データ分析は、データから有用な情報を抽出し、意思決定プロセスに役立てることを目的としています。しかし、モバイル機器やセンサーなどの外部ソースから得られる生データには、多くの外れ値が含まれています。さらに、データは高次元である可能性もあり、データの要約統計量を解釈するのは難しくなります。そのため、現在では、生データを入手して人間が解釈できる結果を得るまでのプロセスを総称して、データ分析と呼んでいます。したがって、データ分析は、データから意味のある情報を抽出できるように、データのクリーニング、変換、モデリングを行うことで構成されます。
優れたデータ分析システムの最も重要な前提条件は、信頼できるデータベースです。データベースは拡張性があり、大規模なデータセットに簡単にクエリを実行できる必要があります。このような機能をすべて備えた最新のデータベースのひとつがGridDBです。GridDBは高性能で、多くのプログラミング言語と簡単に統合することができます。この記事では、PythonとGridDBを使っていくつかのデータを分析してみます。分析には様々な種類がありますが、この記事ではランダムフォレストモデルに焦点を当てます。
GridDBのセットアップ
このビデオでは、GridDBのPythonクライアントのセットアップガイドを紹介しています。
Pythonライブラリ
分析にはpython 3.6とpandasを使用します。
ライブラリのインストールには以下のコマンドを使用します。
pip install pandas
pip install scikit-learn
pip install plotly
pip install matplotlib
各ライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import plotly.graph_objs as go
from plotly.subplots import make_subplots
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score as f1
データ収集
GridDBは、データにアクセスするための優れたインターフェースを提供します。こちらのGridDB Pythonクライアントに関するブログでは、GridDBデータベースをリンクし、すべてのデータをpandasのデータフレームにプッシュする方法を詳しく説明しています。
今回の分析では、クレジットカードのデータを使って、解約率を予測します。データはこちらから入手できます。
コンテナをインスタンス化し、すべてのデータをpandasのデータフレームに格納することで、GridDBをデータベースとして設定することができます。
import griddb_python as griddb
# Initialize container
gridstore = factory.get_store(host= host, port=port,
cluster_name=cluster_name, username=uname,
password=pwd)
conInfo = griddb.ContainerInfo("attrition",
[["CLIENTNUM", griddb.Type.LONG],
["Gender",griddb.Type.STRING],
.... #for all 23 variables
griddb.ContainerType.COLLECTION, True)
cont = gridstore.put_container(conInfo)
cont.create_index("CLIENTNUM", griddb.IndexType.DEFAULT)
以下のSQLクエリを用いて、GridDBからデータを取得することができます。
query = cont.query("select *")
データ解析のパイプラインは、以下のステップで構成されています。
- データ検索: 我々はまず、様々な変数の要約統計を行い、従属変数である生存率との相関を理解しようとします。また、外れ値があればそれを除去するためにデータセットのクリーニングを行います。
- 特徴量エンジニアリング: そして、モデリングに使用できる特徴量を選択していきます。既存のデータやオープンソースのリソースから、新しい特徴量を作成することができます。
- モデリング: そして、機械学習モデル、ここではランダムフォレストを使用します。まず、データをテストセットとトレーニングセットに分けます。通常は、学習データでモデルを学習し、テストセットで評価します。モデルのハイパーパラメータを調整するために、検証セットを用意したり、クロスバリデーションを行ったりすることもあります。
- 評価: 最後に、このモデルを使って予測を行い、その性能を分析します。
データ収集と探査
pandasを使ってデータを読み込みます。最後の2列は別の分類器の結果なので削除します。
data = pd.read_csv('/kaggle/input/credit-card-customers/BankChurners.csv')
data = data[data.columns[:-2]]
まず、いくつかの変数の要約統計量を作成します。理想的にはすべての変数をチェックすることですが、簡潔にするためにいくつかの重要な変数を紹介します。
Attrition_Flag:
attdata = data.groupby(['Attrition_Flag']).count()[["CLIENTNUM"]].reset_index()
attdata['percentage'] = attdata['CLIENTNUM']/attdata['CLIENTNUM'].sum()
attdata[attdata.Attrition_Flag == "Attrited Customer"]
| CLIENTNUM | percentage |
|---|---|
| 1627 | 0.16066 |
解約率は約16%です。
人口統計学的変数
性別
genderdata = data.groupby(['Gender']).count()[["CLIENTNUM"]].reset_index()
genderdata['percentage'] = genderdata['CLIENTNUM']/genderdata['CLIENTNUM'].sum()
genderdata[genderdata.Gender == "F"]
| CLIENTNUM | percentage |
|---|---|
| 5358 | 0.529081 |
女性が52.9%いることがわかります。しかし、男女の差はそれほど大きくありません。
教育
data.groupby(['Education_Level']).count()[["CLIENTNUM"]].reset_index()
Education_Level
| Type | Number |
|---|---|
| College | 1013 |
| Doctorate | 451 |
| Graduate | 3128 |
| High School | 2013 |
| Post-Graduate | 516 |
| Uneducated | 1487 |
| Unknown | 1519 |
お客様の約7割が教育を受けていることがわかります。
Income_Category
data.groupby(['Income_Category']).count()[["CLIENTNUM"]].reset_index()
| Income_Category | Number |
|---|---|
| $120K + | 727 |
| 40k− 60k | 1790 |
| 60k− *80K | 1402 |
| Less than $40k | 3561 |
| Unknown | 1112 |
ほとんどの人が4万ドル以下の収入であることがわかります。
Bank variables
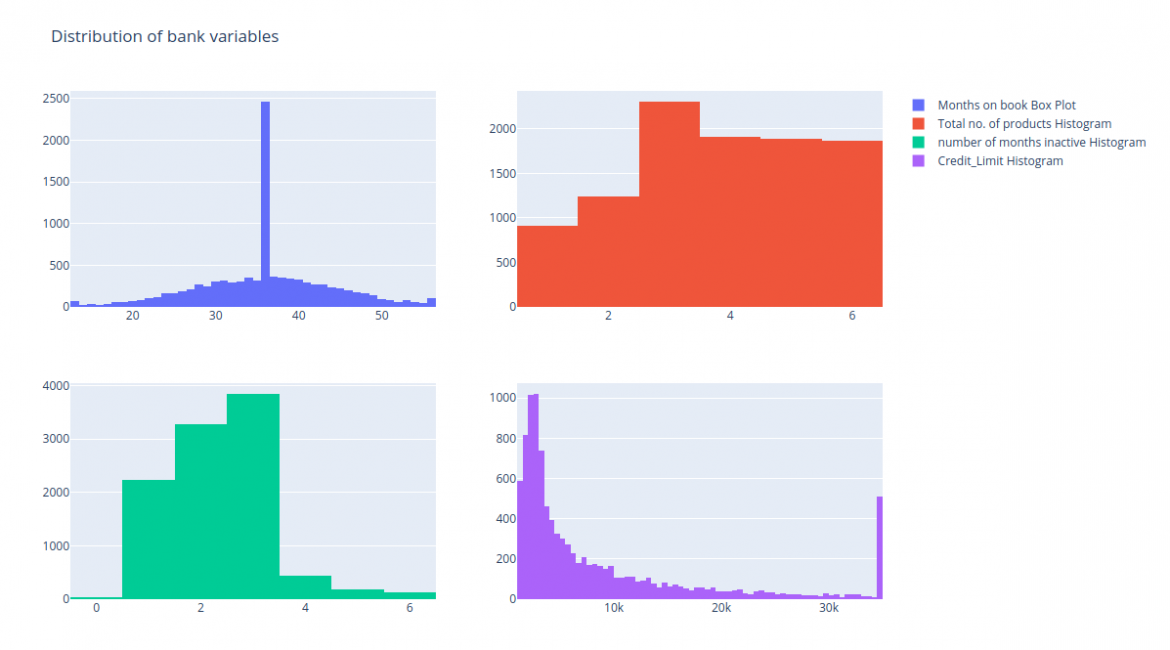
'Months_on_book', 'Total_Relationship_Count' (お客様がお持ちの製品の合計数), 'Months_Inactive_12_mon' (過去12ヶ月間に活動しなかった月数), そして 'Credit_Limit' (クレジットカードのご利用限度額) のヒストグラムを描いてみます。
fig = make_subplots(rows=2, cols=2)
tr1=go.Histogram(x=data['Months_on_book'],name='Months on book Box Plot')
tr2=go.Histogram(x=data['Total_Relationship_Count'],name='Total no. of products Histogram')
tr3=go.Histogram(x=data['Months_Inactive_12_mon'],name='number of months inactive Histogram')
tr4=go.Histogram(x=data['Credit_Limit'],name='Credit_Limit Histogram')
fig.add_trace(tr1,row=1,col=1)
fig.add_trace(tr2,row=1,col=2)
fig.add_trace(tr3,row=2,col=1)
fig.add_trace(tr4,row=2,col=2)
fig.update_layout(height=700, width=1200, title_text="Distribution of bank variables")
fig.show()
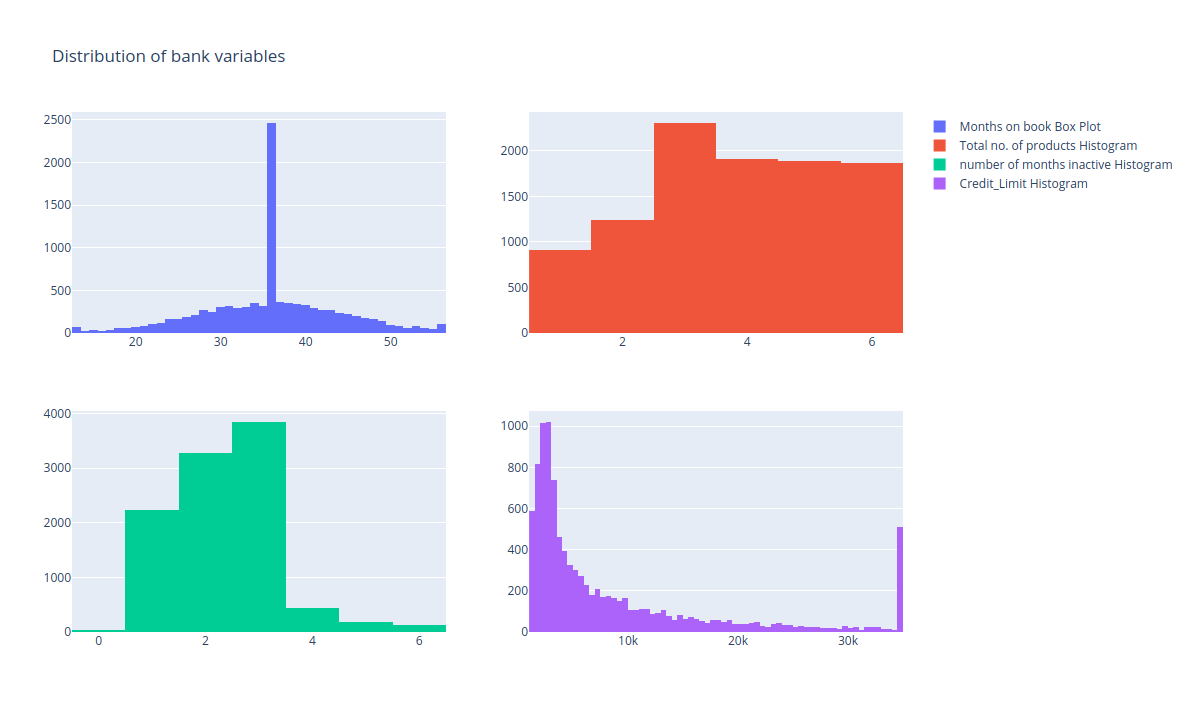
製品総数の分布はほぼ一様であることがわかりますので、理想的にはこの変数を分析から外すことができます。他の変数は多くの変動を示しているので、それらを維持することができます。
Card_Category
data.groupby(['Card_Category']).count()[["CLIENTNUM"]].reset_index()
| Card_Category | Total |
|---|---|
| Blue | 9496 |
| Gold | 116 |
| Platinum | 20 |
| Silver | 555 |
ほとんどのお客様がBlueを使用していることがわかりますので、この変数も無視して構いません。
特徴量エンジニアリング
今回の分析では、顧客番号を無視することができます。しかし、銀行がより多くのデータソースを持っていた場合、異なるデータセットを照合するために顧客番号を使用することができます。
解約率を予測したいので、解約率フラグが従属変数となります。これを0,1の変数としてコーディングします。
次に、ダミー変数を作成します。ダミー変数は、基本的に1つのカテゴリーの変数をエンコードします。私たちは、1つのカテゴリーを省きます。そうしないと、共線性の問題に直面することになります。我々は人口統計学的変数から以下のダミー変数を作成します。これはHot-One Encodingとも呼ばれます。
- Education_Levels
- Income
- Marital status
data.Attrition_Flag = data.Attrition_Flag.replace({'Attrited Customer':1,'Existing Customer':0})
data.Gender = data.Gender.replace({'F':1,'M':0})
data = pd.concat([data,pd.get_dummies(data['Education_Level']).drop(columns=['Unknown'])],axis=1)
data = pd.concat([data,pd.get_dummies(data['Income_Category']).drop(columns=['Unknown'])],axis=1)
data = pd.concat([data,pd.get_dummies(data['Marital_Status']).drop(columns=['Unknown'])],axis=1)
data.drop(columns = ['Education_Level','Income_Category','Marital_Status','Card_Category','CLIENTNUM', 'Card_Category'],inplace=True, errors = "ignore")
データモデリング
次に、データをテストとトレーニングに分けた後、100本の木を使ってシンプルなランダムフォレストモデルを実行します。
X_features = ['Customer_Age', 'Gender', 'Dependent_count',
'Months_on_book', 'Total_Relationship_Count', 'Months_Inactive_12_mon',
'Contcts_Count_12_mon', 'Credit_Limit', 'Total_Revolving_Bal',
'Avg_Open_To_Buy', 'Total_Amt_Chng_Q4_Q1', 'Total_Trans_Amt',
'Total_Trans_Ct', 'Total_Ct_Chng_Q4_Q1', 'Avg_Utilization_Ratio',
'College', 'Doctorate', 'Graduate', 'High School', 'Post-Graduate',
'Uneducated', '$120K +', '$40K - $60K', '$60K - $80K', '$80K - $120K',
'Less than $40K', 'Divorced', 'Married', 'Single']
X = data[X_features]
y = data['Attrition_Flag']
train_x,test_x,train_y,test_y = train_test_split(X,y,random_state=42)
rf = RandomForestClassifier(n_estimators = 100, random_state = 42)
rf.fit(train_x,train_y)
評価
予測のF1スコアを求めます。F1は精度とリコールの調和的平均として定義されます。
rf_prediction = rf_pipe.predict(test_x)
print('F1 Score of Random Forest Model On Test Set {}'.format(f1(rf_prediction,test_y)))
また、ランダムフォレストモデルからは、相対的な変数の重要性を得ることができます。
importances = rf.feature_importances_
indices = np.argsort(importances)
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()
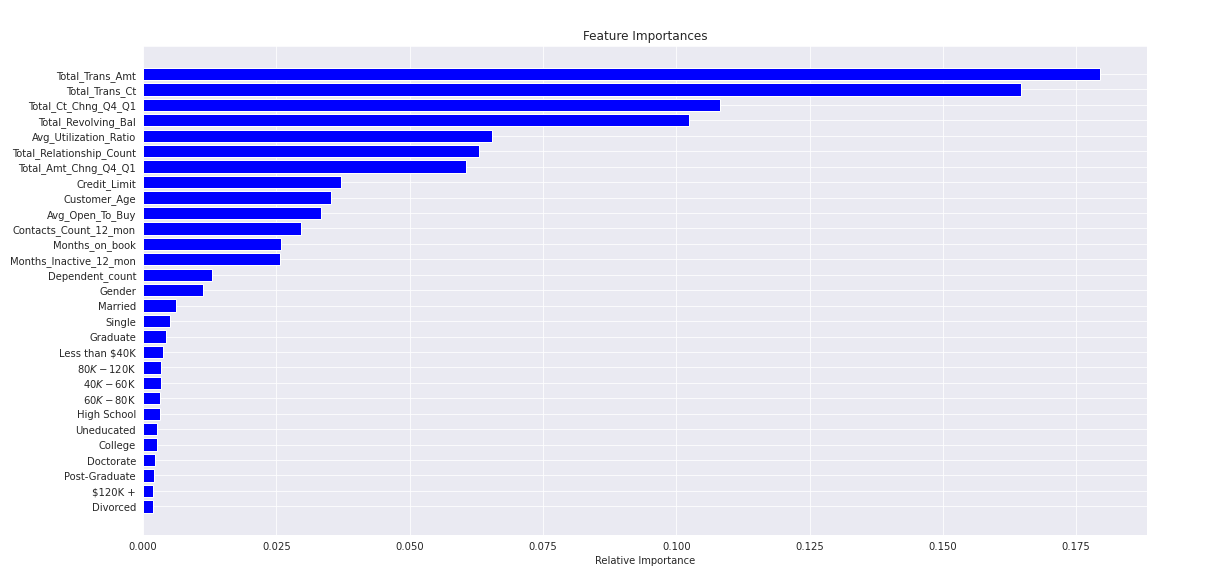
トランザクションの合計金額が最も重要な変数であることがわかります。
まとめ
この記事では、pythonとGridDBを使ったデータ分析と予測モデリングの基礎を学びました。
ソースコード
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb