
このブログでは、PostgreSQLからGridDBへの移行を簡単に行う方法をご紹介します。リレーショナルデータベースにあまり詳しくない方のために説明すると、PostgreSQLは「世界で最も先進的なオープンソースリレーショナルデータベース」1であると言われています。
このブログでは、GridDBとPostgreSQLを直接比較するのではなく、2つのデータベースのスキーマの違いと、リレーショナルデータベースからGridDBにデータを安全に移行する方法に焦点を当てて説明します。また、PostgreSQLからGridDBへの移行を検討すると良い理由についても触れます。
GridDBはNoSQLデータベースでありながらSQLを使用することができ、SQLをルーツとしていることも特徴です。そのため、「伝統的な」リレーショナルデータベースからデータをインポートしても、データ型にあまりこだわる必要がありません。
本ブログのソースコードは、こちらのGitHubからご覧いただけます。この中には、Kaggleからオリジナルのソースデータをクリーンアップするためのpythonスクリプトを含む、すべての関連ファイルが含まれています。
ノンテクニカルセクション
このセクションでは移行方法を理論的に説明します。移行方法をすぐに知りたい方は、次のセクションに進んでください。
過去のブログ
このトピックは過去のブログMySQLからGridDBへの移行とPostgreSQLからGridDBへの移行 でも触れたことがあります。この2つのブログでも、様々な方法を用いて技術的にデータを移行する方法について説明しています。
GridDBのインポート・エクスポートツールを紹介する他に、なぜPostgreSQLからGridDBへ移行すると良いかについても説明します。
それでははじめましょう。
なぜMigrateするべきか?
GridDBインポート・エクスポートツールを使ってPostgreSQLからGridDBにデータを物理的に移行する技術的な側面に入る前に、なぜリレーショナルデータベースから時系列ベースのGridDBにデータを移行するプロセスを踏む必要があるのかを簡単に説明しましょう。
もし、あなたのワークロードやデータセットが時系列データに基づいているならば、時系列データセットを扱うために作られたデータベースに移行することは、完全に理にかなっています。GridDBは、時系列のワークロードを扱うことに長けており、こちらのドキュメントで説明されています。時系列データベースとはを参照してください。
GridDBは、時系列の機能に加えて、ホワイトペーパー GridDBとMariaDBを用いたセンサー課金アプリケーションのベンチマークで公開した過去のベンチマークに見られるように、SQLデータベースと比較して、かなり大きな性能上の優位性を持っています。このベンチマークは幅広いクエリをカバーしていますが、簡潔にまとめると、GridDBはMariaDBに比べて13倍速くデータを取り込むことができました。
時には性能よりも、素早く効率的にプロトタイプを作成する能力がより重要な指標となることもあるでしょう。もしそうでなければ、すべてのユースケースにおいてC++が支配的なプログラミング言語となり、Pythonはかなりニッチな立ち位置になっていたでしょう。GridDBがこの点で優れているのは、JDBC (Java Database Connectivity)を介して使用可能なSQLインターフェースを備えつつ、データベースとの対話に使用できるNoSQLインターフェースも同時に備えている点です。
GridDB NoSQLインターフェースは、GridDBをメインバックエンドとして使用することを中心としたアプリケーションを迅速かつ容易に構築することができます。つまり、GridDBの大規模データセットを素早く分析する必要がある場合(例:GridDBによるニューヨークの犯罪データの地理空間分析)、Pythonコードを書き、Pythonスクリプト内からデータセットに直接問い合わせることができます。また、GridDBがコネクタを持つ他の多くの言語インタフェースについても同様です(Githubページに記載されています)。
RDBとGridDBのスキーマの違いについて
スキーマの違いに入る前に簡単に書いておくと、これはすべての状況に適用できるわけではなく、特定のデータセットを整理するのに最適な方法であるということです。スキーマの違いについては、広いデータテーブルと狭いデータテーブルで詳しく解説しています。
PostgreSQLのテーブルでは、通常のRDBスキーマと呼ばれるものを使用しました。つまり、すべてのデータが1つの大きなテーブルになっています。このスキーマでは、すべてのセンサーのデータが同じテーブルを共有しているので、各行にはセンサー名を示す列が含まれていなければなりません。このデータセットには3つの異なるセンサーがありますが、すべてのセンサーに対して1つのテーブルを使用しています。
GridDBに移行する際には、より「IoTに適した」スキーマとなるものに切り替えることが必須となります。そこで、具体的な話に入る前に、スキーマの変更内容がどうなるのか、なぜそれがIoTの世界でより有用なのかについてお話ししましょう。
リレーショナルテーブルでは、Kaggleからダウンロードした.csvファイルと同じように、すべてのセンサーが同じテーブルを共有する可能性が高いです。これは、SQLデータベースとスキーマ構築は大部分がレガシーであり、現代で生成されるデータ量を必ずしも考慮していないために行われるものです。
一方、GridDBはビッグデータとIoTを念頭に置いて開発されたものなので、検討の余地があります。大規模なIoT環境向けにスキーマやデータベースを構築する場合、データを分割する論理的な方法として、すべてのセンサーを同じテーブルにまとめることを考え直す必要があります。問題は、データが長く蓄積されると、RDBテーブルが扱いにくくなり、使い勝手が悪くなるということです。
そこで、GridDBに移行することになった場合、センサーが同じテーブルを共有するのではなく、次のようにセンサーごとにテーブルを分割して利用することにします。
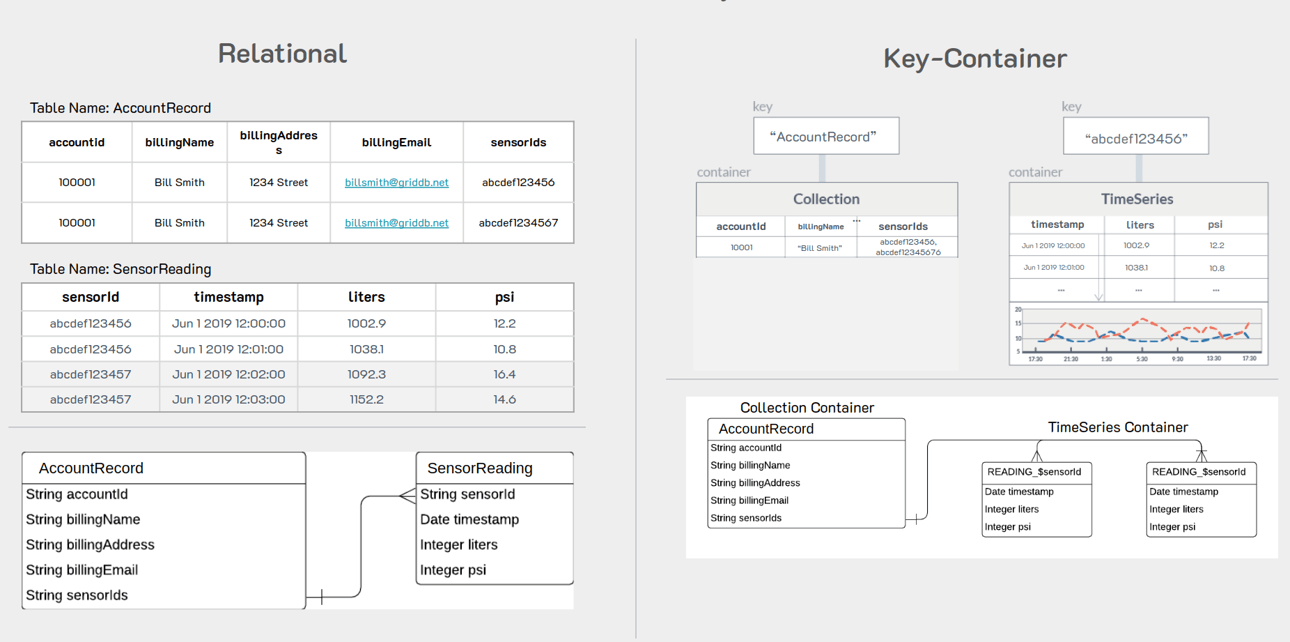
つまり、各テーブルは時間とともに大きくなることはあっても、常に代替案よりはるかに小さくなるのです。
また、GridDBはNクラスタの大きさに対応できるスケーラブルなデータベースなので、このようなスキーマがあれば、クラスタの異なるノードに異なるコンテナを収容することができ、並列化が容易になり、全体として効率の良いデータベースを実現できます。
もうひとつは、時系列データを扱っているため、データの保持ポリシーを設定することで、テーブルの容量が大きくなりすぎないようにすることができることです。つまり、センサーが1秒ごとにデータを発信し、大きなコンテナに蓄積されても、いずれは古くなり、テーブルを小さくすることができます。
テクニカルセクション :GridDB公式インポート・エクスポートツールの利用について
次のセクションでは、これから、あるデータベースから他のデータベースへデータを移行するプロセスを開始します。ここでは、GridDBがaptを使ってインストールされていることを前提とします。そしてもちろんPostgreSQLサーバーが稼働しているものとします。
PostgreSQLテーブルをCSVにエクスポートする
このPostgreSQLのセクションでは、すでにデータベース内に移行したいデータセットがあることを想定しています。今回のデモでは、Kaggleのデータセットをインジェストし、それを使って説明します。
PostgreSQLからGridDBにデータをエクスポートするには、PostgreSQLのコピー機能を使って、1テーブルずつCSVファイルにエクスポートする方法があります。この方法では、一度に1つのテーブルしかエクスポートできませんが、データの正確さとGridDBへのインポートを容易にすることができます。
例えば、以下のコマンドは、後でGridDBで使うために、データをcsvファイルにエクスポートするのに使ったものです。
COPY device15 TO '/tmp/devices_db.csv' DELIMITER ',' CSV HEADER;コマンドが終了すると、エクスポートしたいテーブルの.csvファイルが作成されます。
この場合、device15テーブルは、このKaggle IoT datasetを直接表現したものです。
GridDBでインポートする
GridDBを使ってインポートするには、公式のインポート・エクスポートツールを使用することができます。今回は、もちろんインポートツールを使用します。このツールは、GridDB Export Importからダウンロードできます。
このツールを使うには、csvファイルを少し変更する必要があります。
例えば、このファイルの先頭は以下のようになっています。
ts,device,co,humidity,light,lpg,motion,smoke,temp
2020-07-12 00:01:34.385974,b8:27:eb:bf:9d:51,0.0049559386483912,51,f,0.0076508222705571,f,0.0204112701224129,22.7
2020-07-12 00:01:34.735567,00:0f:00:70:91:0a,0.0028400886071015,76,f,0.005114383400977,f,0.0132748367048515,19.700000762939453
2020-07-12 00:01:38.073572,b8:27:eb:bf:9d:51,0.0049760123404216,50.9,f,0.007673227406398,f,0.0204751255761782,22.6
2020-07-12 00:01:39.589145,1c:bf:ce:15:ec:4d,0.0044030268296996,76.80000305175781,t,0.0070233371458773,f,0.0186282253770188,27
2020-07-12 00:01:41.761234,b8:27:eb:bf:9d:51,0.0049673636419089,50.9,f,0.0076635772823724,f,0.0204476208102336,22.6
2020-07-12 00:01:44.46841,1c:bf:ce:15:ec:4d,0.0043910039545833,77.9000015258789,t,0.0070094585431387,f,0.0185889075400507,27
2020-07-12 00:01:45.448863,b8:27:eb:bf:9d:51,0.0049760251182241,50.9,f,0.0076732416602977,f,0.0204751662043622,22.6
2020-07-12 00:01:46.869075,00:0f:00:70:91:0a,0.0029381156266604,76,f,0.0052414818417311,f,0.0136275211320191,19.700000762939453
2020-07-12 00:01:48.275381,1c:bf:ce:15:ec:4d,0.0043454713595732,77.9000015258789,t,0.0069568023772355,f,0.0184397819021168,27
このように、ファイルの先頭から直接出てきます。では、まずツールを用意して、データを用意してインポートを実行しましょう。
ツールをインストールする
まずは、インポート・エクスポートのレポをクローンして、ファイルをビルドします。
$ git clone https://github.com/griddb/expimp.git次に、ビルドします。
$ cd expimp-ce
$ ./gradlew shadowJarビルドが完了し、.jarファイルの準備ができたら、.propertiesファイルを設定することができます。
$ cd ..
$ vim bin/gs_expimp.propertiesまた、筆者のようにFIXED_LISTモードでGridDBサーバを運用している場合、以下のように設定を変更します。
######################################################################
# gs_import/gs_export Properties
#
#
######################################################################
clusterName=myCluster
mode=FIXED_LIST
#hostAddress=239.0.0.1
#hostPort=31999
#jdbcAddress=239.0.0.1
#jdbcPort=41999
#notificationProvider.url=
notificationMember=127.0.0.1:10001
jdbcNotificationMember=127.0.0.1:20001
logPath=log
getCount=1000
commitCount=1000
transactionTimeout=2147483647
failoverTimeout=10
jdbcLoginTimeout=10
storeBlockSize=64KB
maxJobBufferSize=512
# for debug
restAddress=127.0.0.1
restPort=1004ここでは、コンフィグのマルチキャスト部分(ホストアドレス、ホストポート)を削除し、FIXED_LISTモードをカプセル化した通知先メンバーに置き換えたものです。どちらを実行しているかわからない場合は、gs_statで簡単に確認することができます。
$ sudo su gsadm
$ gs_stat -u admin/adminGridDBをサービスとして実行している場合、FIXED_LISTモードで実行しているので、自分のマシンで上記の設定を安全に使用することができます。
インポートツールのデータを移行する
次に、CSV ファイルを直接編集して、GridDB インポートツールに対応するスキーマに変更する必要があります。そのためには、Python スクリプトを作成し、CSV ファイルを分割して作成することで、より効率的な GridDB データモデルである各センサーを独自のコンテナ・テーブルとして利用することができます。
では、pythonスクリプトを見てみましょう。
import pandas as pd
import numpy as np
import csv
from datetime import datetime as dt
df = pd.read_csv ('devices_db.csv')
df.head()
#Check data types
print(df.dtypes)
# convert ts in unix to ISO 8601 timestamp format
df['ts'] = pd.to_datetime(df['ts'], unit = 's').dt.strftime('%Y-%m-%dT%H:%M:%S.%f+0000')
df.head(5)
# split data by device as recommended by GridDB schema (1 time series container per device)
dfs = dict(tuple(df.groupby('device')))
# Separate device1 data and remove device column as it will be stored in collection container
device1 = dfs['b8:27:eb:bf:9d:51']
device1 = device1.drop('device', axis=1)
device1.head()
# Separate device2 data and remove device column as it will be stored in collection container
device2 = dfs['00:0f:00:70:91:0a']
device2 = device2.drop('device', axis=1)
device2.head()
# Separate device3 data and remove device column as it will be stored in collection container
device3 = dfs['1c:bf:ce:15:ec:4d']
device3 = device3.drop('device', axis=1)
device3.head()
device1.to_csv('device1.csv', encoding='utf-8', quotechar='"', index=False, quoting=csv.QUOTE_ALL)
device2.to_csv('device2.csv', encoding='utf-8', quotechar='"', index=False, quoting=csv.QUOTE_ALL)
device3.to_csv('device3.csv', encoding='utf-8', quotechar='"', index=False, quoting=csv.QUOTE_ALL)このスクリプトは比較的簡単で、PostgreSQLのエクスポートからCSVファイルを受け取り、pandasのデータフレームに全データを読み込んでいます。これらのデータ構造は、各カラムを編集してCSVにエクスポートし直すことができるので便利です。
また、この機会にタイムスタンプ(ts)カラムをGridDBインポートツールが好む形式に変換しています。PostgreSQLがdatetime形式のフォーマットにエクスポートした数値から、次のようになります。
この場合、それぞれのセンサーに deviceX という名前をつけて、そこから別々の CSV ファイルを作成する。そこから新しいファイルを持って、GridDBインポートツールを使って、3つの新しいGridDB TimeSeriesコンテナを作ってみます。
そこで、pythonスクリプトを実行してください。すると、3つの新しいdeviceX.csvファイルができます。
インポートツールの条件付きで新規ディレクトリを作成する
このツールを使ってインポートするには、importという新しいディレクトリを作成し、スムーズなインポートに必要なすべてのファイルを格納します。
まず、GridDBツールで各カラムの型を認識するために、目的のスキーマのメタデータを含める必要があります。そこで、public.device1_properties.jsonというファイルを作成します。このファイルの最初の単語はDB名で、ここではpublicというGridDBのユニバーサル・デフォルトDBを使用します。残りのファイルは、コンテナの残りのデータを記入します。
{
"version":"5.0.0",
"database":"public",
"container":"device1",
"containerType":"TIME_SERIES",
"containerFileType":"csv",
"containerFile":"public.device1.csv",
"columnSet":[
{
"columnName":"ts",
"type":"timestamp",
"notNull":true
},
{
"columnName":"co",
"type":"double",
"notNull":false
},
{
"columnName":"humidity",
"type":"double",
"notNull":false
},
{
"columnName":"light",
"type":"bool",
"notNull":false
},
{
"columnName":"lpg",
"type":"double",
"notNull":false
},
{
"columnName":"motion",
"type":"bool",
"notNull":false
},
{
"columnName":"smoke",
"type":"double",
"notNull":false
},
{
"columnName":"temperature",
"type":"double",
"notNull":false
}
],
"rowKeySet":[
"ts"
],
"timeSeriesProperties":{
"compressionMethod":"NO",
"compressionWindowSize":-1,
"compressionWindowSizeUnit":"null",
"expirationDivisionCount":-1,
"rowExpirationElapsedTime":-1,
"rowExpirationTimeUnit":"null"
},
"compressionInfoSet":[
]
}このメタデータは分かりやすいので、次の説明に進みます。
次に、先ほどのcsvファイルをこのディレクトリに取り込みますが、ファイル名を変更します。device1.csv が public.device1.csv になるように、ファイル名の前に DB 名を追加します。また、GridDBツールにどのメタデータファイルを使用するか、サーバのDB名とコンテナ名を知らせるために、CSVファイルの先頭に少量のメタデータを追加します。
"%","public.device1_properties.json"
"$","public.device1"
"2020-07-12T00:01:34.385974+0000","0.0049559386483912","51.0","False","0.0076508222705571","False","0.0204112701224129","22.7"
"2020-07-12T00:01:38.073572+0000","0.0049760123404216","50.9","False","0.007673227406398","False","0.0204751255761782","22.6"そして最後に、カラム名・ヘッダー行を削除します。インポートツールはすでにjsonファイルにこのデータの詳細を明示的に持っているので、冗長になるためです。
つまり、GridDB にインポートするためには、メタデータの json ファイルと csv ファイルをディレクトリ内に含める必要があります。csvファイルの先頭には、メタデータファイルを示す”%”と、CSVファイルの保存先となるdb.container名の組み合わせを示す”$”の2行が必要です。そして、ヘッダー・列名の行をCSVファイルから削除します。この作業を3つのcsvファイル(device1, device2, device3)すべてに対して行い、同じimportディレクトリ内に置きます。
ツールをインポートする前に必要な最後の1つは、gs_export.jsonを作成することです。このファイルによって、ディレクトリ内のすべてのものを取り込むためのツールを簡単に呼び出すことができるようになり、このjsonファイルがさらにトラフィックを誘導してくれるからです。以下は、このjsonファイルの内容です。
{
"version":"5.0.0",
"address":"127.0.0.1:10001",
"user":"admin",
"containerCount":3,
"rowFileType":"csv",
"parallel":1,
"container":[
{
"database":"public",
"name":"device1",
"metafile":"public.device1_properties.json"
},
{
"database":"public",
"name":"device2",
"metafile":"public.device2_properties.json"
},
{
"database":"public",
"name":"device3",
"metafile":"public.device3_properties.json"
}
]
}これが完了したら、インポートツールを実行します。
$ cd expimp/bin
$ ./gs_import -u admin/admin -d /home/israel/development/import/ --allコマンド自体は簡単で、excutableを呼び出し、GridDBのユーザー名とパスワードを入力し、その後にインポートしたいディレクトリを--allフラグ付きで入力します。うまくいけば、以下のような出力が得られるはずです。
Import Start.
Number of target containers : 3
public.device1 : 187451
public.device2 : 111815
public.device3 : 105918
Number of target containers:3 ( Success:3 Failure:0 )
Import Completed.
GridDB CLIで確認することができます。
$ sudo su gsadm
$ gs_sh
gs> select * from device2;gs[public]> select * from device2;
111,815 results. (131 ms)
gs[public]> get 10
ts,co,humidity,light,lpg,motion,smoke,temp
2020-07-12T00:01:34.735Z,0.0028400886071015706,76.0,false,0.005114383400977071,false,0.013274836704851536,19.700000762939453
2020-07-12T00:01:46.869Z,0.0029381156266604295,76.0,false,0.005241481841731117,false,0.013627521132019194,19.700000762939453
2020-07-12T00:02:02.785Z,0.0029050147565559603,75.80000305175781,false,0.005198697479294309,false,0.013508733329556249,19.700000762939453
2020-07-12T00:02:11.476Z,0.0029381156266604295,75.80000305175781,false,0.005241481841731117,false,0.013627521132019194,19.700000762939453
2020-07-12T00:02:15.289Z,0.0028400886071015706,76.0,false,0.005114383400977071,false,0.013274836704851536,19.700000762939453
2020-07-12T00:02:19.641Z,0.0028400886071015706,76.0,false,0.005114383400977071,false,0.013274836704851536,19.799999237060547
2020-07-12T00:02:28.818Z,0.0029050147565559603,75.9000015258789,false,0.005198697479294309,false,0.013508733329556249,19.700000762939453
2020-07-12T00:02:33.172Z,0.0028400886071015706,76.0,false,0.005114383400977071,false,0.013274836704851536,19.799999237060547
2020-07-12T00:02:39.145Z,0.002872341154862943,76.0,false,0.005156332935627952,false,0.013391176782176004,19.799999237060547
2020-07-12T00:02:47.256Z,0.0029050147565559603,75.9000015258789,false,0.005198697479294309,false,0.013508733329556249,19.700000762939453
まとめ
これで、PostgreSQLからGridDBに直接データをインポートすることができ、さらに新しいスキーマを作成することもできました。ぜひ試してみてください。