概要と目的
使用例
自分が複合ビルのオーナーだとします。電力消費量を監視するスマートメーターを建物のあちこちに設置していて、各装置は1分間に2回、タイムスタンプを作成します。電力消費量のデータはキロワットで、タイムスタンプはエポック秒の形式で保存され、毎月IoTプロバイダからCSVファイルが届きます。
目的
省エネ案を立案したいとします。それにはまず、電力消費量のパターンを特定するのが良いでしょう。つまり、電力がどのように消費されているか、消費量が少ない時間帯はいつか、電力消費量が特に多い時間帯はいつか、などです。そこで回帰分析などの高度な方法を使わずに、個々のデータを可視化することで、時系列データのパターンを把握することにします。
方法
この記事では抽出した生データをGridDBに保存し、Jupyter Notebookで可視化する方法を説明します。後者はデータのトレンドやパターンを調べたり、レポートを作成したりするのに非常に便利です。Jupyterにはコードチャンク用のセル、自分の考えやメモなどを書き留めるシンプルなテキスト用のセルがあります。Jupyter Notebookは大量のデータをロードして簡単に分析することができる、データサイエンティストの強力なツールです。
Jupyter NotebookはすべてのPythonパッケージで動作します。
前提条件
このチュートリアルは、JupyterをインストールしGridDBへアクセスする方法を説明したGridDBの過去のブログ記事を基にしています。
チュートリアルを始めるにあたり、前述のインストールをどちらも完了する必要があります。
データベースにデータを保存する
公開されているIoTデータセットからデータベースを構築します。
このデータは、大学構内の電力消費量のスマートメーターのデータです。
1か月分の計86192個のデータがあり、チュートリアルの手順を説明するには十分な量です。
では実際の作業にとりかかりましょう
データベースにアクセスする
まずJayDeBeApi Pythonパッケージを使って、このデータベースにアクセスします。
import jaydebeapi
conn = jaydebeapi.connect("com.toshiba.mwcloud.gs.sql.Driver",
"jdbc:gs://griddb:20001/defaultCluster/public?notificationMember:127.0.0.1:20001",
["admin", "admin"],
"/usr/share/java/gridstore-jdbc-4.5.0.jar",)
curs = conn.cursor()
テーブルを作成する
データベースへの接続が確立され、データを挿入できるようになりました。
クエリはSQLで書きます。
このクエリをcurs.execute()を使ってデータベースに送信します。
最初のクエリは、データテーブルを作成するクエリです。
curs.execute('CREATE TABLE power2(timestamp INTEGER, power FLOAT)')
データを挿入する
データをCSVファイルからデータベースにロードします。
Jupyterを使って直接、データをデータフレームに保存し、それをGriDBに送信できます。
定期的に新しいデータを取得する場合、この手順を繰り返すことでデータベースに新しいデータを追加したり、この動作を自動化したりできます。
info()関数やhead()関数を呼び出して簡単なチェックを行うのはよい習慣です。ずいぶん頭痛の種を減らせるでしょう。
データにギャップやおかしな箇所があっても、早期に気づくことができます。
import pandas as pd
power = pd.read_csv('Power.csv', names = ['timestamp', 'power'])
power.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 86192 entries, 0 to 86191
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 timestamp 86192 non-null float64
1 power 86192 non-null float64
dtypes: float64(2)
memory usage: 1.3 MB
pd.options.display.float_format = '{:.2f}'.format
power.head()
| timestamp | power | |
|---|---|---|
| 0 | 1401595223 | 0.00 |
| 1 | 1401595253 | 0.00 |
| 2 | 1401595283 | 0.00 |
| 3 | 1401595313 | 0.00 |
| 4 | 1401595343 | 0.00 |
今の時点では、タイムスタンプのカラムは意味をなしません。
最後にゼロが3つありますが、ひょっとしたら秒に加えてミリ秒も計測するはずのところ、スマートメーターがそれに失敗したのかもしれません。
今の状態ではタイムスタンプが長すぎて、データベースに書き込めません。
それに浮動小数点数では、ほとんど意味がありません。エポック秒は整数でなければなりません。
これらの問題を解消しましょう
別のデータセットでこのチュートリアルを試して同じ問題が起きない場合、この手順はスキップしてください。
ポイントは、データベースに書き込む前にタイムスタンプの形式を整数にしなければならないということです。
power['timestamp'] = (power['timestamp']/1000).astype(int)
power.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 86192 entries, 0 to 86191
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 timestamp 86192 non-null int64
1 power 86192 non-null float64
dtypes: float64(1), int64(1)
memory usage: 1.3 MB
データは正常に表示され、どちらの型も、作成した表のカラムのデータ型と一致しています。
これでデータフレームからデータベースにデータを入力する準備が整いました。
for row in power.itertuples():
curs.execute('''
INSERT INTO power2 (timestamp, power)
VALUES (?,?)
''',
(row.timestamp,
row.power)
)
conn.commit()
データが挿入されるのを我慢して待てば、もう一度簡単なチェックを行いデータベースから何が返されるか確認できます。
ここからは、pandasパッケージのread_sql_query()関数を使ってデータベースのテーブルとやりとりします。
この関数が、データをフェッチしてpandasのデータフレームに変換します。
成功したか確認する
sql = ('SELECT power, timestamp FROM power2 LiMIT 1')
sql_query = pd.read_sql_query(sql, conn)
sql_query
| power | timestamp | |
|---|---|---|
| 0 | 0.00 | 1401595223 |
期待どおりのデータのようなので、引き続きすべての行をロードします。
sql = ('SELECT power, timestamp FROM power2')
sql_query = pd.read_sql_query(sql, conn)
sql_query.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 86192 entries, 0 to 86191
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 power 86192 non-null float64
1 timestamp 86192 non-null int64
dtypes: float64(1), int64(1)
memory usage: 1.3 MB
カラムの形式は、どちらも浮動小数点数です。
その中から異なるデータフレームを3つ作成し、電力消費量のパターンを把握します。
次のステップ、データの準備に進みましょう!
最初の考察
手始めに、できるかぎり簡単な方法でデータを可視化するのに折れ線グラフを使います。
高度な方法を行う前に、データを広い視点で見ておくとよいでしょう。
例えば、特定のデータをクローズアップしたり、(現時点でアイデアを持っていませんが)特定のディメンションに焦点を当てたり、特定のパターンを検索したりするなど、次の手順を考える上で役立ちます。
少し準備する
データをプロットするには、エポック秒をdatetime形式に変換しなければなりません。
そこから文字列を作成し、to_datetime() 関数を適用します。
sql_query['timestamp2'] = sql_query['timestamp'].apply(str)
sql_query.head()
| power | timestamp | timestamp2 | |
|---|---|---|---|
| 0 | 0.00 | 1401595223 | 1401595223 |
| 1 | 0.00 | 1401595253 | 1401595253 |
| 2 | 0.00 | 1401595283 | 1401595283 |
| 3 | 0.00 | 1401595313 | 1401595313 |
| 4 | 0.00 | 1401595343 | 1401595343 |
sql_query['datetime'] = sql_query['timestamp2'].apply(lambda x: pd.to_datetime(x, unit='s'))
sql_query.head()
| power | timestamp | timestamp2 | datetime | |
|---|---|---|---|---|
| 0 | 0.00 | 1401595223 | 1401595223 | 2014-06-01 04:00:23 |
| 1 | 0.00 | 1401595253 | 1401595253 | 2014-06-01 04:00:53 |
| 2 | 0.00 | 1401595283 | 1401595283 | 2014-06-01 04:01:23 |
| 3 | 0.00 | 1401595313 | 1401595313 | 2014-06-01 04:01:53 |
| 4 | 0.00 | 1401595343 | 1401595343 | 2014-06-01 04:02:23 |
これで最初のグラフを作成する準備が整いました。
折れ線グラフと最初の結論
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (20, 8) # Change the plot size
sql_query.plot(y = 'power', x = 'datetime', grid=True)
<AxesSubplot:xlabel='datetime'>
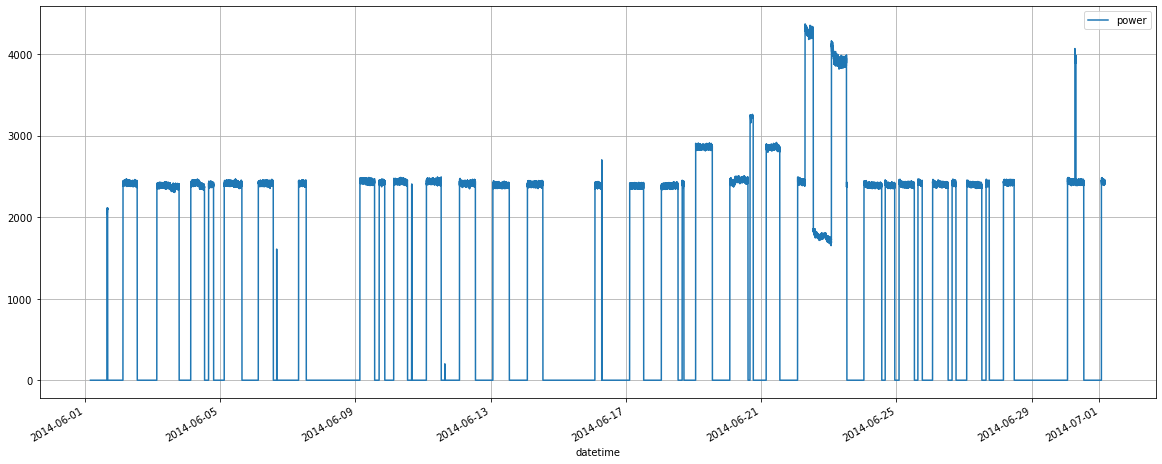
このグラフを見ると、かなり多くのことがわかります。
電力消費が突出している箇所が数日ありますが、それを除けば電力消費量は平坦なトレンドです。
毎日の電力消費量は一定で、夜間は減少し、週末の2日間にギャップがあることが読み取れます。
昼夜で大きな違いは見つかりません。
日中は直線ではなく曲線が見られます。
さらに推察できることとして、夜間の電力消費量が常にゼロになることはありません。
冷暖房システムがあります。消費量は気温に大きく左右されるので、毎日同じということはあり得ません。
このグラフからまだ他にパターンを見つけられるかもしれませんが、もっと高度なグラフに進みましょう。
パターンを見つける
移動平均
夜間のギャップがあるため、毎日のピーク時の消費量が「平坦」に見えてしまいます。
日々の数値の相違点を特定し、トレンドを見つけたいです。
そこで移動平均を追加して、線をさらに平坦にします。
24時間ごとの消費量の平均データを算出し、1日の中で任意の時点に割り当てます。
タイムスタンプは30秒ごとに作成される設定なので、30秒と60秒地点の24時間分で2880行のデータから平均値を算出します。
またrolling windowは、グラフ構築に必要なdatetimeカラムなどの他のカラムを壊してしまうので、インデックスを設定してからリセットしなければなりません。
timeseriesdf = sql_query.drop(columns = ['timestamp', 'timestamp2' ])
timeseriesdf = timeseriesdf.set_index('datetime')
timeseriesdf = timeseriesdf.rolling(2880).mean()
timeseriesdf.reset_index(inplace=True)
timeseriesdf.tail()
| datetime | power | |
|---|---|---|
| 86187 | 2014-07-01 03:57:47 | 1210.53 |
| 86188 | 2014-07-01 03:58:17 | 1210.52 |
| 86189 | 2014-07-01 03:58:47 | 1210.54 |
| 86190 | 2014-07-01 03:59:17 | 1210.53 |
| 86191 | 2014-07-01 03:59:47 | 1210.53 |
2つ目のデータフレームを準備できたら、平均データをプロットし、生データの上に配置します。
ax = sql_query.plot(y = 'power', ylabel = 'power', x = 'datetime', grid=True, label = "raw power data")
timeseriesdf.plot(ax = ax, y = 'power', x = 'datetime', label = "rolling mean")
<AxesSubplot:xlabel='datetime', ylabel='power'>
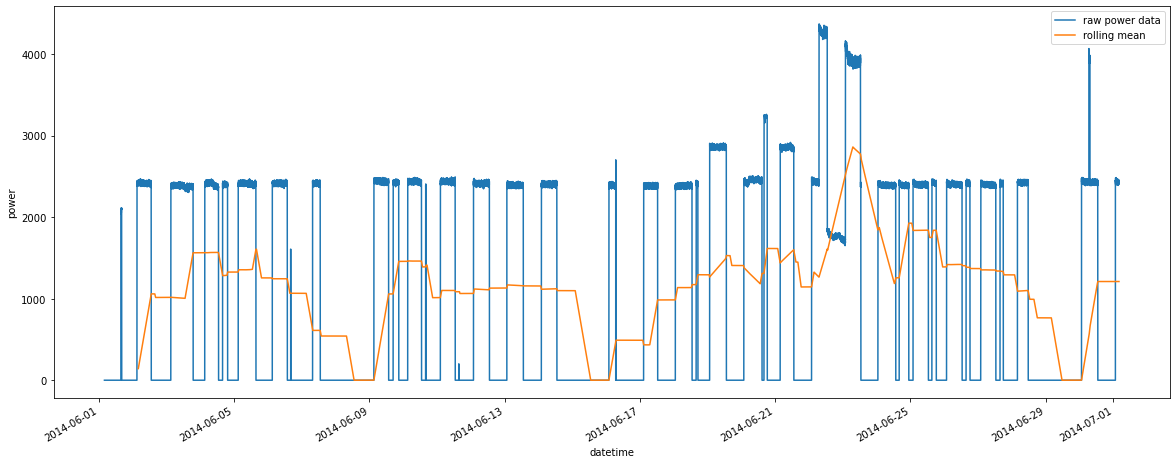
これで毎日の消費量が同じではないとわかります。
例によって週末にはギャップが見られ、続いて消費量が少しずつ増加して火曜日にピークを迎えます。
ピークが火曜日ではない週が1週ありますが、その時は週末に電力消費量が突出しています。
ヒートマップ
時間帯や曜日による電力消費のパターンが漠然とつかめてきたので、この方向でもっと掘り下げることにします。
折れ線グラフから得られるものはもうないので、データ集計してヒートマップに切り替えます。ヒートマップは電力消費のデータソースに適しているのです。
この建物で電力がどのくらい消費されているか見てみましょう。
ディメンション集計の準備
データを集計するため、次の2つのディメンションを作成します。
- 時
- 曜日
直接datetimeカラムから時を抽出できます。
10未満の時には「0」を足して、あとでカラムをソートした場合にきちんと並ぶようにします。
平日データの取得には少し準備が必要です。datetimeをdateに変換してから曜日を抽出します。
読みやすいよう平日に名前もつけます。最後に小さなデータフレームを作成し、メインデータフレームとマージします。
時
sql_query['hour'] = sql_query['datetime'].apply(lambda x: "0" + str(x.hour) if x.hour < 10 else str(x.hour))
sql_query.head()
| power | timestamp | timestamp2 | datetime | hour | |
|---|---|---|---|---|---|
| 0 | 0.00 | 1401595223 | 1401595223 | 2014-06-01 04:00:23 | 04 |
| 1 | 0.00 | 1401595253 | 1401595253 | 2014-06-01 04:00:53 | 04 |
| 2 | 0.00 | 1401595283 | 1401595283 | 2014-06-01 04:01:23 | 04 |
| 3 | 0.00 | 1401595313 | 1401595313 | 2014-06-01 04:01:53 | 04 |
| 4 | 0.00 | 1401595343 | 1401595343 | 2014-06-01 04:02:23 | 04 |
曜日
import datetime
sql_query['date'] = sql_query['datetime'].apply(lambda x: datetime.datetime.date(x))
sql_query['weekday'] = sql_query['date'].apply(lambda x: str(datetime.datetime.weekday(x)))
weekdaydf = pd.DataFrame({'day_of_week': ["Mon", "Tue", "Wed", "Thu", "Fr", "Sat", "Sun"], 'weekday':["0", "1", "2", "3", "4", "5", "6"]})
power = pd.merge(sql_query, weekdaydf, on='weekday')
power = power.drop(columns=['timestamp', 'timestamp2', 'datetime', 'date', 'weekday'])
グループ化と集計
ヒートマップ構築に使う集計データを作成するには、2つの手順が必要です。
- データフレームをgroupby ()関数とsum ()関数でグループ化して
- ピボットテーブルを作成します
これとは別に、平日をソートするため正しい順序を設定する必要があります。
powergrouped = power.groupby(['day_of_week', 'hour'], as_index=False).sum()
powerpivot = powergrouped.pivot('day_of_week','hour', 'power')
new_order= ["Sun", "Sat", "Fr", "Thu", "Wed", "Tue", "Mon"]
powerpivot.sort_index(axis=1, ascending=True, inplace=True) #x-axis
powerpivot = powerpivot.reindex(new_order, axis=0)
powergrouped
| day_of_week | hour | power | |
|---|---|---|---|
| 0 | Fr | 00 | 0.00 |
| 1 | Fr | 01 | 224969.23 |
| 2 | Fr | 02 | 864557.15 |
| 3 | Fr | 03 | 1119128.11 |
| 4 | Fr | 04 | 1150885.10 |
| … | … | … | … |
| 163 | Wed | 19 | 105530.85 |
| 164 | Wed | 20 | 0.00 |
| 165 | Wed | 21 | 0.00 |
| 166 | Wed | 22 | 0.00 |
| 167 | Wed | 23 | 0.00 |
168 rows × 3 columns
powerpivot
| hour | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | … | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| day_of_week | |||||||||||||||||||||
| Sun | 0.00 | 51497.60 | 291117.90 | 292769.57 | 291190.81 | 291278.86 | 290997.18 | 491656.62 | 513788.41 | 510171.87 | … | 213315.17 | 288440.83 | 263605.47 | 208461.53 | 211521.67 | 211974.35 | 212378.75 | 210879.87 | 209623.45 | 206585.15 |
| Sat | 0.00 | 0.00 | 269834.76 | 458969.12 | 915983.93 | 918758.96 | 921725.76 | 999486.05 | 1206349.12 | 1210010.29 | … | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Fr | 0.00 | 224969.23 | 864557.15 | 1119128.11 | 1150885.10 | 1157386.84 | 1156024.29 | 1153747.56 | 1158855.92 | 1158471.02 | … | 181962.75 | 120546.90 | 650737.81 | 633932.26 | 132555.43 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Thu | 0.00 | 309328.00 | 932204.37 | 1205611.23 | 1207128.36 | 1204462.24 | 1206721.36 | 1208640.58 | 1204511.73 | 1199805.57 | … | 287940.39 | 287652.30 | 290639.87 | 287504.60 | 65143.31 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Wed | 0.00 | 281027.87 | 749927.37 | 1100732.95 | 1153720.09 | 1151129.83 | 1153740.49 | 1156341.91 | 1153000.58 | 1147049.35 | … | 0.00 | 296933.91 | 861515.44 | 618844.71 | 372767.37 | 105530.85 | 0.00 | 0.00 | 0.00 | 0.00 |
| Tue | 26562.56 | 445447.54 | 683084.53 | 1342209.28 | 1151558.18 | 1147726.28 | 1149619.97 | 1150122.07 | 1152870.25 | 1148160.37 | … | 282747.19 | 298448.77 | 612924.25 | 572219.97 | 545555.71 | 284165.57 | 286591.83 | 286551.77 | 219794.28 | 0.00 |
| Mon | 206121.08 | 419298.17 | 1068524.79 | 1550715.82 | 1630477.85 | 1630106.16 | 1680749.36 | 1412979.20 | 1332721.77 | 1338198.34 | … | 0.00 | 0.00 | 33988.80 | 290805.45 | 291424.27 | 291727.70 | 242969.68 | 0.00 | 0.00 | 0.00 |
7 rows × 24 columns
パターンを分析する
import seaborn as sns
ax = sns.heatmap(powerpivot)

大学構内のスマートメーターのデータを見ると、当然のように午後から電量消費が減っています。授業は午前中に行われますからね。
毎週ピークは水曜日です。先ほどの推察は惜しかったですね。
しかし判然としません。火曜日のほうが紫の時間帯が多いのに、水曜日のほうが赤い時間帯が多いのです。
それに消費が最も多い時間帯が午前3時から7時なのは、どうしてでしょうか。
こんな夜明けに、誰がこれほどの電力を必要としているのでしょうか。
おまけ:折れ線グラフのグループ化
下図のように簡単な複数折れ線グラフも作成できます。
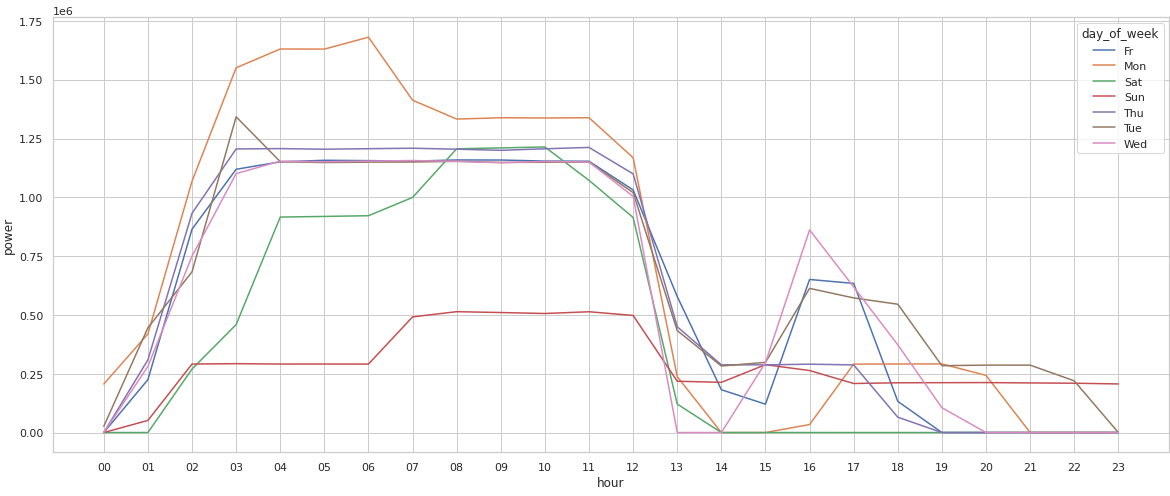
sns.lineplot(data=powergrouped, x="hour", y="power", hue="day_of_week")
<AxesSubplot:xlabel='hour', ylabel='power'>
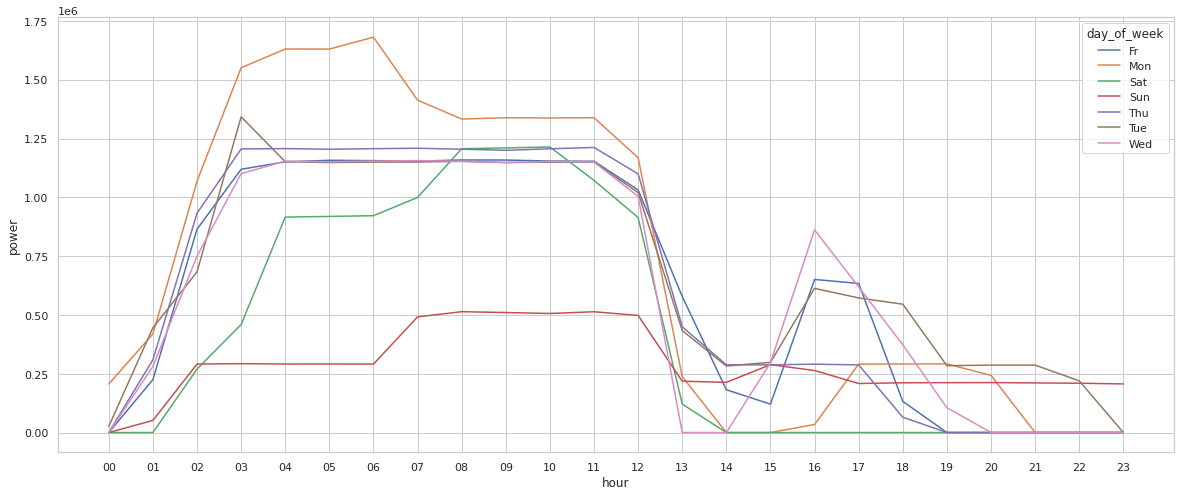
問題は、どの線が何を表すかが煩雑なので、何か興味深いことに気づくたびに凡例を参照しなければならないことです。
ヒートマップを補足するなら、小さな時系列グラフを複数持つグリッドが有効です。
各曜日のトレンドを切り分けて、ピークとギャップに焦点を当てるのに便利です。
powergrouped['day_of_week'] = pd.Categorical(powergrouped['day_of_week'], new_order[::-1])
powergrouped = powergrouped.sort_values(by = 'day_of_week')
g = sns.relplot(
data=powergrouped,
x="hour", y="power", col="day_of_week", hue="day_of_week",
kind="line", palette="crest", linewidth=4, zorder=5,
col_wrap=3, height=2, aspect=1.5, legend=False,
)
for day_of_week, ax in g.axes_dict.items():
ax.text(.8, .85, day_of_week, transform=ax.transAxes, fontweight="bold")
sns.lineplot(
data=powergrouped, x="hour", y="power", units="day_of_week",
estimator=None, color=".7", linewidth=1, ax=ax,
)
ax.set_xticks(ax.get_xticks()[::4])
g.set_titles("")
g.set_axis_labels("", "power")
<seaborn.axisgrid.FacetGrid at 0x7f105ecbf8b0>
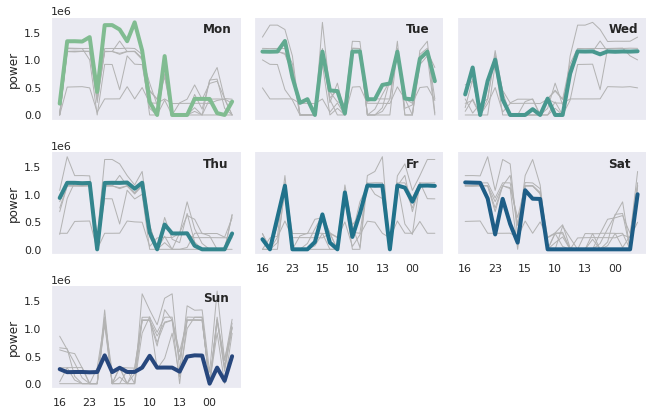
この最終的な可視化で、電力消費量は曜日と時間帯によって大きく変わるという事実が明確に示されました。
結論:省エネが見込める方法
当初の分析の目的に立ち返り、より詳しく調べるための方向性をいくつか提案します。
- 月曜午前中の電力消費量の削減策:日曜日にもう少し温めておく
- 水曜、火曜、金曜の午後の活動について:授業があるか確認する
最も有効な戦略は、電力消費量を平坦にすることです。消費量が下がったあとは必ず大幅な増加が見られます。
週末に低い温度で温めておけば、月曜日に激しく温める必要はありません。
最後に一言
rolling windowや集計など別の方法で時系列データのパターンを取得することもできます。
ヒートマップと複数折れ線グラフは、トレンドの解明と、データのハズレ値を特定するのに有効です。
データをCSVファイルに永続的に格納するのではなく、データベースに保存する方法にはたくさんの利点があります。
- 無数のフォルダを作成しなくて済み、ファイルシステムを溢れさせることがありません。
- ハードドライブに十分な空き容量が生まれます。
- データをローカルに保存するよりもデータベースに保存したほうが安全です。
プロットをお楽しみください!
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.