
GDPとは、「国内総生産」の略で、ある期間(通常1年間)に国内で生産された(市場で販売された)すべての最終財とサービスの貨幣価値の合計です。一国の経済成長を表す指標として用いられます。
GridDBを利用して、各国の経済状況を分析する予定です。GridDBは、高いスケーラビリティと最適化を実現したインメモリNoSQLデータベースで、特に時系列データベースにおいて、より高いパフォーマンスと効率性を実現するために並列処理を可能にします。今回はGridDBのNode.jsクライアントを使用します。GridDBとNode.jsを接続し、リアルタイムにデータをインポートまたはエクスポートすることができます。さらに、Danfo.jsライブラリを使用してデータフレームを操作し、データ解析を行います。
csv形式のデータセットはKaggleから入手したものです。このデータが何を表しているかは、後ほど「データ分析」の項で紹介します。
GridDBへのデータセットの書き出し
はじめに、GridDB ノードモジュール griddb node、danfojs-node、csv-parser を初期化します。 Griddb-nodeはGridDB上で作業できるようにノードを起動し、Danfojs-nodeはデータ解析で使用するdfという変数として初期化し、csv-parserは以下のようにcsvファイルを読み込んでGridDBにデータセットをアップロードします。
var griddb = require('griddb_node');
const dfd = require("danfojs-node")
const csv = require('csv-parser');
const fs = require('fs');
fs.createReadStream('./Dataset/GDP by Country 1999-2022.csv')
.pipe(csv())
.on('data', (row) => {
lst.push(row);
console.log(lst);
})変数の初期化に続いて、GridDB コンテナを生成し、データベーススキーマを作成します。コンテナ内では、データセット内のカラムのデータ型を定義する必要があります。このコンテナを利用して、格納されているデータにアクセスし、GridDB へのデータ挿入を完了します。
const conInfo = new griddb.ContainerInfo({
'name': "gdpanalysis",
'columnInfoList': [
["name", griddb.Type.STRING],
["Country", griddb.Type.STRING],
["1999", griddb.Type.DOUBLE],
["2000", griddb.Type.DOUBLE],
["2001", griddb.Type.DOUBLE],
["2002", griddb.Type.DOUBLE],
["2003", griddb.Type.DOUBLE],
["2004", griddb.Type.DOUBLE],
["2005", griddb.Type.DOUBLE],
["2006", griddb.Type.DOUBLE],
["2007", griddb.Type.DOUBLE],
["2008", griddb.Type.DOUBLE],
["2009", griddb.Type.DOUBLE],
["2010", griddb.Type.DOUBLE],
["2011", griddb.Type.DOUBLE],
["2012", griddb.Type.DOUBLE],
["2013", griddb.Type.DOUBLE],
["2014", griddb.Type.DOUBLE],
["2015", griddb.Type.DOUBLE],
["2016", griddb.Type.DOUBLE],
["2017", griddb.Type.DOUBLE],
["2018", griddb.Type.DOUBLE],
["2019", griddb.Type.DOUBLE],
["2020", griddb.Type.DOUBLE],
["2021", griddb.Type.DOUBLE]
],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});
/// Inserting Data into GridDB
for(let i=0;i<lst.length;i++){
store.putContainer(conInfo, false)
.then(cont => {
container = cont;
return container.createIndex({ 'columnName': 'name', 'indexType': griddb.IndexType.DEFAULT });
})
.then(() => {
idx++;
container.setAutoCommit(false);
return container.put([String(idx), lst[i]['Country'],lst[i]["1999"],lst[i]["2000"],lst[i]["2001"],lst[i]["2002"],lst[i]["2003"],lst[i]["2004"],lst[i]["2005"],lst[i]["2006"],lst[i]["2007"],lst[i]["2008"],lst[i]["2009"],lst[i]["2010"],lst[i]["2011"],lst[i]["2012"],lst[i]["2013"],lst[i]["2014"],lst[i]["2015"],lst[i]["2016"],lst[i]["2017"],lst[i]["2018"],lst[i]["2019"],lst[i]["2020"],lst[i]["2021"]]);
})
.then(() => {
return container.commit();
})
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
}GridDBからデータセットをインポートする
すでにコンテナ内にすべてのデータを保存しているので、あとはGridDBのSQLライクな問い合わせ言語であるTQLを使ってデータを取得するだけです。そこで、まず、getached_dataという名前で、取得したデータを格納するコンテナを構築します。次に、query というカラムオーダーで行を抽出し、df というデータフレームに保存して、データの可視化や分析を行い、データのインポートを完了します。
# Get the containers
obtained_data = gridstore.get_container("gdpanalysis")
# Fetch all rows - language_tag_container
query = obtained_data.query("select *")
# Creating Data Frame variable
let df = await dfd.readCSV("./out.csv")データ分析
データ分析を始めるにあたり、データセットの列とそれらが表すもの、そしてデータセットの行と列の総数を調べます。
- Country : データセットに含まれる国の名前。
- 1999 : 1990年における特定国のGDP。
-
2000 : 2000年における特定国のGDP。
.
.
.
-
2021 : 2021年における特定国のGDP。
console.log(df.shape)
// Output
// [ 180, 24 ]180行24列なので、1999年から2021年までの180種類の国のGDPがあります。
データセットにNULL値があるかどうかを確認します。
for (let column_name in p1_df.columns){
column = p1_df[column_name];
# Get the count of Zeros in column
count = (column == '0').sum();
console.log('Count of zeros in column ', column_name, ' is : ', count)
}
// Output
// Count of zeroes in column Country is : 0
// Count of zeroes in column 1999 is : 2
// Count of zeroes in column 2000 is : 1
// Count of zeroes in column 2001 is : 1
// Count of zeroes in column 2002 is : 0
// Count of zeroes in column 2003 is : 0
// Count of zeroes in column 2004 is : 0
// Count of zeroes in column 2005 is : 0
// Count of zeroes in column 2006 is : 0
// Count of zeroes in column 2007 is : 0
// Count of zeroes in column 2008 is : 0
// Count of zeroes in column 2009 is : 1
// Count of zeroes in column 2010 is : 1
// Count of zeroes in column 2011 is : 1
// Count of zeroes in column 2012 is : 1
// Count of zeroes in column 2013 is : 1
// Count of zeroes in column 2014 is : 13
// Count of zeroes in column 2015 is : 14
// Count of zeroes in column 2016 is : 14
// Count of zeroes in column 2017 is : 14
// Count of zeroes in column 2018 is : 14
// Count of zeroes in column 2019 is : 14
// Count of zeroes in column 2020 is : 15
// Count of zeroes in column 2021 is : 16GDPの値はすべてobjectデータ型なので、データセットのデータ型をfloatに変更し、GDPがゼロになることはないので、ゼロの値を各国のGDP中央値に置き換えることにします。
for (let column_name in p1_df.columns){
if(column_name == 'Country'){
continue;
}
else{
df = df.asType(column_name, "float64")
}
for (let column_name in p1_df.columns){
df[column_name]=df[column_name].replace(0, df[column_name].median())
}これでデータが綺麗になったので、分析を進めることができます。
まず、世界のGDPの推移を見るために、以下のように全180カ国のGDPを1つにまとめて算出した折れ線グラフをプロットします。
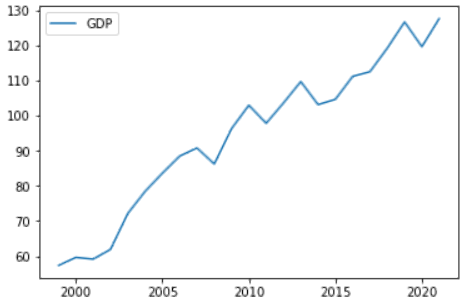
次に、1999年から2021年までの各国の進捗を、サマリー統計で比較します。
df.loc({columns:['2016', '2017', '2018', '2019', '2020', '2021']}).describe().round(2).print()
// Output
// ╔════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╗
// ║ │ 2016 │ 2017 │ 2018 │ 2019 │ 2020 │ 2021 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ count │ 180 │ 180 │ 180 │ 180 │ 180 │ 180 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ mean │ 111.26 │ 112.58 │ 119.30 │ 126.77 │ 119.70 │ 127.74 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ std │ 179.68 │ 176.69 │ 186.00 │ 196.63 │ 186.40 │ 199.65 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ min │ 0.16 │ 0.17 │ 0.17 │ 0.18 │ 0.23 │ 0.25 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ median │ 2657.38 │ 2868.33 │ 2978.95 │ 3207.04 │ 2689.55 │ 2899.29 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ max │ 19555.87 │ 20493.25 │ 21404.19 │ 22294.11 │ 22939.58 │ 24796.08 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ variance │ 32286.52 │ 31220.07 │ 34596.34 │ 38661.75 │ 34743.69 │ 39862.26 ║
// ╚════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╝中央値と分散を見ると、中央値でさえもかなり低く、分散も大きいので、世界のほとんどの国が経済的に苦しんでいることがわかり、第一世界の国と第三世界の国の違いを決定づけます。 この苦しみは、2018年から2020年にかけてのCovid-19が、あらゆる国に大打撃を与え、経済全体を混乱させたために発生しました。しかし、Covid-19の症例が減ってからは、上の折れ線グラフのように、各国が回復に向かいました。一方、これだけ苦悩しても、2016年から2021年までの過去6年間でGDPが最大になった国はどこか、見てみましょう。
console.log(df.loc(df[df['2016'].max()]))
console.log(df.loc(df[df['2017'].max()]))
console.log(df.loc(df[df['2018'].max()]))
console.log(df.loc(df[df['2019'].max()]))
console.log(df.loc(df[df['2020'].max()]))
console.log(df.loc(df[df['2021'].max()]))
// Output
// United States
// United States
// United States
// United States
// United States
// United States米国がGDPチャートでトップになったのは当然ですが、中国も遠く及びません。中国も米国と競うように台頭しており、その差は下の棒グラフで見るほど大きくはありません。
## Distribution of Column Values
const { Plotly } = require('node-kernel');
let cols = df.columns
for(let i = 0; i < cols.length; i++)
{
let data = [{
x: cols[i],
y: df[cols[i]].values,
type: 'bar'}];
let layout = {
height: 400,
width: 700,
title: 'GDP for United States of America and China (2016 - 2021)' +cols[i],
xaxis: {title: cols[i]}};
// There is no HTML element named `myDiv`, hence the plot is displayed below.
Plotly.newPlot('myDiv', data, layout);
}
df.plot("plot_div").bar()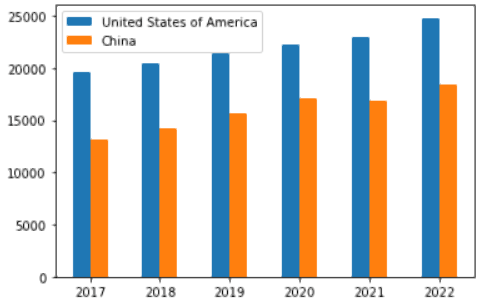
結論
2021年にCovid-19の規制が抑えられ、Covid-19の損失から回復し始めた国もありましたが、ロシアのウクライナ侵攻が再び世界経済を直撃しました。 石油価格が高騰してインフレを招き、こうした変動が今度は2022年の各国のGDPを計算するときに、GDPを下げてしまうことになります。
その一方で、ある第三国は第一世界の一員になろうとしており、第一世界の国々は超大国の座をめぐって競い合っていることが、データをもとに見えてきたのです。
最後に、今回のデータ分析には、データへの素早いアクセスと効率的な読み書き・保存を可能にするGridDBを使用しました。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb