


はじめに
GridDBの開発チームはこれまでにも絶えず管理や操作に改善を重ねてきましたが、最近、時系列データベースをさらに合理的に使用する方法を生み出しました。このブログでは、オンラインポータルを通じてデータベースをクラウドサービスとして提供するサービス、GridDB クラウドを紹介します。いくつかの基本的な機能を紹介し、これから利用するユーザのためにセットアップの方法と使い方を説明します。
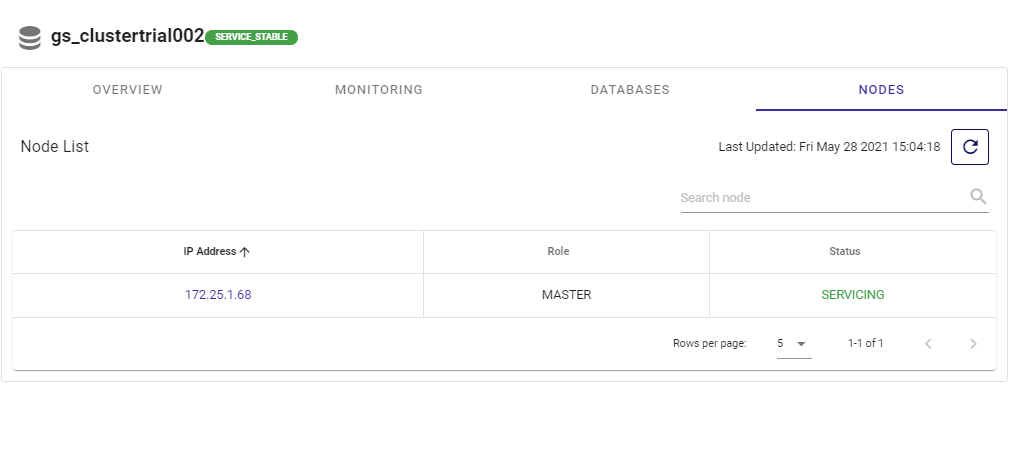
例として、クラスター内のすべての稼働中のノードを示すポータルを以下に示します。
また、参考として、Grafanaをクラウドのインスタンスと連動させる方法も紹介しています。
使い方
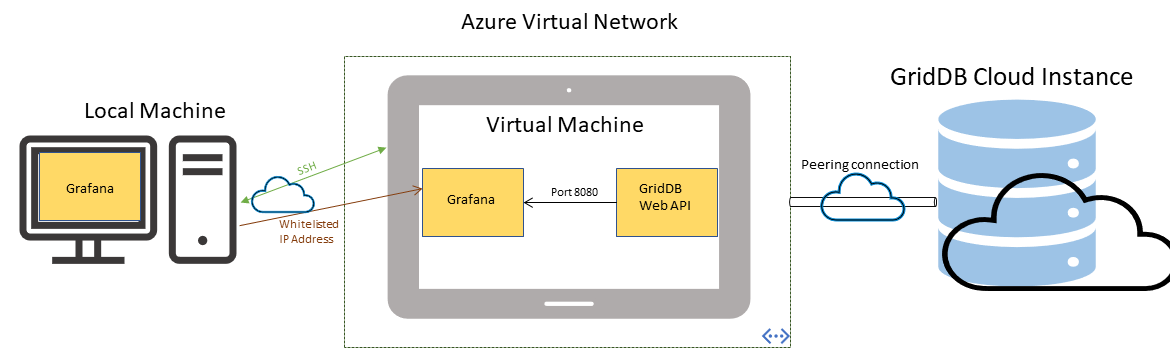
MicrosoftのAzureに仮想プライベートネットワークを設定し、それを使ってクラウドインスタンスに接続する方法を紹介します。この方法は、データを転送する最も安全な方法であるだけでなく、非常に簡単です。
その仕組みは、Azureサブスクリプション上に仮想プライベートネットワークを設定し、そのネットワークに仮想マシンを接続します。その後、Azureネットワークへのリモート接続を可能にするピア接続を設定します。この設定が完了すると、ネットワーク内からGridDBクラウドへの通信が可能になります。(つまり、仮想ネットワーク内の仮想マシンは、GridDBクラウドと直接通信することができます。)
Peer Networkの設定
まず、このプロジェクトのために、Azureサブスクリプションにリソースグループを作成してください。
また、使用しているAzureユーザがAzure AD Roles Directoryで管理者権限を持っていることを確認してください。https://docs.microsoft.com/en-us/azure/active-directory/roles/manage-roles-portal
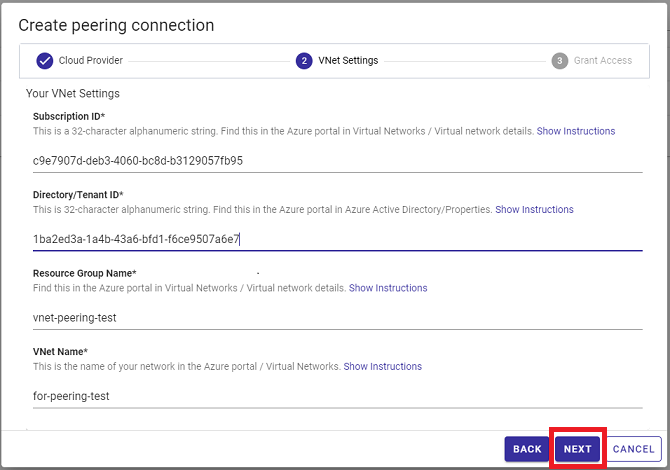
その上で、Azure Subscription ID(リソースグループにあります)とDirectory/Tenant ID(Azure Active Directoryにあります)をメモしてください。
これらの2つのIDを手元に用意した上で、GridDB クラウドウィザードに従ってAzureクラウドプロバイダーとのピアリング接続を作成します。
ウィザードに情報を入力したら、コマンドラインに切り替えてAzure CLIを使用します。(またはAzure Cloud Shellを使用することもできます。)
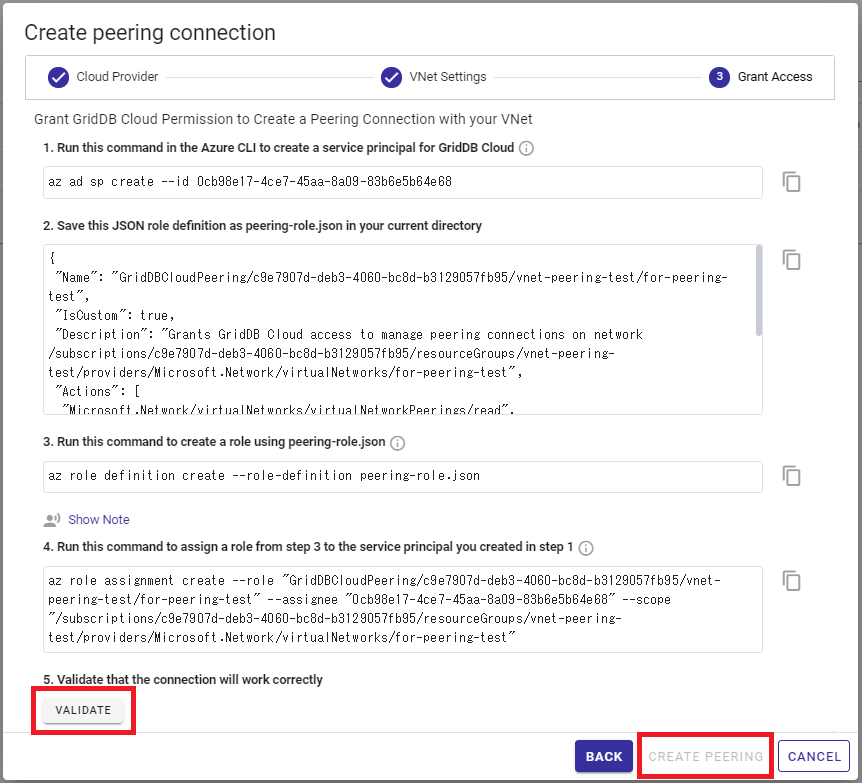
また、最初のコマンドを実行する際に問題が生じた場合は、
az ad sp create --id RESOURCE-ID
ウィザードの手順を進めるために、アクティブユーザが適切な管理者権限を持っていることを確認してください。完了したら、Validateをクリックして、接続が正常であることを確認してください。
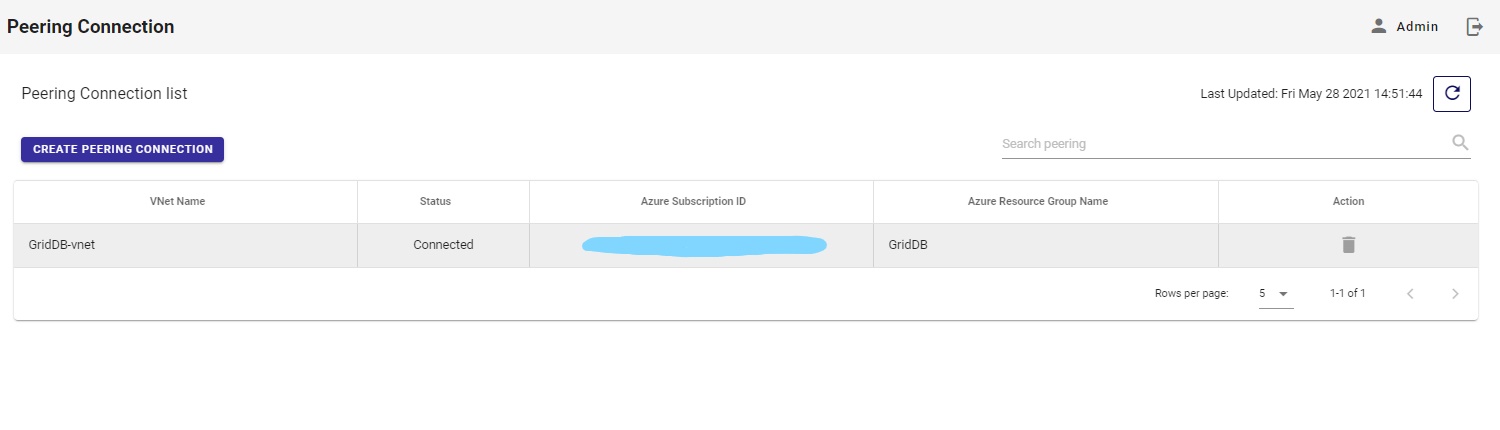
問題がなければ、ピアリング接続ページに表示されます。
DBユーザの作成
クラウドインスタンスにデータをロードする前に、データベースユーザを作成する必要があります。これを行うには、セキュリティタブをクリックして、Create Database Userをクリックします。このユーザ(およびその認証情報)は、クラウドインスタンスと通信する際に使用されます。

GridDBクラウドへのデータ読み込み
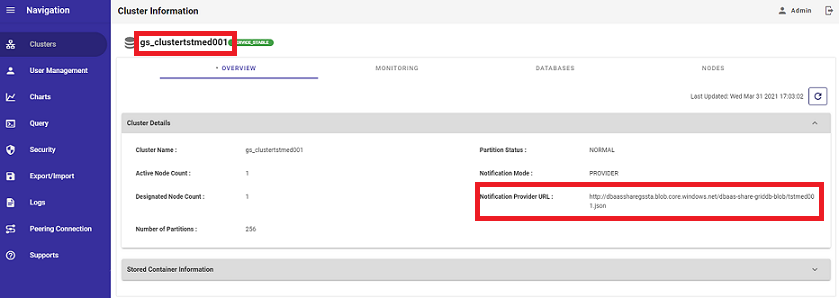
GridDB クラウドのインスタンスに接続するには、現在のところ唯一の方法である 通知プロバイダメソッドを使用します。クラウドポータルのOverviewセクションには、固有の通知プロバイダURLがあります。したがって、クラウド・インスタンスにデータをロードするには、前のステップで作成したID情報と一緒にプロバイダのURLを使用するだけです。
例えば、上記の手順でtest_user1というユーザを作り、test_user1というパスワードを設定した場合、同じネットワーク内の仮想マシンからクラウドのインスタンスに接続する方法は以下の通りです。(pythonスクリプトスニペット)
gridstore = factory.get_store(notification_provider='http://dbaassharegssta.blob.core.windows.net/dbaas-share-griddb-blob/<cloudName>.json',
cluster_name='gs_clustertrial002',
username='test_user1',
password='test_user1')
簡単に説明すると、Azureクラウドの仮想マシンにSSHで接続し、その仮想マシンはクラウド・インスタンスとピアリング接続された仮想ネットワークの中にあったので、データベースのクラウド・インスタンスと直接通信することができました。そのため、上記のpythonスニペットを使って、クラウド・インスタンスに直接データを読み込むことができます。
これで、リモートのGridDB Cloudインスタンスを、ローカルのデータベースのように使うことができるようになります。
オンラインポータルでのデータ閲覧
このブログの準備として、以前のブログで紹介したデータセットをクラウド・インスタンスに読み込みました。
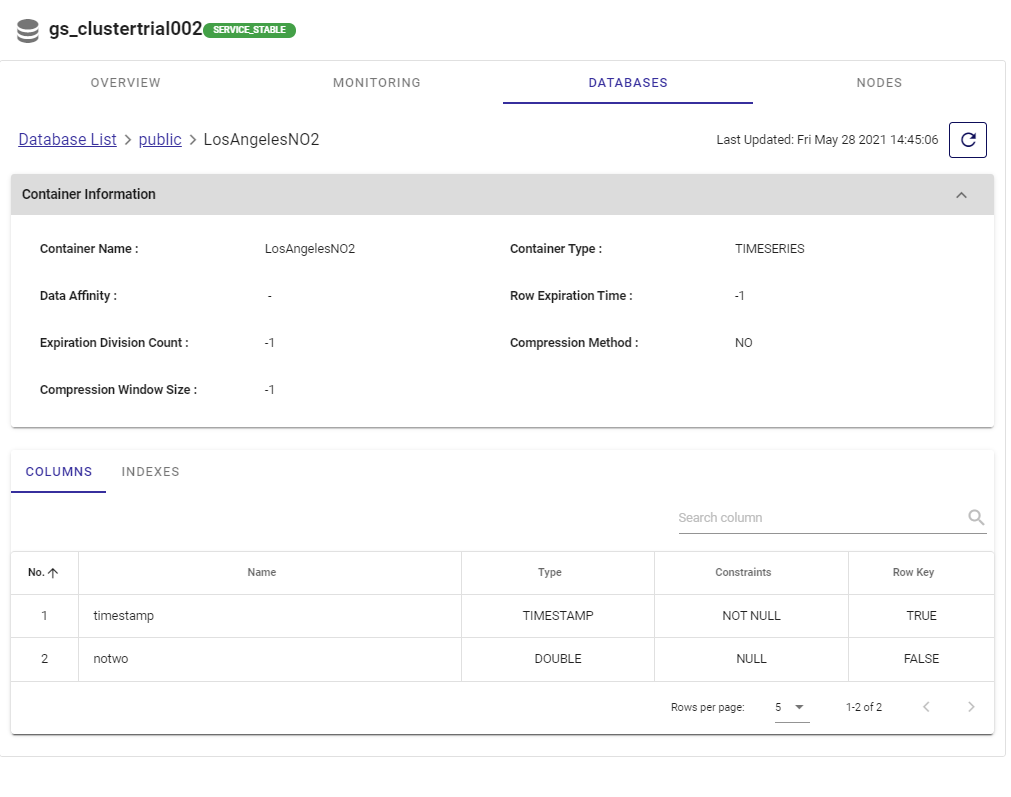
ポータルからデータを見るには、メインページのDATABASESヘッダーに移動してください。このページの下部には、カラムやインデックスの完全なリストが表示されます。
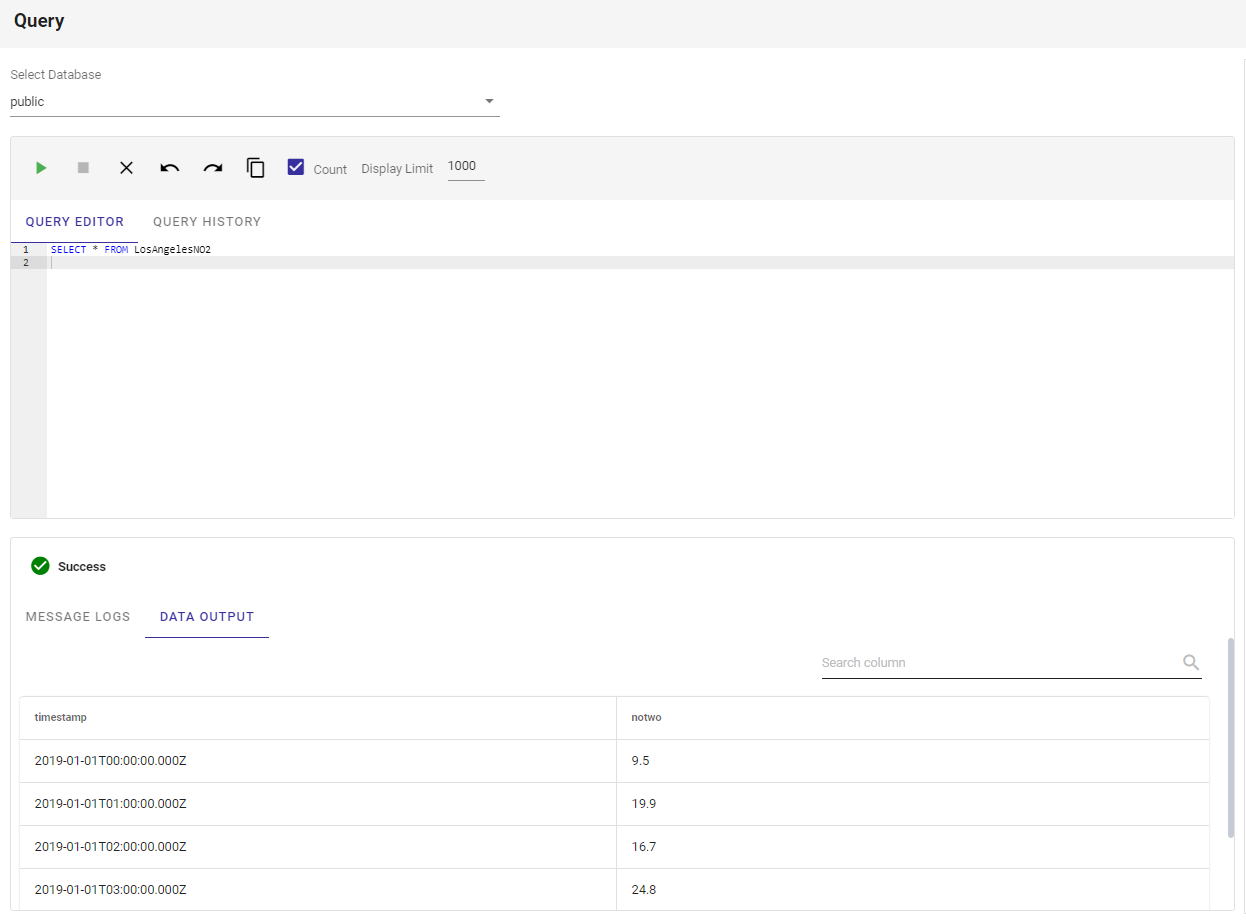
すべてのデータとその構成要素を簡単に見ることができるだけでなく、オンラインポータルには、オンラインクエリエディタ、ビューアが含まれています。つまり、ポータルから直接複雑なクエリを作成し、その出力を同じページで見ることができるのです。これを行うには、サイドメニューのQueryナビゲーションボタンをクリックします。
GridDBは時系列データベースなので、ポータルにはチャートビューアもあります。サイドバーのメニューからChartsボタンをクリックすると、時間範囲を選択して、折れ線グラフや棒グラフでデータを表示することができます。とても便利な機能です。
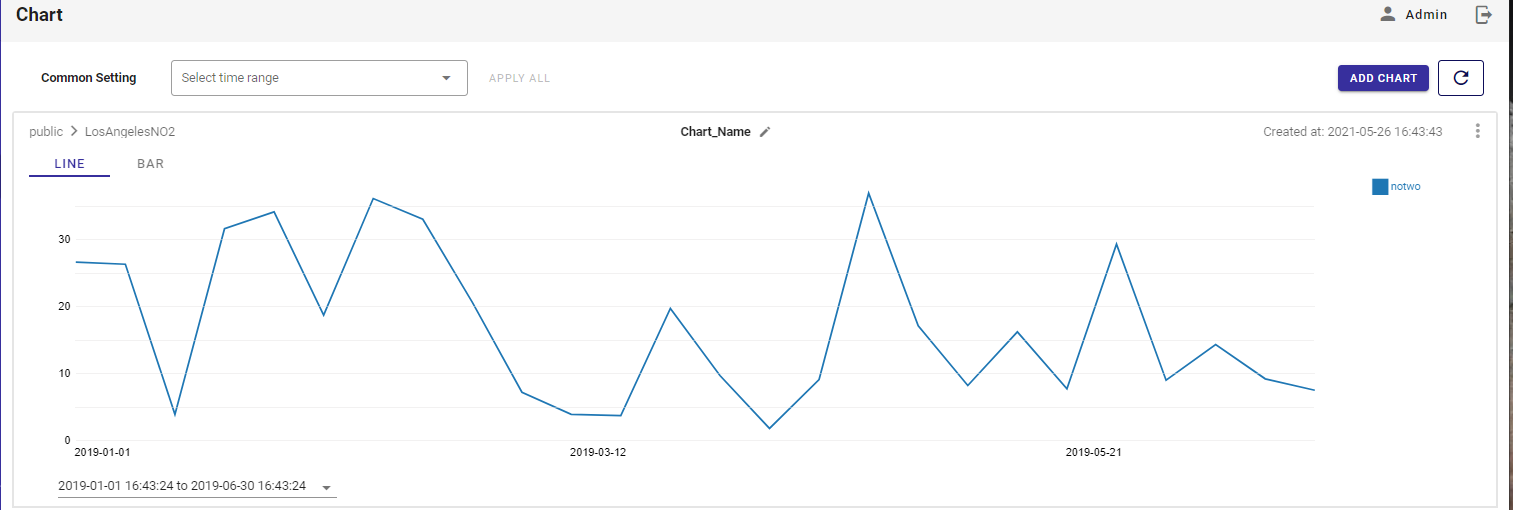
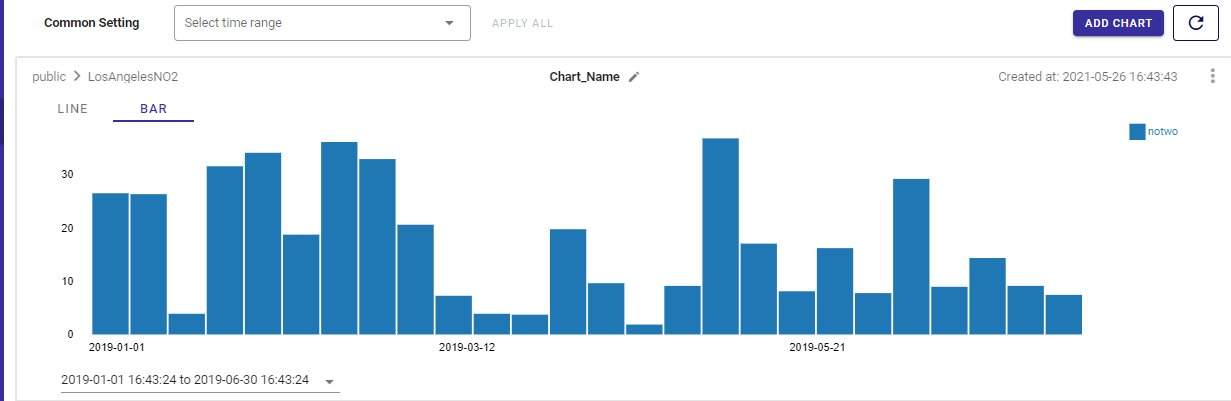
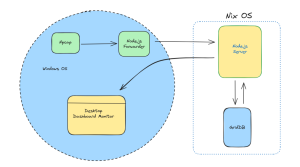
Grafana
Grafanaは、オープンソースの分析・監視ソリューションであり、詳細はこちらで紹介しています。クラウドインスタンスで使用するためには、Grafanaをダウンロードし、GridDB Web APIを設定した上で、GridDB Grafana Pluginをインストールしてください。
設定
そのため、バックエンドとしてGridDB Cloudインスタンスをうまく使えるようにするには、仮想マシン上でGrafanaを実行してインストールします。また、ローカルでアクセスするためにAzureファイアウォールで特定のポートを開いておく必要があります。方法についてはAzureポータルで仮想マシンにポートを開く方法を参照してください。
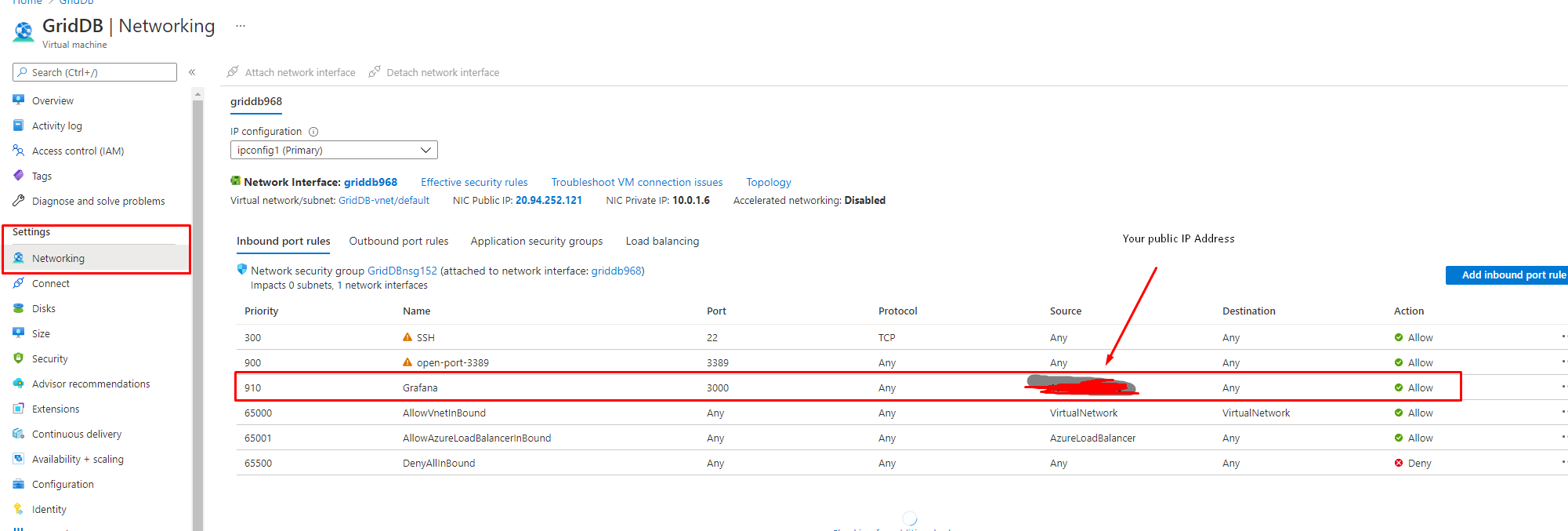
3000番ポートを開放したことが重要な点です。これで、VMのパブリックアドレスを取得してブラウザにアクセスすると、Grafanaのインスタンスが表示されます。http://<yourVMIP:3000>
アクセスできるようになった後は、GridDB Grafana Pluginを追加すれば、GridDB Web APIをデータソースとして利用できるようになります。
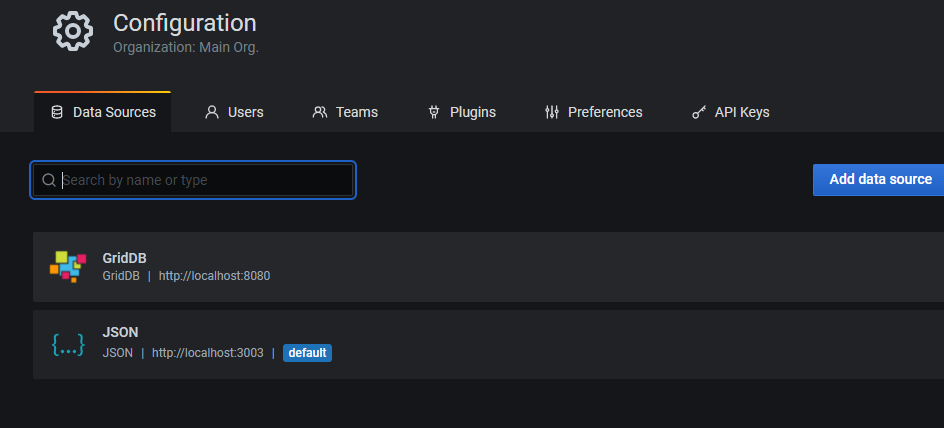
Web APIをインストールして使用する方法について、GitHubのページまたは以前のブログのいずれかを参照してください。そして、webapi-2.2.0/conf/repository.jsonファイルを編集して、GridDBクラウドインスタンスを指すようにしてください。例えば、以下のようになります。
{
"clusters" : [
{
"name" : "gs_clustertrial002",
"mode" : "PROVIDER",
"providerUrl": "http://dbaassharegssta.blob.core.windows.net/<cloud instance name>/trial002.json"
}
]
}
簡単に説明すると、別の端末でWeb APIを実行し、ポータルのデータソースとしてGridDBを追加したら、データホストをlocalhost、ポートを8080に設定します。
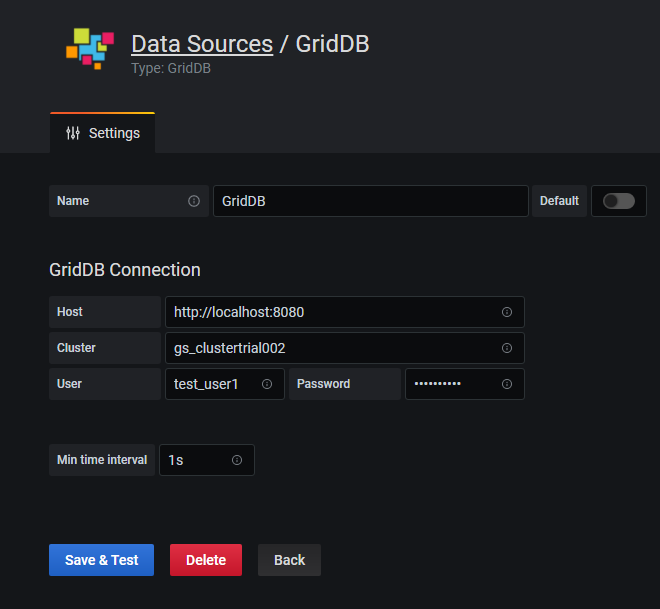
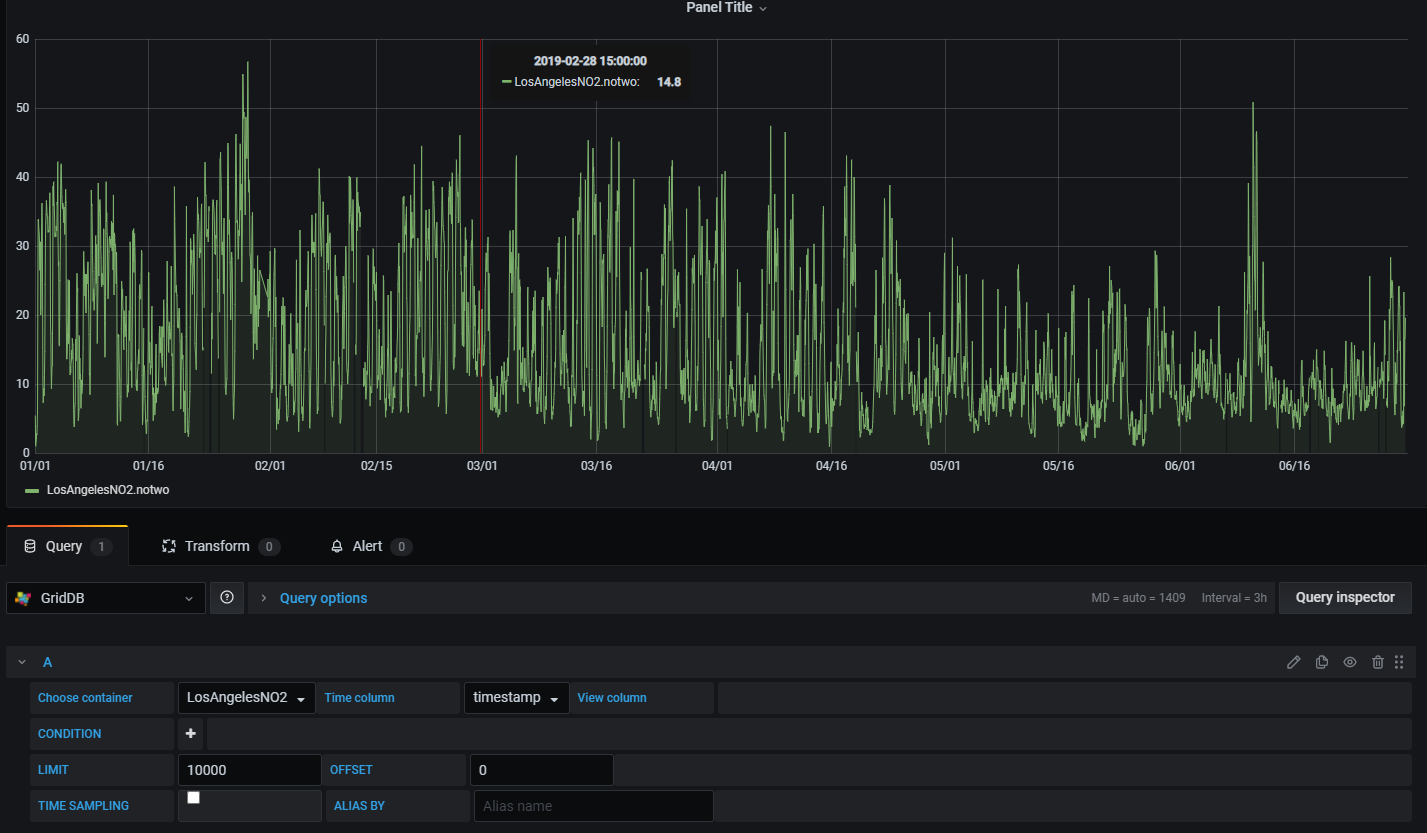
データソースが完全に統合されると、このような詳細で分かりやすいチャートを作成することができます。
結論
GridDBクラウドを利用することで、作業を効率化し、より早く実用的な概念実証アプリケーションを作成することができます。こちらからGridDBクラウドをさっそく使ってみてください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb