
1. CAP 定理とは何か?
ある特定のデータベースの特性を説明する際に、必ず引き合いに出される定理にCAP定理があります。GridDB.net 内の資料でも、CAP定理を引用している資料がいくつかあると思います。今回は、CAP定理について簡単におさらいしてみましょう。
CAP定理はカルフォルニア大学バークレー校のEric A. Brewer 博士によって2000年に提唱された定理です。CAP はそれぞれ、
一貫性(Consistency):
どんな読み出し要求に関しても、単一の最新データを返すか、さもなくばエラーを返す。
可用性(Availability):
システムを構成する要素に障害が発生していたとしても、常にサービスが継続される。
分断耐性(Partition-tolerance):
システムを構成するノード間の通信が一時的に分断されても、機能が継続される。
の3つの頭文字を取ったもので、CAP定理とは、分散コンピュータシステムにおいて、これら3つの性質を全て同時に満たすものは存在しない、というものです。GridDB を含め、スケールアウトを売りとする多くのNoSQLデータベースは、複数のノードによる分散コンピュータシステムであり、分断耐性(Partition-tolerance)は、必須です。つまり、分散コンピュータシステム上に構築されるデータベースは、以下のどちらかしか実現できません。
1. 一貫性と分断耐性(CP) を保証し、可用性(A) を諦める
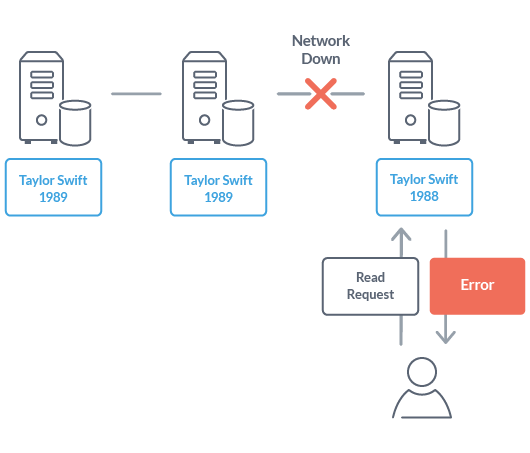
データベースを構築する分散コンピュータシステム上のネットワークがなんらかの理由で遮断されたとします。一貫性(C) を保障するデータベースの場合、この状態でユーザーからの読み出し要求がきてもエラーを返すことになります。ネットワークが遮断されている間、各ノードが分散して持ち合っているデータが一致していない可能性があるためです。一貫性を保障するために、ネットワークが遮断されている間はデータベースが利用できない、つまり、可用性がないわけです。
このようなCP を保証するNoSQL データベースの代表的なものとしては、MongoDB, HBase, Redis などがあります。
2. 可用性と分断耐性(AP) を保証し、一貫性(C) を諦める
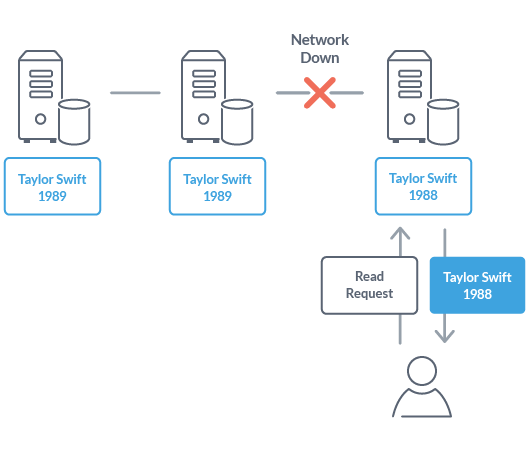
同じようにネットワークが遮断された状態を考えます。可用性(A) を保障するデータベースでは、この状況でユーザーからの読み出し要求が来た場合でも、問い合わせ先のノードが持つ情報を返します。この情報は、他のノードが持つ最新の情報とは異なる可能性がありますが、可用性を保つために最善の回答を返すわけです。
このような、AP を保証するNoSQL データベースの代表的なものにはCassandra やCouchDB などがあります。
2. CAP定理の実際
上記のとおり、CAP定理は、C, A, P 3つの性質の「全て」を「同時」に満たすものは存在しない、というものです。CP型をとるか、AP型を取るかは対象となるアプリケーションによって判断されるべきものですが、実際には一貫性(C)や可用性(A)は、「有るか、無しか」という類のものではなく、 その厳密性にある程度の幅があります。現在主流の各種データベースでは、その厳密性を緩めてあげることで、CAPのトレードオフが運用上問題にならないように工夫されています。
例えば、APが保障されたデータベースにおいて、ネットワークが遮断されるなどして、一時的に各ノードがもつデータが一致しない時間があったとしても、いずれは(Eventually) 全体のデータが一致するように設計することはできます。これを結果整合性(Eventual Consistency)と呼び、いくつかのNoSQLデータベースで採用されています。身近な例としては、インターネット上のDNS (Domain Name System) があります。Webサーバーの変更などで、自分の管理するWebサイトのもつIPアドレスなどのDNSレコードを書き換えた場合、世界中にあるDNSサーバーにその変更が反映されるにはある程度の時間かかりますが、更新の間もDNSが利用できなくなるということはありません。結果整合性のように、一貫性の条件を少し緩めたものを「弱い一貫性」と呼ぶことがあります。
一方、厳密な一貫性(「強い一貫性」と呼ばれます) を持つCP型のデータベースにおいても、可用性を高める手段は多数あります。例えば、クラスタを構成するノード間の通信経路を2重化しておくことは、それほど手間やコストをかけずに可用性を高めることができる、非常に有効な手法の一つです。
3. GridDB はCP型です!
さて、GridDB においてはCAP定理のトレードオフはどのように取り扱われているでしょうか? 章のタイトルに先に書いてしまっていますが、GridDB は、強い一貫性を保証する設計、つまり、CP型のデータベースです。
我々はIoT アプリケーションを取り扱うデータベースにとって、一貫性が最も重要な性能の一つであると考えています。
GridDB が採用されている3つの事例を参照下さい。このようなユースケースにおいては、いくら完全な可用性を持っていたとしても、タイミングによって同一であるべきセンサー値が異なるようでは問題があります。例えば、結果整合性を採用しているAP型データベースの場合、そのようなセンサー値の不具合はアプリケーションレベルで考慮しなければなりません。データが一致するプロセスまで理解してアプリケーションの異常系を設計する必要があり、開発者への負担は非常に大きくなってしまいます。
また、GridDBはCP型ではありますが、可用性を担保する様々な機能を持っています。可用性向上のためにGridDB が持つ特徴的な機能をいくつか紹介しましょう。
1. マスターノードの自動選出
GridDB のクラスタシステムは、マスターノード一台と、スレーブノード一台のいわゆるマスター・スレーブ型の分散データベースシステムです。
通常マスタースレーブ型は、マスターノードが単一故障点(Single Point of Failure, SPOF) となる弱点があるのですが、GridDB の場合、マスターノードに障害が発生しても、正常に動作しているスレーブノードから自律的、動的にひとつのノードが選択され、新しいマスターノードに昇格されます。さらに、新マスターノードは、データの配置状態や、更新状態など、一貫性を保障する上で必須となるメタデータも自動復元します。つまり、障害からのリカバリー中であっても一貫性が毀損されることは無く、常にCP型のデータベースとしてサービスを継続できます。
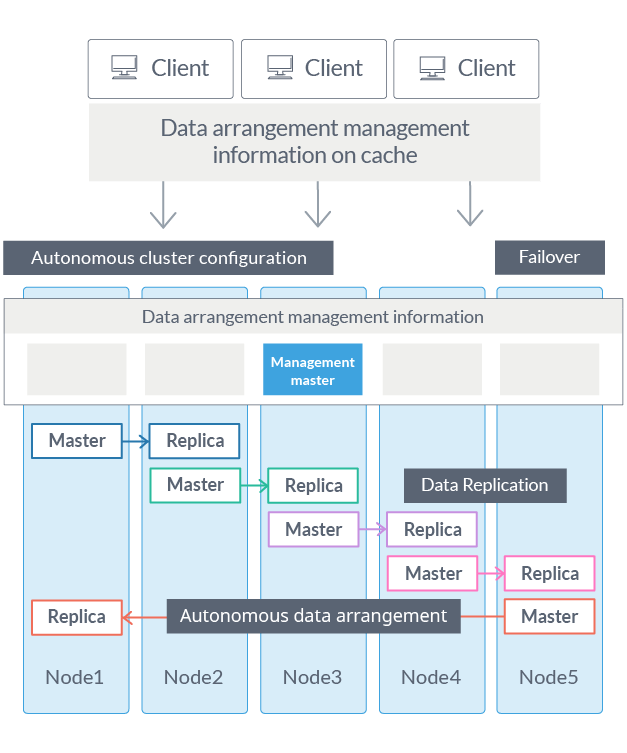
2. 自律的データ配置(Autonomous Data Distribution Algorithm, ADDA)
クラスタ内でデータの複製(レプリカ)を作成しており、クラスタを構成するいずれかのノードに障害が発生した場合でもレプリカを使用することで処理を継続できます。
通常の分散処理データベースでも同様の機能を持つものはありますが、システムを構成するあるノードが何らかの障害で使えなくなってしまった場合、残りのノードが持つデータのバランスが一時的に崩れてパフォーマンスが落ちたり、レプリカ数の不足で可用性のレベルが落ちる可能性があります。
GridDB では、各ノードがもつデータの配置状況を監視しており、配置に偏りが見られた場合に、自動的にシステムにとって最適な状態になるようデータを再分配する機能があります。これにより、障害によるパフォーマンス悪化の時間を最小限にするとともに、高い可用性レベルを維持します。
3. クライアント・フェールオーバー
障害発生時に待機系ノードに自動的に切り替わる、いわゆるフェールオーバー機能は多くのデータベースで採用されています。
GridDB は、そのようなサーバー側でのフェイルオーバー機能はもちろんのこと、さらにクライアントでもデータ配置管理情報のキャッシュを保有しています。これにより、クライアントがノードの障害を検知すると、自動的にフェイルオーバーし、レプリカを用いたデータアクセスを継続できます。
いかがだったでしょうか?CAP定理は提唱者の記事も含めて、様々な場所で詳しく説明されていますが、このブログでは基本的な部分のみを簡単にまとめて紹介しました。また、3章のGridDB 可用性を高める各種の機能については、いずれこのブログでも掘り下げて説明したいと思います。
現在お使いのデータベースの代わりに、一貫性を重視したGridDB を使ってみてください。Community Edition なら、AGPLライセンスでいつでも無料で利用可能です。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb
