
このブログは、前回のこちらの暗号通貨ブログの続きです。
現在、暗号通貨市場をリードしているビットコインの時価総額は、この記事を書いている時点で10億839万9,725,691ドルとなっており、このブログを公開する頃には、その高いボラティリティのおかげで、さらに高くなっているかもしれません。
2009年にサトシ・ナカモトがビットコイン・ネットワークを発明し、その後、プログラマーのラズロ・ハニエツがパパ・ジョンズ・ピザ2枚を1万ビットコインで購入したという、暗号通貨史上初の商業取引が記録されました。当時、ビットコインには実質的な価値がなく、それほど大きな話題にはなりませんでした。しかし、この10年間で、ビットコインは史上最高値を更新し続け、高騰しています。このブログを書いている時点で、ビットコインの現在の価値は1コインあたり5万5,000ドル以上となっています。
数人の専門家が、このコインはまもなく10万ドルの大台を超えるだろうと予測しています。同様に、Ethereum、Binance Coin、XRP、ADA、その他さまざまな暗号通貨についても、今後数年間で急騰し、その価格も指数関数的に高騰すると予測されています。
さまざまな暗号通貨の価格が上昇し続けていることで、世界中の無数の個人投資家だけでなく、機関投資家をも魅了しています。従来の金融市場とは異なり、暗号通貨市場は非常に変動が激しく、予測不可能です。金融市場は予測可能ですが、暗号通貨市場は、その分散型の仕組み、関心の高まり、ボラティリティの高さゆえに、金融市場と同じことは当てはまりません。
そのため、世界中の投資家やトレーダーは、この成長し続けるダイナミックな市場で大胆な予測を行うために、ゲームで一歩先を行くための高速で信頼性の高い分析ツールを求めています。そこで、そのような需要に応えるべく、私たちはGridDBを使って過去の暗号通貨市場データを収集する簡単な方法を考えました。
このブログでは、Coingecko APIから過去の暗号通貨市場データを収集してGridDBに格納し、さらにPythonスクリプトを使って可視化することに主に焦点を当てて説明します。最初に、使用する技術について説明します。
この目標達成のために使う技術
私たちがツールを構築する際に使用する技術は以下の通りです。
- OS: Ubuntu 18.04
- Python 3.6
- GridDB c Client: v4.5.0
- GridDB Server: 最新バージョン
- GridDB Python Client: 0.8.3
データを取得し可視化する
日々の暗号通貨市場のデータを取得する方法は数多くありますが、今回は、ビットコインとイーサリアムの両方の過去のデータを収集して視覚化することに重点を置いています。
まず、ビットコインを対象とします。ビットコインが正式に誕生したのは2009年ですが、最初の数年間はコインが公開で取引されていなかったため、データを取得することはできません。もちろん、チェーンの最初のブロックでは取引が行われていますが、当時は市場で価格がコントロールされていませんでした。
今度は、Coingecko API から履歴データを取得します。そのためには、次のコマンドでPythonクライアントをインストールする必要があります。
python3.6 -m pip install pycoingecko
これから紹介するPythonスクリプトは、Coingecko APIからビットコインとイーサリアムの過去の市場データを収集し、視覚化するためのものです。
それでは早速、Pythonスクリプトを書いてみましょう。
Step I: CoinGecko APIをインポートします。
from pycoingecko import CoinGeckoAPI
Step II: Matplotlib(データ可視化用)、Pandas、Numpy、Scipyをインポートします。
install matplotlib.pylot as plt
import pandas as pd
import numpy as np
import scipy as sp
Step III: Coingecko APIs のインスタンスを作成します。
coingecko = CoinGeckoAPI()
Step IV: 使用する関数を定義します。ここでは、get_coin_by_id() APIコールを使って、指定した暗号通貨のマーケットデータを取得します。取得したデータは、cryptocurrency_data.csvに保存されます。
def get_data(cryptocurrency):
cryptocurrency_data = coingecko.get_coin_by_id(cryptocurrency, market_data='true', sparkline='true')
df = pd.DataFrame.from_dict(cryptocurrency_data, orient='index')
df.to_csv(r'cryptocurrency_data.csv')
return df
Step V: ビットコインとイーサリアムの両方のデータを取得します。
get_data('bitcoin')
get_data('ethereum')
2つのcryptocurrency_data.csvファイルが表示されています。1つずつ開いてみましょう。
ビットコインのCSVファイルはこのようになっています。

次のCSVはイーサリアムのマーケットデータを表しています。
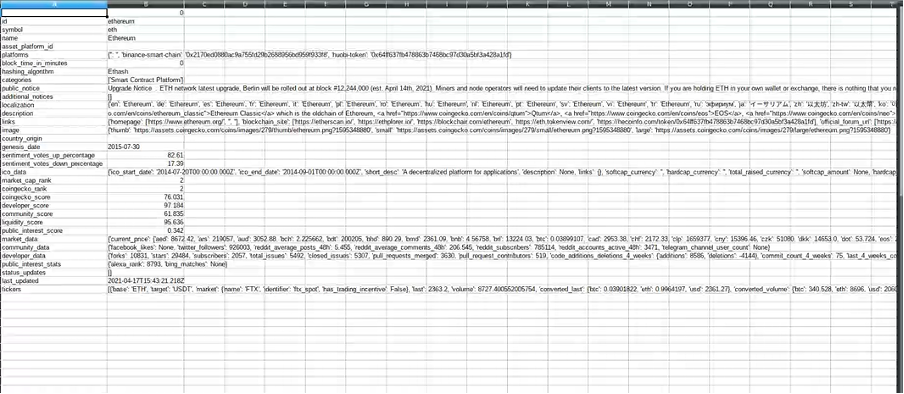
Step VI: BitcoinとEthereumの過去のマーケット・データを入手し、視覚化します。
公式ドキュメントによると、表示されるデータは日数によって異なります。ビットコインの1日のデータを追跡している場合は、分単位で表示されます。しかし、2~90日の過去のデータを追跡している場合は、データが分割され、時間単位で表示されます。
90日以上の期間について、日ごとに分割して表示します。
def get_historical_data(cryptocurrency, fiat_currency, number_of_days):
historic_price = coingecko.get_coin_market_chart_by_id(cryptocurrency, fiat_currency, number_of_days)
prices = [price[1] for price in historic_price['prices']]
return prices
ここでは、変数「prices」がリストになっています。
例えば、この関数の場合、
print(get_historical_data('bitcoin', 'USD', 5))
以下のように出力されます。

このブログをさらに2つのセクションに分けると、ここまでのセクションIはイーサリアムの30日分のデータを収集して視覚化することについて説明しました。ここからのセクションIIではビットコインについて同様に視覚化することについて説明します。
Section I: 過去30日分のイーサリアム市場データを収集し可視化する
Step I: イーサリアムの過去30日分のデータを取得し、ビットコインで行ったように変数に格納します。
ethereum = get_historical_data('ethereum', 'USD', 30)
Step II: このデータをEthereum.csvに保存します。
et_df = pd.DataFrame(ethereum, columns = ['Ethereum Value'])
et_df.index.name = 'Every Hour Count in the Past 30 Days'
et_df.to_csv(r'Ethereum.csv')
df = pd.read_csv("Ethereum.csv")
ここでは、生成されたすべてのデータをEthereum.csvに格納しています。では、それをGridDBデータベースにロードしてみましょう。
Step III: GridDBデータベースのパラメータを初期化します。
factory = griddb.StoreFactory.get_instance()
argv = sys.argv
try:
#Get GridStore object
gridstore = factory.get_store(
notification_member="griddb-server:10001",
cluster_name="defaultCluster",
username="admin",
password="admin"
)
Step IV: CSVファイルのデータフレームを作成します。
ethereum_data = pd.read_csv("/ethereum.csv", na_values=['\N'])
ethereum_data.info()
得られる結果は以下の通りです。

Step V: データベースとのやりとりをしてみましょう。GridDBコンテナと対話する通常の方法は、GridDBコンテナの中にコンテナを作成し、putまたはmulti_put関数を使って情報をロードすることです。
それでは、データを保存するためのコンテナethereum_containerを作成してみましょう。ここで最も注意すべき点は、正しいデータ型が定義されているかどうかを確認することです。そうしないと、データベースの操作を行う際にエラーが発生する可能性があります。
ethereum_container = "ETHEREUM"
ethereum_containerInfo = griddb.ContainerInfo(ethereum_container,
[["count", griddb.Type.INTEGER],["value", griddb.Type.STRING]],
griddb.ContainerType.COLLECTION, True)
ethereum_columns = gridstore.put_container(ethereum_containerInfo)
ethereum_columns.create_index("count", griddb.IndexType.DEFAULT)
ethereum_columns.put_rows(ethereum_data)
print("Data added successfully")
db_data = gridstore.get_container(ethereum_container)
コンテナを作成した後、put_rows関数を使ってデータを読み込みました。ロードされると、「Data added successfully」というメッセージが表示されます。

Step VI: 試しに、いくつかのクエリを実行してみましょう。
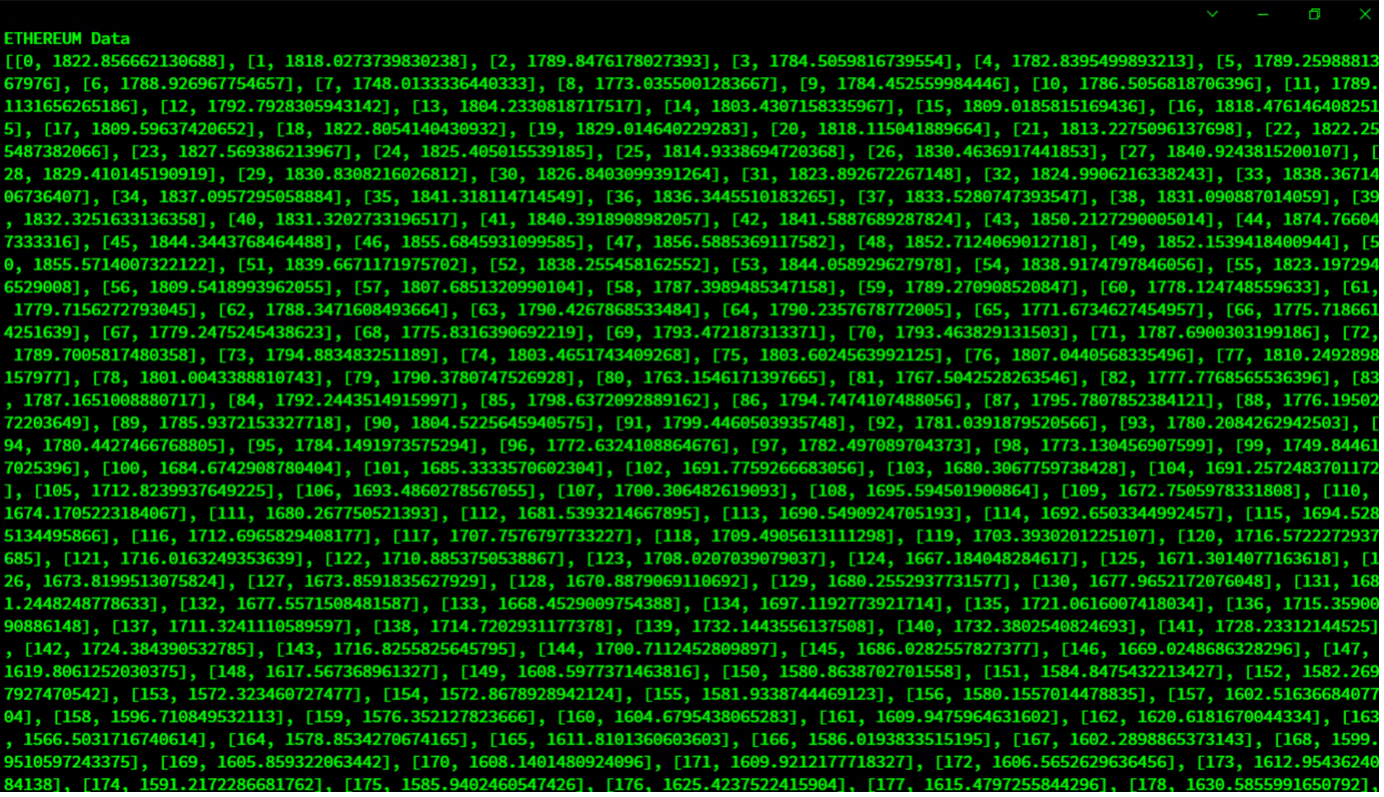
Query 1:「Select *」クエリで読み込んだEthereumのデータをすべて取得します。
query = db_data.query("Select *")
rs = query.fetch(False)
print(f"{ethereum_container} Data")
retrieved_data = []
while rs.has_next():
data = rs.next()
retrieved_data = append(newdata)
print(retrieved_data)
アウトプット:
Query 2: 追跡している30日分のデータのうち、1日目の7時間目のイーサリアムの値を取得します。
query = db_data.query("select * where count = 7")
rs = query.fetch(False)
print(f"{ethereum_container} Data")
retrieved_data = []
while rs.has_next():
data = rs.next()
retrieved_data = append(newdata)
print(retrieved_data)
アウトプット:

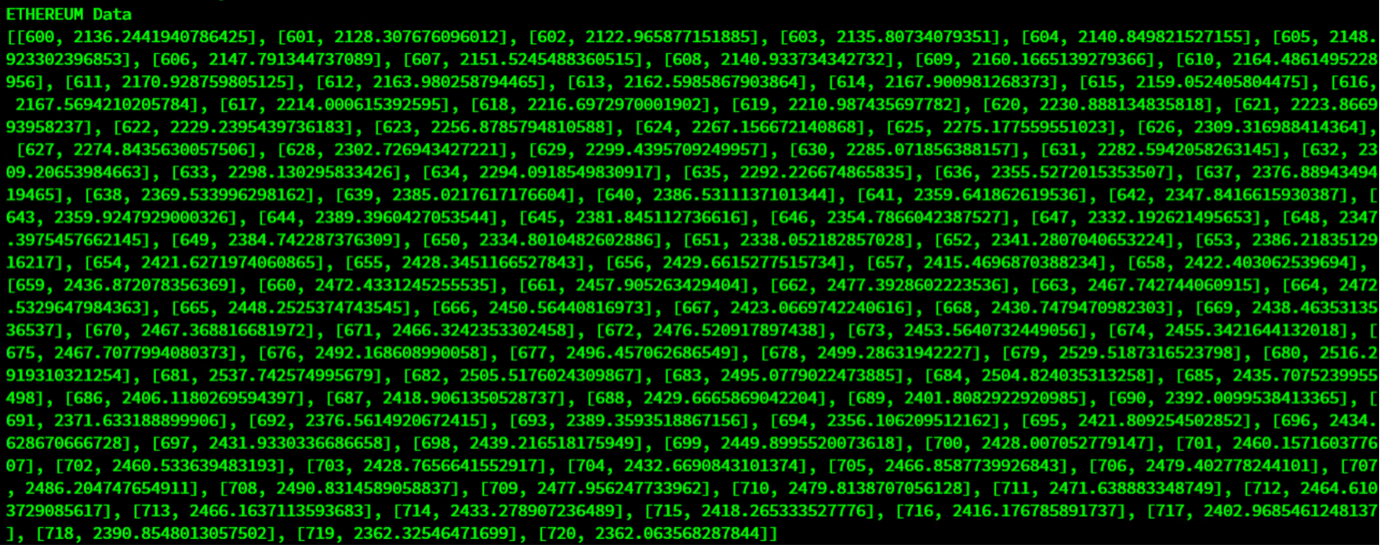
Query 3: 最近のデータを取得してみましょう。
query = db_data.query("select * where count >= 600")
rs = query.fetch(False)
print(f"{ethereum_container} Data")
retrieved_data = []
while rs.has_next():
data = rs.next()
retrieved_data = append(newdata)
print(retrieved_data)
アウトプット:
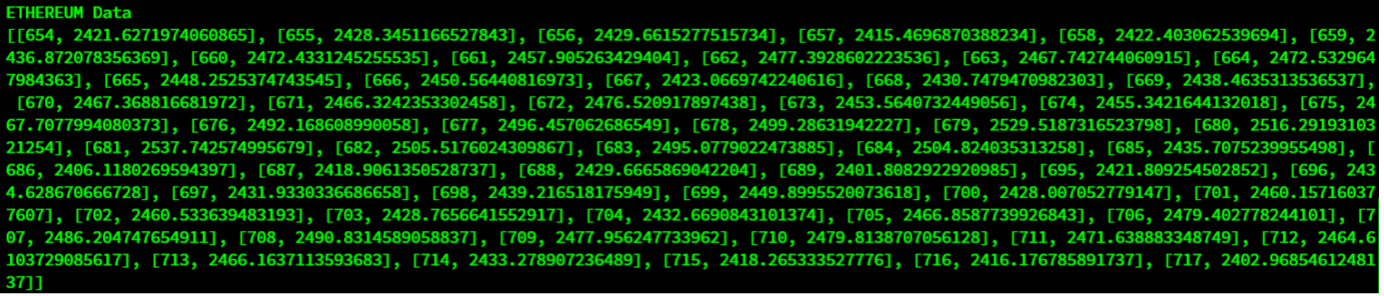
Query 4: イーサリアムの値が2,400ドルを超えた時の期間を調べてみましょう。
query = db_data.query("select * where value > 2400")
rs = query.fetch(False)
print(f"{ethereum_container} Data")
retrieved_data = []
while rs.has_next():
data = rs.next()
retrieved_data = append(newdata)
print(retrieved_data)
アウトプット:
Query V:2,000ドル以上の値についても同様に考えてみましょう。
query = db_data.query("select * where value >2000")
rs = query.fetch(False)
print(f"{ethereum_container} Data")
retrieved_data = []
while rs.has_next():
data = rs.next()
retrieved_data = append(newdata)
print(retrieved_data)
アウトプット:

Step VII: このコードを使って例外を回避します。
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))
Step VIII: 最後に、データを可視化します。
- 散布図:
df.plot(x = 'Every Hour Count in the Past 30 Days', y = 'Ethereum Value', kind = 'scatter')
plt.xlabel('Every Hour Count in the Past 30 Days')
plt.ylabel('Ethereum Value')
plt.show()
グラフ:

- 折れ線グラフ:
df.plot(x = 'Every Hour Count in the Past 30 Days', y = 'Ethereum Value', kind = 'line')
plt.xlabel('Every Hour Count in the Past 30 Days')
plt.ylabel('Ethereum Value')
plt.show()
グラフ:

- 棒グラフ:
df.plot(x = 'Every Hour Count in the Past 30 Days', y = 'Ethereum Value', kind = 'bar')
plt.xlabel('Every Hour Count in the Past 30 Days')
plt.ylabel('Ethereum Value')
plt.show()
グラフ:

- Statsmodelを使った自己相関図(Autocorrelogram or Autocorrelation Plot):
import statsmodel.api as sm
sm.graphics.tsa.plot_acf(df["Ethereum Value"])
plt.show()
グラフ:

ここまでで過去30日間のイーサリアムの市場データを可視化しましたが、次はビットコインについても同じことをしてみましょう。
Section I: 過去30日分のビットコイン市場データを収集し可視化する
Step I:過去30日分のビットコインのデータを取得し、分析しやすいようにこのリストを変数に格納します。
bitcoin = get_historical_data('bitcoin', 'USD', 30)
Step II: これらのデータをすべてCSVで保存します。
bt_df = pd.DataFrame(bitcoin, columns = ['Bitcoin Value'])
bt_df.index.name = 'Every Hour Count in the Past 30 Days'
bt_df.to_csv(r'Bitcoin.csv')
df = pd.read_csv("Bitcoin.csv")
ここでは、生成されたすべてのデータをBitcoin.csvに格納しています。Bitcoinの全データをGridDBデータベースにロードすることもできますが、ここでは可視化するだけにします。
Step III: 可視化します。
- 散布図:
df.plot(x = 'Every Hour Count in the Past 30 Days', y = 'Bitcoin Value', kind = 'scatter')
plt.xlabel('Every Hour Count in the Past 30 Days')
plt.ylabel('Bitcoin Value')
plt.show()
グラフ:

- 折れ線グラフ:
df.plot(x = 'Every Hour Count in the Past 30 Days', y = 'Bitcoin Value', kind = 'line')
plt.xlabel('Every Hour Count in the Past 30 Days')
plt.ylabel('Bitcoin Value')
plt.show()
グラフ:

- 棒グラフ:
df.plot(x = 'Every Hour Count in the Past 30 Days', y = 'Bitcoin Value', kind = 'bar')
plt.xlabel('Every Hour Count in the Past 30 Days')
plt.ylabel('Bitcoin Value')
plt.show()
グラフ:

注: 過去30日間の1時間ごとのデータを追跡しているため、X軸のすべての値がぶつかっています。
Statsmodelを用いた自己相関図(Autocorrelogram or Autocorrelation Plot):
import statsmodel.api as sm
sm.graphics.tsa.plot_acf(df["Bitcoin Value"])
plt.show()
グラフ:

同様に、Coingecko APIでサポートされている他の暗号通貨の過去のデータを取得し、視覚化することもできます。
まとめ
ビットコインやイーサリアムなどの暗号通貨への投資を考えている方は、今回のブログのようにデータを収集して可視化して、リサーチを行うことができます。
全ソースコードはこちらのGitHubからご覧いただけます。