
このブログでは、GPT-4 Visionを使って画像データ、特に画像から表形式のデータを処理し、その結果をGridDBに保存する方法を探ります。React.jsとNode.jsを使用して、ユーザが画像をアップロードし、GPT-4Vの画像処理の結果を見ることができる簡単なWebアプリケーションを構築します。
スタックの紹介
Node.js、GridDB、OpenAIのGPT-4 Visionを使います。ユーザーインターフェースにはReact.jsを使用します。
GPT-4 Vision
GPT-4 with Vision(GPT-4Vと呼ばれることもあります)はOpenAIのプロダクトの一つです。これは、モデルが画像を取り込み、それに関する質問に答えることを可能にします。言語モデルシステムは、歴史的にテキストという単一の入力モダリティを取り込むことによって制限されてきました。多くのユースケースにおいて、これはGPT-4のようなモデルが使用できる領域を制限していました。GPT-4Vの詳細については、公式のドキュメントをご覧ください。
GridDB
GridDBは、IoTやビッグデータ・アプリケーション向けに最適化されたオープンソースのインメモリNoSQLデータベースです。大量のデータを高スループットと低レイテンシーで処理できる拡張性の高いデータベースです。また、GridDBはACIDに準拠しており、SQLライクなクエリをサポートしています。GridDBの詳細については、GridDBウェブサイトをご覧ください。
Node.js
Node.jsは、開発者がスケーラブルなネットワーク・アプリケーションを構築できるようにする、オープンソースのクロスプラットフォームJavaScript実行環境です。GoogleのV8 JavaScriptエンジン上に構築されています。軽量で効率的なイベント駆動、ノンブロッキングI/Oモデルを採用しています。Node.jsの詳細については、Node.jsのウェブサイトをご覧ください。
React.js
React.jsは、ユーザーインターフェースを構築するためのオープンソースのJavaScriptライブラリです。React.jsは、Facebookと個人開発者や企業のコミュニティによって管理されています。React.jsを使用すると、開発者は異なるアプリケーション間で使用できる再利用可能なUIコンポーネントを作成できます。React.jsの詳細については、React.jsのウェブサイトを参照してください。
前提条件
このプロジェクトはUbuntu 20.04.2 LTS WSL 2でテストされています。このプロジェクトを実行するには、OpenAI API キー、GridDB、Node.js、React.js が必要です。以下の手順でインストールしてください。
Install Node.js
Ubuntu で Node.js v20 LTS をパッケージマネージャを使ってインストールするには、 deb リポジトリを追加する必要があります。このドキュメントを読んで、それに従ってください。その後、ターミナルで次のコマンドを入力して、Node.jsが正しくインストールされているかテストします:
node -vInstall GridDB
WSL上のUbuntuにインストールするためのGridDBのドキュメントは、こちらにあります。GridDBが正しくインストールされているかどうかを確認するには、以下のコマンドを実行します:
sudo systemctl status gridstoreGridDBが起動していない場合は、このコマンドで起動できます:
sudo systemctl start gridstoreOpenAI アカウントと API キー
OpenAIのAPIキーは、OpenAIのアカウントにサインアップすることで取得できます。APIキーを安全に保つために、プロジェクトのルートディレクトリにある .env ファイルに保存することができます(これについては後で詳しく説明します)。
プロジェクトの実行
プロジェクトを開始するには、このリポジトリをクローンし、依存関係をインストールする必要があります。以下のコマンドを実行してください:
git clone https://github.com/griddbnet/Blogs.git -- branch image-processingディレクトリをプロジェクトルートの server ディレクトリに変更し、依存関係をインストールします:
cd extract-image-table-gpt4-vision/server
npm installプロジェクトのルートディレクトリに .env ファイルを作成し、OpenAI API キーを記述します。.env` ファイルは以下のようにします:
OPENAI_API_KEY=[your-api-key]また、.env を .gitignore ファイルに追加して、リポジトリにプッシュされないようにします。
サーバーを起動します:
npm startブラウザでデフォルトのプロジェクトURLにアクセスします: http://localhost:5115`にアクセスし、表形式のデータを含む画像をアップロードしてみてください。
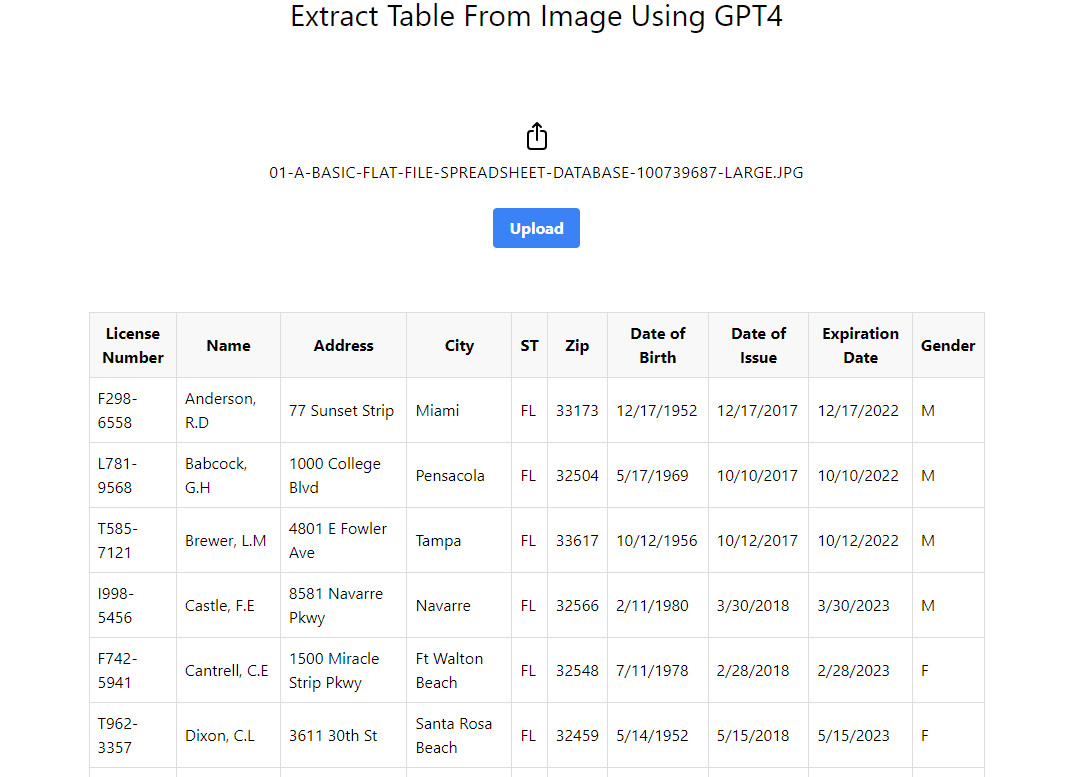
GPT-4 Visionは画像を処理して表データを抽出し、その表データをWebページに表示します。
このプロジェクトの制限については、こちらの注をお読みください。
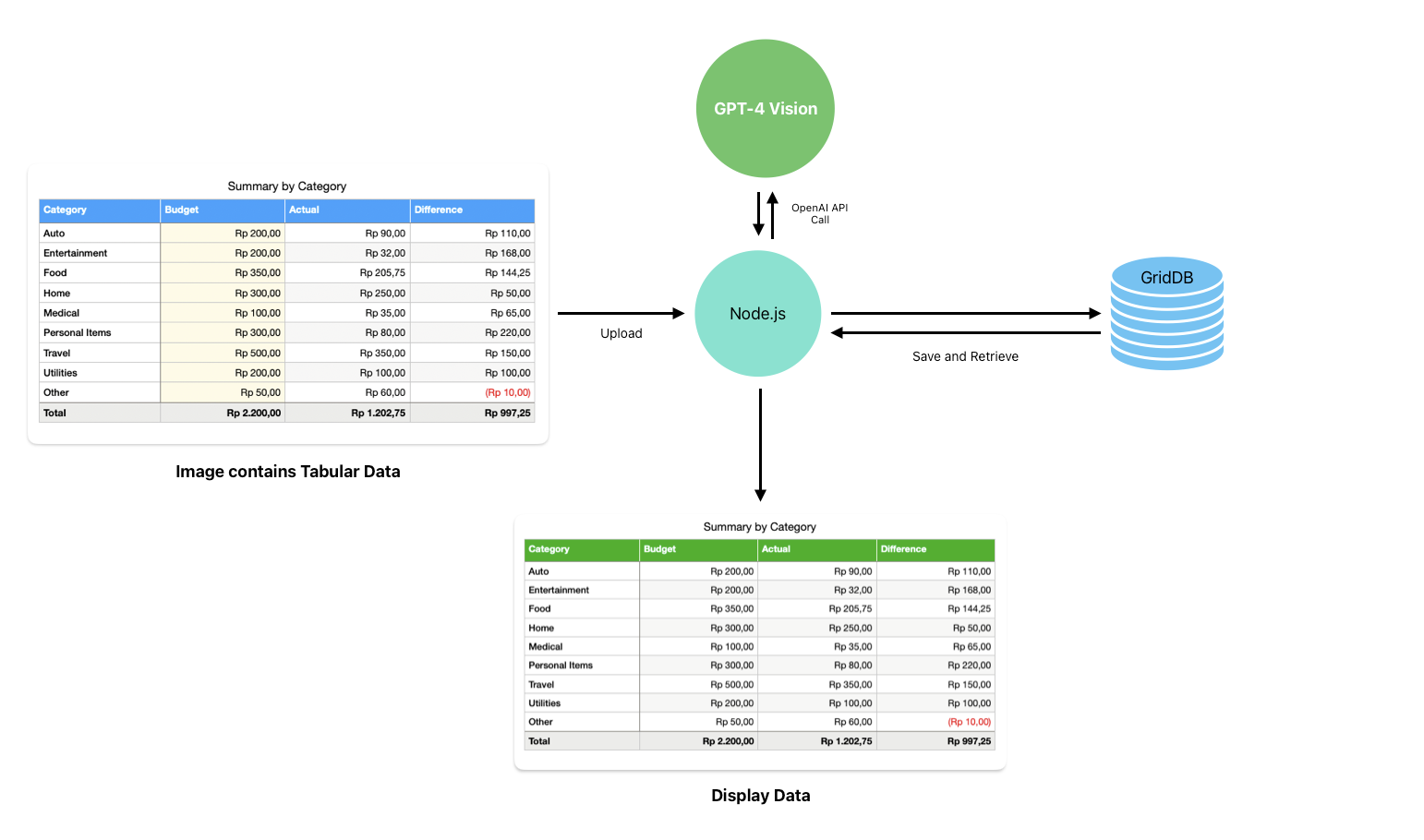
プロジェクトのアーキテクチャ
このアーキテクチャ図は、GPT-4 Vision、Node.js、GridDBを組み込んだデータ処理と可視化のワークフローの概要を示しています。内訳は以下の通りです:
- ユーザは画像をアップロードし、Node.jsは画像を処理するためにGPT-4 Vision APIを呼び出します。Node.jsは中間層で、GPT-4 Visionモデルから送受信されるデータを処理します。
- Node.jsはまた、GridDBと通信します。GridDBは、処理された表形式のデータを永続的に保存するために使用されます。
- 図の下部にあるデータ表示コンポーネントは、アプリケーションがデータを表示していることを示しています。これは、React.jsを使って構築されたウェブ・インターフェイスです。
手元のプロジェクトは、シンプルかつ強力に設計されたWebアプリケーションです。このアプリケーションは、GPT-4 Visionモデルの高度な機能で強化されており、その機能をまったく新しいレベルに引き上げています。
GPT4-Visionを理解します
GPT4-Visionモデルは、画像に何が写っているかという一般的な質問に答えるのが得意です。例えば、画像を説明するために、簡単なプロンプトを使うことができます:
"What's in this image?"そして、GPT4-Vision APIのプロンプトをインターネットから画像を使って実行します:
import OpenAI from "openai";
const openai = new OpenAI();
async function getImageDescription() {
const response = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: "What's in this image?" },
{
type: "image_url",
image_url: {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
},
],
});
console.log(response.choices[0]);
}GPT4 Visionモデルは、プロンプトに基づいて画像を処理し、さらなる処理のために結果を返します。
私たちのプロジェクトでは、アップロードされた画像から表データのみを認識するプロンプトを設計できます。例えば、このプロンプトを使って、画像から表データを抽出することができます:
Recreate the table in the image.そしてコードでは、プロンプトを使って画像から表データだけを抽出することができます:
messages: [
{
role: "user",
content: [
{ type: "text", text: "Recreate table in the image." },
{ type: "image_url",
image_url: {
"url": sampleImageAddress,
},
},
],
},
],OpenAIのGPT4 Visionを使用する利点は、画像から表データを認識するためにモデルを訓練する必要がないことです。私たちは画像を処理するために使用されるプロンプトを設計するだけでよく、このモデルはGPT4のような他のOpenAIのモデルとうまく統合されており、結果をさらに処理することができます。
GPT4-VisionとNode.jsの統合
Node.js と Express.js を使ってシンプルなウェブサーバを構築し、画像がアップロードされた後に GPT4-Vision API を呼び出す画像処理ルートを作成します。
例えば、process-imageルートはアップロードされた画像を受け取り、OpenAI APIを使って画像を処理するためにprocessImageRequest関数を呼び出します:
app.post('/process-image', upload.single('image'), async (req, res) => {
try {
const result = await processImageRequest(req.file.path);
// save the result into the database
res.json(result);
} catch (error) {
res.status(500).send('Error processing image request');
}
});The processImageRequest function is essentially a GPT4 Vision API wrapper function. The code will call the API and then process the image based on the designed prompt earlier:
async function processImageRequest(filePath) {
const imageBuffer = await fs.readFile(filePath);
const base64Image = imageBuffer.toString('base64');
const encodedImage = `data:image/jpeg;base64,{${base64Image}}`;
const response = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: tablePrompt },
{ type: "image_url", image_url: { "url": encodedImage } },
],
},
],
max_tokens: 1024,
});
return response;
}コードでは、GPT4 Vision APIの画像入力にエンコードされたbase64形式を使用しています。これは、画像の公開URLを作成するよりも、サーバーのローカルストレージに保存されている画像を参照する方が簡単だからです。
より良い結果を得るために、processImageRequest関数からの結果をGPT4と呼ばれるより一般的なOpenAIモデルに送り込み、表データのみを抽出します:
const cleanupPrompt = `I need you to extract the table data from this message and provide the answer in markdown format. Answer only the markdown table data, nothing else. Do not use code blocks. nn`;
async function cleanupData(data) {
const response = await openai.chat.completions.create({
model: "gpt-4-1106-preview",
messages: [
{
"role": "system",
"content": "you are a smart table data extractor"
},
{
"role": "user",
"content": `${cleanupPrompt} nn${data}`
}
],
temperature: 1,
max_tokens: 2000,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
});
return response;
}基本的に、cleanupData関数は processImageRequest 関数の結果を特定のプロンプトの助けを借りてクリーンアップします。その結果、Webページに表示可能なデータのマークダウン・テーブルが生成されます。
処理したデータのGridDBへの格納
画像処理とデータのクリーンアップが終わったら、結果をGridDBに保存します。GridDBの put 操作のラッパー関数である saveData 関数を使用します。この関数は server/griddbservices.js ファイルにあります:
export async function saveData({ tableData }) {
const id = generateRandomID();
const data = String(tableData);
const packetInfo = [parseInt(id), data];
const saveStatus = await GridDB.insert(packetInfo, collectionDb);
return saveStatus;
}GridDBコンテナには2つのカラムしかありません: idとdataです。id カラムはデータを識別するために使用され、data カラムは GPT4 のマークダウンテーブルのデータを格納するために使用されます。このスニペットコードは server/libs/griddb.cjs ファイルにあります。
function initContainer() {
const conInfo = new griddb.ContainerInfo({
name: containerName,
columnInfoList: [
['id', griddb.Type.INTEGER],
['data', griddb.Type.STRING],
],
type: griddb.ContainerType.COLLECTION,
rowKey: true,
});
return conInfo;
}saveData関数はprocess-image`ルートで呼び出すことができます。ルート内のコードはGPT4からの結果が終了したかどうかをチェックします。結果が終了していれば、結果をクリーンアップしてからGridDBデータベースに保存します:
app.post('/process-image', upload.single('image'), async (req, res) => {
log.info('Processing image request')
try {
const result = await processImageRequest(req.file.path);
log.info(`Result: ${JSON.stringify(result)}`);
if (result.choices[0].finish_reason === 'stop') {
const cleanedData = await cleanupData(result.choices[0].message.content);
const saveStatus = await saveData({ tableData: JSON.stringify(cleanedData) });
if (saveStatus.status === 0) {
log.error(`Save data to GridDB: ERROR`);
} else {
log.info(`Save data to GridDB: OK`);
}
res.json({ result: cleanedData, status: true });
} else {
res.json({ result, status: false });
}
} catch (error) {
log.error(error);
res.status(500).send('Error processing image request');
}
});結果は直接ウェブ・ページに表示されます。GridDBからデータを取得しない理由は、プロジェクトをシンプルに保つためです。process-imageルートのコードはserver/server.js` ファイルにあります。
しかし、GridDBからデータを取得したい場合は、get-all-data ルートを使用することができます。このルートはGridDBから全てのデータを取得します。
app.get('/get-all-data', async (req, res) => {
log.info('Getting all data from GridDB');
try {
const result = await getAllData();
res.json(result);
} catch (error) {
res.status(500).send('Error getting all data');
}
});ブラウザでルートを実行すると、サーバーはGridDBデータベースに保存されたすべてのデータを応答します。
エンドツーエンドアプリケーションの構築
クライアントやユーザーインターフェースのソースコードは client ディレクトリにある。クライアントはReact.jsアプリケーションです。
アプリケーションのメインエントリ
アップロードのユーザーインターフェースはとてもシンプルです。ユーザーインターフェースの開発を容易にするため、Reactライブラリを使用しています。
これがアプリのメイン・エントリー・コードだ:
import React, { useState } from 'react';
import ImageUploader from './ImageUploader';
import ReactMarkdown from 'react-markdown';
import remarkGfm from 'remark-gfm';
import rehypeRaw from 'rehype-raw';
const App = () => {
const [markdown, setMarkdown] = useState('');
const handleMarkdownFetch = (markdownData) => {
setMarkdown(markdownData.result.choices[0].message.content);
};
return (
Extract Table From Image Using GPT4
{markdown}
);
export default App;メインのアプリケーションエントリは2つのコンポーネントから構成されています: <とです。<コンポーネントは画像をサーバにアップロードする役割を担い、onMarkdownFetchプロップにアタッチされた関数によって処理される結果を返します。
画像アップローダ
<コンポーネントのコードはclient/src/ImageUploader.jsxファイルにあります。画像アップロードのハンドラはhandleUpload関数にあります。この関数は画像をサーバの/process-imageルートにポストし、サーバからの結果はonMarkdownFetch` プロップによって処理されます。
const handleUpload = async () => {
if (selectedFile && !uploading) {
setUploading(true);
const formData = new FormData();
formData.append('image', selectedFile);
try {
const response = await fetch('/process-image', {
method: 'POST',
body: formData,
});
if (!response.ok) {
throw new Error('Network response was not ok');
}
const markdownData = await response.json();
props.onMarkdownFetch(markdownData);
} catch (error) {
console.error('Error posting image:', error);
} finally {
setUploading(false);
}
} else {
alert('Please select an image first.');
}
};マークダウン・レンダラー
幸運なことに、マークダウンのレンダリングにすぐに使えるReactコンポーネントがnpmパッケージにあります。react-markdown]14コンポーネントは使いやすく、どんなReactアプリケーションにも統合できます。
import ReactMarkdown from 'react-markdown';
import remarkGfm from 'remark-gfm';
import rehypeRaw from 'rehype-raw';
...
{markdown}
...また、remark-gfm と rehype-raw プラグインを追加する必要があります。remark-gfmプラグインはマークダウンのテーブルをレンダリングするために使用され、rehype-raw`プラグインはマークダウンのテーブルを生のHTML要素としてレンダリングするために使用されます。
制限事項
このプロジェクトは、GPT4 Visionを使って画像データを処理し、その結果をGridDBに保存する方法の簡単なデモンストレーションです。このプロジェクトを改善する方法はたくさんあります。
現在のところ、このプロジェクトは、表だけを含むクリアでクリーンな画像にのみ対応しています。GPT4 Vision モデルの現状(まだプレビュー中)では、表データに他のテキストや画像が混在しているようなノイズの多い画像を処理することはできません。このプロジェクトを改善する最善の方法は、表データを含む画像をトリミングし、GPT4 Visionを使って処理することです。
参考文献
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.