
はじめに
GridDBには2つの異なるエディション(Community EditionとStandard Edition)があり、いずれも以前のバージョンと比較して機能の数が増えています。 どちらのエディションも、インメモリアーキテクチャを使用してACID準拠、高スケーラビリティ、高性能を実現しています。 また、ハイブリッドクラスタアーキテクチャにより、高い信頼性と可用性を提供します。 このブログでは、この2つのエディションの機能の違いをご紹介します。 様々な例やシナリオの条件下で2つのエディションを比較することで、それぞれのエディションがどのような状況での使用に適しているかがお分かりいただけるでしょう。
GridDB Community Edition(CE)は無償のオープンソース版です。 GridDBの最も基本的なバージョンですが、他のNoSQLデータベースに比べて多くの利点と機能を備えています。 GridDB CEは、AGPLv3ライセンスで提供され、高性能、スケーラビリティ、フォールトトレランスを念頭に置いて構築されています。
GridDB Standard Edition(SE)は、GridDBの商用版です。 GridDB SEは、アップデート、パッチの追加ソフトウェアサポートを提供し、Community Editionにはない新しいツールや機能を提供します。 これには、オンラインノードの追加、Webダッシュボード、クラスタ管理用のコマンドラインシェル、および空間データ型が含まれます。
各バージョン共通の特徴
IoT Data向けの最適化
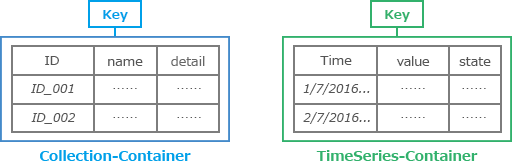
GridDBは、データの格納とアクセスのキーコンテナモデルを使用してIoTデータに合わせて調整されています。 多くのIoTアプリケーションでは、多数のデバイスが非常に頻繁にデータを報告し、データにはタイムスタンプが紐付けられています。 GridDBは、高いレートで到着するタイムスタンプデータを処理できる TimeSeries コンテナを提供します。 TimeSeriesコンテナは、ストレージスペースを節約する方法として、データ圧縮とともに集約およびサンプリング機能を提供します。
高性能
GridDBは、メモリファースト、ストレージファーストアプローチを使用してデータにアクセスします。 頻繁にアクセスされるデータは、メモリ内、好ましくは同じブロック内に記憶されます。GridDBのマルチスレッド化とCPU割り当ての正確で効果的な使用により、データベース操作のオーバーヘッドが削減されます。ノード内およびノード間の並列処理により、パフォーマンスがさらに向上します。 これにより、GridDBはメモリとCPUを最大限に活用することができます。
GridDB Community Edition
GridDB Community Edition はGridDBのオープンソース版です。 3.0.1 は無料で、様々なコネクタとあわせて GridDBダウンロードページからダウンロードできます。GridDB Community Editionはパブリッククラウド環境に導入することができ、 AMI をAmazon AWSから入手できます。 GridDBは次のような重要な機能を提供します。
オープンソースと豊富なドキュメント群
GridDB Community Editionはオープンソースであり、開発者向けのいくつかのフレームワークにAPIとコネクタを提供します。 GridDBには、C、Java、Python、RubyのAPIがあります。 開発者はYCSB、Apache Spark、Hadoop MapReduce、Kafka、KairosDBのコネクタを使用できます。
GridDB、そのAPI、およびそのコネクタのソースコードは、 GitHub で見ることができます。
Community Editionにおける新しいノードの追加
Community Editionでは、多数のノードを用いたGridDBクラスタを構成できます。 新しいノードを追加する手順は非常に単純で簡単です。単にクラスタを停止し、新しいノードを含むすべてのノードを立ち上げるだけです。では、手順をみていきましょう。 まず、すべてのノードマシンで gsadm ユーザーとしてログインします。 そこから、現在のクラスタ内の各ノードをクラスタから離します。 その後、ノードを停止します。
On each of the old nodes:
$ sudo su - gsadm $ gs_leavecluster -u username/password $ gs_stopnode -u username/password
クラスタが停止させ、新しいノードを追加する準備が整いました。 新しいノードが他のすべてのノードと同じクラスタ定義ファイル( gs_cluster.json )を持っていることを確認してください。 そこから、すべてのノードを起動し、それらをクラスタに参加させます。 これで、GridDBクラスタが動作し、新しいノードで使用できるようになりました。
この例では、 cluster1 という名前の 3ノードで構成されるクラスタにIPアドレス 192.168.0.1 に新しいノードを追加します。
On all the nodes (both old and new), issue:
$ gs_startnode $ gs_joincluster -c cluster1 -u username/password -n 4 -w
ノードエントリは、( gs_startnode ですべてのノードが開始されている限り)別のノードから指定することもできます。 この場合、クラスタはすべての4つのノードが結合されるまで動作を開始しません( -n 4 )。
次のコマンドを発行して、新しいノードを追加します。
$ gs_joincluster -c cluster1 -n 4 -s 192.168.0.1:10040 -u username/admin
ここまで、機能しているクラスタのノードをCommunity Editionに追加する方法をご説明しました。続いてはStandard Editionをみていきましょう。
GridDB Standard Editionの主な機能
GridDB Standard Editionは、GridDBの商用バージョンです。 GridDB SE ここの評価版にサインアップできます。 GridDB Standard Editionはメンテナンスリリース、バグフィックス、パッチ、アップデート、および企業サポートを年間24時間365日のソフトウェアサポートを提供しますが、評価契約にはソフトウェアサポートは含まれていませんのでご注意ください。 GridDBは、 AWS AMI も提供しています。 GridDB SEは次のような便利なユーティリティを提供します。
空間データ型
空間データは、座標空間内のポイントまたはトポロジとしてマッピングおよび格納できるデータポイントです。 空間データは、地理情報システム(GIS)アプリケーションや地図情報システムで頻繁に使用されます。対象地域の一部を切り出すような空間データは、IoTアプリケーションでは非常に頻繁に使用されます。 空間データの例には、POINT, LINESTRING, POLYGONなどの図形が含まれます。 空間データは、GridDBの GEOMETRY カラムで表されます。 開発者は、空間列と空間インデックスをコンテナに追加できます。 空間交差などのTQLを使用して幾何学的クエリを作成することもできます。 開発者は、GridDB Standard EditionのCおよびJava APIを使用してジオメトリオブジェクトを作成し、ジオメトリ関数を実行することもできます。

ジオメトリデータの詳細は、 GridDBでのジオメトリ値の使用のブログを参照してください。
Web 管理 GUI
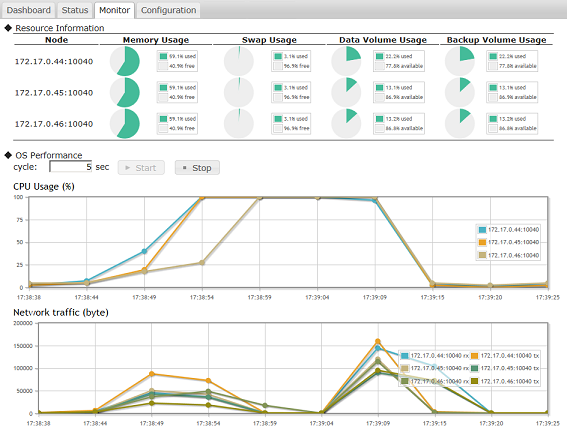
GridDB Standard Editionは、Apache Tomcatで動作する直感的かつ使いやすい管理ダッシュボードアプリケーションを提供します。 Webアプリケーションを使用すると、ユーザーはGridDBクラスタとリポジトリを表示および管理できます。 ユーザーおよび管理者は、GridDBクラスタを使用してノードの構成、接続、および設定を表示および管理し、TQLクエリを発行および分析することもできます。 ノードのスナップショットを取って、個々のノードとそれらのパフォーマンスを特定の時点で表示することができます。 個々のコンテナをリストアップし、ダッシュボードからプロパティとデータを管理することもできます。 チェックポイントやバックアップ情報などの一般的なシステム情報も、GUIアプリケーションで見ることができます。 コンテナおよびGridDBクラスタで発生したエラー、ログ、およびイベントは、管理GUIを使用したリスティングおよび分析にも使用できます。
クラスタ管理シェル
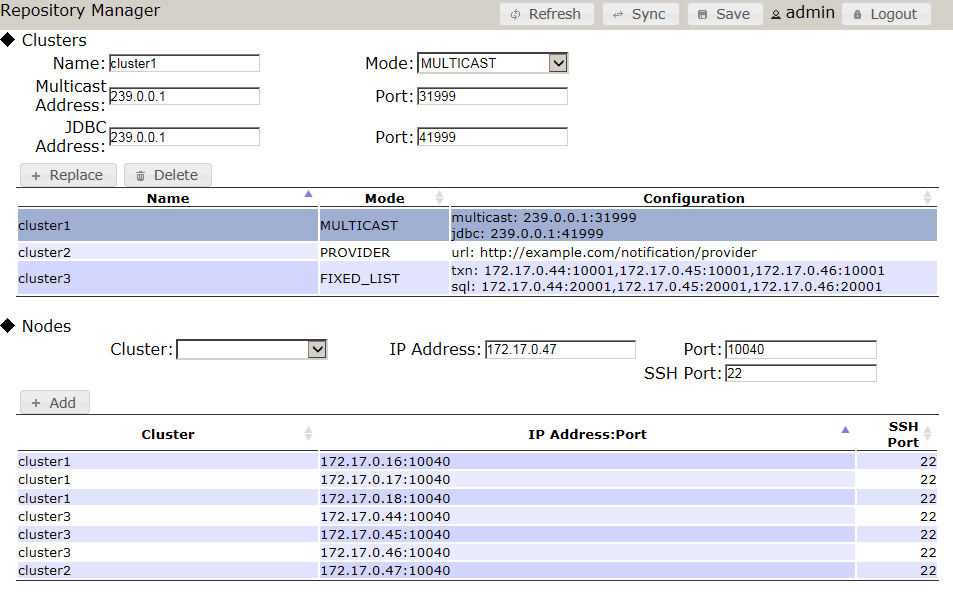
GridDB SEは、GridDB上で動作するコマンドラインインタプリタを提供します。 このツールは、 gsadm ユーザーからアクセスできる gs_sh として知られています。 このコマンドラインツールを使用すると、GridDBでクラスタおよびデータ操作を管理できます。 クラスタを簡単に定義し、そのステータスとログを表示することができます。 個々のノードは、 gs_sh にあるクラスターから開始して停止することもできます。 GridDBのコンテナとトリガをリストして表示することができます。 インデックスは自由にコンテナから追加および削除でき、TQL操作はシェルを通じてコンテナで実行できます。
gs_sh は、2つの異なるモードで使用できます。 1つ目のモードは、特別なGridDB固有のコマンドを従来のコマンドラインのように入力できる対話モードです。 第2のモードはGridDBで実行する一連のサブコマンドを含む .gsh 形式のスクリプトファイルを使用するバッチモードです。
オンラインバックアップとオンライン展開
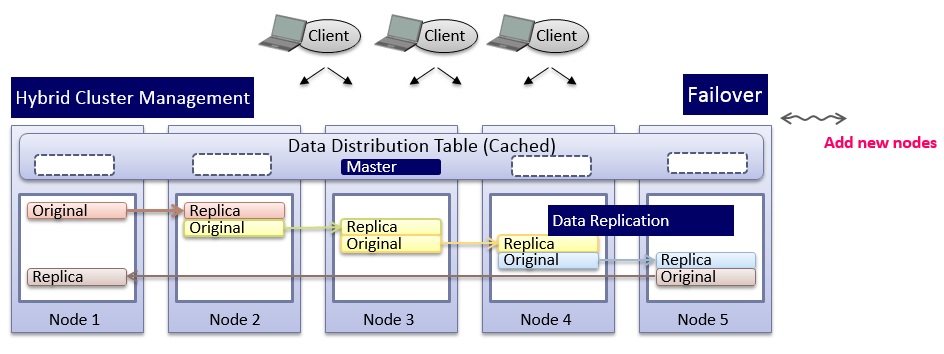
データベースの拡張には、容量と性能の拡大が必要です。 より具体的には、ノードを追加することで、コモディティハードウェアでスケールアウトさせます。ほとんどのデータベースでは、データベースがオフラインのときにのみノードを追加できます。 GridDB Standard Editionは、ユーザが操作を中断したりサービスを停止することなく、データベースをオンラインで拡張する機能を提供します。 Community Edition の新しいノードをクラスタに追加する場合、クラスタ内のすべてのノードはクラスタを離れて再起動する必要があります。 多くのノードを持つ大規模データベースの場合、これは面倒でコストがかかることがありますが、Standard Editionでは、この手順を省略することができます。
GridDB Standardに新しいノードを追加するには、 gs_appendcluster コマンドを使用します。 追加したいクラスタと、ノード・マシンのIPアドレスとポートを指定します。 例えば、IPアドレスが 192.168.0.3 のノードを largeCluster という名前のクラスタに追加するには、次のようにします。
$ sudo su - gsadm $ gs_appendcluster --cluster largeCluster 192.168.0.3:10040 -u username/password
Standard Editionはオンラインバックアップ機能も備えているため、データの破損やアプリケーションの誤動作に対する保護手段として、クラスタで定期的なバックアップを実行できます。
差分バックアップ機能
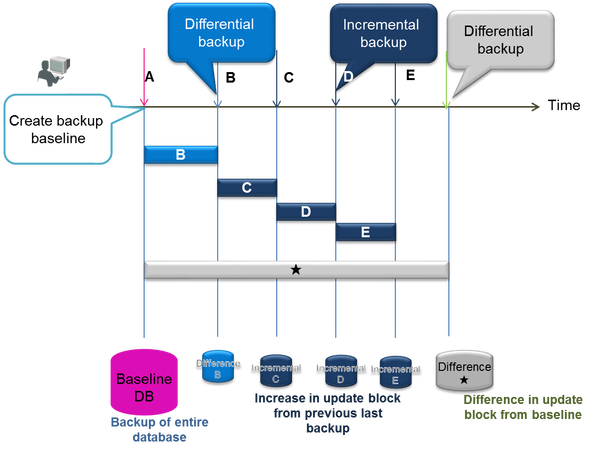
GridDB Standard Editionには、差分バックアップまたは増分バックアップという新しいバックアップタイプが追加されています。 増分バックアップでは、クラスタデータベースはバックアップディレクトリのノード単位で格納されます。 将来のバックアップでは、更新ブロックと最後のバックアップの差分のみがバックアップされます。 更新されたデータブロックは、指定されたベースラインが実行されるとバックアップされます。 差分バックアップもオンラインで行うことができます。
移行のためのエクスポート/インポートツール
Standard Editionはエクスポートとインポートのツールを提供しているため、GridDBノードは局所的な損害から簡単に復旧でき、リレーショナルデータベースからでもコンテナを移行できます。 GridDBのエクスポート機能により、開発者は検索クエリの結果としてクラスタ全体、個々のデータベースとコンテナ、ユーザ権限、行セットをエクスポートできます。 エクスポートされたデータは、 csv またはバイナリ形式のいずれかで保存できます。 個々のコンテナまたは複数のコンテナをコンテナデータファイルという単一のファイルにエクスポートすることもできます。
インポート関数を使用して、リレーショナルデータベースをGridDBに移行できます。 エクスポート機能と同様に、個々のコンテナ、データベース、クラスタをGridDBにインポートすることができます。 リレーショナルデータベースがGridDBデータベースに変換される方法は、リソース定義、RDBコレクション関数、マッピング関数、およびGridDB登録関数で指定できます。
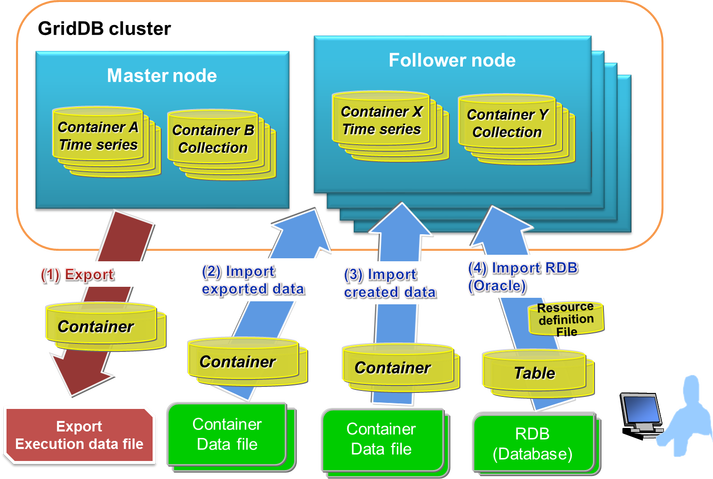
並行して実行することで、インポートとエクスポートのプロセスを高速化することができます。 エクスポートとインポートの機能を使用するための詳細と手順については、このセクション を参照してください。
Standard Editionでのノードの設定
GridDB Standard Editionでは、ノードを追加するには、 Community Edition のようにコマンドラインから gsadm のユーザーを使用してノードを追加する方法と、 gs_sh シェルを使用する方法があります。ノード変数は gs_sh を使ってノードマシンのIP番号とポート番号で作成することができます。 クラスタ変数は多くのノード変数を付けて作成することができ、その後にクラスタを起動したり、結合させたり、またはノードを追加したりすることができるようになります。
// Access gsadm user and gs_sh shell $ sudo su - gsadm $ gs_sh // Define node gs> setnode node0 192.168.0.1 10000 // Define cluster and attach cluster to it gs> setcluster cluster0 defaultCluster 239.0.0.1 31999 $node0 gs> joincluster $cluster0 $node0 // Additional Nodes can be added using 'appendcluster' gs> setnode node2 192.168.0.2 10000 gs> appendcluster $cluster0 $node2
結論
これまでご説明してきたように、GridDBはアプリケーションの規模に関係なく、バックエンドデータベースのニーズに最適なオプションを提供します。 GridDB Community Editionは、小規模なIoTアプリケーションに適しており、オープンソースでありながら信頼性の高い高性能データベースの利点があります。 GridDB Standard Editionは、大規模な商用アプリケーション向けに最適で、より充実したツールやクラスタ管理のサポート機能を備えています。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.