
このプロジェクトでは、バックエンドに Node.js を利用し、ノンブロッキング、イベント駆動型のアーキテクチャを活用することで、AI Voice Note アプリケーションの高速性と拡張性を確保しています。 また、大量の構造化データを取り扱う際のパフォーマンスと拡張性の高さから、データストレージには GridDB を採用しました。これにより、音声メモから生成される複雑かつ膨大なデータを処理するのに最適な環境を実現しています。OpenAIの音声テキスト変換APIは、アプリケーションの中核を担い、音声メモの書き起こし、分析、カテゴリー分けを可能にする高度な自然言語処理機能を実現します。これらの技術を組み合わせることで、私たちは、口述を整理された検索しやすい情報に変換し、メモの作成を簡素化する、堅牢で効率的なツールの開発を目指しています。
ソースコード
ソースコードはこちらです。
$ git clone https://github.com/griddbnet/Blogs.git --branch ai-voice
仕組みは?
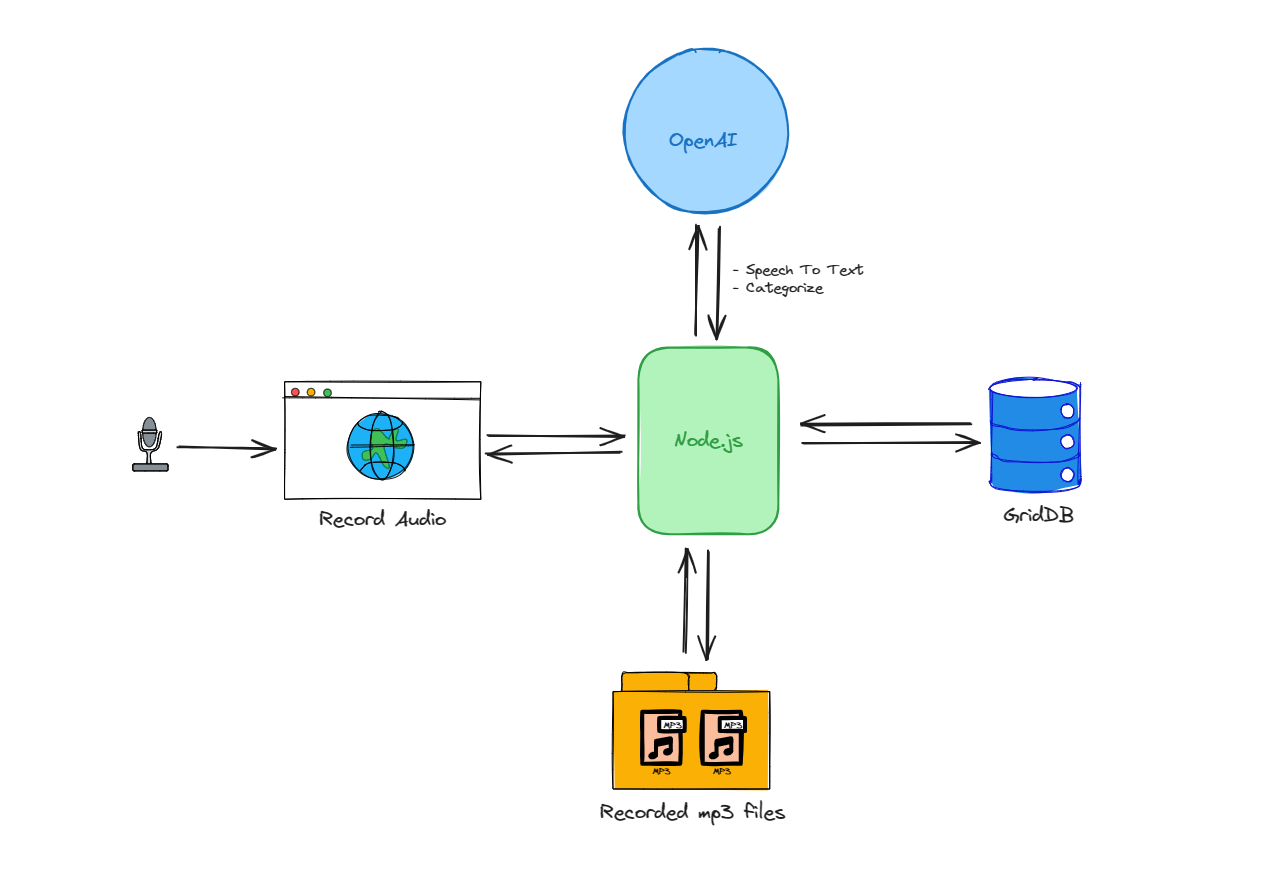
AI Voice Noteアプリケーションのアーキテクチャは、以下のいくつかのステップに簡略化できます。
-
ユーザーはウェブインターフェースを通じて音声を録音し、その音声データはNode.jsサーバーに送信されます。
-
Node.jsはこのデータを処理し、録音を永続ストレージにMP3ファイルとして保存します。
-
同時に、Node.jsはOpenAIのAPIとやりとりし、音声をテキストに書き起こし、内容を分類します。
-
書き起こしとカテゴリー分けが完了したデータは、スケーラブルな NoSQL データベースである GridDB に保存されます。
この処理フローは、Node.js とデータベースおよび AI サービスとの双方向のやり取りであり、これにより Node.js がアプリケーション内のデータ管理と処理の中心ハブとして機能します。
セットアップとインストール
この GitHub リポジトリからプロジェクトコードをクローンします。
git clone git@github.com:junwatu/ai-voice-note.gitディレクトリを app ディレクトリに変更します。
cd ai-voice-note
cd appnpm コマンドを使用して依存関係をインストールします。
npm install.envファイルを作成するか、.env.exampleからコピーし、以下の環境変数キーを設定します。
| Environment Variable Key | Description | Value |
|---|---|---|
OPENAI_API_KEY |
Key for authenticating API requests to OpenAI. | (Your actual OpenAI API key) |
VITE_API_URL |
The base URL of the Vite application’s backend API. | http://localhost:3000 |
デフォルトの VITE_API_URL を自由に変更してかまいません。ただし、変更した場合は、クライアントアプリケーションをこのコマンドでビルドすべきです。
npm run buildプロジェクトを実行するには、次のコマンドを使用します。
npm run startデフォルトでは、3000でポートが実行されています。AIボイスノートアプリを開くには、Google Chromeブラウザを使用することをお勧めします。
http://localhost:3000
このウェブアプリケーションはマイクへのアクセス権限を必要とします。デフォルトのマイクから音声を録音するには、アクセスを許可してください。
音声録音
React Audio Recorder は、React用の音声録音ヘルパーです。音声録音を支援するコンポーネントとフックを提供しており、Media RecorderなどのWeb APIを使用してクライアント側で実行できます。
import { AudioRecorder, useAudioRecorder } from 'react-audio-voice-recorder';
export default function Home() {
const apiUrl = import.meta.env.VITE_API_URL;
const recorderControls = useAudioRecorder({
noiseSuppression: true,
echoCancellation: true,
},
(err) => console.table(err) // onNotAllowedOrFound
);
const addAudioElement = (blob) => {
const url = URL.createObjectURL(blob);
const audio = document.createElement('audio');
audio.src = url;
audio.controls = true;
document.body.appendChild(audio);
const formData = new FormData();
formData.append("file", blob, "audio.webm");
fetch(`${apiUrl}/upload`, {
method: 'POST',
body: formData,
})
.then(response => response.json())
.then(data => {
console.log('Success:', data);
})
.catch((error) => {
console.error('Error:', error);
});
};
return (
<div className="hero min-h-screen bg-base-200">
<div className="hero-content text-center">
<div className="max-w-md">
<h1 className="text-5xl font-bold">Audio Note</h1>
<div className='flex justify-center items-center w-full my-32'>
<AudioRecorder
onRecordingComplete={(blob) => addAudioElement(blob)}
recorderControls={recorderControls}
showVisualizer={true}
/>
</div>
</div>
</div>
</div>
);
}<AudioRecorder> は、onRecordingComplete() メソッドをプロパティとして受け取り、録音を保存する際に呼び出す、すぐに使えるコンポーネントです。この React コンポーネントは、Web API を使用して音声を録音します。録音が完了すると、オーディオ blob が処理され、Node.js の /upload サーバーエンドポイントにアップロードされます。 
Node.js サーバーの作成
Node.js サーバーは、録音を永続ストレージに .webm ファイルとして保存し、音声ファイルを OpenAI に送信して音声認識を行います。
Node.js サーバーは、/upload エンドポイントで POST リクエストを処理する Express サーバールートを設定します。リクエストからの単一ファイルのアップロードを処理するために、multer ミドルウェアを使用します。
app.post('/upload', upload.single('file'), async (req, res) => {
if (req.file) {
const filePath = join(__dirname, 'uploads', req.file.filename);
try {
const transcription = await openai.audio.transcriptions.create
({
file: fs.createReadStream(filePath),
model: "whisper-1",
});
console.log(transcription.text);
// eslint-disable-next-line no-unused-vars
const speechData = {
filename: filePath,
text: transcription.text,
category: "voice note"
}
// Process data to GridDB database
// Save the transcription data to GridDB
const saveStatus = await saveData(speechData);
res.json({
message: 'Successfully uploaded file and saved data',
transcription: transcription.text,
saveStatus: saveStatus
});
} catch (error) {
console.error('Error during transcription:', error);
res.status(500).json({ message: 'Error during transcription', error: error.message });
}
} else {
res.status(400).json({ message: 'No file uploaded' });
}
});録音されたオーディオファイルがアップロードされると、通常は以下のような処理が行われます。
- サーバーは、カレントディレクトリと「uploads」サブディレクトリに基づいて、ファイルのパスを生成します。
- OpenAIの音声転写APIを使用して、「whisper-1」モデルを使用して音声ファイルをテキストに転写しようと試みます。
- 成功した場合、転写結果をコンソールに記録し、ファイルパス、転写テキスト、ハードコードされた「ボイスメモ」のカテゴリーを含むオブジェクトを作成します。
- このデータをGridDBデータベースに保存する必要があります。
- その後、サーバーはクライアントに成功を通知するJSON形式の応答を送信し、書き起こしテキストを含めます。
- 書き起こし中にエラーが発生した場合は、エラーを記録し、エラーメッセージとともに500ステータスを返します。
- 音声ファイルがアップロードされていない場合は、
400ステータスを返してリクエストが不正であることを示します。
ルート
server.jsファイルは、音声データの保存と取得のためのルートを提供します。以下は、Node.jsサーバーで定義されたルートの概要をまとめた表です。メソッド、パス、説明を含みます。
| Method | Path | Description |
|---|---|---|
| POST | /upload |
ファイルをアップロードし、テキスト化し、オプションでデータを保存します. |
| POST | /save-data |
データベースに提供されたデータ(ファイル名、テキスト、カテゴリー)を保存します。 |
| GET | /data/:id |
データベースから特定のIDのデータを取得します。 |
| GET | /all-data |
データベースからすべてのデータエントリを取得します。 |
| GET | /info |
GridDBコンテナに関する情報を提供します。 |
これらのエンドポイントは、Express、ファイル処理用のmulter、データストレージ用のGridDBを使用して、Node.jsアプリケーション内で音声書き起こしのアップロードと管理を行うための機能をまとめて有効にします。
音声からテキストへの変換OpenAI を使用
OpenAI には、音声をテキストに変換する機能、または 音声からテキストへの変換機能があります。 オーディオ API は、最先端のオープンソースの Large-v2 Whisper モデルに基づく 2 つの音声からテキストへの変換エンドポイント transcriptions と translations を提供しています。 これらは以下のような用途に使用できます。
- 音声を、音声が収録されている言語に書き換えます。
- 音声を英語に翻訳し、書き起こす。.
現在、ファイルのアップロードは25MBまでに制限されており、以下の入力ファイル形式がサポートされています。 mp3、mp4、mpeg、mpga、m4a、wav、およびwebm。
このプロジェクトでは、書き起こし機能を使用し、ファイル形式をwebmに限定します。 オーディオファイルを書き起こすコード:
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream(filePath),
model: "whisper-1",
});転写APIはストレージから音声ファイルを入力として受け取り、音声の転写結果を返します。デフォルトでは、生のテキストを含むJSON形式で応答します。
GridDBへのデータ保存
GridDBは、IoTやビッグデータに最適化されたオープンソースの時系列データベースです。しかし、一般的なウェブアプリケーションにも使用できます。OpenAIから書き出したデータを保存するために、データベースとしてGridDBを使用します。Node.jsサーバーでは、これらのデータがデータベースに保存されます。
const speechData = {
filename: filePath,
text: transcription.text,
category: "voice note"
}
const saveStatus = await saveData(speechData);データベースには3つのフィールドが保存されます。重要な注意点として、このプロジェクトではデータベースにオーディオファイルを保存せず、オーディオファイルの参照(ファイルパス)を保存します。
| Key | Description | Example Value |
|---|---|---|
filename |
アップロードされたオーディオファイルが保存されるパス。 | /path/to/uploads/audio-12345.webm |
text |
音声ファイルから取得した書き起こしテキスト。 | “Transcribed speech from the audio.” |
category |
音声メモに割り当てられたラベルまたはカテゴリー。 | “voice note” |
saveData()メソッドは、オーディオデータをGridDBデータベースに保存します。griddbservice.jsファイルにsaveData()のコードがあります。
export async function saveData({ filename, text, category }) {
const id = generateRandomID();
const sfilename = String(filename);
const speechText = String(text);
const scategory = String(category);
const packetInfo = [parseInt(id), sfilename, speechText, scategory];
const saveStatus = await GridDB.insert(packetInfo, collectionDb);
return saveStatus;
}initContainer() 関数は、GridDBコンテナを音声または音声データで初期化します。この関数は、libs/griddb.cjsファイルで確認できます。
function initContainer() {
const conInfo = new griddb.ContainerInfo({
name: containerName,
columnInfoList: [
['id', griddb.Type.INTEGER],
['filename', griddb.Type.STRING],
['speechText', griddb.Type.STRING],
['category', griddb.Type.STRING]
],
type: griddb.ContainerType.COLLECTION,
rowKey: true,
});
return conInfo;
}さらなる機能強化
このプロジェクトは現在プロトタイプであり、機能性とユーザー体験を向上させるための強化の余地がいくつかあります。以下に、検討可能な強化策をいくつかご紹介します。
-
デバイスの選択機能:
- 複数のデバイスをサポート:利用可能なマイクや入力デバイスからユーザーが選択できる機能を実装します。これにより、ユーザーは好みのオーディオソースを選択できるようになります。特に、複数のオーディオ入力オプションがある環境では便利です。
-
オーディオ環境の最適化:
- ノイズ抑制:録音中にバックグラウンドノイズを動的に低減または除去できる高度なノイズ抑制アルゴリズムを統合します。この機能強化により、特にノイズの多い理想的な環境ではない場合において、オーディオの明瞭度と品質が大幅に改善されます。
-
ユーザーインターフェースの改善:
- デバイス選択UI:利用可能なすべてのマイクを一覧表示し、ユーザーが好みの入力デバイスを簡単に選択できる、ユーザーフレンドリーなインターフェースを開発する。このインターフェースには、デバイスの仕様、現在のステータス、オーディオ品質をチェックするテスト機能を含めることができる。
- サウンドレベルの視覚フィードバック:サウンドレベルメーターや波形表示などの視覚フィードバックメカニズムを追加し、ユーザーがオーディオ入力レベルをリアルタイムで理解できるようにします。この機能により、ユーザーは録音を開始する前にマイクの配置や設定を調整しやすくなります。 これらの機能強化は、より幅広い録音状況やユーザーの好みに応えることを目的としており、ウェブアプリケーションをより堅牢で多機能、かつユーザーフレンドリーなものにすることを目指しています。これらの機能を統合することで、アプリケーションの利便性と魅力が大幅に向上します。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb