
はじめに
ほとんどのウェブサイトでは、APIを介してユーザーにデータを提供しています。しかし、そのようなAPIを開発していないウェブサイトもあります。そのようなウェブサイトのデータにアクセスするには、Webスクレイピングを使用するという方法があります。
Webスクレイピングとは、ウェブサイトのコンテンツからデータを抽出するための技術です。データは通常、各ウェブサイトのHTML要素から抽出されます。
ワシントンDCでJavaプログラマーの仕事を探しているとします。仕事を探すためには、多くの時間を投資しなければならないのが通常です。一つ一つ自分で探すのは、退屈で時間がかかる作業です。
このプロセスを簡単にして時間を節約するために、Jsoupを使ってウェブスクレーパーを作成し、この探すプロセスを自動化することができます。ウェブスクレーパーは、選択した求人情報サイトから求人に関するデータをスクレイピングし、それをGridDBなどのデータベースに保存します。
Webスクレイピングを使うことで、データ収集のプロセスを高速化し、時間を節約することができます。このブログでは、JavaのJsoupを使ってウェブサイトからデータをスクレイピングし、そのデータをGridDBに保存する方法を紹介します。
前提条件
Jsoup とは何か?
Jsoupは、HTML文書の内容を抽出したり操作したりするためのメソッドで構成されたJavaライブラリです。Jsoupはオープンソースで、2009年にJonathan Hedley氏によって開発されました。もしあなたがjQueryに詳しければ、Jsoupも簡単に使うことができるはずです。Jsoupでは以下のようなことができます。
-
ファイル、URL、または文字列からのHTMLのスクレイピングと解析を行う
-
CSSセレクタやDOMトラバーサルを用いてデータを検索・抽出する
-
HTMLの要素、テキスト、属性を操作する
-
整理してHTMLを出力する
Jsoupをプロジェクトに追加する方法
Jsoupライブラリを使用するには、JavaプロジェクトにJsoupを追加する必要があります。Jsoupのサイトからjarファイルをダウンロードして、Javaプロジェクトで参照してください。JsoupサイトのURLは以下の通りです。
https://jsoup.org/download
Eclipseで以下の手順を実行します。
Step 1: プロジェクトエクスプローラー上でプロジェクト名を右クリックし、表示されたメニューから「プロパティ…」を選択します。
Step 2: プロパティダイアログで以下の操作を行います。
-
左側のリストからJavaのビルドパスを選択します。
-
「Libraries」 タブをクリックします。
-
「Add external JARS… 」ボタンをクリックし、Jsoupのjarファイルを保存した場所に移動します。「Open」ボタンをクリックします。
Step 3: 「OK」をクリックしてダイアログボックスを閉じます。
後述するように、OSのターミナルから直接Jsoupライブラリを使用することも可能です。
パッケージをインポートする
まず、プロジェクトで必要となるすべてのライブラリをインポートします。これを以下に示します。
import java.io.IOException;
import java.util.Collection;
import java.util.Properties;
import java.util.Scanner;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;次に、Jsoupを使ってWebページからコンテンツを取得する方法をご紹介します。
ページを取得する方法
DOMを扱うためには、解析可能なドキュメントのマークアップが必要となります。Jsoupはウェブページを表わすために、org.jsoup.nodes.Documentオブジェクトを使用しています。
Webページを取得するための最初のステップは、リソースへの接続を確立することです。次に,Webページの内容を取得するために,get()関数を呼び出す必要があります。
このブログでは、以下のURLのJava sub-redditをスクレイピングします。
https://www.reddit.com/r/java/
ページを取得します。
Document subreddit = Jsoup.connect("https://www.reddit.com/r/java/").get();ウェブサイトの中には、未知のユーザーエージェントを使ったクロールを許可していないものがあります。ウェブスクレイパーがブロックされるのを防ぐために、Mozillaのユーザーエージェントを使います。
Document subreddit = Jsoup.connect("https://www.reddit.com/r/java/").userAgent("Mozilla").data("name", "jsoup").get();WebページのHTMLコンテンツを格納するために、Documentコンテナを作成し、subredditという名前をつけました。
subreddit`コンテナの内容をプリントアウトすると、WebページのHTMLコンテンツ、つまりJavaのsub-redditが表示されます。次のコマンドを実行します。
System.out.println(subreddit);今回のケースでは、投稿のタイトルと各投稿が作成された時間を取得したいので、これにはHTMLタグを使用します。すべてのタイトルは <h3> タグに格納され、以下のようなクラス名が与えられています。
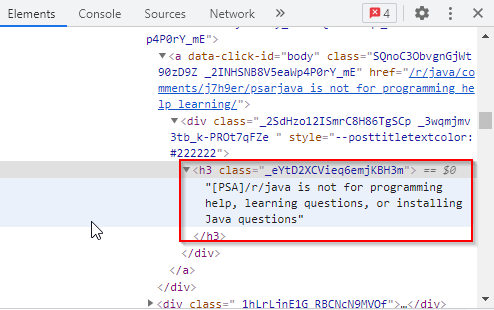
投稿が作成された時間は、<a>タグに格納され、以下のようなクラス名が与えられています。
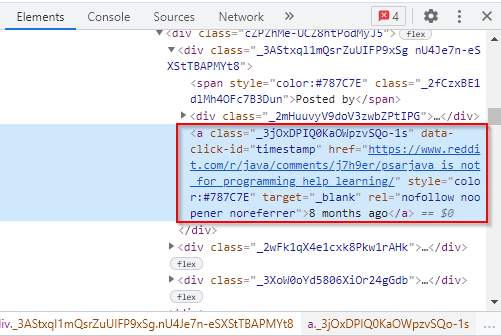
上記のHTMLタグを使って、ウェブサイトからタイトル記事と作成された時間をスクレイピングします。以下は、タイトルをスクレイピングするためのJavaコードです。
Elements titles = subreddit.select("h3[class]._eYtD2XCVieq6emjKBH3m");
for (Element title : titles)
{
System.out.println("Title: " + title.text());
}titlesという名前の要素を作成し、その中にすべてのタイトルを格納します。そして、要素に格納されているすべてのアイテムを反復して表示するために、forループを作成しました。これにより、投稿の個々のタイトルにアクセスできるようになります。
以下は、投稿が作成された時間をスクレイピングするためのJavaコードです。
Elements times = subreddit.select("a[class]._3jOxDPIQ0KaOWpzvSQo-1s");
for (Element time : times) {
System.out.println("Time Posted: " + time.text());
}サイトから抽出したすべての時間を格納するために、timesという名前の要素を作成しました。そして、forループを使って、要素に格納されているアイテムを繰り返し処理し、それらをプリントアウトしています。
それでは、forループを入れ子にしてコードを組み立て、tryとcatchブロックで囲んで、ウェブサイトのスクレイピング時に発生する可能性のある例外をキャッチしてみましょう。これを以下に示します。
try {
for (Element title : titles) {
for (Element time : times) {
System.out.println("Title: " + title.text());
System.out.println("Time Posted: " + time.text());
}
}
catch (IOException e) {
e.printStackTrace();
}
}この時点でコードを実行すると、投稿のタイトルや投稿された時間など、サイトからスクレイピングされたテキストが表示されます。
スクレイピングした DataをGridDBに格納する
サイトからのデータのスクレイピングに成功したら、次にそのデータをGridDBに格納します。
まず、コンテナスキーマをスタティッククラスとして作成します。
public static class Post{
@RowKey String post_title;
String when;
}上のクラスは、私たちのクラスタ内のコンテナを表しています。SQLテーブルとして見ることができます。
GridDBへの接続を確立するためには、接続するクラスタの名前、接続する必要のあるユーザの名前、そのユーザのパスワードなど、GridDBインストールの詳細を使用してPropertiesインスタンスを作成する必要があります。以下のコードでこれを説明します。
Properties props = new Properties();
props.setProperty("notificationAddress", "239.0.0.1");
props.setProperty("notificationPort", "31999");
props.setProperty("clusterName", "defaultCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);クエリの実行を開始するには、それぞれのコンテナを取得する必要があります。先ほどPostという名前のコンテナを作成しておいたので、これを取得しましょう。
Collection<String, Post> coll = store.putCollection("col01", Post.class);コンテナのインスタンスを作成して、collという名前をつけました。これからコンテナを参照するときには、この名前を使うことになります。
次に、コンテナの2つのカラムのそれぞれにインデックスを作成してみましょう。
coll.createIndex("post_title");
coll.createIndex("when");
coll.setAutoCommit(false);AutoCommitをfalseに設定していることにも注意してください。これは、手動で変更をコミットしなければならないことを意味しています。
次に、コンテナのインスタンス(Post)を作成し、そのインスタンスを使って、データの準備とコンテナへの挿入を行います。これを以下に示します。
Post post = new Post();
post.post_title = title.text();
post.when = time.text();
coll.put(post);
coll.commit();データベースへの変更をコミットしたら、元に戻すことはできません。
コードをコンパイルする
まず、gsadmユーザでログインします。作成したjavaファイルとJsoupの.jarファイルを、以下のパスにあるGridDBのbinフォルダに移動します。
/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin
次に、Linuxのターミナルで以下のコマンドを実行し、gridstore.jarファイルのパスを設定します。
export CLASSPATH=$CLASSPATH:/home/osboxes/Downloads/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin/gridstore.jar次に、上記のディレクトリに移動し、以下のコマンドを実行して、WebScraping.javaファイルをコンパイルします。
javac -cp jsoup-1.13.1.jar WebScraping.java以下のコマンドを実行して生成された.classファイルを実行します。
java WebScraping以上、JavaでJsoupを使ってウェブサイトからデータをスクレイピングし、GridDBにデータを挿入する方法を紹介しました。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.