
データを収集して分析することは、データ駆動型の組織やソフトウェアアプリケーションにとって不可欠な要素です。データを収集する際に最も面倒な作業の一つが、データベースへの入力です。この記事では、生データを変換し、構造化された方法でデータベースに入力するための簡単な方法を紹介します。
前提条件
このチュートリアルでは、プログラミング言語としてPythonを使用し、バックエンド・データベースとしてGridDBを使用してスクリプトを作成します。
このチュートリアルを続ける前に、GridDB データベースが稼働している必要があります。GridDBをソースコードまたはパッケージからインストールする方法が包括的なドキュメントとして提供されています。
また、PythonとGridDBの接続には、GridDB Python Connectorを使用しています。最終的には、Kaggleで取得できるデータセットを作成します。このチュートリアルでは、CSV形式のF1 World Championship (1950 – 2020)データセットを使用します。
このデータセットには複数のCSVファイルが含まれており、この記事の例ではそこにあるcircuit.csvとraces.csvファイルを使用します。次の表は、各テーブルの基本構造と、データを変換するために予定されている変更点を表示しています。データタイプとは、GridDBの対象データタイプを指します。
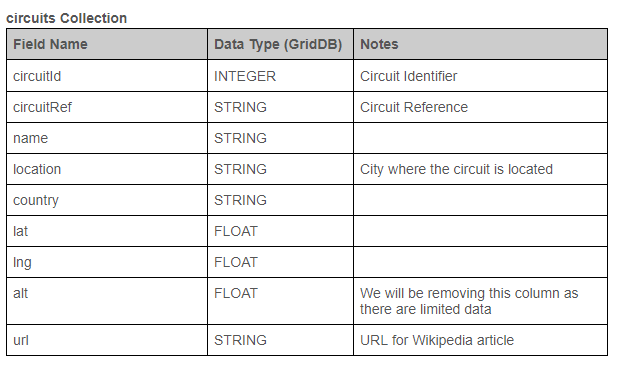
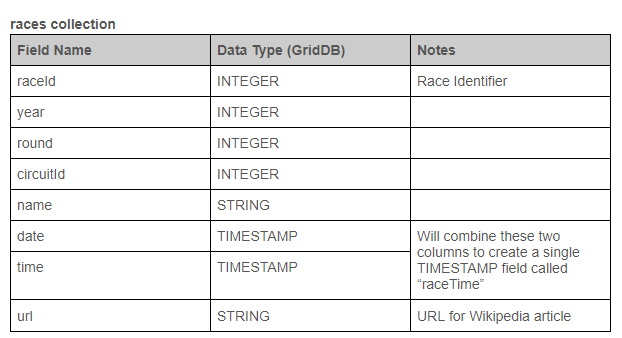
データの抽出
CSVファイルからデータを抽出するには、CSVファイルを読み込んで、データ構造を特定し、最後に各行のデータを繰り返し処理するのが主な手順です。これは、CSVファイルからデータを抽出するための普遍的なプロセスです。
これを実現する一つの方法は、CSVファイルを開き、”csv.reader”機能を使ってCSVとして読み込み、列名とデータを別々に識別することです。
import csv
with open("./dataset/circuits.csv") as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
line_count = 0
for row in csv_reader:
if line_count == 0:
print(f'Column Names : {", ".join(row)}')
line_count += 1
else:
print(f'{", ".join(row)}')
上記のコードブロックは、circuit.csvファイルを読み込んで、各行から抽出する列名とデータを特定します。しかし、この方法では、抽出したデータでできることが限られてしまいます。複雑なデータ分析を行うには、操作可能な構造化されたデータセットが必要です。
PythonにはPandasという強力でユニークなライブラリがあり、データ構造の作成や複雑なデータの分析に特化して設計されています。そのため、データを移行する際には、抽出したデータからPandasのデータフレームを作成することが最適な選択肢となります。これにより、要求に応じてデータを簡単に変換することができるようになります。
Pandasライブラリには、CSVファイルからデータを抽出するために必要な関数がすべて含まれています。Pandasのread_csv関数は、指定されたCSVファイルを読み込んで、自動的にカラム名とデータを識別します。このPandasの機能を説明すると以下のようになります。
import pandas as pd
# circuits.csvからデータフレームを作成
circuits_data = pd.read_csv("./dataset/circuits.csv")
# races.csvからデータフレームを作成
races_data = pd.read_csv("./dataset/races.csv")
# circuits.csvの全ての行を出力する
for row in circuits_data.itertuples(index=False):
print(f"{row}")
# races.csv内の全ての行を出力する
for row in races_data.itertuples(index=False):
print(f"{row}")
上記のコードでは、CSVファイルごとに1つとして2つのデータフレームを作成し、データフレームを反復してCSVファイルから抽出された構造化データセットを識別します。データセット(circuitIdとraceId)の中には既にインデックスが使用されているため、インデックスオプションはFalseに設定されています。データフレームは、データを管理・変換するためのゲートウェイです。
次のステップは、抽出されたデータをクリーンにして変換することです。これは、Pandasデータフレームが提供する関数を使って簡単に行うことができます。それでは、データベースに構造化されたデータセットを提供するために、CSVファイルをクリーンアップして変換してみましょう。
import pandas as pd
# null値を定義しながらデータフレームを作成する
circuits_data = pd.read_csv("./dataset/circuits.csv", na_values=['\N'])
races_data = pd.read_csv("./dataset/races.csv", na_values=['\N'])
# データフレームの構造を表示する
circuits_data.info()
races_data.info()
# altカラムの削除
circuits_data.drop(['alt'], inplace=True, axis=1)
# raceTimeカラムの組み合わせを作成する
races_data['time'].replace({pd.NaT: "00:00:00"}, inplace=True)
races_data['raceTime'] = races_data['date'] + " " + races_data['time']
races_data['raceTime'] = pd.to_datetime(races_data['raceTime'], infer_datetime_format=True)
# dataとtimeカラムを削除する
races_data.drop(['date', 'time'], inplace=True, axis=1)
# 修正したデータフレームの構造を表示する
circuits_data.info()
races_data.info()
上記のコードブロックでは、na_valuesオプションを使ってCSVファイルの読み込み方法を変更しています。CSVファイルの中で(N)と定義されているnull値を特定し、実際のpandasのnull値(NaT)に変換することができます。
次に、info()メソッドを使用して、データフレームの構造を識別することができます。
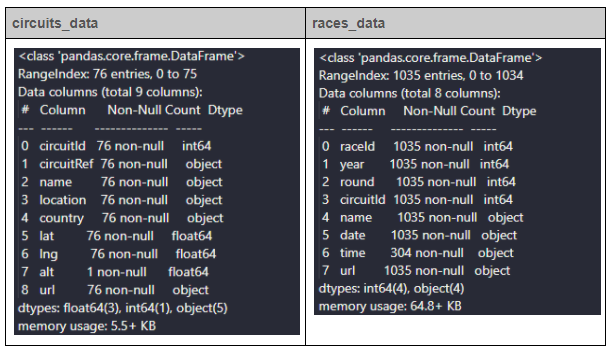
circuits_dataにはalt列のレコードが1つしかない(Non-Null Count)ので、データセットから削除することができます。次に、races_dataでは、まず、time列のnull値を置き換えます。次に、data列とtime列を組み合わせて、raceTimeという新しい列を作り、datetimeフィールドに変換します。最後に、データフレームから冗長なデータと時間列を削除します。
修正したデータフレームを見るには、info()メソッドを再度使用します。
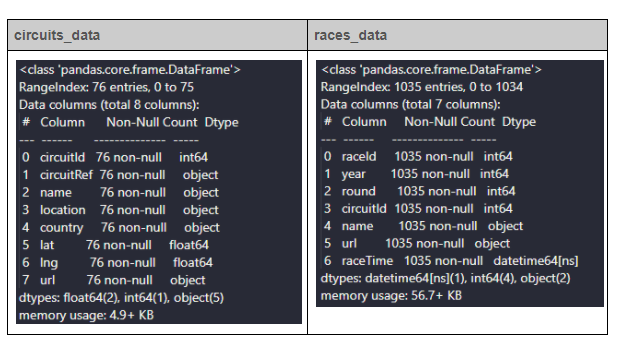
次のステップでは、データベースにデータを挿入します。
データベースを操作する
通常、データベースを操作するには、GridDB 内にコンテナを作成し、put メソッドや multi_put メソッドを使用してデータを挿入することになります。しかし、GridDB の python クライアントは、データフレームを使ったデータの挿入もサポートしています。
コンテナを使う最初のステップは、データを格納するコンテナを作成することです。今回の例では、circuits と races という 2 つの GridDB コンテナを作成します。コンテナを作成する際に最も重要なことは、正しいデータ型を定義することです。誤ったデータ型を定義すると、データベースの操作を行う際にエラーが発生する可能性があります。
circuits_container = "circuits"
races_container = "races"
# Create Collection circuits
circuits_containerInfo = griddb.ContainerInfo(circuits_container,
[["circuitId", griddb.Type.INTEGER],
["circuitRef", griddb.Type.STRING],
["name", griddb.Type.STRING],
["location", griddb.Type.STRING],
["country", griddb.Type.STRING],
["lat", griddb.Type.FLOAT],
["lng", griddb.Type.FLOAT],
["url", griddb.Type.STRING]],
griddb.ContainerType.COLLECTION, True)
circuits_columns = gridstore.put_container(circuits_containerInfo)
# Create Collection races
races_containerInfo = griddb.ContainerInfo(races_container,
[["raceID", griddb.Type.INTEGER],
["year", griddb.Type.INTEGER],
["round", griddb.Type.INTEGER],
["circuitId", griddb.Type.INTEGER],
["name", griddb.Type.STRING],
["url", griddb.Type.STRING],
["raceTime", griddb.Type.TIMESTAMP]],
griddb.ContainerType.COLLECTION, True)
races_columns = gridstore.put_container(races_containerInfo)
次のステップは、Databaseに行を挿入することです。put_rows関数を使用すると、入力としてデータフレームを定義することができます。これにより、データフレーム内の各行がGridDBコレクションに挿入されます。
# Put rows
# Define the data frames
circuits_columns.put_rows(circuits_data)
races_columns.put_rows(races_data)
以上で、CSVファイル経由で取得したデータを変換・クリーニングし、必要なデータを構造化されたフォーマットでGridDBコレクションに追加することに成功しました。
データベースからのデータ取得
本節では、データベースからデータを取得する方法について説明します。GridDB にはクエリ機能があり、ユーザはコンテナにクエリを発行してデータベースからデータを取得することができます。以下のコードブロックを見てください。ここでは、get_container 関数を使用してコンテナを取得し、コレクションを照会して必要なデータを抽出しています。
# Define the container names
circuits_container = "circuits"
races_container = "races"
# Get the containers
circuits_data = gridstore.get_container(circuits_container)
races_data = gridstore.get_container(races_container)
# Fetch all rows - circuits_container
query = circuits_data.query("select *")
rs = query.fetch(False)
print(f"{circuits_container} Data")
# Iterate and create a list
retrieved_data= []
while rs.has_next():
data = rs.next()
retrieved_data.append(data)
print(retrieved_data)
# Convert the list to a pandas data frame
circuits_dataframe = pd.DataFrame(retrieved_data, columns=['circuitId', 'circuitRef', 'name', 'location', 'country', 'lat', 'lng', 'url'])
# Get the data frame details
print(circuits_dataframe)
circuits_dataframe.info()
# Fetch all rows - races_container
query = races_data.query("select * where raceTime >= TIMESTAMP('2010-12-31T00:00:00.000Z')")
rs = query.fetch()
print(f"{races_container} Data")
# Iterate and create a list
retrieved_data= []
while rs.has_next():
data = rs.next()
retrieved_data.append(data)
print(retrieved_data)
# Convert the list to a pandas data frame
races_dataframe = pd.DataFrame(retrieved_data, columns=['raceID', 'year', 'round', 'circuitId', 'name', 'url', 'raceTime'])
# Get the data frame details
print(races_dataframe)
races_dataframe.info()
上記のコードでは、GridDBのクエリ言語であるTQLを使用して、”circuits”コレクションのすべてのレコードを照会し、2010-12-31以降に開催されたレースを選択しています。
以下のように、circuitsコンテナに対して基本的なTQLのselect文を使って、すべてのレコードを選択することができます。
circuits_data.query("select *")
レースコンテナでは、2010年12月31日以降に開催されたレースのみを抽出するために、データをフィルタリングする必要があります。
races_data.query("select * where raceTime >= TIMESTAMP('2010-12-31T00:00:00.000Z')")
必要に応じて、条件、順序、制限、オフセットを使って、TQLでさらにデータをフィルタリングすることができます。以下は、TQLを使って実行できるクエリの例です。
# TQLのクエリ例
query = races_data.query("select * where circuitID = 22 raceTime >= TIMESTAMP('2010-12-31T10:10:00.000Z')")
query = races_data.query("select * where raceTime >= TIMESTAMP('2010-12-31T10:10:00.000Z') order by asc")
query = races_data.query("select * limit 25")
次に、結果の出力をフェッチし、出力を反復して、フェッチされたすべてのレコードを含むリストを作成する必要があります。最後に、リストをcircuits_dataframeとraces_dataframeという2つのPandasのデータフレームに変換します。
リストをデータフレームに変換する際に、columnsオプションを定義して、データを関連するフィールドにマッピングすることができます。これで、GridDBデータベースのデータを使った2つの新しいデータフレームができました。
データの整理
さて、2つのデータセットができましたが、これらを使って何ができるでしょうか?答えは何でもです。ユーザーの要求を満たすためにデータを使用することができます。単純な例として、両方のデータフレームを使用して1つの結合データセットを作成することを考えてみましょう。
そのためには、Pandasライブラリのマージ関数を使用して、circuitIDを2つのデータセットの関係として使用して、2つのデータフレームを1つのデータフレームに結合することができます。結合する前に、両方のデータフレームに名前とURLのカラムがあるので、カラム名を変更する必要があります。各データフレームの名前を変更して個々のデータセットを表し、resultsという1つのデータフレームにデータをマージしてみましょう。
# Rename columns in circuits_dataframe
circuits_dataframe.rename(
columns={
'name' : 'circuit_name',
'url' : 'circuit_info'
}, inplace=True
)
# Rename columns in races_dataframe
races_dataframe.rename(
columns={
'name' : 'race_name',
'url' : 'race_info'
}, inplace=True
)
# Merge the two data sets
result = pd.merge(races_dataframe, circuits_dataframe, on='circuitId')
# Print the result
print(result)
とても簡単ですね。これで、データをより効果的に分析するための1つのデータセットを作成することに成功しました。
まとめ
この記事では、CSVファイルで取得したデータを変換してクリーンアップする方法を学びました。さらに、変換されたデータを使用してコレクションを作成するためのGridDBとの対話方法や、必要な情報を抽出するためのクエリの方法についても学ぶことができました。この記事をベースにして、データアナリティクスの世界へのデータジャーニーを始めてみてはいかがでしょうか。