気候変動の影響とそれに伴う地域・地方スケールでの異常気象を理解することは、実現可能な適応策を計画・開発する上で非常に重要です。
気候変動は、間違いなく現代における人類への最も深刻な脅威です。IPCCによれば、気候変動による悪影響を緩和するためには、世界の平均気温を産業革命以前の水準から1.5℃以内に抑える必要があるとされています。
今回は、PythonとGridDBの力を使って、気温変動のマップチャートやアニメーションを作成する方法について分析します。
フルソースコードとjupyterファイルへのリンクです。
https://github.com/griddbnet/Blogs/tree/analyzing-global-climate-change
チュートリアルの概要は以下の通りです。
- データセット概要
- 必要なライブラリのインポート
- データセットの読み込み
- データのクリーニングと前処理
- データの可視化による分析
- まとめ
前提条件と環境設定
このチュートリアルは、Windows オペレーティングシステム上の Anaconda Navigator (Python バージョン – 3.8.5) で実行されます。チュートリアルを続ける前に、以下のパッケージがインストールされている必要があります。
- Pandas
- NumPy
- plotly
- Matplotlib
- Seaborn
- griddb_python
これらのパッケージは Conda の仮想環境に conda install package-name を使ってインストールすることができます。ターミナルやコマンドプロンプトから直接Pythonを使っている場合は、 pip install package-name でインストールできます。
GridDBのインストール
このチュートリアルでは、データセットをロードする際に、GridDB を使用する方法と、Pandas を使用する方法の 2 種類を取り上げます。Pythonを使用してGridDBにアクセスするためには、以下のパッケージも予めインストールしておく必要があります。
- GridDB Cクライアント
- SWIG (Simplified Wrapper and Interface Generator)
- GridDB Pythonクライアント
データセット概要
データセットはローレンス・バークレー国立研究所に所属するバークレー・アースによってまとめられたもので、世界中の気温データを含んでいます。データセットは数個のファイルに分かれていますが、全世界の陸上と海陸の気温 (GlobalTemperatures.csv) に含まれるいくつかのデータについて紹介します。
- Date: 陸上平均気温は1750年から、陸上最高・最低気温と全球海洋・陸上気温は1850年から開始
- LandAverageTemperature: 世界平均陸上気温(単位:摂氏)
https://www.kaggle.com/datasets/berkeleyearth/climate-change-earth-surface-temperature-data
必要なライブラリのインポート
# import griddb_python as griddb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly
import plotly.graph_objs as go
import plotly.tools as tls
import plotly.express as px
import plotly.graph_objs as go
import seaborn as sns
import time
import warnings
warnings.filterwarnings('ignore')
%matplotlib inlineデータセットの読み込み
続けて、データセットをノートブックにロードしてみましょう。
GridDBを利用する
東芝GridDB™は、IoTやビッグデータに最適な高スケーラブルNoSQLデータベースです。GridDBの理念の根幹は、IoTに最適化され、高い拡張性を持ち、高性能のためにチューニングされ、高い信頼性を確保した汎用性の高いデータストアの提供にあります。
大量のデータを保存する場合、CSVファイルでは面倒なことがあります。GridDBは、オープンソースでスケーラブルなデータベースとして、完璧な代替手段となっています。GridDBは、スケーラブルでインメモリなNo SQLデータベースで、大量のデータを簡単に保存することができます。GridDBを初めて使う場合は、GridDBへの読み書きのチュートリアルが役に立ちます。
すでにデータベースのセットアップが完了していると仮定して、今度はデータセットをロードするためのSQLクエリをPythonで書いてみましょう。
factory = griddb.StoreFactory.get_instance()
Initialize the GridDB container (enter your database credentials)
try:
gridstore = factory.get_store(host=host_name, port=your_port,
cluster_name=cluster_name, username=admin,
password=admin)
info = griddb.ContainerInfo("GlobalTemperatures",
[["dt", griddb.Type.TIMESTAMP],["LandAverageTemperature", griddb.Type.DOUBLE],
["LandAverageTemperatureUncertainty", griddb.Type.DOUBLE],
["LandMaxTemperature", griddb.Type.DOUBLE],
["LandMaxTemperatureUncertainty", griddb.Type.DOUBLE],
["LandMinTemperature", griddb.Type.DOUBLE],
["LandMinTemperatureUncertainty", griddb.Type.DOUBLE],
["LandAndOceanAverageTemperature", griddb.Type.DOUBLE],
["LandAndOceanAverageTemperatureUncertainty", griddb.Type.DOUBLE],
, True)
cont = gridstore.put_container(info)
data = pd.read_csv("GlobalTemperatures.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Data added successfully")
try:
gridstore = factory.get_store(host=host_name, port=your_port,
cluster_name=cluster_name, username=admin,
password=admin)
info = griddb.ContainerInfo("GlobalLandTemperaturesByCity",
[["dt", griddb.Type.TIMESTAMP],["AverageTemperature", griddb.Type.DOUBLE],
["AverageTemperatureUncertainty", griddb.Type.DOUBLE],
["City", griddb.Type.STRING],["Country", griddb.Type.STRING],
["Latitude", griddb.Type.STRING], ["Longitude", griddb.Type.STRING],True)
cont = gridstore.put_container(info)
data = pd.read_csv("GlobalLandTemperaturesByCity.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Data added successfully")
try:
gridstore = factory.get_store(host=host_name, port=your_port,
cluster_name=cluster_name, username=admin,
password=admin)
info = griddb.ContainerInfo("GlobalLandTemperaturesByState",
[["dt", griddb.Type.TIMESTAMP],["AverageTemperature", griddb.Type.DOUBLE],["AverageTemperatureUncertainty", griddb.Type.DOUBLE],
["State", griddb.Type.STRING],["Country", griddb.Type.STRING], True)
cont = gridstore.put_container(info)
data = pd.read_csv("GlobalLandTemperaturesByState.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Data added successfully")Data added successfully
pandasライブラリが提供するread_sql_query関数は、取得したデータをpandasのデータフレームに変換し、ユーザーが作業しやすいようにします。
sql_statement1 = ('SELECT * FROM GlobalTemperatures.csv')
df1 = pd.read_sql_query(sql_statement1, cont)
sql_statement2 = ('SELECT * FROM GlobalLandTemperaturesByCity.csv')
df2 = pd.read_sql_query(sql_statement2, cont)
sql_statement3 = ('SELECT * FROM GlobalLandTemperaturesByState.csv')
df3 = pd.read_sql_query(sql_statement3, cont)変数 cont には、データが格納されているコンテナ情報が格納されていることに注意してください。credit_card_dataset をコンテナの名前に置き換えてください。詳細は、チュートリアルGridDBへの読み書きを参照してください。
IoTやビッグデータのユースケースに関して言えば、GridDBはリレーショナルやNoSQLの領域の他のデータベースの中で明らかに際立っています。全体として、GridDBは高可用性とデータ保持を必要とするミッションクリティカルなアプリケーションのために、複数の信頼性機能を提供しています。
pandasのread_csvを使用する
また、Pandasの read_csv 関数を使用してデータを読み込むこともできます。どちらの方法を使っても、データはpandasのdataframeの形で読み込まれるので、上記のどちらの方法も同じ出力になります。
global_temp_country = pd.read_csv('GlobalLandTemperaturesByCity.csv')global_temp_country.head()global_temp=pd.read_csv('GlobalTemperatures.csv')global_temp.head()GlobalTempState = pd.read_csv('GlobalLandTemperaturesByState.csv') GlobalTempState.head()データクリーニングと前処理
global_temp_country.isna().sum()dt 0
AverageTemperature 364130
AverageTemperatureUncertainty 364130
City 0
Country 0
Latitude 0
Longitude 0
dtype: int64
global_temp_country.dropna(axis='index',how='any',subset=['AverageTemperature'],inplace=True)def fetch_year(date):
return date.split('-')[0]
global_temp['years']=global_temp['dt'].apply(fetch_year)
global_temp.head()データの可視化による分析
各国の平均気温を計算してみましょう。
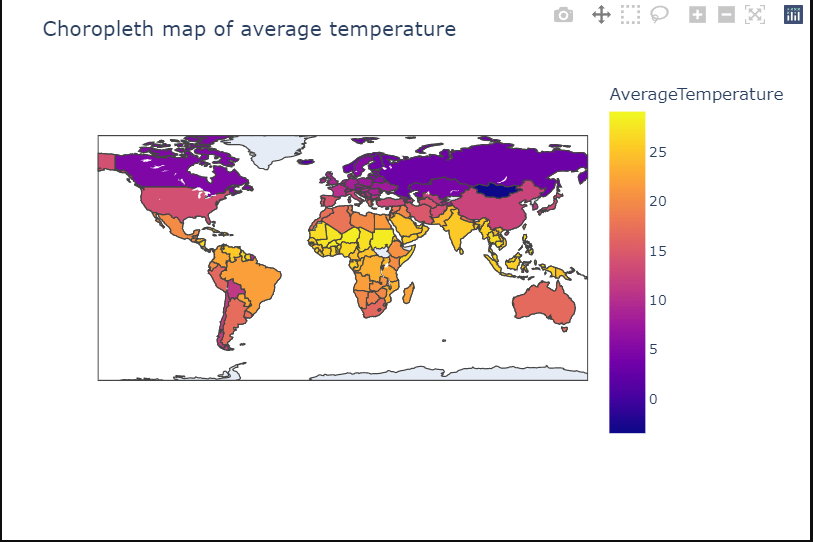
avg_temp=global_temp_country.groupby(['Country'])['AverageTemperature'].mean().to_frame().reset_index()
avg_tempfig=px.choropleth(avg_temp,locations='Country',locationmode='country names',color='AverageTemperature')
fig.update_layout(title='Choropleth map of average temperature')
fig.show()
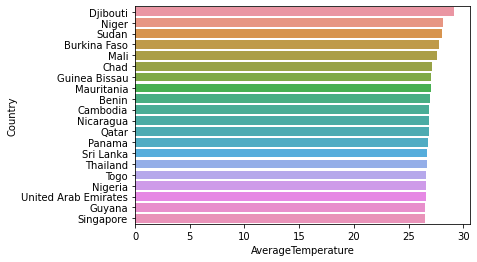
# The average temperature and Horizontal Bar sort by countries
sns.barplot(x=avg_temp.sort_values(by='AverageTemperature',ascending=False)['AverageTemperature'][0:20],y=avg_temp.sort_values(by='AverageTemperature',ascending=False)['Country'][0:20])<AxesSubplot:xlabel='AverageTemperature', ylabel='Country'>
地球温暖化は進んでいるのでしょうか?
data=global_temp.groupby('years').agg({'LandAverageTemperature':'mean','LandAverageTemperatureUncertainty':'mean'}).reset_index()
data.head()data['Uncertainty top']=data['LandAverageTemperature']+data['LandAverageTemperatureUncertainty']
data['Uncertainty bottom']=data['LandAverageTemperature']-data['LandAverageTemperatureUncertainty']fig=px.line(data,x='years',y=['LandAverageTemperature',
'Uncertainty top', 'Uncertainty bottom'],title='Average Land Tmeperature in World')
fig.show()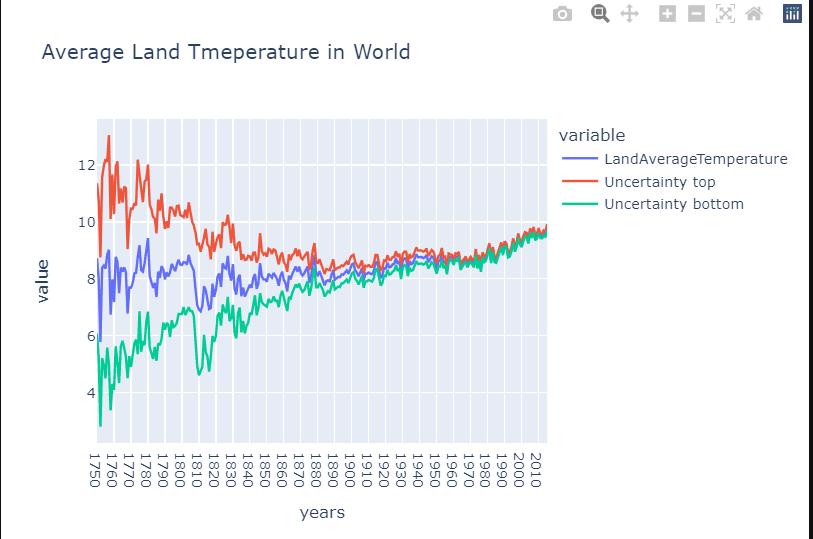
このグラフは、現在、地球が温暖化していることを示しています。地表の平均気温は、過去3世紀で最も高いレベルに達しています。ここ30年で最も速いスピードで気温が上昇しているのです。早く人類がエコロジーなエネルギー源に完全移行して、CO2を減らしてほしいものです。このままでは大変なことになります。このグラフには信頼区間もあり、近年、気温の測定が正確になってきていることがわかります。
各季節の平均気温
global_temp = global_temp[['dt', 'LandAverageTemperature']]
global_temp['dt'] = pd.to_datetime(global_temp['dt'])
global_temp['year'] = global_temp['dt'].map(lambda x: x.year)
global_temp['month'] = global_temp['dt'].map(lambda x: x.month)
def get_season(month):
if month >= 3 and month <= 5:
return 'spring'
elif month >= 6 and month <= 8:
return 'summer'
elif month >= 9 and month <= 11:
return 'autumn'
else:
return 'winter'
min_year = global_temp['year'].min()
max_year = global_temp['year'].max()
years = range(min_year, max_year + 1)
global_temp['season'] = global_temp['month'].apply(get_season)
spring_temps = []
summer_temps = []
autumn_temps = []
winter_temps = []
for year in years:
curr_years_data = global_temp[global_temp['year'] == year]
spring_temps.append(curr_years_data[curr_years_data['season'] == 'spring']['LandAverageTemperature'].mean())
summer_temps.append(curr_years_data[curr_years_data['season'] == 'summer']['LandAverageTemperature'].mean())
autumn_temps.append(curr_years_data[curr_years_data['season'] == 'autumn']['LandAverageTemperature'].mean())
winter_temps.append(curr_years_data[curr_years_data['season'] == 'winter']['LandAverageTemperature'].mean())sns.set(style="whitegrid")
sns.set_color_codes("pastel")
f, ax = plt.subplots(figsize=(10, 6))
plt.plot(years, summer_temps, label='Summers average temperature', color='orange')
plt.plot(years, autumn_temps, label='Autumns average temperature', color='r')
plt.plot(years, spring_temps, label='Springs average temperature', color='g')
plt.plot(years, winter_temps, label='Winters average temperature', color='b')
plt.xlim(min_year, max_year)
ax.set_ylabel('Average temperature')
ax.set_xlabel('Year')
ax.set_title('Average temperature in each season')
legend = plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), frameon=True, borderpad=1, borderaxespad=1)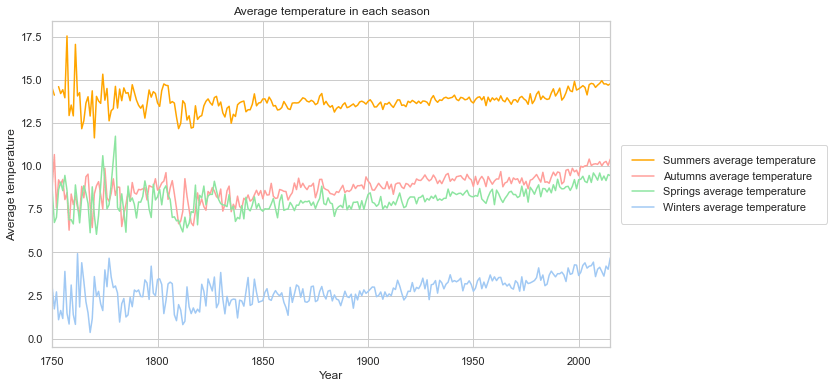
# Statewise scenario of average temperature.
country_state_temp = GlobalTempState.groupby(by = ['Country','State']).mean().reset_index().sort_values('AverageTemperature',ascending=False).reset_index()
country_state_temp
country_state_temp["world"] = "world"
fig = px.treemap(country_state_temp.head(200), path=['world', 'Country','State'], values='AverageTemperature',
color='State',color_continuous_scale='RdGr')
fig.show()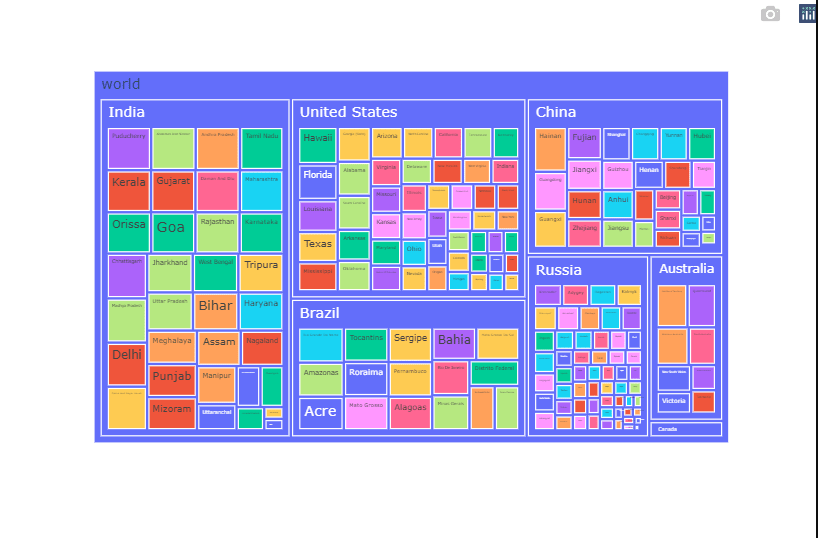
結論
このチュートリアルでは、PythonとGridDBを使用して世界の気候を分析しました。データをインポートする方法として、(1) GridDB と (2) Pandas の2つの方法を検討しました。GridDBは、オープンソースで拡張性が高いため、大規模なデータセットの場合、ノートブックにデータをインポートするための優れた代替手段を提供します。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb