
Watching Coastlines Vanish
More
Introduction Global climate change is accelerating sea level rise at an alarming rate—averaging 3.3mm per year due to ocean warming and ice melt—posing severe threats to coastal communities and infrastructure. The complex dynamics of tides, storm surges, and long-term sea level trends require advanced, real-time monitoring systems that can handle vast streams of temporal data with precision and speed. This guide details the deployment of a robust time-series database using GridDB’s efficient columnar storage, integrated with NOAA’s oceanographic APIs, to build a scalable platform for coastal vulnerability assessment. We’ll walk through designing a high-throughput data ingestion pipeline that converts raw tidal data into practical insights, empowering proactive climate adaptation efforts. Why GridDB for Time-Series in Coastal Monitoring? GridDB is an excellent choice for managing time-series data in coastal resilience projects because of its specialized features that handle high-volume, time-sensitive information effectively. Here’s why it stands out, explained in simple terms: Speedy Data Handling: GridDB uses storage system that’s optimized for quick reads and writes, making it ideal for processing millions of real-time sea level readings from sensors without slowdowns—crucial during fast-changing events like storms. Scalability for Big Data: It can easily scale to store and query massive datasets from sources like NOAA APIs, allowing coastal monitoring systems to grow as more sensors are added without losing performance. Time-Series Focus: Built-in support for timestamp-based queries lets you analyze trends over time (e.g., daily tides vs. yearly rises) efficiently, turning raw data into useful forecasts for flood risks or erosion. Cost-Effective Integration: Easy to connect with tools like APIs and analytics software, reducing setup time and costs for building end-to-end systems that support climate adaptation decisions. Oceanographic Data Pipeline Architecture Contemporary coastal monitoring systems require ingestion and correlation of multiple oceanographic data streams to provide comprehensive situational awareness. Our implementation targets three primary data categories: Real-Time Hydrostatic Measurements: High-frequency water level observations captured via pressure transducers and acoustic sensors, providing minute-resolution temporal data for immediate hazard detection and tidal analysis. Statistical Aggregations: Monthly mean sea level calculations derived from harmonic tidal constituent analysis, essential for identifying long-term trends and separating anthropogenic signals from natural oceanographic cycles. Geospatial Station Metadata: Comprehensive sensor network topology information including geographic coordinates, operational status, calibration parameters, and data quality metrics. The NOAA Tides and Currents API ecosystem provides standardized access to these data streams: Instantaneous Water Level Service: https://tidesandcurrents.noaa.gov/api/datagetter configured with high-resolution temporal sampling parameters Long-Term Statistical Trends: Monthly aggregation endpoints providing climatological baseline data Network Topology Service: https://tidesandcurrents.noaa.gov/mdapi/v1.0/webapi/stations delivering comprehensive sensor metadata GridDB Cloud Infrastructure Configuration Set Up GridDB Cloud For this exercise, we will be using GridDB Cloud vesion. Start by visiting the GridDB Cloud portal and signing up) for an account. Based on requirements, either the free plan or a paid plan can be selected for broader access. After registration ,an email will be sent containing essential details, including the Web API URL and login credentials. Once the login details are received, log in to the Management GUI to access the cloud instance. Application Properties Configuration The application.properties file located in src/main/resources is crucial for configuring the application’s connection to GridDB Cloud and other external services. Here’s an example of the properties you would typically configure: # GridDB Cloud Connection Properties griddb.rest.url=YOUR_GRIDDB_CLOUD_WEB_API_URL griddb.api.key=YOUR_GRIDDB_CLOUD_API_KEY griddb.cluster.name=YOUR_CLUSTER_NAME griddb.username=YOUR_USERNAME griddb.password=YOUR_PASSWORD # NOAA API Base URL (if applicable, for data fetching) noaa.api.base.url=https://tidesandcurrents.noaa.gov/api/datagetter Replace the placeholder values (YOUR_GRIDDB_CLOUD_WEB_API_URL, YOUR_GRIDDB_CLOUD_API_KEY, etc.) with your actual GridDB Cloud credentials and cluster details. These properties ensure the application can securely connect to and interact with your GridDB instance. Development Environment Architecture $ └───my-griddb-app $ ├───pom.xml $ ├───src $ │ ├───main $ │ │ ├───java $ │ │ │ └───com $ │ │ │ └───griddb $ │ │ │ └───coastal $ │ │ │ ├───CoastalMonitorApplication.java $ │ │ │ ├───controller $ │ │ │ │ └───DashboardController.java $ │ │ │ ├───model $ │ │ │ │ ├───MonthlyMeanData.java $ │ │ │ │ ├───StationMetadata.java $ │ │ │ │ └───WaterLevelData.java $ │ │ │ └───service $ │ │ │ ├───DataSchedulerService.java $ │ │ │ ├───GridDBService.java $ │ │ │ ├───NOAADataService.java $ │ │ │ └───RestTemplateConfig.java $ │ │ └───resources $ │ │ ├───application.properties $ │ │ └───templates $ │ │ └───dashboard.html $ └───target $ └───… (compiled classes, jar, etc.) ### Maven Dependency Integration Configure the project build system with GridDB client libraries: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.example</groupId> <artifactId>my-griddb-app</artifactId> <version>1.0-SNAPSHOT</version> <name>my-griddb-app</name> <url>http://maven.apache.org</url> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.4</version> <relativePath /> <!– lookup parent from repository –> </parent> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <!– JSON processing –> <dependency> <groupId>org.glassfish.jersey.core</groupId> <artifactId>jersey-client</artifactId> <version>2.35</version> </dependency> <dependency> <groupId>org.json</groupId> <artifactId>json</artifactId> <version>20210307</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.15.0</version> <!– or the latest version –> </dependency> <!– Lombok –> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>jakarta.annotation</groupId> <artifactId>jakarta.annotation-api</artifactId> <version>2.1.1</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <annotationProcessorPaths> <path> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> </path> </annotationProcessorPaths> </configuration> </plugin> </plugins> </build> </project> GridDB Container Architecture Our implementation leverages three specialized Time Series Containers optimized for different temporal characteristics and query patterns: Primary Time-Series Container (coastal_water_level) Designed for high-frequency sensor data ingestion with microsecond timestamp precision: timestamp (TIMESTAMP) – Primary temporal index with automatic partitioning station_id (STRING) – Composite index for spatial queries station_name (STRING) – Human-readable station identifier water_level (DOUBLE) – Calibrated measurement in specified datum datum (STRING) – Vertical reference system (MLLW, MSL, NAVD88) latitude (DOUBLE) – WGS84 decimal degrees longitude (DOUBLE) – WGS84 decimal degrees flags (STRING) – Quality control and sensor status indicators Statistical Aggregation Container (coastal_monthly_mean) Optimized for climatological analysis and trend detection: month (TIMESTAMP) – Monthly temporal partitioning key station_id (STRING) – Station correlation index station_name (STRING) – Station metadata mean_sea_level (DOUBLE) – Statistically processed monthly average year (INTEGER) – Temporal grouping field month_number (INTEGER) – Numerical month for seasonal analysis latitude (DOUBLE) – Geospatial coordinates longitude (DOUBLE) – Geospatial coordinates Metadata Container (coastal_stations) Station configuration and operational status tracking: station_id (STRING) – Unique station identifier station_name (STRING) – Official station designation state (STRING) – Administrative geographic region latitude (DOUBLE) – Precise geographic positioning longitude (DOUBLE) – Precise geographic positioning region (STRING) – Oceanographic zone classification is_active (BOOL) – Operational status flag last_updated (TIMESTAMP) – Maintenance tracking Real-Time Data Ingestion Pipeline The heart of any real-time monitoring system lies in its ability to efficiently collect and process incoming data streams. For our coastal monitoring solution, this means seamlessly integrating with authoritative sources like NOAA to capture critical oceanographic measurements as they happen. NOAA API Integration Service To ensure our system always has the most up-to-date information on sea levels and coastal conditions, we’ve developed a dedicated service for interacting with NOAA’s comprehensive APIs. This service is designed for resilience, handling network fluctuations and data retrieval with robust error management, ensuring a continuous flow of vital data into our system. package com.griddb.coastal.service; import com.griddb.coastal.model.WaterLevelData; import com.griddb.coastal.model.MonthlyMeanData; import com.griddb.coastal.model.StationMetadata; import org.json.JSONArray; import org.json.JSONObject; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Service; import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.time.LocalDate; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter; import java.util.*; @Service public class NOAADataService { private static final Logger logger = LoggerFactory.getLogger(NOAADataService.class); @Value("${noaa.api.base.url}") private String noaaBaseUrl; @Value("${noaa.api.metadata.url}") private String noaaMetadataUrl; @Value("${noaa.api.application}") private String applicationName; @Value("${noaa.stations}") private String stationsConfig; private Map<String, StationMetadata> stationCache = new HashMap<>(); /** * Fetch latest water level data for a station */ public List<WaterLevelData> fetchLatestWaterLevels(String stationId) { List<WaterLevelData> waterLevels = new ArrayList<>(); try { String urlStr = String.format("%s?product=water_level&application=%s&station=%s&date=latest&datum=MLLW&time_zone=gmt&units=metric&format=json", noaaBaseUrl, applicationName, stationId); logger.info("Fetching latest water levels from: {}", urlStr); String response = makeHttpRequest(urlStr); JSONObject jsonResponse = new JSONObject(response); if (jsonResponse.has("data")) { JSONArray dataArray = jsonResponse.getJSONArray("data"); StationMetadata station = getOrFetchStationMetadata(stationId); for (int i = 0; i < dataArray.length(); i++) { JSONObject dataPoint = dataArray.getJSONObject(i); // NOAA format: {"t": "yyyy-MM-dd HH:mm", "v": "x.xxx", "f": "…"} String timestamp = dataPoint.getString("t"); double waterLevel = Double.parseDouble(dataPoint.getString("v")); String flags = dataPoint.optString("f", ""); LocalDateTime dateTime = LocalDateTime.parse(timestamp, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm")); WaterLevelData wld = new WaterLevelData( stationId, station.getStationName(), dateTime, waterLevel, "MLLW", station.getLatitude(), station.getLongitude(), flags ); waterLevels.add(wld); } } logger.info("Fetched {} water level readings for station {}", waterLevels.size(), stationId); } catch (Exception e) { logger.error("Error fetching water level data for station {}: {}", stationId, e.getMessage()); } return waterLevels; } /** * Fetch historical water level data (last 7 days) */ public List<WaterLevelData> fetchRecentWaterLevels(String stationId, int days) { List<WaterLevelData> waterLevels = new ArrayList<>(); try { LocalDate endDate = LocalDate.now(); LocalDate startDate = endDate.minusDays(days); String urlStr = String.format("%s?product=water_level&application=%s&station=%s&begin_date=%s&end_date=%s&datum=MLLW&time_zone=gmt&units=metric&format=json", noaaBaseUrl, applicationName, stationId, startDate.format(DateTimeFormatter.ofPattern("yyyyMMdd")), endDate.format(DateTimeFormatter.ofPattern("yyyyMMdd"))); logger.info("Fetching recent water levels from: {}", urlStr); String response = makeHttpRequest(urlStr); JSONObject jsonResponse = new JSONObject(response); if (jsonResponse.has("data")) { JSONArray dataArray = jsonResponse.getJSONArray("data"); StationMetadata station = getOrFetchStationMetadata(stationId); for (int i = 0; i < dataArray.length(); i++) { JSONObject dataPoint = dataArray.getJSONObject(i); String timestamp = dataPoint.getString("t"); double waterLevel = Double.parseDouble(dataPoint.getString("v")); String flags = dataPoint.optString("f", ""); LocalDateTime dateTime = LocalDateTime.parse(timestamp, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm")); WaterLevelData wld = new WaterLevelData( stationId, station.getStationName(), dateTime, waterLevel, "MLLW", station.getLatitude(), station.getLongitude(), flags ); waterLevels.add(wld); } } logger.info("Fetched {} historical water level readings for station {}", waterLevels.size(), stationId); } catch (Exception e) { logger.error("Error fetching recent water level data for station {}: {}", stationId, e.getMessage()); } return waterLevels; } /** * Fetch monthly mean data for long-term trend analysis */ public List<MonthlyMeanData> fetchMonthlyMeanData(String stationId, int years) { List<MonthlyMeanData> monthlyData = new ArrayList<>(); try { LocalDate endDate = LocalDate.now(); LocalDate startDate = endDate.minusYears(years); String urlStr = String.format("%s?product=monthly_mean&application=%s&station=%s&begin_date=%s&end_date=%s&datum=MSL&time_zone=gmt&units=metric&format=json", noaaBaseUrl, applicationName, stationId, startDate.format(DateTimeFormatter.ofPattern("yyyyMMdd")), endDate.format(DateTimeFormatter.ofPattern("yyyyMMdd"))); logger.info("Fetching monthly mean data from: {}", urlStr); String response = makeHttpRequest(urlStr); JSONObject jsonResponse = new JSONObject(response); if (jsonResponse.has("data")) { JSONArray dataArray = jsonResponse.getJSONArray("data"); StationMetadata station = getOrFetchStationMetadata(stationId); for (int i = 0; i < dataArray.length(); i++) { JSONObject dataPoint = dataArray.getJSONObject(i); // NOAA format: {"year": "YYYY", "month": "MM", "MSL": "x.xxx"} int year = Integer.parseInt(dataPoint.getString("year")); int monthNumber = Integer.parseInt(dataPoint.getString("month")); double meanLevel = Double.parseDouble(dataPoint.getString("MSL")); LocalDate month = LocalDate.of(year, monthNumber, 1); MonthlyMeanData mmd = new MonthlyMeanData( stationId, station.getStationName(), month, meanLevel, year, monthNumber, station.getLatitude(), station.getLongitude() ); monthlyData.add(mmd); } } logger.info("Fetched {} monthly mean readings for station {}", monthlyData.size(), stationId); } catch (Exception e) { logger.error("Error fetching monthly mean data for station {}: {}", stationId, e.getMessage()); } return monthlyData; } /** * Get configured monitoring stations */ public List<StationMetadata> getConfiguredStations() { List<StationMetadata> stations = new ArrayList<>(); String[] stationConfigs = stationsConfig.split(";"); for (String config : stationConfigs) { String[] parts = config.split(","); if (parts.length >= 6) { StationMetadata station = StationMetadata.builder() .stationId(parts[0].trim()) .stationName(parts[1].trim()) .state(parts[2].trim()) .latitude(Double.parseDouble(parts[3].trim())) .longitude(Double.parseDouble(parts[4].trim())) .isActive(Boolean.parseBoolean(parts[5].trim())) .build(); stations.add(station); } } return stations; } /** * Get or fetch station metadata */ private StationMetadata getOrFetchStationMetadata(String stationId) { if (stationCache.containsKey(stationId)) { return stationCache.get(stationId); } // Return default station info if not in cache StationMetadata station = StationMetadata.builder() .stationId(stationId) .stationName("Station " + stationId) .latitude(40.0) // Default coordinates .longitude(-74.0) .build(); stationCache.put(stationId, station); return station; } /** * Make HTTP request to NOAA API */ private String makeHttpRequest(String urlStr) throws Exception { URL url = new URL(urlStr); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setRequestMethod("GET"); conn.setRequestProperty("User-Agent", "GridDB-CoastalMonitor/1.0"); int responseCode = conn.getResponseCode(); if (responseCode != 200) { throw new RuntimeException("HTTP Error: " + responseCode); } BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream())); StringBuilder response = new StringBuilder(); String line; while ((line = reader.readLine()) != null) { response.append(line); } reader.close(); String responseStr = response.toString(); logger.info("NOAA API Response for {}: {}", urlStr, responseStr); if (responseStr.trim().isEmpty()) { return "{}"; } return responseStr; } } Data Transformation and Persistence Layer Once raw data is acquired, it must be prepared for storage and analysis. This layer is dedicated to transforming the diverse incoming data into a standardized, clean, and enriched format, ensuring its integrity and usability within GridDB. The NOAA APIs provide data in various JSON structures. Before this data can be effectively stored and utilized in GridDB, it undergoes a transformation process. This ensures consistency, handles potential missing values, and converts raw measurements into a format optimized for our time-series database. Example NOAA API response structure: { "metadata": { "id": "8518750", "name": "The Battery", "lat": "40.7012", "lon": "-74.0137", "url": "https://tidesandcurrents.noaa.gov/stationhome.html?id=8518750" }, "data": [ { "t": "2025-08-23 10:00", "v": "0.193", "s": "0.000", "f": "0,0,0,0", "q": "p" } ] } The ingestion service performs automatic data type conversions, handles missing values through interpolation algorithms, and maintains data lineage for audit trails. For persistence, the transformed data is stored in GridDB using its REST-based API. Each record is written into a time-series container. The REST API allows applications to send JSON payloads directly to GridDB, where the data is indexed by timestamp and made available for queries and analysis. Interactive Visualization and Analytics Dashboard A powerful monitoring system is incomplete without a clear and intuitive way to visualize its data. Our interactive dashboard transforms raw oceanographic measurements into actionable insights, providing a dynamic view of coastal changes and trends. The dashboard retrieves data directly from GridDB, which efficiently serves time-series queries, ensuring that visualizations update quickly as new measurements arrive. Web Application Controller Layer The presentation tier implements RESTful endpoints serving both human-readable dashboards and machine-readable APIs for external system integration: package com.griddb.coastal.controller; import com.griddb.coastal.service.NOAADataService; import com.griddb.coastal.service.GridDBService; import com.griddb.coastal.service.DataSchedulerService; import com.griddb.coastal.model.StationMetadata; import org.json.JSONArray; import org.json.JSONObject; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.ResponseEntity; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.*; import java.util.List; @Controller public class DashboardController { private static final Logger logger = LoggerFactory.getLogger(DashboardController.class); @Autowired private NOAADataService noaaDataService; @Autowired private GridDBService gridDBService; @Autowired private DataSchedulerService schedulerService; /** * Main dashboard page */ @GetMapping("/") public String dashboard(Model model) { logger.info("Rendering main dashboard"); List<StationMetadata> stations = noaaDataService.getConfiguredStations(); model.addAttribute("stations", stations); model.addAttribute("title", "Watching Coastlines Vanish"); model.addAttribute("subtitle", "Real-time Coastal Monitoring with GridDB Time-Series"); return "dashboard"; } /** * Get latest water levels for a specific station (JSON API) */ @GetMapping("/api/water-levels/{stationId}") @ResponseBody public ResponseEntity<String> getWaterLevels(@PathVariable String stationId, @RequestParam(defaultValue = "24") int hours) { try { String data = gridDBService.queryLatestWaterLevels(stationId, hours); return ResponseEntity.ok(data); } catch (Exception e) { logger.error("Error fetching water levels for station {}: {}", stationId, e.getMessage()); return ResponseEntity.internalServerError().body("{"error": "" + e.getMessage() + "}"); } } /** * Get monthly trends for sea level rise analysis (JSON API) */ @GetMapping("/api/monthly-trends/{stationId}") @ResponseBody public ResponseEntity<String> getMonthlyTrends(@PathVariable String stationId, @RequestParam(defaultValue = "10") int years) { try { String data = gridDBService.queryMonthlyTrends(stationId, years); return ResponseEntity.ok(data); } catch (Exception e) { logger.error("Error fetching monthly trends for station {}: {}", stationId, e.getMessage()); return ResponseEntity.internalServerError().body("{"error": "" + e.getMessage() + "}"); } } /** * Get all stations metadata (JSON API) */ @GetMapping("/api/stations") @ResponseBody public ResponseEntity<List<StationMetadata>> getAllStations() { try { List<StationMetadata> stations = noaaDataService.getConfiguredStations(); return ResponseEntity.ok(stations); } catch (Exception e) { logger.error("Error fetching stations: {}", e.getMessage()); return ResponseEntity.internalServerError().build(); } } /** * Get aggregated data for all stations dashboard */ @GetMapping("/api/dashboard-data") @ResponseBody public ResponseEntity<String> getDashboardData() { try { JSONObject dashboardData = new JSONObject(); JSONArray stationsData = new JSONArray(); List<StationMetadata> stations = noaaDataService.getConfiguredStations(); for (StationMetadata station : stations) { JSONObject stationInfo = new JSONObject(); stationInfo.put("stationId", station.getStationId()); stationInfo.put("stationName", station.getStationName()); stationInfo.put("state", station.getState()); stationInfo.put("latitude", station.getLatitude()); stationInfo.put("longitude", station.getLongitude()); // Get latest water level String latestDataString = gridDBService.queryLatestWaterLevels(station.getStationId(), 1); JSONObject latestDataObject = new JSONObject(latestDataString); stationInfo.put("latestWaterLevel", latestDataObject); // Get monthly trend (last 2 years for quick overview) String trendDataString = gridDBService.queryMonthlyTrends(station.getStationId(), 2); JSONObject trendDataObject = new JSONObject(trendDataString); logger.info("Monthly Trend Data for {}: {}", station.getStationId(), trendDataObject.toString()); stationInfo.put("monthlyTrend", trendDataObject); stationsData.put(stationInfo); } dashboardData.put("stations", stationsData); dashboardData.put("lastUpdated", System.currentTimeMillis()); dashboardData.put("totalStations", stations.size()); return ResponseEntity.ok(dashboardData.toString()); } catch (Exception e) { logger.error("Error generating dashboard data: {}", e.getMessage()); return ResponseEntity.internalServerError().body("{"error": "" + e.getMessage() + "}"); } } /** * Manual data collection trigger (for testing/admin) */ @PostMapping("/api/trigger-collection") @ResponseBody public ResponseEntity<String> triggerDataCollection() { try { schedulerService.triggerDataCollection(); JSONObject response = new JSONObject(); response.put("status", "success"); response.put("message", "Data collection triggered successfully"); response.put("timestamp", System.currentTimeMillis()); return ResponseEntity.ok(response.toString()); } catch (Exception e) { logger.error("Error triggering data collection: {}", e.getMessage()); return ResponseEntity.internalServerError().body("{"error": "" + e.getMessage() + "}"); } } /** * Manual monthly data update trigger */ @PostMapping("/api/trigger-monthly-update") @ResponseBody public ResponseEntity<String> triggerMonthlyUpdate() { try { schedulerService.triggerMonthlyUpdate(); JSONObject response = new JSONObject(); response.put("status", "success"); response.put("message", "Monthly data update triggered successfully"); response.put("timestamp", System.currentTimeMillis()); return ResponseEntity.ok(response.toString()); } catch (Exception e) { logger.error("Error triggering monthly update: {}", e.getMessage()); return ResponseEntity.internalServerError().body("{"error": "" + e.getMessage() + "}"); } } /** * Health check endpoint */ @GetMapping("/api/health") @ResponseBody public ResponseEntity<String> healthCheck() { JSONObject health = new JSONObject(); health.put("status", "UP"); health.put("application", "Coastal Monitor"); health.put("timestamp", System.currentTimeMillis()); health.put("griddb", "Connected"); health.put("noaa", "Available"); return ResponseEntity.ok(health.toString()); } } The dashboard retrieves data from GridDB using paging-based REST APIs, which allow large time-series datasets to be read in smaller chunks. This makes queries efficient and ensures the visualizations can update smoothly as new measurements arrive. Application Deployment Build and Execution Pipeline Deploy the complete monitoring system using Maven’s integrated build lifecycle: $ mvn clean install && mvn spring-boot:run Access the operational dashboard through standard HTTP protocols: http://localhost:8080/. Once the system is running, it continuously fetches live data and updates the dashboards with real-time insights. This chart displays real-time and historical water level data, providing a clear visualization of coastal conditions. Specifically, it shows: Real-time Water Level (m): Instantaneous water level measurements over time, reflecting current tidal and environmental conditions. This data is crucial for immediate hazard detection, such as storm surges and unusually high tides, allowing for timely warnings and emergency responses to protect coastal communities and infrastructure. Monthly Mean Water Level (m): The average monthly sea level, which helps in identifying long-term trends and assessing sea level rise. By analyzing these long-term trends, coastal planners and scientists can understand the rate of sea level rise, predict future impacts, and develop strategies for climate adaptation, including land-use planning, infrastructure development, and ecosystem restoration. The combination of real-time and historical data provides a comprehensive view, enabling both immediate operational decisions and long-term strategic planning for coastal

Generate Fun AI Videos from a Photo with Kling
More
Table of Contents Prerequisites Node.js GridDB Fal Kling 2.1 API How to Run 1. Clone the repository 2. Install dependencies 3. Set up environment variables 4. Run the project 5. Open the application Architecture Technical Implementations Camera Captures Image Prompt Generate Video Kling 2.1 from Fal 1. Initiating polling 2. Checking the job status 3. Call the API endpoint for a status check 4. Handling video when the status is complete API Routes Saving Data to GridDB Read Data from GridDB User Interface What This Blog is About Using your camera to capture memorable moments or interesting objects, then transforming them into creative, stylized video clips with AI, is an exciting way to engage users and demonstrate the power of modern technology. In this guide, we build a developer-friendly pipeline using Next.js for the frontend, Fal.ai as a serverless inference runtime, Kling AI for video generation, and GridDB Cloud for real-time metadata storage. We’ll walk through how to capture frames from the webcam, send them to Kling for enhancement, log metadata (image URL, applied effects, which is the prompt, and generated video URL) to GridDB, and render the final video. Prerequisites Node.js This project is built using Next.js, which requires Node.js version 16 or higher. You can download and install Node.js from https://nodejs.org/en. GridDB Sign Up for GridDB Cloud Free Plan If you would like to sign up for a GridDB Cloud Free instance, you can do so at the following link: https://form.ict-toshiba.jp/download_form_griddb_cloud_freeplan_e. After successfully signing up, you will receive a free instance along with the necessary details to access the GridDB Cloud Management GUI, including the GridDB Cloud Portal URL, Contract ID, Login, and Password. GridDB WebAPI URL Go to the GridDB Cloud Portal and copy the WebAPI URL from the Clusters section. It should look like this: GridDB Username and Password Go to the GridDB Users section of the GridDB Cloud portal and create or copy the username for GRIDDB_USERNAME. The password is set when the user is created for the first time. Use this as the GRIDDB_PASSWORD. For more details, to get started with GridDB Cloud, please follow this quick start guide. IP Whitelist When running this project, please ensure that the IP address where the project is running is whitelisted. Failure to do so will result in a 403 status code or forbidden access. You can use a website like What Is My IP Address to find your public IP address. To whitelist the IP, go to the GridDB Cloud Admin and navigate to the Network Access menu. Fal Kling 2.1 API You need a Kling 2.1 API key to use this project. You can sign up for an account at fal.ai. After signing up, go to the Account section, and create and copy your API key. Kling 2.1 is the latest version of Kling AI’s text/image-to-video generation engine, released in May 2025 by Kuaishou (also known as Kwai). It’s a significant upgrade from Kling 1.6 and 2.0, bringing smoother motion, sharper visuals, stronger prompt adherence, faster speeds, and better cost efficiency. How to Run 1. Clone the repository Clone the repository from https://github.com/junwatu/camtovid-ai to your local machine. $ git clone https://github.com/junwatu/camtovid-ai $ cd camtovid-ai $ cd apps 2. Install dependencies This project uses Bun for installing package dependencies. You can download Bun from https://bun.sh. $ bun install 3. Set up environment variables Copy file .env.example to .env and fill in the values: # Copy this file to .env.local and add your actual API keys # Never commit .env.local to version control # Fal.ai API Key for Kling 2.1 # Get your key from: https://fal.ai/dashboard FAL_KEY= GRIDDB_WEBAPI_URL= GRIDDB_PASSWORD= GRIDDB_USERNAME= Please look at the section on Prerequisites before running the project. 4. Run the project Run the project using the following command: $ npm run dev 5. Open the application Open the application in your browser at http://localhost:3000. You also need to allow the browser to access your camera. If you access the web application from a mobile device, there will be an option to select between the rear and back camera. Architecture The architecture and user flow are intentionally simple for rapid development and ease of use. Users access the app from any desktop or mobile browser. After capturing an image with their device’s camera, they enter a prompt describing the video they want to generate. The Next.js frontend sends both the image and prompt to Fal AI’s Kling 2.1 model. Kling 2.1 processes these inputs, generates a video, and returns it directly to the browser client. When generation is done, the metadata: image URL, prompt, and generated video URL will be saved to the GridDB Cloud. Technical Implementations Camera Captures The use-camera.ts is a useCamera custom hook, which encapsulates all the logic for controlling the camera, including starting, stopping, switching, and capturing a photo. The capturePhoto function is the one that actually captures the image from the video stream and returns it as a base64-encoded JPEG. // … existing code … const capturePhoto = useCallback(() => { if (videoRef.current && canvasRef.current) { const canvas = canvasRef.current const video = videoRef.current const context = canvas.getContext('2d') canvas.width = video.videoWidth canvas.height = video.videoHeight if (context) { context.drawImage(video, 0, 0) const imageData = canvas.toDataURL('image/jpeg') stopCamera() optionsRef.current.onSuccess?.('Photo captured successfully') return imageData } } optionsRef.current.onError?.('Failed to capture photo') return null }, [stopCamera]) // … existing code … The app/page.tsx is the main page component. It uses the useCamera hook to get the capturePhoto function and other camera-related state and methods. The handleCapturePhoto function is called when the user clicks the capture button. This function calls capturePhoto from the hook and then updates the application state with the captured image data. // … existing code … // Handle photo capture const handleCapturePhoto = () => { const imageData = capturePhoto() if (imageData) { setCapturedImage(imageData) setState('captured') } } // … existing code … Image Prompt In the app/page.tsx, there is a prompt input that only shows after a photo has been captured (state === ‘captured’). // … existing code … {/* Prompt Input Section – Only show after photo is captured */} {(state === "captured" || state === "generating" || state === "completed") && ( <div> <div className="space-y-2"> <Label htmlFor="prompt" className="text-lg font-semibold"> 2. Enter Your Creative Prompt </Label> <Textarea id="prompt" placeholder="e.g., a majestic lion roaring on a cliff, cinematic lighting" value={prompt} onChange={(e) => setPrompt(e.target.value)} className="min-h-[80px] text-base" disabled={state === "generating"} /> </div> </div> )} </TabsContent> <TabsContent value="video" className="p-6"> <div className="space-y-6"> {/* Video and Generation status */} // … existing code … Along with the capturedImage, this prompt will be used to generate video. This will happen if the user clicks the Generate Video button. Generate Video Kling 2.1 API from the Fal needs two main parameters: Image reference, which is the image the user captured from the camera Prompt for the video creation. Before the video generation, the captured image needed to be saved first. In this app, we use Fal server to save the captured image. // … existing code … static async uploadImage(imageData: string): Promise<ImageUploadResponse> { try { // Convert data URL to blob const response = await fetch(imageData); const blob = await response.blob(); // Create form data const formData = new FormData(); formData.append('file', blob, 'captured-image.jpg'); const uploadResponse = await fetch(`${this.baseUrl}/upload-image`, { method: 'POST', body: formData, }); // … existing code … The upload process is handled by the /api/upload-image endpoint. This route uses the Fal.ai client (@fal-ai/client) to upload it to Fal.ai’s storage. It then returns the public URL of the uploaded image. // … existing code … import { fal } from '@fal-ai/client'; // … existing code … // Upload file to Fal.ai storage const uploadUrl = await fal.storage.upload(file); return NextResponse.json({ success: true, url: uploadUrl, file_name: file.name }); // … existing code … After successfully uploading an image and we get the image URL, the useVideoGeneration hook will call VideoSeevice.generateVideo, passing the image URL and the user’s prompt: // … existing code … setUploadedImageUrl(uploadResult.url) // Start video generation setState('generating') setGenerationStatus('initializing') const result = await VideoService.generateVideo({ image_url: uploadResult.url, prompt: prompt, }) // … existing code … The generateVideo will call the /api/generate-video endpoint, which in turn calls the Fal.ai Kling AI model to start the video generation job. Kling 2.1 from Fal The AI model we use to generate video is Kling 2.1. Like other models on Fal, it is best accessed asynchronously. After the video generation job is submitted to Fal.ai, the application enters a monitoring phase to wait for the video to be ready. This is handled by polling for the result in an asynchronous process. Here, step by step, is implemented in this app until the video is ready: 1. Initiating polling. The useVideoGeneration hook in hooks/use-video-generation.ts doesn’t just fire and forget. After submitting the job and getting a request_id, it starts a polling mechanism to repeatedly check the status of the generation job. // … existing code … if (result.success && result.request_id) { const imageUrl = uploadResult.url // Polling function const poll = async () => { try { const videoResult = await VideoService.getVideoResult(result.request_id!) const status = (videoResult as any).status setGenerationStatus(status) options.onStatusChange?.(status) if (status === 'COMPLETED') { // … existing code … } else if (status === 'FAILED' || status === 'CANCELLED') { // … existing code … } else { // Continue polling setTimeout(poll, pollInterval) } } catch (error) { // … existing code … } } poll() } // … existing code … 2. Checking the job status. The poll function calls VideoService.getVideoResult, which is responsible for fetching the latest status of the video generation job. // … existing code … /** * Get the result of a video generation task */ static async getVideoResult(requestId: string): Promise<VideoResultResponse> { try { const response = await fetch(`${this.baseUrl}/get-video?request_id=${requestId}`); const result = await response.json(); if (!response.ok) { throw new Error(result.error || 'Failed to get video result'); } return result; } catch (error) { return { success: false, error: 'Failed to process request', details: error instanceof Error ? error.message : 'Unknown error' }; } } // … existing code … 3. Call the API endpoint for a status check. The VideoService calls the /api/get-video endpoint. This endpoint uses the fal-ai client library to get the status of the job from Fal.ai using the request_id. // … existing code … export async function GET(request: NextRequest) { try { const { searchParams } = new URL(request.url) const requestId = searchParams.get('request_id') if (!requestId) { return NextResponse.json( { error: 'Missing request_id parameter' }, { status: 400 } ); } const result = await fal.queue.get(requestId); return NextResponse.json(result); } catch (error) { return NextResponse.json( // … existing code … 4. Handling video when the status is complete. Once the polling mechanism receives a COMPLETED status, the useVideoGeneration hook updates the application state with the generated video’s URL and calls the onSuccess callback that was passed to it from the main page component. // … existing code … if (status === 'COMPLETED') { const generatedVideoUrl = (videoResult as any).data.data.video.url setGeneratedVideo(generatedVideoUrl) setState('completed') setIsLoading(false) setGenerationStatus(null) options.onSuccess?.(generatedVideoUrl, imageUrl, prompt) } // … existing code … Once the video generation is complete, the video will be displayed in the Generated Video UI tab. More on this in the User Interface section. API Routes This web app exposed some API. Here is a table summarizing all the API routes used in this web application, along with their HTTP methods and descriptions. Route HTTP Method Description /api/upload-image POST Receives an image file from the client and uploads it to Fal.ai’s temporary storage, returning a URL. /api/generate-video POST Submits a job to the Fal.ai Kling AI model to generate a video using an image URL and a text prompt. /api/get-video GET Polls the Fal.ai service to check the status of a video generation job using its request_id. /api/save-data POST Saves the metadata for a generated video (image URL, prompt, video URL) into the GridDB database. Saving Data to GridDB After the video generation is completed, the app will save the metadata to GridDB Cloud. This saves the metadata of the generated video (the original image URL from Fal.ai, the user’s prompt, and the new video URL) to your GridDB database. So, here is the data schema used in the database that you can find in the lib/types/griddb.types.ts file: // Types for container data export interface GridDBData { id: string | number; imageURL: string; prompt: string; generatedVideoURL: string; } The sava data happening in the app\page.tsx main component: // … existing code … // Video generation management const { // … existing code … } = useVideoGeneration({ onSuccess: async (videoUrl, imageUrl, promptText) => { setState('completed') setActiveTab('video') // … existing code … // Auto-save data const saved = await saveData({ imageURL: imageUrl, prompt: promptText, generatedVideoURL: videoUrl, }) // … existing code … This saveData function calls the /api/save-data endpoint to perform the database operation. Read Data from GridDB The GET method in the /api/save-data/route.ts file is responsible for fetching all records from the database. Here’s how it works: // … existing code … // Optional: Add GET method to retrieve data export async function GET(request: NextRequest) { try { const { searchParams } = new URL(request.url); const id = searchParams.get('id'); const limit = searchParams.get('limit') || '10'; // … existing code … let query; if (id) { // Search for specific ID query = { type: 'sql-select', stmt: `SELECT * FROM camvidai WHERE id = ${parseInt(id)}` }; } else { // Get recent entries query = { type: 'sql-select', stmt: `SELECT * FROM camvidai ORDER BY id DESC LIMIT ${parseInt(limit)}` }; } const result = await dbClient.searchData([query]); // … existing code … This GET function handles two cases: Fetch by ID: If an id is provided as a query parameter (e.g., /api/save-data?id=123), it fetches that specific record. Fetch All (Recent): If no id is provided, it fetches the most recent entries from the camvidai container, ordering them by ID in descending order. It defaults to a limit of 10 records, but this can be changed with a query parameter (e.g., /api/save-data?limit=50). So, to get all the data (or at least the most recent set), you would make a GET request to /api/save-data. User Interface The user interface is built using Next.js. It has three main views: Capture Tab. Prompt Input (shows only after image captured). Generated Video Tab. In essence, the UI is a wizard-like workflow that moves the user through a linear sequence: Capture -> Prompt -> Generate -> View Video. The best way to get to know the user interface is to try it yourself! ☺️ However, here is a demo so you can see what the app looks
Building a Smarter Book Inventory using Vaadin and Spring AI
More
Here is a project showcasing a simple yet powerful project: a smarter website for managing book collections. In this post, we’re going to build this web application from the ground up. We will use Spring Boot, Spring AI, Vaadin Flow to create it. And we will store the data in the cloud using GridDB Cloud. Core Features So, what exactly are we building? Let’s break it down. Importing Books from CSV A common and easy way to get a list of existing books is often from a CSV file. Think of a simple spreadsheet with columns like `Title` and `Author`. We will build a small part of the application to read this CSV file. This `parser` will read lines, split them by commas, and create `Book` object with `title`, `authors`, `publisher`, and `rating`. This will serve as our initial dataset in the database. It’s the first step before adding more exciting features. AI Enrichment Once we have the initial dataset, we’ll take each book record and look up it’s genre and a brief summary. We’ll use Spring AI to send request to the Open AI API. Then, we’ll read the response, extract the genre and summary, and update the book data. Based on the above features we need the following components: A web interface for listing books, upload the CSV, and book detail page where user ask the AI to update book’s genre and summary by clicking a button. We will develop this UI using Vaadin Flow. CSV parser component An AI Enrichment Service that uses Spring AI to interact with LLM model. A NoSQL Database Service to interact with GridDB Cloud API. We will use Spring `RestClient` to handle the `request` and `response`. This will also convert Java `record` into `HTTP` body according to the API specifications. Tech Stack For this project, I selected: Spring Boot Spring Boot streamlines development with auto-configuration, an embedded server, and starter dependencies. This effortless setup accelerates our ability to build and launch applications swiftly. Vaadin Flow Vaadin Flow serves as a versatile Java UI framework, allowing us to construct web applications purely in Java. This approach simplifies our process by minimizing the hassle of juggling separate frontends. Packed with a treasure trove of pre-built components, Vaadin is tailor-made for data-rich business applications, ensuring users enjoy a seamless experience. Spring AI Spring AI is a powerful extension of the Spring Framework. It empowers Java developers to craft AI-driven applications with minimal reskilling required. By tapping into the strengths of the Spring Framework, Spring AI opens the door to advanced AI features, simplifying the journey to creating intelligent apps. GridDB Cloud GridDB Cloud is a fully managed, cloud-based database offered by GridDB, designed to store and process massive volumes of time-series data in real-time. Read this quick start guide to learn how to use GridDB Cloud. You can sign up for a GridDB Cloud Free instance at this link: https://form.ict-toshiba.jp/downloadformgriddbcloudfreeplan_e. Create a new Vaadin Project To create a Vaadin Flow project, go to start.vaadin.com. This starter project has a basic application with a fully-functional end-to-end workflow. Choose a pure Java option with Vaadin Flow. Click the download button, then unzip and open the project into your favorite IDE. You should now see a typical Maven project as shown below: $ ├───.mvn $ ├── mvnw $ ├── mvnw.cmd $ ├── pom.xml $ ├── README.md $ ├───src $ │ ├───main $ │ │ ├───frontend $ │ │ ├───java $ │ │ └───resources $ │ └───test $ │ ├───java $ │ └───resources Data Access Next, we need a domain object to hold the Book data as follow: public record Book(String id, String title, String authors, String publisher, Double rating, String genres, String summary, Long goodreadsBookId, String goodreadsUrl) { public Book(String id, String title, String authors, String publisher, Double rating, String genres, String summary, Long goodreadsBookId) { this(id, title, authors, publisher, rating, genres, summary, goodreadsBookId, null); } } Next, we create a `BookService.java` class to fetch and store data. Also to pass data to the presentation layer. @Service public class BookService { private final BookContainer bookContainer; public BookService(BookContainer bookContainer) { this.bookContainer = bookContainer; } public List listBooks() { return this.bookContainer.getBooks(); } public Book getBook(String id) { Book book = this.bookContainer.getBook(id); if (book == null) { throw new IllegalArgumentException(“Book with ID ” + id + ” does not exist.”); } return book; } public void createTableBooks() { this.bookContainer.createTableBooks(); } public void saveBooks(List books) { if (books == null || books.isEmpty()) { return; } List newBooks = books.stream().map(book -> { String id = (book.id() != null) ? book.id() : nextId(); return new Book(id, book.title(), book.authors(), book.publisher(), book.rating(), book.genres(), book.summary(), book.goodreadsBookId(), book.goodreadsUrl()); }).collect(Collectors.toList()); this.bookContainer.saveBooks(newBooks); } public static String nextId() { return “book_” + TsidCreator.getTsid().format(“%S”); } } The `saveBooks()` method accept a list of books. Both creating a new book and updating a book will use this method. We generate the book’s ID using Time-Sorted Unique Identifiers (TSID). Next, we create the `BookContainer.java` to interact with the database API: @Service public class BookContainer { private final GridDbCloudClient gridDbCloudClient; private static final String BOOKSTBLNAME = “Books”; public BookContainer(GridDbCloudClient gridDbCloudClient) { this.gridDbCloudClient = gridDbCloudClient; } public void createTableBooks() { List columns = List.of(new GridDbColumn(“id”, “STRING”, Set.of(“TREE”)), new GridDbColumn(“title”, “STRING”), new GridDbColumn(“authors”, “STRING”), new GridDbColumn(“publisher”, “STRING”), new GridDbColumn(“rating”, “DOUBLE”), new GridDbColumn(“genres”, “STRING”), new GridDbColumn(“summary”, “STRING”), new GridDbColumn(“goodreadsBookId”, “LONG”), new GridDbColumn(“goodreadsUrl”, “STRING”)); GridDbContainerDefinition containerDefinition = GridDbContainerDefinition.createContainer(BOOKSTBLNAME, columns); this.gridDbCloudClient.createContainer(containerDefinition); } } `GridDbCloudClient`: to communicate with the GridDB Cloud database. Provided automatically by Spring Boot through constructor-based dependency injection. `BOOKSTBLNAME`: table name as a constant. `createTableBooks()`: create a `Books` table (`collection`) in GridDB Cloud database to hold records for our books. This method started by creating a `List` of `GridDBColumn` objects. Each object describes one column with data type. Then create the container definition and use the `GridDbCloudClient` to actually create the table. public class GridDbCloudClient { private final RestClient restClient; public GridDbCloudClient(String baseUrl, String authToken) { this.restClient = RestClient.builder().baseUrl(baseUrl).defaultHeader(“Authorization”, “Basic ” + authToken) .defaultHeader(“Content-Type”, “application/json”).defaultHeader(“Accept”, “application/json”) .build(); } public void createContainer(GridDbContainerDefinition containerDefinition) { try { restClient.post().uri(“/containers”).body(containerDefinition).retrieve().toBodilessEntity(); } catch (Exception e) { throw new GridDbException(“Failed to create container”, HttpStatusCode.valueOf(500), e.getMessage(), e); } } } The `GridDbCloudClient` class is a Java client for interacting with the GridDB Cloud Web API. It provides methods for creating containers, registering rows, acquiring rows, and executing POST requests. We set `RestClient` up with a base URL and a basic authorization header so that it could connect to the GridDB Cloud Web API and authenticate. //BookContainer.java public void saveBooks(List books) { StringBuilder sb = new StringBuilder(); sb.append(“[“); for (int i = 0; i < books.size(); i++) { Book book = books.get(i); sb.append("["); sb.append("\"").append(book.id()).append("\""); sb.append(", "); sb.append("\"").append(book.title()).append("\""); sb.append(", "); sb.append("\"").append(book.authors()).append("\""); sb.append(", "); sb.append("\"").append(book.publisher()).append("\""); sb.append(", "); sb.append(book.rating()); sb.append(", "); sb.append("\"").append(book.genres() != null ? book.genres() : "").append("\""); sb.append(", "); sb.append("\"").append(book.summary() != null ? book.summary() : "").append("\""); sb.append(", "); sb.append(book.goodreadsBookId()); sb.append(", "); sb.append("\"").append(book.goodreadsUrl() != null ? book.goodreadsUrl() : "").append("\""); sb.append("]"); if (i < books.size() - 1) { sb.append(", "); } } sb.append("]"); String result = sb.toString(); this.gridDbCloudClient.registerRows(BOOKSTBLNAME, result); } `saveBooks(List books)`: designed to receieve a List of Book objects and save them into the `Book` collection created earlier. First, format the list into a specialized string representation of an array of arrays, and then uses the GridDB client to send this formatted string to save all the book records in the database. An illustration of the request body used to register rows into a container: [ ["abf8e412", "The Ultimate Hitchhiker's Guide to the Galaxy", "Douglas Adams", "Del Rey Books", 4.37, "", "", 13], ["5f8bdef1", "The Lost Continent: Travels in Small Town America", "Bill Bryson", "William Morrow Paperbacks", 3.83, "", "", 26] ] Getting books from GridDB Cloud Cloud. //BookContainer.java public List getBooks() { AcquireRowsRequest requestBody = AcquireRowsRequest.builder().limit(50L).build(); AcquireRowsResponse response = this.gridDbCloudClient.acquireRows(BOOKSTBLNAME, requestBody); if (response == null || response.getRows() == null) { return List.of(); } List books = convertResponseToBook(response); return books; } Build the Request body by creating a `AcquireRowsRequest` object, tells GridDB how many rows I want to get. Use the `gridDbCloudClient.acquireRows(BOOKSTBLNAME, requestBody)` to send request to the API. Check if the response is null or if there are no rows in the response. If everything is okay, convert the database response into a list of `Book` object and return it. Converting raw data to `Book` objects. //BookContainer.java private List convertResponseToBook(AcquireRowsResponse response) { List books = response.getRows().stream().map(row -> { try { var book = new Book(row.get(0).toString(), row.get(1).toString(), row.get(2).toString(), row.get(3).toString(), Optional.ofNullable(row.get(4)).map(Object::toString).map(Double::valueOf).orElse(null), Optional.ofNullable(row.get(5)).map(Object::toString).orElse(null), Optional.ofNullable(row.get(6)).map(Object::toString).orElse(null), Optional.ofNullable(row.get(7)).map(Object::toString).map(Long::valueOf).orElse(null), Optional.ofNullable(row.get(8)).map(Object::toString).orElse(null)); return book; } catch (Exception e) { return null; } }).filter(book -> book != null).toList(); return books; } Using Java Streams to process each row from the database. For each row, create a new `Book` object. The database returns data as a list where each position represents a different field. Check for null values and handle errors gracefully. CSV Parser for Goodreads Book In this project we are going to use Goodreads book dataset. Goodreads is the world’s largest site for readers and book recommendations. The book sample in CSV: Id,Name,RatingDist1,pagesNumber,RatingDist4,RatingDistTotal,PublishMonth,PublishDay,Publisher,CountsOfReview,PublishYear,Language,Authors,Rating,RatingDist2,RatingDist5,ISBN,RatingDist3 1339,”Loving and Dying: A Reading of Plato’s Phaedo, Symposium, and Phaedrus”,1:0,288,4:2,total:5,12,11,University Press of America,0,2001,,Richard Gotshalk,4.6,2:0,5:3,0761820728,3:0 Why creating a custom Parser? > Because this CSV data contain commas within the actual data. //GoodReadBookCSVParser.java try (BufferedReader reader = new BufferedReader(new InputStreamReader(is, StandardCharsets.UTF_8))) { String line; boolean isFirst = true; while ((line = reader.readLine()) != null) { if (isFirst) { isFirst = false; continue; } String[] fields = parseCsvLine(line); //assign parser result into each field Book book = new Book(null, title, authors, publisher, rating, null, null, goodreadsBookId); books.add(book); } } The parser receive `InputStream` and wrap it into `BufferedReader`, buffering characters to efficiently read characters, arrays, and lines. We use a `Try-with-resource` block to ensure the File resource gets closed properly, even if something goes wrong. Also specify UTF-8 encoding to handle special characters correctly. //GoodReadBookCSVParser.java private String[] parseCsvLine(String line) { List result = new ArrayList(); boolean inQuotes = false; StringBuilder sb = new StringBuilder(); for (int i = 0; i < line.length(); i++) { char c = line.charAt(i); if (c == '"') { inQuotes = !inQuotes; } else if (c == ',' && !inQuotes) { result.add(sb.toString()); sb.setLength(0); } else { sb.append(c); } } result.add(sb.toString()); return result.toArray(new String[0]); } `parseCsvLine()`: goes through each character one by one. Tracking whether currently inside a quoted field. When there is a comma, only treat it as a field separator if NOT inside quotes. Creating Vaadin views and layouts Because this project was generated using Vaadin Start, we got a fully functional application that can be easily extended and customized. So, we will add new view by following the existing structure. $ com.company $ ├───base $ │ └───ui $ │ ├───component $ │ └───view $ └───bookinventory $ ├───domain $ ├───seeder $ ├───service $ └───ui $ └───view $ BookDetailView.java $ BookListView.java Now, let's add `BookListView` component to display all books. //BookListView.java @Route("book-list") @PageTitle("Book List") @Menu(order = 0, icon = "vaadin:book", title = "Book List") public class BookListView extends Main { private final Logger log = LoggerFactory.getLogger(getClass()); private final BookService bookService; private final Grid bookGrid; } `@Route("book-list")` : defined a Flow view that can be accessed at `htt://localhost:8080/book-list`. `@Menu`: make a Flow view appear in the menu. Use `BookService` to get list of books and to save uploaded books from CSV Vaadin `Grid` to display tabular data of books. A component for uploading a CSV file as shown at BookListView.java Next, adding `BookDetailView`. From the book list, we click one of the book titles, then navigate to the book detail. @Route("book-detail") @PageTitle("Book Detail") public class BookDetailView extends VerticalLayout implements HasUrlParameter { private final BookService bookService; private FormLayout content; private String bookId; private Button fetchGenreBtn; private ProgressBar progressBar; private NativeLabel progresLabel; private Button fetchSummaryBtn; public BookDetailView(BookService bookService) { this.bookService = bookService; fetchGenreBtn.addClickListener(e -> { var ui = UI.getCurrent(); Book book = getCurrentBook(); progresLabel.setVisible(true); progresLabel.setText(“Asking AI for ” + book.title() + “…”); progressBar.setVisible(true); progressBar.setIndeterminate(true); bookService.asyncGenerateGenre(book.id(), ui.accessLater(this::onJobCompleted, null), ui.accessLater(progressBar::setValue, null), ui.accessLater(this::onJobFailed, null)); }); } } Extends `VerticalLayout`, so all components added will be shown vertically. Implements `HasUrlParameter`, so the page can receive a book ID from the URL. We use `BookService` to fetch the book from database, call the AI assistant, and update the book data. The `content` form layout will show book details. When the `fetchGenreBtn` button clicked, we show a progress bar while the `bookService` starting the AI task. Spring AI Integration Our book data is ready in the database and we can access it through the listing and details page. Now it is time to enhance the functionality by integrating AI. We’re going to dive into how we can use AI to automatically figure out the genre and write a concise summary for each book. Before we dive into the “how”, let’s talk about an important part: Large Language Models (LLM). These are powerful AI systems (like OpenAI’s GPT models) that can understand and create human-like text. They let us “ask” for a book’s genre or summary. Now, we need to connect to these AI models. This is where Spring AI comes in as our best friend. Spring AI simplifies how we work with LLMs. We don’t have to send raw HTTP requests to OpenaI. Spring AI handles all that heavy lifting. It provides a consistent way to interact with different LLM provider. So, whether we’re using OpenAI today or decide to switch to Google Gemini tomorrow, our code for making AI calls remains largerly the same. Include Spring AI dependency in our `pom.xml`: 1.0.0-SNAPSHOT org.springframework.ai spring-ai-starter-model-openai ${spring-ai.version} Configure API Key: # The OpenAI API key to use spring.ai.openai.api-key=${OPENAIAPIKEY} The default OpenAI model to use spring.ai.openai.model=${OPENAI_MODEL: gpt-4o-mini} Configure `ChatClient`: @Configuration public class ChatClientConfig { @Bean public ChatClient chatClient(ChatClient.Builder chatClientBuilder) { return chatClientBuilder.build(); } } Create a `BookAssistant.java` for sending book data into LLM and return the response. This class called by `BookService`. public BookAIReply findBookGenre(String title, String authors) { BookAIReply reply = chatClient.prompt() .user(user -> user.text(“What is the genre of the book {title} by {authors}. Provide the source url.”) .param(“title”, title).param(“authors”, authors)) .call().entity(BookAIReply.class); return reply; } public BookAIReply findBookSummary(String title, String authors) { BookAIReply reply = chatClient.prompt() .user(user -> user.text(“What is the summary of the book {title} by {authors}. Provide the source url.”) .param(“title”, title).param(“authors”, authors)) .call().entity(BookAIReply.class); return reply; } We use zero-shot prompting techniques. The zero-shot prompt directly instructs the model to perform a task without any additional examples to steer it. `chatClient.prompt()` Starts building a prompt for the AI model. `.user(user -> user.text(…).param(…))` – Defines the user message for the prompt. – User Role: Represents the user’s input – their questions, commands, or statements to the AI. – `user.text(…)` sets the message template, using placeholders (`{title}`, `{authors}`). – `.param(“title”, title)` and `.param(“authors”, authors)` inject the actual values into the template. `.call()` Executes the prompt, sending it to the AI model. `.entity(BookAIReply.class)` Maps the AI’s response to a `BookAIReply` Java object, making it easy to work with structured data. This method chain provides a fluent, type-safe way to interact with AI models using Spring AI, abstracting away the complexity of prompt construction and response parsing. The same pattern is used for other methods. And finally wire in the `BookAssistant` component into the `BookService`. BookAIReply reply = bookAssistant.findBookSummary(book.title(), book.authors()); String summary = reply.value(); String sourceUrl = reply.sourceUrl(); You can find the code for this article on Github and run the application from the command line with Maven. GridDB Cloud query output. Summary In this article, we have built a web application without touching a single line of JavaScript or HTML. We achieved this by combining Vaadin with Spring Boot. What’s more, we make it even smarter by integrating Spring AI, giving it intelligent capabilities. Future enhancements: Adding data filtering Use pagination or lazy loading. Evaluate generative AI output. Enable natural language queries for book searches with semantic search. Add a voice assistant that responds to user

GridDB IoT Hackathon Recap (Part 1 of 2): The Online Idea Phase
More
Hackathon Gallery Introduction Over the last few months of 2025, GridDB held what is known as a hackathon, to really highlight the versatility and productiveness of GridDB Cloud. The prompt of the event was simple: use the power of GridDB Cloud to build any sort of app you want; the webpage for the event made mentions of IoT, but really the prompt was open and users could submit ideas based on any personal interests or expertise. The event (officially titled as the GridDB IoT Hackathon) had two distinct phases: the aforementioned online phase, where teams of 2-5 could submit their ideas with no coding necessary, just a basic blueprint of how they would plan to implement their idea. The next phase of the event would be an all-out in-person event hosted in Bengaluru, India for the top 5 teams, decided by the judging panel. And as exciting as the in-person event was, we will save that portion for another day. For today’s article, we will focus on the online portion of the event. And now, for some numbers. We had over 250 participants sign up for the event through the online portal. From there, we had 28 teams submit their ideas. We had ideas ranging from health, to finance, to on-the-field sensors for a variety of different purposes. All-in-all, we were very impressed and flattered at the breadth and range of project ideas submitted by the wonderful GridDB community. Due to technical issues, we lost access to the original hackathon portal, but we have re-created the gallery for all to see here: Hackathon Gallery. Please be on the lookout for the next article where we will showcase the 5 submissions which graduated on to the finalist round where we hosted an event in Bengaluru,
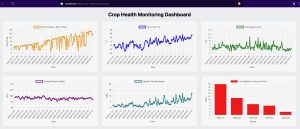
Precision Agriculture with GridDB
More
Introduction As global populations grow, agriculture faces mounting pressure to produce more food sustainably. Precision agriculture, powered by IoT and real-time data analytics, offers a solution by optimizing crop management through actionable insights. However, traditional relational databases struggle with the velocity and volume of agricultural time-series data, creating performance bottlenecks when farmers need immediate analysis of crop conditions, weather patterns, and soil metrics. GridDB’s specialized time-series architecture addresses these challenges through efficient storage, high-speed ingestion, and optimized query performance for temporal data patterns. Its ability to handle mixed-frequency sensor data—from hourly weather readings to daily satellite imagery—makes it particularly well-suited for agricultural monitoring systems. This article explores a simple Spring Boot application that leverages GridDB Cloud to monitor crop health predicatively. Our implementation integrates real-time weather data from NASA’s POWER API, stores environmental time-series in GridDB, and exposes analytics through REST APIs for dashboard visualization. Time-Series Database Requirements for Agricultural IoT An ideal time-series database platform must efficiently ingest, store, and analyze data from diverse sources to enable data-driven decisions in crop health monitoring, irrigation management, and yield prediction. Meeting these demands involves addressing several critical data characteristics and infrastructure requirements, such as: High Cardinality Numerous unique time series generated by varied sensor types, farm locations, and devices. Multi-Frequency Data Streams Environmental sensors: Updates every 15 minutes. Weather APIs: Typically provide hourly updates. Satellite imagery: Collected daily or at intervals of 1 to 7 days. Sensor Metrics Each sensor point typically captures four distinct metrics (e.g., temperature, humidity, soil moisture, and light intensity). Ingestion Volume Per farm: 100 sensors × 4 metrics × 96 readings/day = ~38,400 records daily. Across 500+ farms: 500 farms × ~38.4K records = ~19 million inserts per day. Timestamp Precision Data is recorded with microsecond-level precision to support fine-grained temporal analysis. Query and Storage Requirements Optimized for frequent time-based queries (e.g., daily or weekly trends). Requires efficient data compression and long-term retention strategies to manage continuous high-volume ingestion. These patterns demand a robust time-series database like GridDB, designed to handle high-ingest rates, granular timestamps, and complex queries, all essential for scalable agricultural IoT solutions. Project Overview: Building the Predictive Crop Health Monitoring Farmers In this project, we focus on real-time crop health monitoring by processing environmental data and displaying important insights through visual dashboards, built with Spring Boot, GridDB Cloud, Thymeleaf, and Chart.js. System Workflow Collection Fetches environmental metrics from NASA’s POWER API. Storage Stores data in GridDB using a time-series model (CropHealthData container). Analysis Processes raw data into actionable stress indicators using CropHealthService Visualization Displays daily, weekly, and monthly trends on a web-based dashboard. Setting Up GridDB Cluster and Spring Boot Integration Project Structure Here’s a suggested project structure for this application: ├── pom.xml ├── src │ ├── main │ │ ├── java │ │ │ └── mycode │ │ │ ├── controller │ │ │ │ └── CropHealthController.java │ │ │ ├── dto │ │ │ │ └── CropHealthData.java │ │ │ ├── MySpringBootApplication.java │ │ │ └── service │ │ │ ├── CollectionService.java │ │ │ ├── CropHealthService.java │ │ │ └── RestTemplateConfig.java │ │ └── resources │ │ ├── application.properties │ │ └── templates │ │ └── dashboard.html This structure separates controllers, models, repositories, services, and the application entry point into distinct layers, enhancing modularity and maintainability. It can be further customized based on individual requirements. Set Up GridDB Cloud For this exercise, we will be using GridDB Cloud vesion. Start by visiting the GridDB Cloud portal and signing up for an account. Based on requirements, either the free plan or a paid plan can be selected for broader access. After registration, an email will be sent containing essential details, including the Web API URL and login credentials. Once the login details are received, log in to the Management GUI to access the cloud instance. Create Database Credentials Before interacting with the database, we must create a database user: Navigate to Security Settings: In the Management GUI, go to the “GridDB Users” tab. Create a Database User: Click “Create Database User,” enter a username and password, and save the credentials. For example, set the username as soccer_admin and a strong password. Store Credentials Securely: These will be used in your application to authenticate with GridDB Cloud. Set Allowed IP Addresses To restrict access to authorized sources, configure the allowed IP settings: Navigate to Security Settings: In the Management GUI, go to the “Network Access” tab and locate the “Allowed IP” section and add the . Add IP Addresses: For development, you can temporarily add your local machine’s IP. Add POM Dependency Here’s an example of how to configure the dependency in the pom.xml file: <?xml version=”1.0″ encoding=”UTF-8″?> <project xmlns=”http://maven.apache.org/POM/4.0.0″ xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=”http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd”> <modelVersion>4.0.0</modelVersion> <groupId>com.example</groupId> <artifactId>my-griddb-app</artifactId> <version>1.0-SNAPSHOT</version> <name>my-griddb-app</name> <description>GridDB Application with Spring Boot</description> <url>http://maven.apache.org</url> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.4</version> <relativePath /> <!– lookup parent from repository –> </parent> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <jackson.version>2.16.1</jackson.version> <lombok.version>1.18.30</lombok.version> <springdoc.version>2.3.0</springdoc.version> <jersey.version>3.1.3</jersey.version> <httpclient.version>4.5.14</httpclient.version> </properties> <dependencies> <!– Spring Boot Starters –> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <!– Testing –> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!– API Documentation –> <dependency> <groupId>org.springdoc</groupId> <artifactId>springdoc-openapi-starter-webmvc-ui</artifactId> <version>${springdoc.version}</version> </dependency> <!– JSON Processing –> <dependency> <groupId>org.glassfish.jersey.core</groupId> <artifactId>jersey-client</artifactId> <version>${jersey.version}</version> </dependency> <dependency> <groupId>org.json</groupId> <artifactId>json</artifactId> <version>20231013</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>${jackson.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>${jackson.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> <version>${jackson.version}</version> </dependency> <!– HTTP Client –> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>${httpclient.version}</version> </dependency> <!– Development Tools –> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> <optional>true</optional> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.11.0</version> <configuration> <source>${maven.compiler.source}</source> <target>${maven.compiler.target}</target> <annotationProcessorPaths> <path> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> </path> </annotationProcessorPaths> </configuration> </plugin> </plugins> </build> </project> The application.properties file stores configuration settings like the GridDB Cloud API URL and key, and the NASA POWER API URL, enabling the app to connect securely to these external services. griddb.rest.url=https://your-griddb-cloud-url/rest griddb.api.key=your-griddb-api-key nasa.power.api.url=https://power.larc.nasa.gov/api/temporal/daily/point Technical Implementation In the following section, we’ll walk through the key steps required to set up the project. Container Setup in GridDB Cloud A container named CropHealthData is created in GridDB Cloud, defined as a time-series type, with timestamp set as the row key. Next, we define the schema, which includes the following columns: Data Collection: CollectionService The CollectionService handles weather data ingestion by acting as the interface between external data sources and the GridDB backend. It integrates with NASA’s POWER API to retrieve daily environmental metrics crucial for monitoring crop health. Weather Metrics In this section, we retrieve high-precision, real-time data from an external API. The service provides access to various environmental parameters through the following endpoint: https://power.larc.nasa.gov/api/temporal/daily/pointparameters=ALLSKY_SFC_SW_DWN,T2MDEW,WS2M,PS,QV2M&community=AG&longitude=-93.5&latitude=42.0&start=%s&end=%s&format=JSON API Reference: NASA POWER API Documentation Data is retrieved for a fixed geographical location (latitude: 42.0, longitude: -93.5) via a GET request to NASA’s temporal endpoint. The parameters fetched include: ALLSKY_SFC_SW_DWN: Solar Radiation (MJ/m²/day) T2MDEW: Dew Point (°C) WS2M: Wind Speed (m/s) PS: Surface Pressure (kPa) QV2M: Specific Humidity (g/kg) After receiving the JSON response: Relevant fields are extracted. Timestamps are formatted to GridDB’s required pattern: yyyy-MM-dd HH:mm:ss. Invalid or missing values (represented as -999) are filtered out to ensure data quality. Here is the implementation of CollectionService.java file. @Service public class CollectionService { @Value(“${nasa.power.api.url}”) private String nasaApiUrl; private static String gridDBRestUrl; private static String gridDBApiKey; @Value(“${griddb.rest.url}”) public void setGridDBRestUrl(String in) { gridDBRestUrl = in; } @Value(“${griddb.api.key}”) public void setGridDBApiKey(String in) { gridDBApiKey = in; } public void fetchAndStoreData(String startDate, String endDate) { try { // Fetch JSON data from NASA POWER API String jsonData = fetchJSONFromNASA(String.format( “%s?parameters=ALLSKY_SFC_SW_DWN,T2MDEW,WS2M,PS,QV2M&community=AG&longitude=-93.5&latitude=42.0&start=%s&end=%s&format=JSON”, nasaApiUrl, “20250101”, “20250514”)); // Process and send data to GridDB Cloud sendBatchToGridDB(jsonData); } catch (Exception e) { throw new RuntimeException(“Failed to fetch and store data”, e); } } private String fetchJSONFromNASA(String urlString) throws Exception { URL url = new URL(urlString); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setRequestMethod(“GET”); conn.setRequestProperty(“Accept”, “application/json”); if (conn.getResponseCode() != 200) { throw new RuntimeException(“Failed to fetch data: HTTP error code : ” + conn.getResponseCode()); } Scanner scanner = new Scanner(url.openStream()); StringBuilder response = new StringBuilder(); while (scanner.hasNext()) { response.append(scanner.nextLine()); } scanner.close(); conn.disconnect(); return response.toString(); } private void sendBatchToGridDB(String jsonData) throws Exception { JSONArray batchData = new JSONArray(); ObjectMapper mapper = new ObjectMapper(); JsonNode root = mapper.readTree(jsonData); JsonNode data = root.path(“properties”).path(“parameter”); JsonNode allSkyNode = data.path(“ALLSKY_SFC_SW_DWN”); // Iterate over the field names (dates) in ALLSKY_SFC_SW_DWN Iterator<String> dateIterator = allSkyNode.fieldNames(); while (dateIterator.hasNext()) { String dateStr = dateIterator.next(); double solarRadiation = allSkyNode.path(dateStr).asDouble(); double dewPoint = data.path(“T2MDEW”).path(dateStr).asDouble(); double windSpeed = data.path(“WS2M”).path(dateStr).asDouble(); double surfacePressure = data.path(“PS”).path(dateStr).asDouble(); double specificHumidity = data.path(“QV2M”).path(dateStr).asDouble(); // Skip records with -999 (missing data) if (solarRadiation == -999 || dewPoint == -999 || windSpeed == -999 || surfacePressure == -999 || specificHumidity == -999) { continue; } JSONArray rowArray = new JSONArray(); rowArray.put(formatTimestamp(dateStr)); rowArray.put(42.0); // latitude rowArray.put(-93.5); // longitude rowArray.put(solarRadiation); rowArray.put(dewPoint); rowArray.put(windSpeed); rowArray.put(surfacePressure); rowArray.put(specificHumidity); batchData.put(rowArray); } if (batchData.length() > 0) { sendPutRequest(batchData); } else { System.out.println(“No valid data to send to GridDB.”); } } private String formatTimestamp(String inputTimestamp) { try { if (inputTimestamp == null || inputTimestamp.isEmpty()) { return LocalDateTime.now().format(DateTimeFormatter.ofPattern(“yyyy-MM-dd’T’HH:mm:ss”)) + “Z”; } SimpleDateFormat sdf = new SimpleDateFormat(“yyyyMMdd”); SimpleDateFormat outputFormat = new SimpleDateFormat(“yyyy-MM-dd’T’HH:mm:ss’Z'”); return outputFormat.format(sdf.parse(inputTimestamp)); } catch (Exception e) { return LocalDateTime.now().format(DateTimeFormatter.ofPattern(“yyyy-MM-dd’T’HH:mm:ss”)) + “Z”; } } private void sendPutRequest(JSONArray batchData) throws Exception { URL url = new URL(gridDBRestUrl); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setDoOutput(true); conn.setRequestMethod(“PUT”); conn.setRequestProperty(“Content-Type”, “application/json”); conn.setRequestProperty(“Authorization”, gridDBApiKey); // Send JSON Data try (var os = conn.getOutputStream()) { os.write(batchData.toString().getBytes()); os.flush(); } int responseCode = conn.getResponseCode(); if (responseCode == HttpURLConnection.HTTP_OK || responseCode == HttpURLConnection.HTTP_CREATED) { System.out.println(“Batch inserted successfully.”); } else { throw new RuntimeException(“Failed to insert batch. Response: ” + responseCode); } conn.disconnect(); } } Batch Insertion to GridDB Next, cleaned data is sent to the CropHealthData container in GridDB using a PUT request via the /CropHealthData/row endpoint. This process: < ul> Utilizes batch insertion to reduce network overhead. Takes advantage of GridDB’s high-throughput performance, which is ideal for time-series ingestion at scale. Data Retrieval and Analytical Processing The CropHealthService is responsible for retrieving data from GridDB and performing analytical computations to derive actionable indicators. It queries the CropHealthData container using GridDB’s REST API, which returns a JSON response with a rows array. Each row contains eight fields, with timestamps formatted as yyyy-MM-dd’T’HH:mm:ss.SSSSSSSSSZ (e.g., 2025-01-01T00:00:00.000000000Z). The service parses this response, mapping each row to a CropHealthData DTO object. package mycode.dto; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import java.util.Date; @Data @AllArgsConstructor @NoArgsConstructor public class CropHealthData { private Date timestamp; private double latitude; private double longitude; private double solarRadiation; private double dewPoint; private double windSpeed; private double surfacePressure; private double specificHumidity; private String status; } This object is then used to compute five key indicators: Photosynthetic Stress: Identifies days with solar radiation below 10 MJ/m²/day, aggregated by month to highlight periods of reduced photosynthesis. Fungal Risk: Counts days with dew point above 20°C within a 7-day window, signaling potential fungal disease outbreaks. Wind Stress: Tracks days with wind speed exceeding 5 m/s, aggregated weekly to assess mechanical stress on crops. Atmospheric Stress: Detects daily surface pressure drops greater than 2 kPa, indicating weather instability. Moisture Deficit: Calculates weekly average specific humidity to evaluate water availability. These indicators transform raw weather data into insights tailored for agriculture. For example, a high fungal risk score prompts farmers to apply fungicides, while persistent low radiation signals the need for supplemental lighting. Visualization: Unified Dashboard API Visualization is a key feature of the system, delivered through a Thymeleaf-based dashboard powered by Chart.js for dynamic, interactive charts. The CropHealthController exposes a single API endpoint: GET /api/dashboard-data This endpoint calls CropHealthService.getAllVisualizationData to retrieve data for all ten charts in one JSON response. Here is the complete implementation from CropHealthController.java file. @Controller @RequestMapping(“/crop-health”) public class CropHealthController { @Autowired private CropHealthService cropHealthService; @GetMapping(“/dashboard”) public String dashboard(Model model) { model.addAttribute(“solarRadiationData”, cropHealthService.getVisualizationData(“solar_radiation”)); model.addAttribute(“dewPointData”, cropHealthService.getVisualizationData(“dew_point”)); model.addAttribute(“windSpeedData”, cropHealthService.getVisualizationData(“wind_speed”)); model.addAttribute(“surfacePressureData”, cropHealthService.getVisualizationData(“surface_pressure”)); model.addAttribute(“specificHumidityData”, cropHealthService.getVisualizationData(“specific_humidity”)); model.addAttribute(“photosyntheticStressData”, cropHealthService.getVisualizationData(“photosynthetic_stress”)); model.addAttribute(“fungalRiskData”, cropHealthService.getVisualizationData(“fungal_risk”)); model.addAttribute(“windStressData”, cropHealthService.getVisualizationData(“wind_stress”)); model.addAttribute(“atmosphericStressData”, cropHealthService.getVisualizationData(“atmospheric_stress”)); model.addAttribute(“moistureDeficitData”, cropHealthService.getVisualizationData(“moisture_deficit”)); return “dashboard”; } } Running the Project To run the project, execute the following command to build and run our application: mvn clean install && mvn spring-boot:run Accessing the Dashboard After successfully launching the Spring Boot application, users can access the interactive visualization dashboard by opening a web browser and navigating to: `http://localhost:9090/dashboard`. The dashboard currently showcases the following visual insights: The dashboard presents a comprehensive view of crop health through ten interactive charts: Environmental Metrics (Line Charts) Solar Radiation: Daily solar radiation values in MJ/m²/day, helping identify optimal photosynthesis periods Dew Point: Temperature at which air becomes saturated (°C), crucial for fungal disease prediction Wind Speed: Daily wind measurements in m/s, indicating potential mechanical stress on crops Surface Pressure: Atmospheric pressure readings in kPa, showing weather stability Specific Humidity: Daily moisture content in g/kg, essential for irrigation planning Crop Stress Indicators Photosynthetic Stress: Monthly bar chart showing days with suboptimal radiation (< 10 MJ/m²/day) Fungal Risk: Gauge chart displaying 7-day dew point risk assessment (> 20°C) Wind Stress: Weekly bar chart tracking high wind events (> 5 m/s) Atmospheric Stress: Area chart highlighting significant pressure drops (> 2 kPa/day) Moisture Deficit: Weekly line chart of humidity averages for water management Conclusion: Precision farming relies on fast, accurate time-series data to make informed decisions that improve crop health and yield. By harnessing GridDB’s ability to handle large-scale, high-frequency environmental data in real time, farmers can detect stress factors early and respond proactively. This timely insight reduces waste, optimizes resource use, and ultimately leads to more sustainable and efficient agricultural practices. Fast, reliable time-series databases are essential for unlocking the full potential of precision agriculture in today’s data-driven
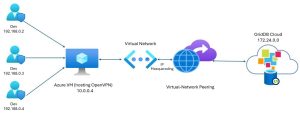
Connect to GridDB Cloud with Local Development Environment (How to set up and use OpenVPN)
More
With GridDB Cloud 3.1, you can now access the native API of GridDB through Azure’s virtual peering network connection. The way it works is that that any virtual network (vnet) that you set up in your Azure cloud environment can set up what is called a peering connection, which allows two disparate sources to communicate through Azure’s vast resources. Through this, any virtual machine connected to that vnet can communicate and use the GridDB Cloud native APIs. We discuss at greater length here: https://griddb.net/en/blog/griddb-cloud-v3-1-how-to-use-the-native-apis-with-azures-vnet-peering/ In this article, we will build upon that idea and teach you how to set up a VPN which will allow you to access your GridDB Cloud through your local environment, meaning you can freely use GridDB with your existing application code as long as you connect to the VPN. Prereqs To fully utilize GridDB Cloud with native APIs in your local environment, you will need to, of course, have access to one of the paid GridDB Cloud instances: https://griddb.net/en/blog/griddb-cloud-azure-marketplace/. The nice thing, though, is that there are trial versions on the marketplace of one month so that you may try out GridDB Cloud’s features for free! You will also need to have set up a the vnet peering as described in the opening paragraphs of this article: GridDB Cloud v3.1 – How to Use the Native APIs with Azure’s VNET Peering If you have this set up, you should have the following in your Azure resource: GridDB Cloud (Pay As You Go) Azure Virtual Network with peering connection to GridDB Cloud A virtual machine connected to the above vnet Please note, that all of the above will incur some sort of cost on Azure (for example, an Azure VM b1 instance costs roughly ~$8/month if left on at all times). OpenVPN and IP Masquerading The way this set up works is through something called IP Masquerading which is “a process where one computer acts as an IP gateway for a network. All computers on the network send their IP packets through the gateway, which replaces the source IP address with its own address and then forwards it to the internet.” (https://www.linux.com/training-tutorials/what-ip-masquerading-and-when-it-use/). Essentially, it means that the traffic from your local machine will be intended for the GridDB Cloud IP, but instead will route through the VPN the DB will see the request coming and it will look like the request is coming from the local machine within the network (the vm) and accept it, and then make its response and push it back through the virtual network, through the virtual machine, and to your local env. So to get this running, you simply need to set up openvpn on the Azure virtual machine and then turn on the rule to do IP Masquerading and it will work. Install OpenVPN To install openvpn and the client certs for my machine, I used the guide from ubuntu: https://documentation.ubuntu.com/server/how-to/security/install-openvpn/. Through this guide, you will have OpenVPN installed on your Azure VM and then will have certs on your local machine that can connect to your VM. 1. Install OpenVPN & Easy-RSA sudo apt install openvpn easy-rsa 2. Set Up the PKI (Certificate Authority) sudo make-cadir /etc/openvpn/easy-rsa cd /etc/openvpn/easy-rsa/ Initialize PKI: ./easyrsa init-pki Build the CA: ./easyrsa build-ca 3. Generate Server Certificates Generate server key request: ./easyrsa gen-req myservername nopass Generate Diffie-Hellman params: ./easyrsa gen-dh Sign server certificate: ./easyrsa sign-req server myservername Copy required files into /etc/openvpn/: pki/dh.pem pki/ca.crt pki/issued/myservername.crt pki/private/myservername.key 4. Create Client Certificates Generate client key request: ./easyrsa gen-req myclient1 nopass Sign client cert: ./easyrsa sign-req client myclient1 Securely copy to the client machine: ca.crt (from earlier) myclient1.crt (inside /pki/issued) myclient1.key (inside /pki/private) 5. Configure the OpenVPN Server Copy sample config: sudo cp /usr/share/doc/openvpn/examples/sample-config-files/server.conf /etc/openvpn/myserver.conf Edit myserver.conf so these lines reference your certs: ca ca.crt cert myservername.crt key myservername.key dh dh.pem Generate TLS auth key: sudo openvpn –genkey secret ta.key Enable IP forwarding: Edit /etc/sysctl.conf, set: net.ipv4.ip_forward=1 Apply: sudo sysctl -p /etc/sysctl.conf Start the server: sudo systemctl start openvpn@myserver 6. Configure the Client Install OpenVPN: sudo apt install openvpn Copy sample config: sudo cp /usr/share/doc/openvpn/examples/sample-config-files/client.conf /etc/openvpn/ Place the files on client: ca.crt myclient1.crt myclient1.key ta.key Edit client.conf: client remote your.server.ip 1194 ca ca.crt cert myclient1.crt key myclient1.key tls-auth ta.key 1 Start client: sudo systemctl start openvpn@client 7. Quick Troubleshooting Check logs: sudo journalctl -u openvpn@myserver -xe sudo journalctl -u openvpn@client -xe Ensure: Ports match Protocol (udp/tcp) matches tls-auth index matches (0 on server, 1 on client) Same cipher, auth, and dev tun settings IP Masquerading As explained above, if you try it now, it simply won’t work, as the traffic will be routed to the GridDB DB from the IP on your local environment which is blocked due to security rules. But once this setting is turned on, it will work. Run the following command in your VM: sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE. And that should do it! To ensure it works, you can of course run the sample code based on the previous blog. But before going through that effort, you can also simply try this: from the local environment (connected to the VPN), ping the IP of your GridDB Cloud DB (can be fetched from the notification provider URL in the GridDB Cloud DB UI home page) ping 172.26.30.68. And then on your Azure VM (the one hosting the VPN and that can also connect to GridDB Cloud) run: sudo tcpdump -i eth0 -n host 172.26.30.68. If successful, your pings to GridDB Cloud should be routed through the VM and be heading to its destination. Cool! To run the sample code, you can start by cloning the github repo and changing to the correct branch: $ git clone https://github.com/griddbnet/Blogs.git –branch griddb_cloud_paid_guide Then set your env variables for your GridDB Connection: export GRIDDB_NOTIFICATION_PROVIDER=”” export GRIDDB_CLUSTER_NAME=”” export GRIDDB_USERNAME=”” export GRIDDB_PASSWORD=”” export GRIDDB_DATABASE=”” And then from here, navigate to either the java or python dirs and run them! For java, do – $ mvn clean package – $ java -jar target/java-samples-1.0-SNAPSHOT-jar-with-dependencies.jar For python, after installing the python client, you can install the requirements text (python3.12 -m pip install -r requirements.txt), make sure your JAVA_HOME and CLASSPATH env variables are set, and then run the code python3.12

Building a Volunteer-Matching System for Health Events
More
Welcome! We’re about to build something useful, a volunteer-matching platform that connects skilled medical professionals with health organizations that need them. It’s the kind of system you’d see powering real health events, from blood drives to vaccination clinics. By the time we’re done, you’ll understand how to architect and deploy a complete full-stack application that handles real-world complexity, including matching qualified people to opportunities, managing permissions across different user roles, and keeping everything secure. The Stack: Technologies That Work Together We’re using a carefully selected tech stack that mirrors what you’ll find in production environments: Spring Boot & Thymeleaf handles the business rules, data orchestration, and renders dynamic HTML templates on the server side. GridDB (cloud-hosted NoSQL datastore) stores volunteer profiles, opportunities, and applications. Each technology serves a specific purpose, and together they create a seamless user experience backed by robust backend logic. Learning Roadmap We’ll move from foundation to mastery: Setup & Architecture: We’ll start by understanding the three-layer system design, laying out your Maven project structure, and configuring Spring Boot for success. Core Features: Next, we’ll implement the data model (entities, relationships, indexing) and set up GridDB integration. User Interface & Experience: Then we’ll create server-rendered Thymeleaf templates for browsing opportunities, applying for roles, and managing skills. You’ll see how server-side rendering keeps everything simple. Security: We’ll add Spring Security authentication, implement role-based access control, ensuring organizers see different screens than volunteers, and ensuring data stays protected. Real-World Patterns: Finally, integrate real-time slot updates. By completing this tutorial, you’ll understand how to architect a full-stack Java application from database to user interface. More importantly, you’ll have a complete, deployable system you can adapt to other matching problems. Let’s build something real. Project Setup Here’s how we’ll set it up: Navigate to start.spring.io Configure your project: Project: Maven Language: Java Spring Boot: 3.5.x (latest stable version) Group: com.example Artifact: springboot-volunteermatching Java Version: 21 Add the following dependencies: Spring Web Thymeleaf Spring Security Click Generate to download a ZIP file with our project structure Once you’ve downloaded and extracted the project, import it into your IDE. Next, we will create the package structure by grouping the classes based on their respective entities, e.g., a package organization contains the controller, service, DTO, etc. volunteer-matching/ ├── pom.xml ├── src/main/java/com/volunteermatching/ │ ├── config/ (RestClient config) │ ├── griddb/ │ ├── griddbwebapi/ │ ├── opportunity/ │ ├── opportunity_requirement/ │ ├── organization/ │ ├── organization_member/ │ ├── registration/ │ └── security/ (Auth filters, RBAC) │ ├── skill/ │ ├── user/ │ ├── volunteer_skill/ └── src/main/resources/ ├── templates/ (Thymeleaf templates) └── application.properties (Configuration) Connecting to the GridDB Cloud Configure the credentials for connecting to the GridDB Cloud through HTTP. Add the following to application.properties: # GridDB Configuration griddbcloud.base-url=https://cloud5197.griddb.com:443/griddb/v2/gs_cluster griddbcloud.auth-token=TTAxxxxxxx Next, create a bean of org.springframework.web.client.RestClient that provides a fluent, builder-based API for sending synchronous and asynchronous HTTP requests with cleaner syntax and improved readability. @Configuration public class RestClientConfig { final Logger LOGGER = LoggerFactory.getLogger(RestClientConfig.class); @Bean(“GridDbRestClient”) public RestClient gridDbRestClient( @NonNull @Value(“${griddbcloud.base-url}”) final String baseUrl, @NonNull @Value(“${griddbcloud.auth-token}”) final String authToken) { return RestClient.builder() .baseUrl(baseUrl) .defaultHeader(HttpHeaders.AUTHORIZATION, “Basic ” + authToken) .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE) .defaultHeader(HttpHeaders.ACCEPT, MediaType.APPLICATION_JSON_VALUE) .defaultStatusHandler( status -> status.is4xxClientError() || status.is5xxServerError(), (request, response) -> { String responseBody = getResponseBody(response); LOGGER.error(“GridDB API error: status={} body={}”, response.getStatusCode(), responseBody); if (response.getStatusCode().value() == 403) { LOGGER.error(“Access forbidden – please check your auth token and permissions.”); throw new ForbiddenGridDbConnectionException(“Access forbidden to GridDB Cloud API.”); } throw new GridDbException(“GridDB API error: “, response.getStatusCode(), responseBody); }) .requestInterceptor((request, body, execution) -> { final long begin = System.currentTimeMillis(); ClientHttpResponse response = execution.execute(request, body); logDuration(request, body, begin, response); return response; }) .build(); } } @Bean(“GridDbRestClient”): register this client as a Spring bean so we can inject it anywhere with @Qualifier(“GridDbRestClient”) final RestClient restClient. .baseUrl(baseUrl): set the common base URL for all requests. .defaultHeader(…): adds a header that will be sent with every request. .defaultStatusHandler(…): when the API return an error (4xx or 5xx status code), log the error status. If the status is 403, throws a custom ForbiddenGridDbConnectionException. For any other error, it throws a general GridDbException. .requestInterceptor(: log how long the request took for debugging performance. Next, create a helper that will be used by each service class to talk to the GridDB Cloud over the internet using HTTP requests. It wraps a pre-configured RestClient and provides easy-to-use methods for common database operations. All the complicated stuff (URLs, headers, error handling) is hidden inside this class. @Component public class GridDbClient { private final RestClient restClient; public GridDbClient(@Qualifier(“GridDbRestClient”) final RestClient restClient) { this.restClient = restClient; } public void createContainer(final GridDbContainerDefinition containerDefinition) { try { restClient .post() .uri(“/containers”) .body(containerDefinition) .retrieve() .toBodilessEntity(); } catch (Exception e) { throw new GridDbException(“Failed to create container”, HttpStatusCode.valueOf(500), e.getMessage(), e); } } public void registerRows(String containerName, Object body) { try { ResponseEntity result = restClient .put() .uri(“/containers/” + containerName + “/rows”) .body(body) .retrieve() .toEntity(String.class); } catch (Exception e) { throw new GridDbException(“Failed to execute PUT request”, HttpStatusCode.valueOf(500), e.getMessage(), e); } } public AcquireRowsResponse acquireRows(String containerName, AcquireRowsRequest requestBody) { try { ResponseEntity responseEntity = restClient .post() .uri(“/containers/” + containerName + “/rows”) .body(requestBody) .retrieve() .toEntity(AcquireRowsResponse.class); return responseEntity.getBody(); } catch (Exception e) { throw new GridDbException(“Failed to execute GET request”, HttpStatusCode.valueOf(500), e.getMessage(), e); } } public SQLSelectResponse[] select(List sqlStmts) { try { ResponseEntity responseEntity = restClient .post() .uri(“/sql/dml/query”) .body(sqlStmts) .retrieve() .toEntity(SQLSelectResponse[].class); return responseEntity.getBody(); } catch (Exception e) { throw new GridDbException(“Failed to execute /sql/dml/query”, HttpStatusCode.valueOf(500), e.getMessage(), e); } } public SqlExecutionResult[] executeSqlDDL(List sqlStmts) { try { ResponseEntity responseEntity = restClient.post().uri(“/sql/ddl”).body(sqlStmts).retrieve().toEntity(SqlExecutionResult[].class); return responseEntity.getBody(); } catch (Exception e) { throw new GridDbException(“Failed to execute SQL DDL”, HttpStatusCode.valueOf(500), e.getMessage(), e); } } public SQLUpdateResponse[] executeSQLUpdate(List sqlStmts) { try { ResponseEntity responseEntity = restClient .post() .uri(“/sql/dml/update”) .body(sqlStmts) .retrieve() .toEntity(SQLUpdateResponse[].class); return responseEntity.getBody(); } catch (Exception e) { throw new GridDbException(“Failed to execute /sql/dml/update”, HttpStatusCode.valueOf(500), e.getMessage(), e); } } } The constructor takes a RestClient that was named GridDbRestClient. The @Qualifier makes sure we get the correct one. Every method follows the same safe structure: Try to send an HTTP request using restClient. If something goes wrong (network issue, wrong data, server error), catch the exception. Data Model using DTOs Now, let’s create the Data Transfer Objects (DTOs). DTOs are simple classes that carry information from one part of the app to another, for example, from the database to the screen. In this project, the DTOs represent important things like users, skills, organizations, and volunteer events. Each DTO has its own fields to hold the data. Each DTO matches the structure of rows inside one GridDB container. UserDTO: represents a user in the system, such as a volunteer or an organization admin. It’s used to create, update, or display user information. public class UserDTO { @Size(max = 255) @UserIdValid private String id; @NotNull @Size(max = 255) @UserEmailUnique private String email; @NotNull @Size(max = 255) private String fullName; @NotNull private UserRole role; // Setter and Getter } SkillDTO: represents a skill that volunteers can have, such as “First Aid” or “Paramedic.” It’s used to manage the list of available skills. public class SkillDTO { @Size(max = 255) private String id; @NotNull @Size(max = 255) @SkillNameUnique private String name; public SkillDTO() {} public SkillDTO(String id, String name) { this.id = id; this.name = name; } // Setter and Getter } VolunteerSkillDTO: links a user (volunteer) to a specific skill. It includes details like when the skill expires and its verification status. It’s useful for tracking what skills a volunteer has and their validity. OrganizationDTO: represents an organization that creates volunteer opportunities. It’s used to manage organization details. OrganizationMemberDTO: links a user to an organization, specifying their role within it (e.g., member or admin). It’s used to manage who belongs to which organization. OpportunityDTO: represents a volunteer opportunity, like an event that needs volunteers. It’s used to create and display opportunities. OpportunityRequirementDTO: specifies the skills required for a volunteer opportunity. It links an opportunity to skills and indicates if a skill is mandatory. RegistrationDTO: represents a volunteer’s registration for an opportunity. It tracks who signed up and the status of their registration. Service Layer and Business Logic Next, we implement the service layer. The services will utilize these DTOs to handle business logic, communicate with GridDB Cloud through our client, and prepare data for the controllers. The Service class does not use any repository layer like JPA. Instead, it directly connects to GridDB, which is a database, using a GridDbClient. The Service class implements the interface, which means it must provide methods like findAll() to get all rows and get() to find one by ID, create to add a new row, and others. When fetching data, it sends requests to GridDB to get rows, then maps those rows into DTO objects. For saving or updating, it builds a string in JSON format with data and sends it to GridDB Cloud. It also generates unique IDs using TsidCreator and handles date times carefully by parsing and formatting them. @Service public class RegistrationGridDBService implements RegistrationService { private final Logger log = LoggerFactory.getLogger(getClass()); private final GridDbClient gridDbClient; private final String TBL_NAME = “VoMaRegistrations”; public RegistrationGridDBService(final GridDbClient gridDbClient) { this.gridDbClient = gridDbClient; } public void createTable() { List<GridDbColumn> columns = List.of( new GridDbColumn(“id”, “STRING”, Set.of(“TREE”)), new GridDbColumn(“userId”, “STRING”, Set.of(“TREE”)), new GridDbColumn(“opportunityId”, “STRING”, Set.of(“TREE”)), new GridDbColumn(“status”, “STRING”), new GridDbColumn(“registrationTime”, “TIMESTAMP”)); GridDbContainerDefinition containerDefinition = GridDbContainerDefinition.build(TBL_NAME, columns); this.gridDbClient.createContainer(containerDefinition); } @Override public List<RegistrationDTO> findAll() { AcquireRowsRequest requestBody = AcquireRowsRequest.builder().limit(50L).sort(“id ASC”).build(); AcquireRowsResponse response = this.gridDbClient.acquireRows(TBL_NAME, requestBody); if (response == null || response.getRows() == null) { log.error(“Failed to acquire rows from GridDB”); return List.of(); } return response.getRows().stream() .map(row -> { return extractRowToDTO(row); }) .collect(Collectors.toList()); } private RegistrationDTO extractRowToDTO(List<Object> row) { RegistrationDTO dto = new RegistrationDTO(); dto.setId((String) row.get(0)); dto.setUserId((String) row.get(1)); dto.setOpportunityId((String) row.get(2)); try { dto.setStatus(RegistrationStatus.valueOf(row.get(3).toString())); } catch (Exception e) { dto.setStatus(null); } try { dto.setRegistrationTime(DateTimeUtil.parseToLocalDateTime(row.get(4).toString())); } catch (Exception e) { dto.setRegistrationTime(null); } return dto; } @Override public RegistrationDTO get(final String id) { AcquireRowsRequest requestBody = AcquireRowsRequest.builder() .limit(1L) .condition(“id == ‘” + id + “‘”) .build(); AcquireRowsResponse response = this.gridDbClient.acquireRows(TBL_NAME, requestBody); if (response == null || response.getRows() == null) { log.error(“Failed to acquire rows from GridDB”); throw new NotFoundException(“Registration not found with id: ” + id); } return response.getRows().stream() .findFirst() .map(row -> { return extractRowToDTO(row); }) .orElseThrow(() -> new NotFoundException(“Registration not found with id: ” + id)); } public String nextId() { return TsidCreator.getTsid().format(“reg_%s”); } @Override public String register(String userId, String opportunityId) { RegistrationDTO registrationDTO = new RegistrationDTO(); registrationDTO.setUserId(userId); registrationDTO.setOpportunityId(opportunityId); registrationDTO.setStatus(RegistrationStatus.PENDING); registrationDTO.setRegistrationTime(LocalDateTime.now()); return create(registrationDTO); } } Implement the validation We create a dedicated Service class for validating volunteer registration requests against opportunity requirements. Some benefit from this approach: Hides the complexity. If the rules change later (e.g., “User needs 2 out of 3 skills”), we only change that one place Business validation logic isolated from HTTP concern Validation service can be used by REST APIs or other controllers Service can be unit tested independently Clear, focused exception handling with rich context @Service public class RegistrationValidationService { private final Logger log = LoggerFactory.getLogger(getClass()); private final RegistrationService registrationService; private final OpportunityService opportunityService; private final OpportunityRequirementService opportunityRequirementService; private final VolunteerSkillService volunteerSkillService; private final SkillService skillService; public RegistrationValidationService( final RegistrationService registrationService, final OpportunityService opportunityService, final OpportunityRequirementService opportunityRequirementService, final VolunteerSkillService volunteerSkillService, final SkillService skillService) { this.registrationService = registrationService; this.opportunityService = opportunityService; this.opportunityRequirementService = opportunityRequirementService; this.volunteerSkillService = volunteerSkillService; this.skillService = skillService; } public void validateRegistration(final String userId, final String opportunityId) { // Check 1: User not already registered validateNotAlreadyRegistered(userId, opportunityId); // Check 2: Opportunity has available slots validateSlotsAvailable(opportunityId); // Check 3: User has mandatory skills validateMandatorySkills(userId, opportunityId); } private void validateNotAlreadyRegistered(final String userId, final String opportunityId) { Optional existingReg = registrationService.getByUserIdAndOpportunityId(userId, opportunityId); if (existingReg.isPresent()) { throw new AlreadyRegisteredException(userId, opportunityId); } } private void validateSlotsAvailable(final String opportunityId) { OpportunityDTO opportunity = opportunityService.get(opportunityId); Long registeredCount = registrationService.countByOpportunityId(opportunityId); if (registeredCount >= opportunity.getSlotsTotal()) { throw new OpportunitySlotsFullException(opportunityId, opportunity.getSlotsTotal(), registeredCount); } } private void validateMandatorySkills(final String userId, final String opportunityId) { List userSkills = volunteerSkillService.findAllByUserId(userId); List opportunityRequirements = opportunityRequirementService.findAllByOpportunityId(opportunityId); for (OpportunityRequirementDTO requirement : opportunityRequirements) { if (!requirement.getIsMandatory()) { continue; } boolean hasSkill = userSkills.stream() .anyMatch(userSkill -> userSkill.getSkillId().equals(requirement.getSkillId())); if (!hasSkill) { SkillDTO skill = skillService.get(requirement.getSkillId()); String skillName = skill != null ? skill.getName() : “Unknown Skill”; throw new MissingMandatorySkillException(userId, opportunityId, requirement.getSkillId(), skillName); } } } } This service depends on 5 collaborating services (Opportunity, OpportunityRequirement, VolunteerSkill, Skill, Registration) and throws custom exceptions for each validation failure, allowing callers to handle different error scenarios appropriately (e.g., different error messages, logging, etc). HTTP Layer Now, we need a class that handles all incoming web requests, processes user input, and sends back responses. It’s the bridge between the user’s browser and the application’s code logic. @Controller @RequestMapping(“/opportunities”) public class OpportunityController { private final Logger log = LoggerFactory.getLogger(getClass()); private final OpportunityService opportunityService; private final RegistrationService registrationService; private final RegistrationValidationService registrationValidationService; private final UserService userService; private final OpportunityRequirementService opportunityRequirementService; private final SkillService skillService; public OpportunityController( final OpportunityService opportunityService, final RegistrationService registrationService, final RegistrationValidationService registrationValidationService, final UserService userService, final OpportunityRequirementService opportunityRequirementService, final SkillService skillService) { this.opportunityService = opportunityService; this.registrationService = registrationService; this.registrationValidationService = registrationValidationService; this.userService = userService; this.opportunityRequirementService = opportunityRequirementService; this.skillService = skillService; } @GetMapping public String list(final Model model, @AuthenticationPrincipal final CustomUserDetails userDetails) { List allOpportunities = new ArrayList(); UserDTO user = userDetails != null ? userService.getOneByEmail(userDetails.getUsername()).orElse(null) : null; if (userDetails != null && userDetails.getOrganizations() != null && !userDetails.getOrganizations().isEmpty()) { OrganizationDTO org = userDetails.getOrganizations().get(0); model.addAttribute(“organization”, org); allOpportunities = opportunityService.findAllByOrgId(org.getId()); } else { model.addAttribute(“organization”, null); allOpportunities = opportunityService.findAll(); } List opportunities = extractOpportunities(allOpportunities, user); model.addAttribute(“opportunities”, opportunities); return “opportunity/list”; } @GetMapping(“/add”) @PreAuthorize(SecurityExpressions.ORGANIZER_ONLY) public String add( @ModelAttribute(“opportunity”) final OpportunityDTO opportunityDTO, final Model model, @AuthenticationPrincipal final CustomUserDetails userDetails) { if (userDetails != null && userDetails.getOrganizations() != null && !userDetails.getOrganizations().isEmpty()) { OrganizationDTO org = userDetails.getOrganizations().get(0); opportunityDTO.setOrgId(org.getId()); } opportunityDTO.setId(opportunityService.nextId()); return “opportunity/add”; } @PostMapping(“/add”) @PreAuthorize(SecurityExpressions.ORGANIZER_ONLY) public String add( @ModelAttribute(“opportunity”) @Valid final OpportunityDTO opportunityDTO, final BindingResult bindingResult, final RedirectAttributes redirectAttributes) { if (bindingResult.hasErrors()) { return “opportunity/add”; } opportunityService.create(opportunityDTO); redirectAttributes.addFlashAttribute(WebUtils.MSG_SUCCESS, WebUtils.getMessage(“opportunity.create.success”)); return “redirect:/opportunities”; } @GetMapping(“/edit/{id}”) @PreAuthorize(SecurityExpressions.ORGANIZER_ONLY) public String edit(@PathVariable(name = “id”) final String id, final Model model) { model.addAttribute(“opportunity”, opportunityService.get(id)); return “opportunity/edit”; } @PostMapping(“/edit/{id}”) @PreAuthorize(SecurityExpressions.ORGANIZER_ONLY) public String edit( @PathVariable(name = “id”) final String id, @ModelAttribute(“opportunity”) @Valid final OpportunityDTO opportunityDTO, final BindingResult bindingResult, final RedirectAttributes redirectAttributes) { if (bindingResult.hasErrors()) { return “opportunity/edit”; } opportunityService.update(id, opportunityDTO); redirectAttributes.addFlashAttribute(WebUtils.MSG_SUCCESS, WebUtils.getMessage(“opportunity.update.success”)); return “redirect:/opportunities”; } @PostMapping(“/{id}/registrations”) public String registrations( @PathVariable(name = “id”) final String opportunityId, final RedirectAttributes redirectAttributes, @AuthenticationPrincipal final UserDetails userDetails) { UserDTO user = userService .getOneByEmail(userDetails.getUsername()) .orElseThrow(() -> new UsernameNotFoundException(“User not found”)); try { // Validate registration using the validation service registrationValidationService.validateRegistration(user.getId(), opportunityId); // If validation passes, proceed with registration OpportunityDTO opportunityDTO = opportunityService.get(opportunityId); registrationService.register(user.getId(), opportunityId); log.debug( “Registration Successful – user: {}, opportunity: {}”, user.getFullName(), opportunityDTO.getTitle()); redirectAttributes.addFlashAttribute( WebUtils.MSG_INFO, WebUtils.getMessage(“opportunity.registrations.success”)); return “redirect:/opportunities/” + opportunityId; } catch (AlreadyRegisteredException e) { redirectAttributes.addFlashAttribute( WebUtils.MSG_ERROR, WebUtils.getMessage(“opportunity.registrations.already_registered”)); return “redirect:/opportunities/” + opportunityId; } catch (OpportunitySlotsFullException e) { redirectAttributes.addFlashAttribute( WebUtils.MSG_ERROR, WebUtils.getMessage(“opportunity.registrations.full”)); return “redirect:/opportunities/” + opportunityId; } catch (MissingMandatorySkillException e) { redirectAttributes.addFlashAttribute( WebUtils.MSG_ERROR, WebUtils.getMessage(“opportunity.registrations.missing_skill”, e.getSkillName())); return “redirect:/opportunities/” + opportunityId; } } } The OpportunityController.java: Doesn’t do the work itself; it delegates to specialized services. This keeps code organized and reusable. Manages everything related to /opportunities URLs, for example, listing volunteer opportunities. Receives services it needs using constructor injection. @PreAuthorize ensures only authorized users perform actions Validate registration using registrationValidationService. If validation fails, catches specific exceptions and shows error messages. Clean Controller: focus on orchestration only User Interface Preview Listing opportunity page: Register page: Conclusion Building a volunteer-matching web for a health event is a practical project that trains core skills: Spring Boot service design, server-rendered Thymeleaf UI, Cloud NoSQL integration, and RBAC. Feel free to add more feature like email notifications or calendar integration. Keep building, keep
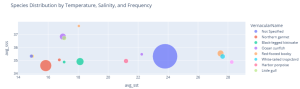
Exploring Ocean Biodiversity using GridDB and Python
More
Modern Ecological Research is largely data-driven, with actionable insights and decisions made using massive, complex datasets.