
データセットと環境設定
この記事では、GridDBとJavaを使って時系列データセットを分析して取り込む方法を説明します。分析するデータは、不動産物件の売上の詳細に関して公開されているデータセットです。このリンクからデータセットをダウンロードできます。
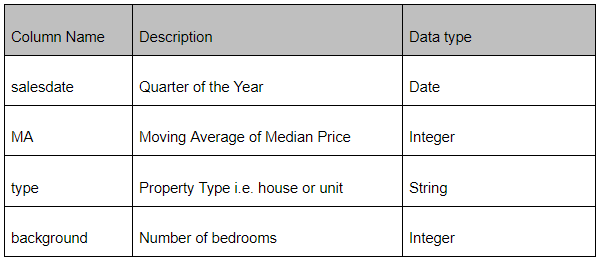
まず、データセットの構造を見てみましょう。データセットを理解するためには次の表を参照してください。
今回の実装でGridDBを使用したのは、GridDBには時系列データに最適な独自の機能があるためです。
この記事では時系列データとGridDBについてわかりやすく説明しています。
実装を始める前に、JavaクライアントでGridDBサーバーを設定する必要があります。
まだ設定していない場合は、こちらのクイックスタートガイドに従って設定してください。
この記事では、接続、GridStoreの取得、データの保存の方法については詳しく扱いません。主にデータセットの分析に焦点を当てます。では、実装について説明します。
カラム名を宣言し、GridStoreインスタンスを取得する
最初に、データセットの属性を次のようにstaticな内部クラスとして宣言する必要があります。
static class Sales {
@RowKey Date salesdate;
int MA;
String type;
int bedrooms;
}データセットに応じて、4つの属性があります。ここでは、読みやすさを考慮してカラム名と同じ名前を使っています。 @RowKey 構文は、ドキュメントの行キーを識別するために使っています。
次に、GridStoreインスタンスを取得し、時系列を作成します。
GridStoreを取得するには、通知アドレス、通知ポート、ユーザー名、パスワードなどのプロパティを設定します。
データセットの読み取りと保存
データベースに保存するため、データをデータセットから読み取って前処理する必要があります。
このデータセットの日付の形式は 「dd/MM/yyyy」 です。ただし、日付はタイムスタンプとして保存する必要があります。
このデータセットは時刻が指定されていないので、 「00:00」 に設定することにします。その他のカラム値は、変更しなくても保存できます。
File csvFile = new File("ma_lga_12345.csv");
Scanner sc = new Scanner(csvFile);
String data = sc.next();
while (sc.hasNext()) {
String scData = sc.next();
String dataList[] = scData.split(",");
String salesdate = dataList[0];
String MA = dataList[1];
String type = dataList[2];
String bedrooms = dataList[3];
Sales sales = new Sales();
sales.salesdate = convertDateToTimeStamp(salesdate);
sales.MA = Integer.parseInt(MA);
sales.type = type;
sales.bedrooms = Integer.parseInt(bedrooms);
ts.append(sales);
}上記のコードは、行ごとにCSVファイルを読み取って関連データを抽出し、salesオブジェクトを作成します。それから作成した sales オブジェクトがデータベースに追加されます。
convertDateToTimeStamp メソッドを使って、次のようにデータセットの販売日をタイムスタンプに変換します。
static Date convertDateToTimeStamp(date) {
String OLD_FORMAT = "dd/MM/yyyy";
String NEW_FORMAT = "yyyy/MM/dd";
SimpleDateFormat format = new SimpleDateFormat("yyyy/MM/ddHH:mm:ss");
SimpleDateFormat sdf = new SimpleDateFormat(OLD_FORMAT);
Date d = sdf.parse(salesdate);
sdf.applyPattern(NEW_FORMAT);
String newDateString = sdf.format(d);
String datetimes = newDateString +"00"+":00:00";
Date dates = format.parse(datetimes);
Long dt = dates.getTime();
return new Date(dt);
}Java の SimpleDateFormat パッケージを使って日付をタイムスタンプに変換しました。これで必要なデータがすべてデータベースに保存されました。
データ分析
ここからは、用意したデータセットの分析に取りかかれます。ここで不動産販売データに適用したデータ分析法は、他の課題シナリオでも使えるように一般化することができます。
指定した時間範囲内のデータ取得
まず指定範囲の時系列要素の抽出方法を見てみます。例として時間範囲は4か月とします。そこで必要となるのが、現在のタイムスタンプから4か月前までのデータの抽出です。このコードを読んで、実装しているロジックと構文を把握してください。
Date now = TimestampUtils.current();
Date before = TimestampUtils.add(now, -4, TimeUnit.MONTH);
RowSet rs = ts.query(before, now).fetch();
while (rs.hasNext()) {
Sales sales = new Sales();
sales = rs.next();
System.out.println("Sales Date=" + TimestampUtils.format(sales.salesdate) +
" MA =" + sales.MA +
" Type" + sales.type +
" Bedrooms" + sales.bedrooms);
}
このコードの1行目で現在のタイムスタンプを取得しています。そのため今回の実装ではTimestampUtilsメソッドを使っています。次に現在の時刻から4か月分を引く必要があります。これにはTimestampUtils.addメソッドを使います。現在の時刻に特定の時間を足したい場合は、関数内の時間の前にある 「-」 記号を削除します。
時間単位の変更は、足したり引いたりする必要がある時間範囲に応じてTimeUnit.MONTH、TimeUnit.HOURSなどと指定するだけです。
現在、2つのタイムスタンプがあります。1つ目は現在の時刻、2つ目は4か月前のタイムスタンプです。この時間範囲のデータを取得するためのクエリ作成は非常に簡単です。
RowSet rs = ts.query(before, now).fetch();これで指定した時間範囲内のデータ行がすべて表示されます。ただし、上記のコードで複数行が出力される場合があります。そのため、サンプルコードで行っているように、データ行を1つずつ読み込んでください。
行データを変数に取り出したら、そのデータを表示したり任意の操作を適用したりできます。
データベースのクエリ
ここで、SQLクエリと同じ属性で複数の条件を持つクエリを作成し、データを抽出する方法を説明します。
ユーザーは、MA値が5万ドル未満の住宅の種類を降順にソートした最初の20件の詳細情報を取得しなければならないと仮定します。まず、このシナリオのクエリの書き方を見てみます。
Select * from sales01 where type=’unit’ and MA <5000 order by MA desc limit 20SQLに精通している方なら、今回のシナリオでどのようにSQLクエリを書くかわかるでしょう。重要なのは、このクエリと、その他ほとんどのクエリの構文はSQLに似ていますが、GridDB (TQL)とSQLで使うクエリ言語には違いがあるということです。
今書いたクエリでアウトプットを取得する方法を見てみましょう。
Query query = ts.query("select * from sales01" +
" where type='unit' and MA < 50000 order by MA desc limit 20");
RowSet res = query.fetch();上記のコードは、任意のクエリから結果を取得する方法です。先の例と同様に、結果として行が取得できたかどうかを確認し、抽出データに関連する操作を適用しなければなりません。
抽出データの平均値の計算
最後に、指定の時間範囲内にある特定のデータ値の平均値を取得する方法について説明します。
指定した日付の2か月前から2か月後までの4か月間の平均MA値を取得します。
salesTimeはユーザーが指定したタイムスタンプだと仮定します。
Date start = TimestampUtils.add(salesTime, -2, TimeUnit.MONTH);
Date end = TimestampUtils.add(salesTime, 2, TimeUnit.MONTH);
AggregationResult avg = ts.aggregate(start, end, "MA", Aggregation.AVERAGE);
System.out.println(“avg=" + avg.getDouble());前述したように、開始時刻と終了時刻はTimestampUtils.addメソッドを使って取得できます。ここで指定した時間範囲内の平均MA値を取得しますが、次の集計方法で行います。
AggregationResult avg = ts.aggregate(start, end, "MA", Aggregation.AVERAGE);一旦avg変数の平均値を取得すれば、適切な操作を適用できます。例えば、データベースに値を保存したり、値をパラメータとして別の関数に渡したり、単に標準出力に出力したりすることができます。
Conclusion
いいですね。今回は以上です。この記事では、Javaで不動産販売データを分析する簡単な方法について説明し、時系列データセットの操作にGridDBを使いました。この技術により一層親しみ、もっと複雑なメソッドをデータ分析に追加して、さらなる機能改善にお役立てください。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.