はじめに
テクノロジーが発達した現代では、生成・収集されるデータの量は膨大なものになっています。しかし、これらのデータは、適切な分析によってデータから情報へと変換されなければ価値がありません。さらに、分析から得られた洞察は、正しく意思決定者に伝えられる必要があります。そのため、膨大な量のデータを一目で理解し、結果的に将来に向けた効果的な意思決定に役立つ優れた視覚化は、データ分析に不可欠な要素となります。そこで、このブログでは、GridDBに格納されたデータにアクセスした後、Plotlyで高品質な視覚化を行う方法を紹介します。
Pythonを使ってGridDBと接続する
GridDBは、東芝が開発したスケーラブルで信頼性の高いNoSQLデータベースです。GridDBは、こちらから無料でダウンロードできます。ダウンロードしたら、griddb_pythonパッケージを使用してPythonで操作します。このブログのためにGridDBからデータを挿入したり読み出したりするPythonの完全なコードはこちらにあります。
データセットの概要
データセットのオリジナルソース(ted_main.csv)はこちらにあります。データセットには全部で17のカラムがありますが、このブログでは以下の6つの特徴だけに注目しています。
- Duration – 講演の時間(秒)
- Event – 講演が行われたTED/TEDxイベント
- Views – 講演が閲覧された合計回数
- Comments – 講演に付いた第一階層のコメント数
- Num_speaker – 講演に含まれる話し手の数
- Published_date – 講演が公開されたUNIXタイムスタンプ
このデータセットから取ったいくつかのサンプル行のスナップショットを以下に示します。

まず、データセットに欠損値がないかどうか、定性的なチェックをしてみましょう。下の図を見ると、データセットには欠損値やNULL値がないことがわかります。

視覚化の段階に進む前に、以下の列のためにいくつかの前処理が必要です。
「Duration」列の値を秒から分に変換する
data_relevant['duration_minutes'] = data_relevant['duration']/60下のスクリーンショットから、最も短いスピーチはわずか2.25分で、最も長いスピーチは87分であったことがわかります。平均スピーチ時間は13.77分です。

Published_dateカラムからYearの値を抽出する
Published_dateカラムはUnixのタイムスタンプ形式であるため、まずpandasの日-月-年形式に変換し、年の値だけを抽出してyear_releasedという新しいカラムに保存します。
data_relevant['date_normal'] =
data_relevant['published_date'].apply(lambda x:
datetime.datetime.fromtimestamp(int(x)).strftime('%d-%m-%Y'))それでは早速、plotlyで視覚化チャートを作ってみましょう。
Plotlyとは何か?
Plotly for pythonは、オープンソースでフリーのデータ可視化ライブラリです。最小限のコードで、基本的なチャートから統計的なチャート、金融チャート、地理的な地図のチャートまで、幅広い種類のインタラクティブなチャートを構築するために使用されます。
次の2つのインターフェイスのいずれかを使ってplotlyパッケージを呼び出すことができます。1つめのPlotly Expressは非常に少ないコード行で強力なグラフを構築するための高レベルAPI (2019年リリース) で、 もう1つのPlotly Graph Objectはより多くのグラフのカスタマイズのための低レベルAPIです。Plotly Expressは、実際にはPlotly Graph Objectsライブラリの高レベルラッパーです。
これらをpythonのコードでpxとしてインポートすると、次のようになります。
import plotly.express as px
import plotly.graph_objects as goPlotlyを使用する際の核となるコンセプトは、図形オブジェクトです。図形オブジェクトには、チャートの構成を決定するすべてのパラメータが格納されています。
Plotlyで視覚化してデータセットを分析する
基本的なチャート
毎年開催されているTEDイベントの数が、時間の経過とともに増えているのか減っているのかを調べたいとします。そのためにはどうすればいいのでしょうか。
px.line()関数を呼び出して、X軸に年、Y軸にイベントの総開催数をとった折れ線グラフを描くことができます。この関数が返すアイテムはFigureオブジェクトです。次に、このFigureオブジェクトのupdate_layout()を呼び出して、このグラフにカスタムタイトルを追加し、中央揃えにしています。また、plotly_darkのようにテンプレートを選択して背景色を変更することもできます。
最後に、Figure オブジェクトの show() を呼び出して、このチャートを画面に表示します。この線上の特定の場所にカーソルを置くと、X軸とY軸の詳細を正確に知ることができます。
line_plot = px.line(year_events, x='year_released', y='event', labels=dict(year_released="Year", event="Events Held"))
line_plot.update_layout(title_text='TED Events held per year (2006 - 2017)', title_x=0.5, template='plotly_dark')
line_plot.update_traces(mode='lines+markers')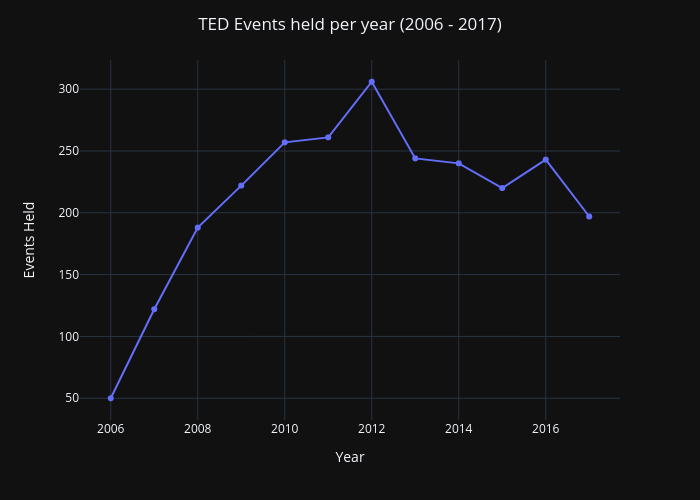
上記の質問に対する答えに戻ると、たった3行のコードで、イベント開催数が2006年から2012年までは増加傾向にあり、2012年から2017年までは減少傾向にあることを示すことができました。
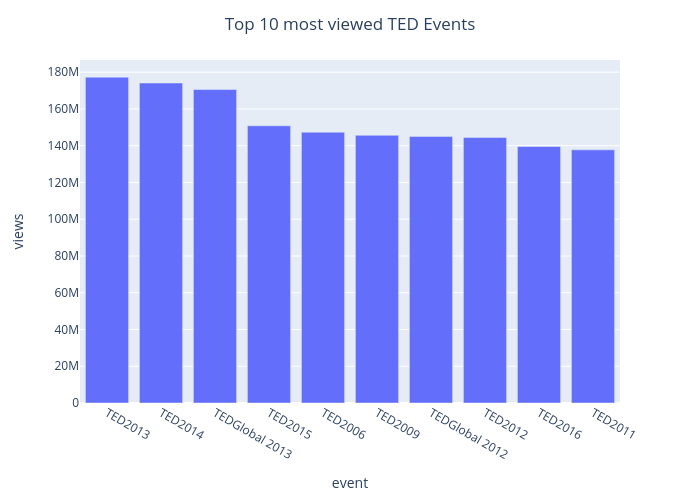
次に、最も視聴されたTEDイベントのトップ10を見てみましょう。下の棒グラフは、これらの情報を整然と簡潔に表しています。2013年のTEDは、1億7730万回の再生回数を記録し、最も人気のあるイベントとなっています。
また、同じ情報を横棒グラフで表示することもできます。
すべての年のデータを見るのではなく、ある年(2012年とします)のデータを掘り下げて、最も視聴されたイベントのトップ5の名前と割合を、以下のドーナツチャートの形で見てみましょう。
統計チャート
さて、plotlyの基本的なチャートを理解したところで、統計チャートのレンズを通してデータを可視化してみましょう。
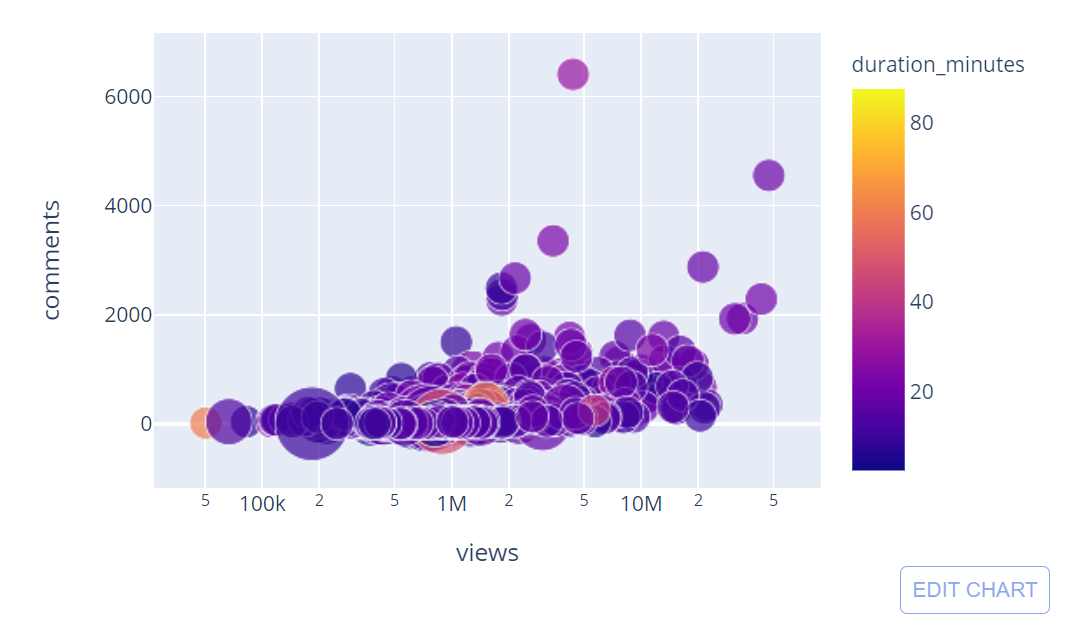
まず、数値化したコラムの閲覧数とコメント数の間に関係があるかどうかを調べます。ここでは、データセット全体を使用します。
トレンドラインを描けば、大まかな方向性を知ることができます。上図のトレンドラインは正の傾きを持っているので、一般的には、最も視聴数が多い講演は最も多くのコメントが付いた講演であると言えます。
また、3つ目の次元(duration_minutes)を追加することで、各講演の長さを同じ散布図に色分けして表示することができます。
さらに、sizeパラメータを追加することで、この散布図をバブル図に素早く変換することができます。これで、バブルの大きさは、その講演の話し手の数に比例します。
また、統計図表の中で非常に一般的なのが、データセット内のある特徴の値の分布を示すヒストグラムです。
また、非常に便利な統計グラフとして、最小値、最大値、中央値、四分位値を描いたボックスプロットがあります(下図参照)。
アニメーション
また、Plotlyはanimation_frame引数によって、以下のようなアニメーション図形にも対応しています。
3Dプロット
たった1行のコードで、このような3次元の散布図を作成することができます。この散布図は、カーソルを使って移動したりドラッグしたりすることができます。
まとめ
このように、 koplotlyを使えば、インタラクティブなプロットやアニメーションをあっという間に作ることができることがお分かりいただけたと思います。しかし、ここで紹介したのは、plotlyパッケージで利用できるカスタマイズのほんの一部であることを覚えておいてください。他にもたくさんのオプションが用意されていますので、試しに使って、重要な識見を効果的に視聴者に伝えるための素晴らしい視覚化を作成してみてください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb