
はじめに
ノーベル賞は、おそらく世界で最もよく知られた名誉ある賞です。世界中の専門家や活動家が、ノーベル賞受賞者になりそれぞれの分野でその威光を分かち合うことを夢見ています。ビジネスリーダーやデータアナリストたちにとって、この重要で威信のあるノーベル賞に対して探索的分析や予測分析を行い時系列でのノーベル賞受賞者の傾向を調べることは、とてもエキサイティングなことです。
研究者やアナリストが注目するこのノーベル賞に関する分析は、時系列的な活動に関連しているため、そのような時系列的な複雑さに対応できるように設計・最適化されているGridDBは理想的な分析ツールであると言えます。
GridDBとPythonのシームレスな統合は、データサイエンスプログラミング言語のデファクトリーダーを活用することで、競争上の優位性をもたらします。今回は、IoTやビッグデータに最適化された拡張性の高いインメモリNoSQL時系列データベースであるGridDBを使ってみましょう。
The Nobel Foundationが提供する、1901年のノーベル賞開始から2016年までの全受賞者の人口統計データを視覚的に分析することを目的とした簡単なプロジェクトを通じて、GridDBを使い始めるためのステップバイステップのチュートリアルをご紹介します。それでは、データを読み込んで見てみましょう。
Ubuntu上でGridDBを設定する
実際のプロジェクトとその実装作業に入る前に、お使いのシステムでGridDBが稼働していることを確認してください。UbuntuやCentOSでのGridDBの設定についての詳細は、GridDBのクイックスタートガイドをご参照ください。
データセット
今回のプロジェクトでは、Kaggleで公開されているNobel Laureates データセットを使用します。
データフレームにファイルを読み込む
Pythonには、データ関連の複雑なタスクを実行するために特別に設計、実装、最適化されたPandasという優れたライブラリが用意されており、探索分析や予測分析を行うことができます。Pandasには、アナリストや科学者がCSVファイルからのデータ抽出を含むエンド・ツー・エンドのプロセスをスムーズに実行するための様々なモジュールがあります。
# Read CSV file
nobelprize_data = pd.read_CSV("nobel.CSV")
上のコードスニペットでは、CSVファイルを読み込んでPandasのデータフレームを作成し、データの管理、変換、前処理を行っています。
データの前処理
先ほどPandasのデータフレームに格納したデータを使って、前処理を行います。前処理スクリプトを何度も実行しなくて済むように、ユースケースに関連するデータポイントをフィルタリングし、データをクリーニングし、処理したデータを新しいCSVファイルに保存します。
このCSVには、私たちの分析にとって重要ではない多くの列が含まれているため、この初心者の段階でデータをより深く理解するためには、列数は少なく減らす方が良いでしょう。
# Drop irrelevant columns
nobelprize_data = nobelprize_data.drop(labels =
["Motivation","Full Name", "Birth Date",
"Birth City" , "Birth Country",
"Death Date", "Death City" , "Death Country" ,
"Organization City", "Organization Country",
"Organization Name"], axis = 1)
いくつかの列を削除すると、以下のような列が残ります。
- Year(受賞年)
- Category(受賞部門)
- Prize(受賞した賞のタイトル)
- Prize Share(受賞発表日)
- Laureate ID(ノーベル賞データベースが付与する受賞者ID)
- Laureate Type(受賞者が個人か団体か)
- Sex(性別)
さらに、列が非nullとして識別されてしまう場合があり、「性別」の列でnullが「非公表」を表しているような場合に、その行を維持するために設定変更を行う必要があります。
nobelprize_data['Sex'] = nobelprize_data['Sex'].fillna("Not disclosed")
さらに、データベースの主キーとして参照するために、IDというカラムを導入します。
# Add auto incremental ID
nobelprize_data.index.name = 'ID'
ここで、より分かりやすくなるようにカラム名を変更します。
# Rename columns
fixColNames = nobelprize_data.rename(columns =
{"Year": "year",
"Category":"category",
"Prize": "prize",
"Prize Share":"prize_share",
"Laureate ID":"laureate_id",
"Laureate Type":"laureate_type",
"Sex":"sex"})
処理したデータを新しいCSVファイルに保存した後、CSVファイルからPandasのデータフレームにデータをロードする手順を再度行います。
# Generate a new processed file
fixColNames.to_CSV("preprocessed.CSV")
Pandasのデータフレームにデータが読み込まれたら、それをGridDBに挿入して、データに対して最適化された分析操作を行う準備が整いました。
GridDBへデータを挿入する
GridDBがデータを挿入するために設定している標準的な方法は、コンテナを作成し、putメソッドを使用することです。ここでは、この方法とPandaのデータフレームへのデータ挿入方法を組み合わせてみます。
まず、GridDBでコンテナnobelprize_1901をインスタンス化し、データタイプを定義します。データタイプが正しいことを確認しておかないと、解析時にバリデーションエラーが発生する可能性があります。
# Create Collection circuits
nobelprize_containerInfo = GridDB.ContainerInfo(nobelprize_container,
[["ID", GridDB.Type.INTEGER],
["year", GridDB.Type.INTEGER],
["category", GridDB.Type.STRING],
["prize", GridDB.Type.STRING],
["prize_share", GridDB.Type.STRING],
["laureate_id", GridDB.Type.INTEGER],
["laureate_type", GridDB.Type.STRING],
["sex", GridDB.Type.STRING]],
GridDB.ContainerType.COLLECTION, True)
nobelprize_columns = gridstore.put_container(nobelprize_containerInfo)
コンテナの準備ができたので、レコードをこのコンテナにインポートします。GridDBのput_rowsメソッドを使うと、データフレームからインポートすることができます。
# Put rows
nobelprize_columns.put_rows(nobelprize_data)
CSVのデータと構造がnobelprize_1901に取り込まれ、GridDBの構造化されたフォーマットに適応されました。
GridDBからデータにアクセスする
データが GridDB コンテナにインポートされたので、データを取得します。GridDB には独自のクエリ言語である TQL があり、このソースから学習することができます。TQL は GridDB コンテナからデータを照会するために使用され、標準的な SQL プロトコルに似たコマンドを使用します。ここでは、データベースからデータを取得する方法について説明します。GridDB にはクエリ機能があり、ユーザはコンテナにクエリを発行して Database からデータを取得することができます。以下のコードブロックを見てください。ここでは、get_container関数を使ってコンテナを取得し、コレクションを照会して必要なデータを取り出しています。get_container関数を使ってコンテナを取得し、クエリを使ってデータを抽出するために使用したTQLの簡単な例を紹介します。この例では、コンテナからすべてのレコードを選択するためにselect *を使います。
# Fetch all rows - circuits_container
query = nobelprize_data.query("select *")
このブログは、すべてのレコードを選択するシンプルなクエリを記述していますが、さらに踏み込んで、注文、制限、条件に沿ってデータをフィルタリングするために、さまざまなコマンドを使用することもできます。先に述べたGridDBの公式ページから、自由に構文を調べることができます。
GridDBコンテナからデータを取得した後は、分析のためにPandasのデータフレームにデータを戻します。これにはpd.DataFrame()メソッドを使って、GridDBコンテナのリストをデータフレームに変換します。
これで、GridDBデータベースからデータフレームを取得することができました。
GridDBで解析する
データセットがGridDBコンテナに読み込まれたところで、いよいよ分析に入ります。まず、必要なライブラリをインポートします。numpy、 matplotlib、 pandas の3つです。
import numpy as np
import GridDB_python as GridDB
import sys
import pandas as pd
import matplotlib.pyplot as plt
ここでは、ノーベル賞受賞者の性別欄を見て、性別とノーベル賞の比率を棒グラフにして考えてみます。
# Analysis on Gender
gender_wise = nobelprize_dataframe['sex'].value_counts()
genderplot = gender_wise.plot(kind='bar')
genderplot.figure.tight_layout()
genderplot.figure.savefig('gender_wise.png')
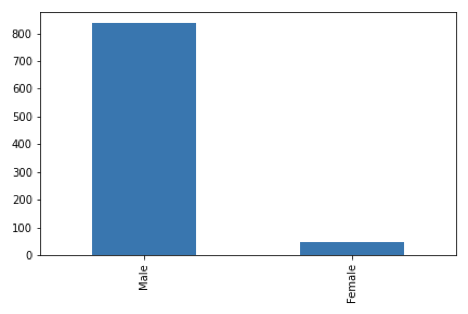
見て分かるように、ノーベル賞受賞者は圧倒的に男性が多数です。数ある理由のうちの1つとして、20世紀前半に女性の地位向上が進んでいなかったことが挙げられます。また、女性に比べて男性の才能の方が認められやすいという偏りがあったということもあるでしょう。2018年にノーベル物理学賞を受賞したドナ・ストリックランドは、わずか3人目の女性受賞者です。
従来のステレオタイプでは、女性は「数学が嫌い」「科学が苦手」という理由でSTEM分野を避けようとしがちです。これは現在も続いている問題ですが、ここ数十年、この見方を克服するために多くの努力がなされています。
分野別に見てみると、科学分野での受賞が多く、中でも医学と物理学の受賞が多いことがわかります。これは、20世紀に非科学的な分野があまり評価されなかったことや、ある分野のノーベル賞が存在しなかったり、後から追加されたりしたことによると思われます。特にコンピュータサイエンスは、現在のところノーベル賞の対象となっておらず、代わりにチューリング賞という別の賞が設けられています。分析の目的が分野の認知度と人気を比較することであるならば、チューリング賞を含めることで、別の意味のある洞察を得ることができるでしょう(本ブログでは取り上げていません)。
さらに、先ほどの2つの分野を使ってデータを分析し、1つのグラフにしました。
# Analysis on Category
category_wise = nobelprize_dataframe['category'].value_counts()
nobelprize_dataframe.groupby(['category','sex']).size().unstack().plot(kind='bar',stacked=True)
plt.tight_layout()
plt.savefig('Category+Gender.png', orientation = 'landscape')
plt.show()
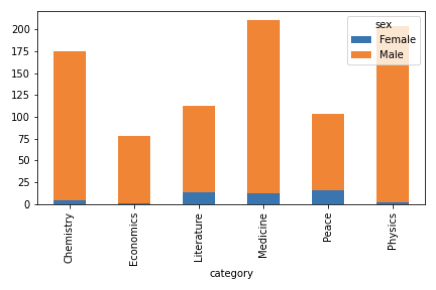
女性のノーベル賞受賞者が最も多いのは平和賞であるのに対し、STEM分野で女性の活躍が目立つのは医学賞だけであることがわかります。
また、各分野に与えられた賞を異なる期間に渡って分析し、それがどのように変化してきたかを知ることで、何らかのヒントが得られるでしょう。
# Time series analysis on Year Group
nobelprize_dataframe["Year_Group"] = pd.cut(nobelprize_dataframe["year"],[1900,1910,1920,1930,1940,1950,1960,1970,1980,1990,2000,2010,2016], precision=0, labels=['1900-1910','1910-1920','1920-1930','1930-1940','1940-1950','1950-1960','1960-1970','1970-1980','1980-1990','1990-2000','2000-2010','2010-2016'])
nobelprize_dataframe.groupby(['Year_Group','category']).size().unstack().plot(kind='bar',stacked=True)
plt.tight_layout()
plt.savefig('Change_over_years.png')
plt.show()
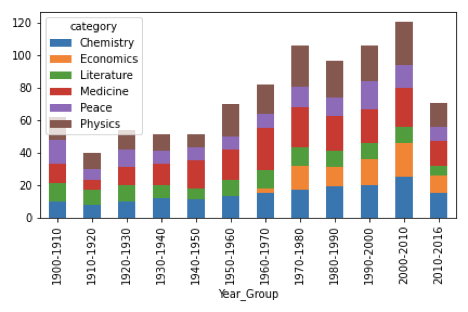
下のグラフを見ると、過去120年間で全体の比率が変わらない分野があることがわかります。例えば、平和賞と文学賞です。一方、医学賞や物理学賞などのSTEM分野では、ノーベル賞の受賞数が年々増加していることが明らかになっています。グラフから得られる最も重要な洞察として、経済学賞は1900年代初頭には目立たなかったものの、1970年以降に経済学賞受賞者数が大幅に増加していることが分かります。
このように、GridDBとPythonを使って、データの読み込み、挿入、取り出し、分析を行う方法について紹介しました。
まとめ
このブログでは、GridDBを使い始めるための簡単なプロジェクトを作成し、CSVファイルの前処理と読み込み、GridDBコンテナからのデータの挿入と取得、matplotlib、pandas、numpyを使ったデータ分析の方法を紹介しました。また、GridDBからのデータの問い合わせや、データフレームへのインポートの基本についても説明しました。これはGridDBでできる機能のほんの一部に過ぎません。TQLフィルタやGridDBコンテナを自由に使って、より充実した学習体験をしてみてください。Happy coding!
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb