
はじめに
クラスタリングはデータマイニングの代表的なタスクです。このタスクでは、データアイテムをいくつかの意味のあるグループまたはクラスタに分割します。クラスタリングは、データアイテム間の基本的な関係を特定するのに役立ち、意思決定にも役立ちます。
クラスタリングアルゴリズムは数多く存在しますが、K-Meansは最も一般的で簡単なクラスタリングアルゴリズムです。K-Meansはデータセットをk個のグループに分割します。似たようなアイテムは同じグループに入れられ、似ていないアイテムは異なるグループに入れられます。このブログでは、JavaとGridDBを使ってK-Meansアルゴリズムを実装する方法について説明します。
K-Meansアルゴリズム とは何か?
K-Meansはデータアイテムを最も近いクラスタに割り当てるクラスタリングアルゴリズムです、このアルゴリズムでは、一つのプロパティ、すなわち、通常kと示されるクラスタの数を指定する必要があります。
以下の疑似コードは、このアルゴリズムがどのように機能するかを説明しています。
Step 1: `k`個の初期セントロイドを選択します。
繰り返す:
Step 2: 各データポイントを最も近いクラスタのセントロイドに割り当てて,`k`個のクラスタを作成します。
Step 3: クラスタの新しいセントロイドを再計算します。
これをセントロイドが変化しなくなるまで繰り返して行います。
ユーザーは、形成するクラスタの数であるkの値を指定することが求められます。アルゴリズムは、データセットから k 個のオブザベーションを選択して,クラスターの中心とします。
次のステップでは、すべてのデータ項目を調べてクラスタに分類し、すべての観測データが最も近いセントロイドに割り当てられるようにします。
その後、クラスタの新しいセントロイドが再計算されます。これは、クラスタ内のすべてのオブザベーションの平均値を得ることで行われ、その結果が新しいセントロイドになります。上記のステップは、セントロイドが変化しなくなるまで繰り返されます。
次に、K-MeansアルゴリズムをJavaで実装する方法を紹介します。蓄積データベースとしてGridDBを使用します。
JavaでK-Meansを実装する
ここからは、JavaとGridDBを使ってK-Meansアルゴリズムを実装します。今回は、複数人の年収と、それに対応する支出スコアを示すデータセットを使用します。
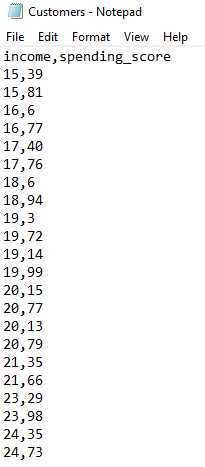
まず、データをGridDBに書き込み、そこからK-Meansアルゴリズムを使って分析するためにデータを取り出します。
パッケージをインポートする
まず、使用するパッケージをインポートします。
import java.io.IOException;
import java.util.Collection;
import java.util.Properties;
import java.util.Scanner;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;GridDBにデータを書き込む
データは“Customers.csv”というCSVファイルに保存されていますが、これをGridDBコンテナに移動する必要があります。まず、コンテナのスキーマをスタティックなクラスとして作成します。
public static class Customers{
@RowKey String income;
String spending_score;
}上記のクラスは、2つのカラムを持つコンテナまたはSQLテーブルとして見てください。
ここで、GridDBへの接続を確立させます。接続するクラスタの名前、接続する必要のあるユーザの名前、およびそのユーザのパスワードなど、GridDBインストールの仕様を使用してPropertiesインスタンスを作成する必要があります。以下のコードを使用します。
Properties props = new Properties();
props.setProperty("notificationAddress", "239.0.0.1");
props.setProperty("notificationPort", "31999");
props.setProperty("clusterName", "defaultCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);上記は、私たちがインストールしたGridDBの詳細です。各自の環境に合わせて適宜変更してください。
今回はCustomersコンテナを使用するので、まずそれを選択します。
Collection<String, Customers> coll = store.putCollection("col01", Customers.class);コンテナ Customers のインスタンスを作成し、coll という名前を付けました。今後はこのインスタンスを使ってコンテナを参照します。
データをGridDBに格納する
次のJavaコードは、”Customers.csv “ファイルからデータを読み取り、それをGridDBに格納するために使います。
File file1 = new File("Customers.csv");
Scanner sc = new Scanner(file1);
String data = sc.next();
while (sc.hasNext()){
String scData = sc.next();
String dataList[] = scData.split(",");
String income = dataList[0];
String spending_score = dataList[1];
Customers customers = new Customers();
customers.income = income;
customers.spending_score = spending_score;
coll.append(customers);
}このコードでは、”Customers.csv “ファイルからデータを読み込み、customersオブジェクトを作成しています。そして、その customers オブジェクトを GridDB コンテナに追加しています。.csv データセットの区切り文字にはカンマ (,) を使用しています。
GridDBからデータを取得する
これで、GridDBからデータを取り出し、K-Meansアルゴリズムを使って分析することができます。以下のコードは、GridDBにデータを照会するためのものです。
Query<customers> query = coll.query("select *");
RowSet</customers><customers> rs = query.fetch(false);
RowSet res = query.fetch();</customers>select *文は、データベースコンテナからすべてのデータを照会するのに役立ちます。
データをクラスター化する
データベースからデータを取り出したので、K-Meansアルゴリズムを使ってクラスタリングを行います。データから2つのクラスタを作成するので、kの値を2に設定します。
また、2つの点を初期化して、2つのクラスタのセントロイドの初期セントロイドとして機能させます。このコードでは、各データアイテムとセントロイドの間の距離を計算し、各データアイテムを最も近いクラスタに割り当てます。
このコードは、クラスターのセントロイドが変化しなくなると、反復処理を停止します。
コードは以下の通りです。
int x,j,k=2;
int cluster1[][] = new int[18][10];
int cluster2[][] = new int[20][80];
float mean1[][] = new float[1][2];
float mean2[][] = new float[1][2];
float temp1[][] = new float[1][2], temp2[][] = new float[1][2];
int sum11 = 0, sum12 = 0, sum21 = 0, sum22 = 0;
double dist1, dist2;
int i1 = 0, i2 = 0, itr = 0;
System.out.println("\nNumber of clusters: "+k);
// Set random means
mean1[0][0] = 18;
mean1[0][1] = 10;
mean2[0][0] = 20;
mean2[0][1] = 80;
// Loop untill the new mean and previous mean are the same
while(!Arrays.deepEquals(mean1, temp1) || !Arrays.deepEquals(mean2, temp2)) {
//Empty the partitions
for(x=0;x<10;x++) {
cluster1[x][0] = 0;
cluster1[x][1] = 0;
cluster2[x][0] = 0;
cluster2[x][1] = 0;
}
i1 = 0; i2 = 0;
//Find the distance between mean and the data point and store it in its corresponding partition
for(x=0;x<10;x++) {
dist1 = Math.sqrt(Math.pow(res[x][0] - mean1[0][0],2) + Math.pow(res[x][1] - mean1[0][1],2));
dist2 = Math.sqrt(Math.pow(res[x][0] - mean2[0][0],2) + Math.pow(res[x][1] - mean2[0][1],2));
if(dist1 < dist2) {
cluster1[i1][0] = res[x][0];
cluster1[i1][1] = res[x][1];
i1++;
}
else {
cluster2[i2][0] = res[x][0];
cluster2[i2][1] = res[x][1];
i2++;
}
}
//Store the previous mean
temp1[0][0] = mean1[0][0];
temp1[0][1] = mean1[0][1];
temp2[0][0] = mean2[0][0];
temp2[0][1] = mean2[0][1];
//Find the new mean for new partitions
sum11 = 0; sum12 = 0; sum21 = 0; sum22 = 0;
for(x=0;x<i1;x++) {
sum11 += cluster1[x][0];
sum12 += cluster1[x][1];
}
for(x=0;x<i2;x++) {
sum21 += cluster2[x][0];
sum22 += cluster2[x][1];
}
mean1[0][0] = (float)sum11/i1;
mean1[0][1] = (float)sum12/i1;
mean2[0][0] = (float)sum21/i2;
mean2[0][1] = (float)sum22/i2;
itr++;
}
System.out.println("Cluster1:");
for(x=0;x<i1;x++) {
System.out.println(cluster1[x][0]+" "+cluster1[x][1]);
}
System.out.println("\nCluster2:");
for(x=0;x<i2;x++) {
System.out.println(cluster2[x][0]+" "+cluster2[x][1]);
}
System.out.println("\nFinal Mean: ");
System.out.println("Mean1 : "+mean1[0][0]+" "+mean1[0][1]);
System.out.println("Mean2 : "+mean2[0][0]+" "+mean2[0][1]);
System.out.println("\nTotal Iterations: "+itr);コードをコンパイルし実行する
まず、gsadmユーザでログインします。作成した.javaファイルを、以下のパスにあるGridDBのbinフォルダに移動します。
/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin
次に、Linuxのターミナルで以下のコマンドを実行し、gridstore.jarファイルのパスを設定します。
export CLASSPATH=$CLASSPATH:/home/osboxes/Downloads/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin/gridstore.jar
次に、以下のコマンドを実行して、.javaファイルをコンパイルします。
javac Kmeans.java
以下のコマンドを実行して生成された.classファイルを実行します。
java Kmeans
このコードでは、以下のように、2つのクラスターそれぞれにクラスタリングされたデータポイント、各クラスターの平均値、および実行された反復回数が表示されます。同じクラスターに入れられたデータポイントは、他のクラスターに入れられたデータポイントよりも互いに似ていることがわかります。
Number of clusters: 2
Cluster1:
15 39
16 6
17 40
18 6
19 3
Cluster2:
15 89
16 77
17 76
18 94
19 72
Final Mean:
Mean1 : 17.0 18.8
Mean2 : 17.0 81.6
Total Iterations: 2
これで完了です。以上、JavaとGridDBを使ったK-Meansアルゴリズムの実装方法について説明しました。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb