
このチュートリアルでは、Kaggleで公開されているクレジットカード不正取引検出のデータセットを探ります。クレジットカード会社にとって、損失を避けるために不正を検出することは非常に重要であり、同時に顧客が実際に購入していないものを請求しないようにすることも重要です。我々は、GridDBを使用してデータを抽出し、不正を正確に検出するための機械学習モデルを構築します。
チュートリアルの概要は以下の通りです。
- データセット概要
- 必要なライブラリのインポート
- データセットの読み込み
- 探索的データ解析
- 機械学習モデル構築
- モデル評価
- 結論
- 参考文献
GridDBのインストール
このチュートリアルでは、データセットをロードする際に、GridDBを使用する方法と、Pandasを使用する方法の2つを取り上げます。Pythonを使用してGridDBにアクセスするためには、以下のパッケージも予めインストールしておく必要があります。
- GridDB C-クライアントです。
- SWIG (Simplified Wrapper and Interface Generator)
- GridDB Pythonクライアントです。
1. データセット概要
このデータセットには、2013年9月の2日間にヨーロッパのカード会員が行ったすべてのクレジットカード取引が含まれています。合計284,407件の取引があり、そのうち492件が不正取引です。明らかに、このデータセットは非常にアンバランスであり、詐欺のクラスは全取引の0.172%しか構成されていません。
データセットにPCA(主成分分析)変換を適用した。PCA変換とは、相関のある可能性のある変数を、主成分と呼ばれる線形相関のない変数の値の集合に変換することを指します。PCAでは、V1, V2, …, V28が特徴量として与えられ、変換されていない唯一の特徴量は、取引時刻と取引額です。残りの生の(元の)特徴は機密情報を含んでいるので、これらは最終的なデータセットには含まれません。
機能の説明
-
Time:各トランザクションとデータセットの最初のトランザクションとの間の経過秒数が含まれています。
-
Acount:取引金額です。
-
V1、V2、…、V28:変換された特徴量であり、必ずしもクレジットカード取引に関連する生の特徴量ではない可能性があります。
このデータセットは一般に公開されており、Kaggleからダウンロードできます。このチュートリアルに沿って、データセットをダウンロードしてください。
2. 必要なライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import auc
from sklearn.metrics import make_scorer
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_scoreパッケージのインストールに失敗した場合は、コマンドラインに pip install package-name と入力することでインストールすることができます。また、condaの仮想環境を使用している場合は、conda install package-nameと入力することでもインストールできます。
3. データセットの読み込み
続けて、データセットをノートブックにロードしてみましょう。
3.a GridDBの使用
大量のデータを保存する場合、CSVファイルでは面倒なことがあります。GridDBはオープンソースであり、拡張性の高いデータベースであるため、完璧な代替案として機能します。GridDBは、スケーラブルでインメモリなNo SQLデータベースで、大量のデータを簡単に保存することができます。GridDBを初めて使う場合は、「GridDBへの読み書き」4のチュートリアルが役に立ちます。
すでにデータベースの設定が済んでいると仮定して、今度はデータセットを読み込むためのSQLクエリをpythonで書いてみましょう。
import griddb_python as griddb
sql_statement = ('SELECT * FROM credit_card_dataset')
heart_dataset = pd.read_sql_query(sql_statement, cont)変数 cont には、データが格納されているコンテナ情報が格納されていることに注意してください。credit_card_dataset` をコンテナの名前に置き換えてください。詳細は、チュートリアルGridDBへの読み書きを参照してください。
3.b Pandasの使用
Pandasの read_csv 関数を使用して、データを読み込むこともできます。どちらの方法でも、pandasのdataframeの形でデータが読み込まれるので、上記のどちらの方法でも同じ出力になります。
credit_card_dataset = pd.read_csv('creditcard.csv')4. 探索的データ解析
データセットが読み込まれたら、次はそのデータセットを調べてみましょう。head()関数の引数に10を渡して、このデータセットの最初の10行を表示します。
credit_card_dataset.head(10)| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | … | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | … | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | … | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | … | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | … | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | … | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
| 5 | 2.0 | -0.425966 | 0.960523 | 1.141109 | -0.168252 | 0.420987 | -0.029728 | 0.476201 | 0.260314 | -0.568671 | … | -0.208254 | -0.559825 | -0.026398 | -0.371427 | -0.232794 | 0.105915 | 0.253844 | 0.081080 | 3.67 | 0 |
| 6 | 4.0 | 1.229658 | 0.141004 | 0.045371 | 1.202613 | 0.191881 | 0.272708 | -0.005159 | 0.081213 | 0.464960 | … | -0.167716 | -0.270710 | -0.154104 | -0.780055 | 0.750137 | -0.257237 | 0.034507 | 0.005168 | 4.99 | 0 |
| 7 | 7.0 | -0.644269 | 1.417964 | 1.074380 | -0.492199 | 0.948934 | 0.428118 | 1.120631 | -3.807864 | 0.615375 | … | 1.943465 | -1.015455 | 0.057504 | -0.649709 | -0.415267 | -0.051634 | -1.206921 | -1.085339 | 40.80 | 0 |
| 8 | 7.0 | -0.894286 | 0.286157 | -0.113192 | -0.271526 | 2.669599 | 3.721818 | 0.370145 | 0.851084 | -0.392048 | … | -0.073425 | -0.268092 | -0.204233 | 1.011592 | 0.373205 | -0.384157 | 0.011747 | 0.142404 | 93.20 | 0 |
| 9 | 9.0 | -0.338262 | 1.119593 | 1.044367 | -0.222187 | 0.499361 | -0.246761 | 0.651583 | 0.069539 | -0.736727 | … | -0.246914 | -0.633753 | -0.120794 | -0.385050 | -0.069733 | 0.094199 | 0.246219 | 0.083076 | 3.68 | 0 |
10 rows × 31 columns
ここで、Timeは数値変数です。それは有用ではありません。取引金額を含む Amount カラムがあります。次に、対象変数 Class の分布を見てみましょう。データセットには284,315件の非不正取引と492件の不正取引があり、不正と分類される取引は0.172%だけなので、非常にアンバランスな状態になっていることがわかります。
credit_card_dataset.Class.value_counts() 0 284315
1 492
Name: Class, dtype: int64
変数の分布を調べるために、ヒストグラムとしてプロットすることができます。プロット空間を整理するために、ターゲット変数と軸ラベルを削除します。
credit_card_dataset_without_target = credit_card_dataset.drop(columns = ['Class'], axis=1)
variable_hist = credit_card_dataset_without_target.hist(bins=100)
for axis in variable_hist.flatten():
axis.set_xticklabels([])
axis.set_yticklabels([])
plt.figure(figsize = (20,15))
plt.show()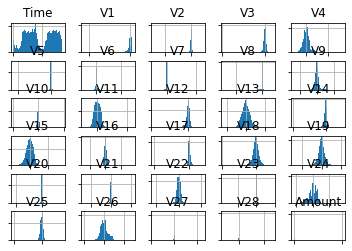
上記のように、ほとんどの変数がガウス分布であり、その多くがゼロを中心とした分布であることがわかります。これは、変数がPCA変換を経たときに標準化された可能性を示しています。
5. 機械学習モデル構築
それでは、クレジットカードのデータセットを使って、機械学習モデルを構築し、評価してみましょう。まず、モデルの特徴(features)とラベル(labels)を作成し、訓練用(train)とテスト用(test)のサンプルに分割します。テストサンプルはデータセット全体の20%です。
features = credit_card_dataset.drop(columns = ['Time', 'Class'], axis = 1)
labels = credit_card_dataset[['Class']]
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size = 0.2, random_state = 0)このチュートリアルの目的は、k-Nearest Neighbors 分類モデルを構築することです。k-最近傍モデルでは、予測のために、最も似ている(近い)k個の点を見て、それに応じて予測を行います。ここでは、「n_neighbors」パラメータを3としています。
model = KNeighborsClassifier(n_neighbors = 3)
model.fit(X_train, y_train) {.output .stream .stderr} /Users/aniket/opt/anaconda3/lib/python3.9/site-packages/sklearn/neighbors/\_classification.py:179: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n\_samples,), for example using ravel(). return self._fit(X, y)
{.output .execute_result execution_count="7"} KNeighborsClassifier(n_neighbors=3)
学習データに対してモデルの適合が行われた後、モデルの性能を評価するために、テストセットに対する予測に進むことができます。予測値を predicted に格納しましょう。
predicted = model.predict(X_test)6. モデル評価
我々は、classification report` メトリックを使用して、modelphaの性能を評価します。Classification reportは分類モデルを評価するために広く使われている指標です。これは以下のように出力されます。
- Precision: 予測された正のオブザベーションの合計に対する,正しく予測された正のオブザベーションの比率
- Recall: 実際のクラスでの全オブザベーションに対する正しく予測されたポジティブオブザベーションの比率
- F1 score: PrecisionとRecallの調和平均
- Support: 各クラスで予測されたオブザベーションの数
print(classification_report(predicted,y_test)) {.output .stream .stdout}
precision recall f1-score support
0 1.00 1.00 1.00 56882
1 0.72 0.91 0.81 80
accuracy 1.00 56962
macro avg 0.86 0.96 0.90 56962
weighted avg 1.00 1.00 1.00 56962
7. 結論
このチュートリアルでは、GriDBとPythonを使用して、クレジットカード詐欺検出データセットの分類器を構築する方法について見てきました。データのインポート方法として、(1)GridDB、(2)Pandasの2つの方法を検討しました。GridDBはオープンソースで拡張性が高いため、大規模なデータセットの場合、ノートブックにデータを取り込むための優れた代替手段となります。GridDBを今すぐダウンロードしてください。
8. 参考文献
- https://www.kaggle.com/mlg-ulb/creditcardfraud
- https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
- https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
- https://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb