
はじめに
このブログでは、GridDBに保存されているデータを使って、銀行ローンの分類モデルを一から構築し、以下の内容を説明します。
1.GridDBへのデータ保存
2.GridDBからのデータ抽出
3.Pandasを用いたロジスティック回帰モデルの構築
4.ヒートマップと相関行列を用いたモデルの評価
まず、前提条件をインストールして環境を整えるところから始めます。このチュートリアルでは、モデル構築に使用する主要言語がPythonであることから、GridDBのPythonコネクタを使用します。GridDBは接続するライブラリやAPIが充実しており、SQLとNoSQLの両方のインターフェースを簡単に扱うことができます。
環境と前提条件
以下のチュートリアルは、Ubuntu OS (v. 18.04)、gcc version 7.5.0、GridDB (v. 4.5.2)、Jupyter Notebooks (Anaconda Navigator)を使っています。コードはPython 3で書かれているので、同プログラミング言語で動作するあらゆるデバイス・コードエディタで実行することができます。なお、Pythonや機械学習を初めて使う方は、以下のリンクを参考にインストールしてください。
GridDBをインストールする際は、Githubで公開されているガイドを参考にしてください。GridDBのpythonコネクタを利用するための前提条件は次の3つです。1. GridDB C-client 2. SWIG 3. Pcre
Pythonクライアントのインストールについてはこちらのチュートリアルを参照してください。
データセット
このチュートリアルでは、Kaggleで公開されている銀行ローン分類データセットを使用します。このデータセットには、合計5000のインスタンスと14の属性があります。属性とは、収入、年齢、経験などの様々な基準で評価されたユーザ・データを意味します。この場合の応答変数は、‘Personal Loan’という変数で、性質は二値です。0のラベルはローンアプリケーションの却下を意味し、1は受け入れを意味します。
この目的は、残りの説明変数に基づいて、インスタンスを0または1(却下または受け入れ)のいずれかのカテゴリに分類することです。これは、ロジスティック回帰モデルを使用して達成できる2クラスの分類タスクです。では、早速やってみましょう。
必要なパスを設定する
GridDBをインストールし、上記の前提条件を満たした上で、Ubuntu TerminalなどのOSで以下のコードを実行します。
export CPATH=$CPATH:<Python header file directory path>
export PYTHONPATH=$PYTHONPATH:<installed directory path>
export LIBRARY_PATH=$LIBRARY_PATH:C client library file directory path
必要なライブラリをインポートする
最初のステップは、必要なライブラリをインポートすることです。このチュートリアルで使用するライブラリは以下の通りです。
なお,これらのライブラリを初めて使用する場合には,インストールエラーが発生する可能性があります。その場合は、pip install package-nameまたはconda install package-nameを試してください。
これらのライブラリのインストールが完了したら、今度は griddb_python ライブラリをインポートしてみましょう。以下のコマンドをpythonコンソール上で個別に実行するか、都合に合わせて.pyファイルを作成してください。インストールが成功すれば、importコマンドはエラーを返さないはずです。
import griddb_python
参考ビルドがうまくいかない場合は、パスを設定した後に make コマンドを実行してください。また、サンプルプログラムを実行して、詳細を把握することもできます。
Adding data to GridDB
import griddb_python as griddb
import pandas as pd
factory = griddb.StoreFactory.get_instance()
# Container Initialization
try:
gridstore = factory.get_store(host=your_host, port=ypur_port,
cluster_name=your_cluster_name, username=your_username,
password=your_password)
conInfo = griddb.ContainerInfo("Dataset_Name",
[["attribute1", griddb.Type.INTEGER],["attribute2",griddb.Type.FLOAT],
....],
griddb.ContainerType.COLLECTION, True)
cont = gridstore.put_container(conInfo)
cont.create_index("id", griddb.IndexType.DEFAULT)
dataset = pd.read_csv("BankLoanClassification.csv")
#Adding data to container
for i in range(len(dataset)):
ret = cont.put(data.iloc[i, :])
print("Data has been added")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))注意点 1. factory.get_store()関数のパラメータを、お使いのクラスタの認証情報に置き換えてください。または、新規クラスタの作成方法を参照してください。 2. 関数 griddb.ContainerInfo() に、関連する属性名、データセット名、データタイプを設定します。
SQLを使ってGridDBからデータを取得する
griddb_pythonライブラリを使うと、PythonでSQL経由でデータにアクセスできるようになります。これにより、両方の言語を上手に使うことができます。Pythonファイルの中で次のようにクエリを渡すだけで、データベースに保存されているデータにアクセスできるようになります。
statement = ('SELECT * FROM Dataset_Name')
sql_query = pd.read_sql_query(statement, cont)
なお、pd.read_sql_query()関数は、SQLクエリからのデータをpandasのデータフレームに変換します。これにより,データフレームを直接操作して機械学習モデルを構築することができます.また、次のようにcsvファイルを直接インポートすることもできます。
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix,mean_squared_error,accuracy_score
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
APP_PATH = os.getcwd()
APP_PATH
'C:\\Users\\SHRIPRIYA\\Desktop\\GridDB'
データセットを読み込む
Note that if you have loaded your dataset using GridDB’s python_client, you can skip this step as it is redundant. GridDBのpython_clientを使ってデータセットを読み込んだ場合は、このステップは冗長なので省略することもできます。
APP_PATH 変数には,以下のコマンドでファイル名に付加される現在のディレクトリが含まれています。混乱を避けるために,pythonファイルとcsvファイルが同じディレクトリにあることを確認してください。そうでない場合は、FileNotFoundErrorを避けるために、データセットファイルのフルパスを指定してください。
dataset = pd.read_csv(os.path.join(APP_PATH, 'UniversalBank.csv'))データセットを使ってみる
モデルを構築する前に、データセットの概要を把握するため、いくつかの簡単なコマンドを実行してみましょう。データの前処理と分析をしておくことで、より強固で効果的なモデルを作ることができます。headコマンドは、データセットの最初の5行を返します。もっと多くの行を表示したい場合には、headコマンドの引数に数字を入力してください。例えば,dataset.head(20) とすると,最初の20行が表示され,dataset.head(-5) とすると,最後の5行が表示されます。
dataset.head()
| ID | Age | Experience | Income | ZIP Code | Family | CCAvg | Education | Mortgage | Personal Loan | Securities Account | CD Account | Online | CreditCard | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 25 | 1 | 49 | 91107 | 4 | 1.6 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 2 | 45 | 19 | 34 | 90089 | 3 | 1.5 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 3 | 39 | 15 | 11 | 94720 | 1 | 1.0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 4 | 35 | 9 | 100 | 94112 | 1 | 2.7 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 5 | 35 | 8 | 45 | 91330 | 4 | 1.0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 |
後にテストとトレーニングに分けられるデータセットの全長を確認してみましょう。
len(dataset)5000
dataset.dtypesコマンドは、各属性がどのようなデータ型を持っているかを示します。このステップは、数値変数のスケーリングや、テキストデータの場合はダミー変数の作成やエンコーディングスキームを使用する必要があるため、不可欠です。したがって、モデル構築の前にこれらのステップを計画できるように、データを見ておくとよいでしょう。
dataset.dtypesID int64
Age int64
Experience int64
Income int64
ZIP Code int64
Family int64
CCAvg float64
Education int64
Mortgage int64
Personal Loan int64
Securities Account int64
CD Account int64
Online int64
CreditCard int64
dtype: object
それでは、データセットに欠損値がないかどうかを調べてみましょう。isnull()コマンドは,データセットの中に少なくとも一つのNULL値があれば,Trueを返します.NULL値は、データセットを学習用に回す前に、削除するか、あらかじめ決められた値で置き換えることになります。今回のケースではNULL値がないので、そのまま先に進みます。データセットに含まれるNULL値の総数を得るには、dataset[key].isnull().sum()と入力します。[key]は対象となる属性名です。dataset.dropna()コマンドは、少なくとも一つのNULL値を含む行を削除します。
dataset.isnull().values.any()False
IDとZIP Codeは、ローン申請の結果を予測する上でほとんど役割を果たさないため、今後はこれらの列を削除します。
dataset.drop(["ID","ZIP Code"],axis=1,inplace=True)前のステップを検証するためにコラムを表示する
dataset.keys()Index(['Age', 'Experience', 'Income', 'Family', 'CCAvg', 'Education',
'Mortgage', 'Personal Loan', 'Securities Account', 'CD Account',
'Online', 'CreditCard'],
dtype='object')
モデルの作成に移る前に、序列データをダミーデータに変換する必要があります。これにより、モデルが簡単にこれらの属性を解釈することができるようになります。数値データについては、モデルがそのまま利用するため、ここでは省略します。
cat_cols = ["Family","Education","Personal Loan","Securities Account","CD Account","Online","CreditCard"]
dataset = pd.get_dummies(dataset,columns=cat_cols,drop_first=True,)dataset.keys()Index(['Age', 'Experience', 'Income', 'CCAvg', 'Mortgage', 'Family_2',
'Family_3', 'Family_4', 'Education_2', 'Education_3', 'Personal Loan_1',
'Securities Account_1', 'CD Account_1', 'Online_1', 'CreditCard_1'],
dtype='object')
Family属性に3つのダミーカラムが作成されているのが分かります。同様に、Education, Personal Loanなどにもダミーのカラムが作成されています。列の数は、特定の属性が持つラベルに依存します。簡単に言うと、0、1、2の3段階の変数があれば、作成されるダミーカラムの数は3になります。
これで、データをXとY(独立変数と応答変数)に分割する準備が整いました。y にはラベルが入ります。ここでは、Personal_Loan_1 という属性が入ります。
X = dataset.copy().drop("Personal Loan_1",axis=1)
y = dataset["Personal Loan_1"]各カテゴリーのラベル数を見てみましょう。
dataset["Personal Loan_1"].value_counts()0 4520
1 480
Name: Personal Loan_1, dtype: int64
sns.countplot(x ='Personal Loan_1', data=dataset, palette='hls')
plt.show()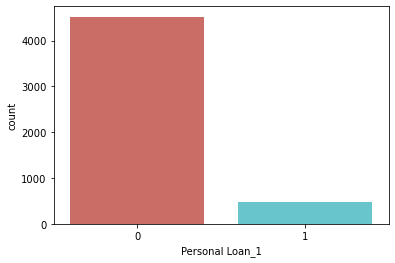
データセットをテストとトレーニングに分割する
データセットをトレーニングとテストに分けてみましょう。ここでは、80対20の比率を使用しています。一般的には66対33の割合でもよいでしょう。今回は1000個のインスタンスを使います。
trainx, testx, trainy, testy = train_test_split(X, y, test_size=0.20)print(trainx.shape)
print(testx.shape)
print(trainy.shape)
print(testy.shape)(4000, 14)
(1000, 14)
(4000,)
(1000,)
機能を拡張する
データの正規化や標準化は、数値データを扱う際によく行われます。これは、各属性が同じ範囲にあることを保証するために重要です。データの標準化とは、全体の平均値が0、標準偏差が1になるようにデータセットを再スケーリングすることです。ここでは、scikit-learn StandardScaler()を用います。
scaler = StandardScaler()
scaler.fit(trainx.iloc[:,:5])
trainx.iloc[:,:5] = scaler.transform(trainx.iloc[:,:5])
testx.iloc[:,:5] = scaler.transform(testx.iloc[:,:5])C:\Users\SHRIPRIYA\anaconda3\lib\site-packages\pandas\core\indexing.py:966: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
C:\Users\SHRIPRIYA\anaconda3\lib\site-packages\pandas\core\indexing.py:966: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
モデルを構築する
データセットの前処理、分割、標準化が終わったら、次は分類モデルに渡します。学習セットと出力ラベルは,モデル構築のために、model.fit関数に渡されます。
X = trainx
y = trainy
model = LogisticRegression()
model.fit(X , y)
predicted_classes = model.predict(X)
accuracy = accuracy_score(y,predicted_classes)
parameters = model.coef_Model Evaluation
精度と係数
ここでのaccuracyは学習精度、parametersは構築したモデルの係数を表します。
print(accuracy)
print(parameters)
print(model)0.9615
[[-0.11052202 0.21417872 2.70013875 0.30873518 0.04262124 -0.19654911
1.68376406 1.39637464 3.44973088 3.7034019 -0.56957366 3.35123915
-0.64710272 -0.72719671]]
LogisticRegression()
ここでは、テストデータセットを用いて、1000件の未処理データに対するモデルの精度を評価します。
model.fit(testx , testy)
predicted_classes_test = model.predict(testx)
accuracy = accuracy_score(testy,predicted_classes_test)
print(accuracy)0.962
混乱マトリックスとヒートマップ
コンフュージョン・マトリクスでは、4つのカテゴリーがあります。1. 真の否定: 正しく予測されたゼロ(実際と予測-0) 2. False Negative: ゼロとして誤って予測されたもの (Actual – 1, Predicted – 0)3. False Positive: ゼロを誤ってゼロと予測した場合(実際 – 0, 予測 – 1) 4. 真正:正しく予測されたもの(実際と予測-1)
cm = confusion_matrix(testy,predicted_classes_test)
fig, ax = plt.subplots(figsize=(6, 6))
ax.imshow(cm)
ax.grid(False)
ax.xaxis.set(ticks=(0, 1), ticklabels=('Predicted 0s', 'Predicted 1s'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('Actual 0s', 'Actual 1s'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j, i, cm[i, j], ha='center', va='center', color='red')
plt.show()
まとめと今後の展望
今回の銀行ローン分類モデルは、5000件のデータセットで95.3%の精度を達成し、まずまずの結果となりました。また、混同行列によって、偽陰性と偽陽性の詳細が明らかになりました。精度を上げるための他の選択肢としては、Naive Bayes, KNN Classifier, Decision Trees, SVM, etc. があります。詳しくはデータセットのホームページこちらで調べてみてください。
このチュートリアルでは、GridDBにデータを挿入し、python-clientを使ってアクセスする方法を紹介しました。また、簡単なSQLクエリを使って、GridDBからpandasのデータフレームにデータを取得しました。このように、GridDBには様々な機能があり、時系列データの保存に適しています。GridDBでできることはまだまだたくさんあります。ぜひオンラインコミュニティをチェックしてみてください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb