
はじめに
Pandas データフレームは、そのドキュメントで定義されているように、「2次元の、サイズ変更可能な、潜在的に異種の表形式データ」であるデータ構造です。データフレームは、開発者やデータサイエンティストが長いコードブロックを書くことなく迅速に実験を行うことを可能にし、データ分析を素早くかつ簡単に行うことができます。
このブログでは、GridDBとPandasデータフレーム間の基本的な読み書きの方法と、GridDB開発者がよく使う変換方法について紹介します。
データを読み込む
GridDBからデータフレームにデータを読み込むには、通常のクエリを設定し、while rs.has_next()ループの代わりにrs.fetch_rows()を呼び出すと、以下の例のように、結果のデータフレームが返されます。
import datetime
import griddb_python as griddb
import sys
import pandas as pd
import matplotlib.pyplot as plt
factory = griddb.StoreFactory.get_instance()
argv = sys.argv
gridstore = factory.get_store(
host="239.0.0.1",
port=31999,
cluster_name="defaultCluster",
username="admin",
password="admin"
)
col = gridstore.get_container("precinct_108")
start = datetime.datetime.utcnow().timestamp()
query = col.query("select *")
rs = query.fetch(False)
rows = rs.fetch_rows()
rows['CMPLNT_FR'] = pd.to_datetime(rows['CMPLNT_FR'])
print(rows)
データを書き込む
データフレームから GridDB へのデータの書き込みも、簡単に行うことができます。データスキーマを格納したContainerInfoオブジェクトを作成し、コンテナを開き、データフレームを引数としてput_rows()を呼び出します。注意点としては、スキーマの列順とデータフレームの列順が一致している必要がありますが、仕様書のリストに正しい列順を指定しておくと、データフレームの列順を簡単に変更することができます。
conInfo = griddb.ContainerInfo("PANDAS_AGGS",
[["key", griddb.Type.STRING],
["timestamp", griddb.Type.TIMESTAMP],
["precinct", griddb.Type.INTEGER],
["count", griddb.Type.INTEGER]],
griddb.ContainerType.COLLECTION, True)
aggcn = gridstore.put_container(conInfo)
aggcn.put_rows(df[["key", "timestamp","precinct","count"]])
簡単に変換する
データフレームで実行できる簡単な操作の例はたくさんありますが、ここではそのうちのいくつかを紹介します。
列の値を設定します。
df['precinct'] = 108
異なる2つの列を組み合わせて、各行の和や差を求める場合も同様です。
df['key'] = df['CMPLNT_FR'].dt.strftime('%Y-%m-%d') +"_"+ df['precinct'].astype('str')
列の名前を変更します。
df = df.rename(columns={'CMPLNT_FR':'timestamp'})
Binning, Bucketing
時系列予測のチュートリアルでは、個々の苦情を月ごとに報告された苦情の数に変換する必要がありました。これには複数のネストしたforループが必要でした。Pandas データフレームを使えば、同じことを1行のコードで実現することができます。
monthly_df = rows.groupby([pd.Grouper(key='CMPLNT_FR',freq='M')]).size().reset_index(name='count')
一見すると複雑なコードに見えますが、行は入力引数リストで定義されたグループに分割されます。これらのグループのそれぞれのサイズは、’count’列に入れることができます。
また、曜日や時間ごとにイベントの発生状況を把握することも有効です。実際、私は日曜日や午後5時のデータだけを簡単に照会するために、構築したスキーマに dayofweek と hourofday フィールドを含めることがよくありますが、Pandasのデータフレームでは、どちらも一行で済みます。
weekly_df = rows.groupby(rows['CMPLNT_FR'].dt.day_name()).size().reset_index(name='count')
hourly_df = rows.groupby(rows['CMPLNT_FR'].dt.hour).size().reset_index(name='count')
パフォーマンス
では、実際にどちらが速いのでしょうか?pyarrayやdataframesへの読み書きは?Binningについてははどうでしょうか?
実はPandasのデータフレームには欠点があります。それは速度が遅いことです。
10000行の書き込みと読み込みを行う簡単なベンチマークを書いてみましたが、データフレームをGridDBに書き込むと、同じデータをList of Listsとして multiputするよりも約50%遅くなります。
blob = bytearray([65, 66, 67, 68, 69, 70, 71, 72, 73, 74])
conInfo = griddb.ContainerInfo("col01",
[["name", griddb.Type.STRING],
["status", griddb.Type.BOOL],
["count", griddb.Type.LONG],
["lob", griddb.Type.BLOB]],
griddb.ContainerType.COLLECTION, True)
i=0
rows=[]
while i < 10000:
rows.append([str(uuid.uuid1()), False, random.randint(0, 1048576), blob])
i=i+1
gridstore.drop_container("col01")
start = datetime.datetime.utcnow().timestamp()
col = gridstore.put_container(conInfo)
col.multi_put(rows)
print("multiput took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")
df = pandas.DataFrame(rows, columns=["name", "status", "count", "lob"])
gridstore.drop_container("col01")
start = datetime.datetime.utcnow().timestamp()
col = gridstore.put_container(conInfo)
col.put_rows(df)
col.multi_put(rows)
print("putrows took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")
データを読み返すと、結果セットをpylistに追加すると、データフレームに直接読み込むよりも約25%速くなりました。リストを読み込んでからデータフレームに変換すると、再び50%遅くなりました。
col = gridstore.get_container("col01")
start = datetime.datetime.utcnow().timestamp()
query = col.query("select *")
rs = query.fetch(False)
result = []
while rs.has_next():
result.append(rs.next())
print("pylist append took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")
start = datetime.datetime.utcnow().timestamp()
query = col.query("select *")
rs = query.fetch(False)
result = rs.fetch_rows()
print("fetch_rows took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")
Binningについては、binの数に依存します。以下のコードでは、binの数やサイズを調整することでパフォーマンスが変化しています。binの数が少なければパフォーマンスが良いということになりますが、一方でデータフレームのパフォーマンスは、binのサイズや数を調整してもそれほど変化しませんでした。
tqls=[]
dt = datetime.datetime(2000, 1, 1, 0, 0, 0)
while dt < datetime.datetime(2020, 1, 1, 0, 0):
start = int(dt.timestamp()*1000)
end = int((dt + relativedelta(months=+1)).timestamp()*1000)
query = "select count(*) where CMPLNT_FR > TO_TIMESTAMP_MS("+str(start)+")"
query = query + " AND CMPLNT_FR < TO_TIMESTAMP_MS("+str(end)+")"
tqls.append([dt, query])
dt = dt + relativedelta(months=+1);
col = gridstore.get_container("precinct_108")
start = datetime.datetime.utcnow().timestamp()
for tql in tqls:
q = col.query(tql[1])
rs = q.fetch(False)
if rs.has_next():
data = rs.next()
count = data.get(griddb.Type.LONG)
print([str(tql[0].timestamp()), count ])
print("forloop "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")
プロットする
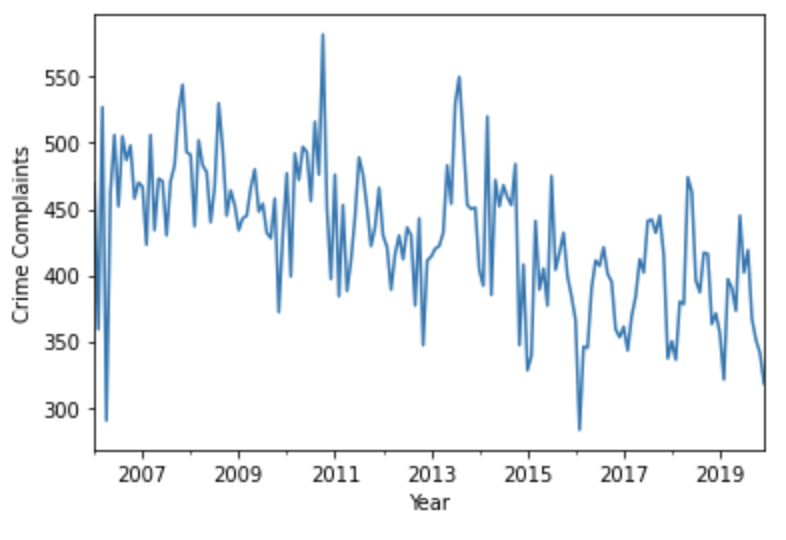
MatPlotLibを使えば、データフレームの可視化も簡単です。ここでは、2006年以降の月次集計の単純な折れ線グラフをプロットしてみましょう。
monthly_df = monthly_df.set_index('timestamp')
ts = monthly_df['count']
ax = ts['2006':].plot()
ax.set_xlabel('Year')
ax.set_ylabel('Crime Complaints')
ax.set_xlabel('Year')
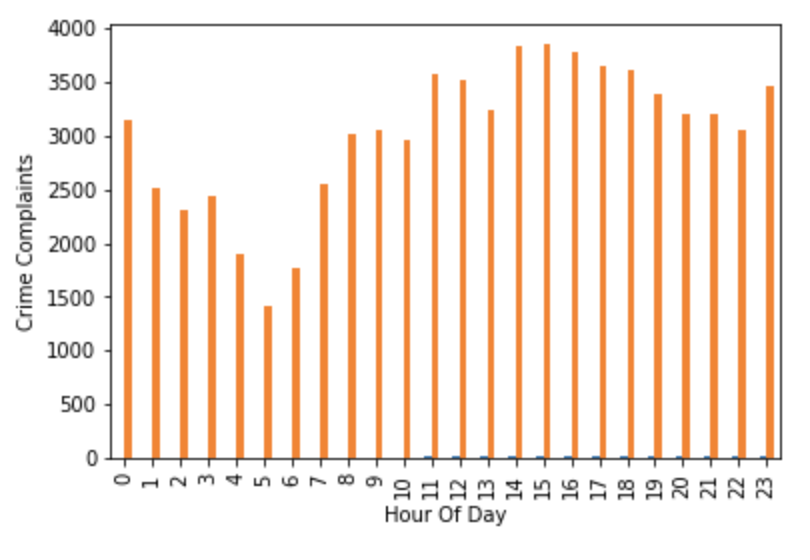
同様に、1日の中で犯罪が報告された時間帯の分布を表示するのも簡単です。
ax = hourly_df.plot.bar()
ax.set_xlabel('Hour Of Day')
ax.set_ylabel('Crime Complaints')
ax.get_legend().remove()
plt.show()
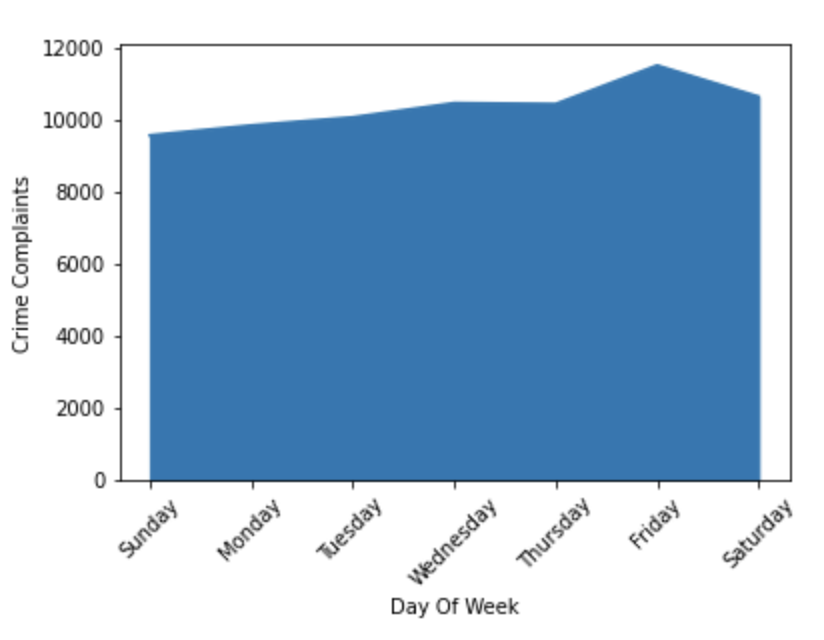
一週間のうちの分布を表示するには、曜日が比較順になっていないため少し難しいのですが、正しい順番で辞書を作成し、その辞書でインデックスを設定することで問題は解決します。
order = ['Sunday', 'Monday', 'Tuesday', 'Wednesday','Thursday','Friday','Saturday']
ax = weekly_df.set_index('timestamp').loc[order].plot(kind='area')
ax.set_xlabel('Day Of Week')
ax.set_ylabel('Crime Complaints')
plt.xticks(rotation=45)
ax.get_legend().remove()
plt.show()
まとめ
Pandas データフレームはGridDBの完璧な補完物であり、開発者はデータ駆動型のアプリケーションを素早く展開したり、mathplotlibと組み合わせることで、面倒なデータ変換を行うことなくデータに対する新しい洞察を得ることができます。データフレームは、大規模なデータセットを分析するためのより柔軟でシンプルな方法を提供するため、データベースの観点から見た生の読み書きの速度と引き換えに、開発のしやすさとコーディングの速さで補うことができます。
このブログで使用しているJupyter Notebookは、GridDB.netのGitHubページこちらで公開しています。