index])
result_dict['ORDERDATE'] = sales_dates[index]
result_list.append(result_dict)
df_result = pd.DataFrame(result_list) #merge with actual sales dataframe
df_sales_pred = pd.merge(data,df_result,on='ORDERDATE',how='left')
#plot actual and predicted
plot_data = [
go.Scatter(
x=df_sales_pred['ORDERDATE'],
y=df_sales_pred['SALES'],
name='actual'
),
go.Scatter(
x=df_sales_pred['ORDERDATE'],
y=df_sales_pred['pred_value'],
name='predicted'
)
]
plot_layout = go.Layout(
title='Sales Prediction'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig) 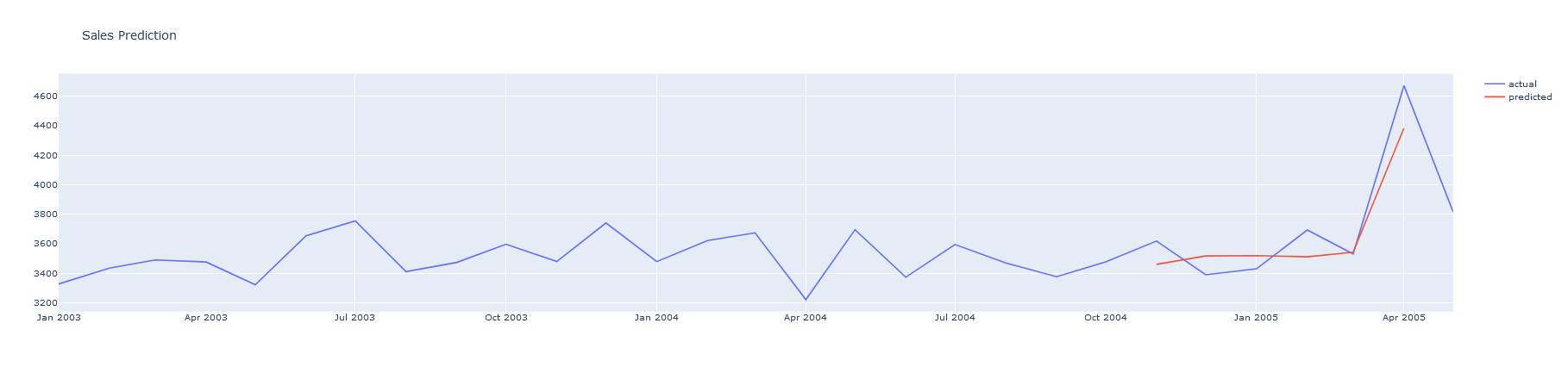
予測値は、数100の誤差で、近いことがわかります。これは、非常に単純なモデルで数分のうちに十分に近い予測ができる、予測の力を示しています。
結論
この記事では、Keras、python、gridDBを使用してLSTM予測モデルを学習する方法を学びました。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.