
データセット
この記事では、GridDBとNode.jsを使って天気予報の時系列データセットを分析する方法を見ていきます。このチュートリアルでは 「ジャイプール市の天気予報データセット」 を使用します。公開されているデータセットは、ここからダウンロードできます。
このデータセットは、インドのジャイプール市の2016年5月1日から2018年3月11日までの気象データです。気象を描写するカラム属性は40種類あります。次の表で、データセットの属性を分かりやすく説明しています。
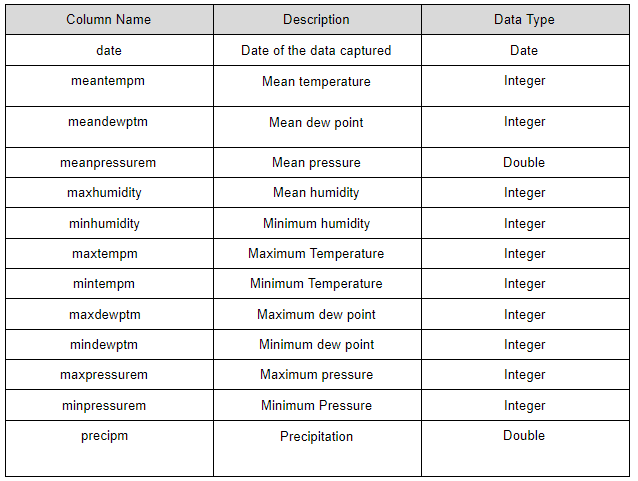
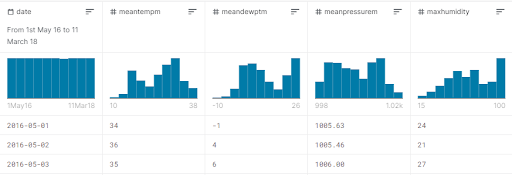
今回のチュートリアルでは、日付、平均気温、平均露点温度、平均気圧、最大湿度値のみを扱います。分析を行う値は、次の図のとおりです。
実装の前に、Node.jsクライアントを使ってGridDBサーバを設定する必要があります。
環境設定
Node.jsクライアントを設定するには、このブログで使われているソースで構築する方法もありますし、Node Package Manager (npm)でGridDBを使う方法もあります。GridDB npmパッケージのダウンロードは、このページを参照してください。
このチュートリアルではインストール手順については扱いません。次のステップに進む前に、前述のブログで説明している方法でインストールし、環境設定が完了していることを確認してください。ここまででnode.jsプロジェクトを作成し、GridDBライブラリをインストールできていると思います。
実装
まず、次のようにGridDBライブラリをプログラムにインポートします。
const griddb = require('griddb_node');
次に、正しいホスト名、クラスタ名、ユーザ名、パスワードなどを指定して、GridStoreを取得します。
const factory = griddb.StoreFactory.getInstance();
const gridStore = factory.getStore({
"host": '239.0.0.1',
"port": 31999,
"clusterName": "defaultCluster",
"username": "admin",
"password": "admin"
});
これでコンテナを作成できます。簡単のため今回はコンテナを1つだけ使いますが、シナリオに応じてコードを拡張し、コンテナを複数追加することもできます。
const colConInfo = new griddb.ContainerInfo({
'name': "Weather",
'columnInfoList': [
["date", griddb.Type.TIMESTAMP],
["meantempm", griddb.Type.STRING],
["meandewptm", griddb.Type.INTEGER],
["meanpressurem", griddb.Type.DOUBLE],
["maxhumidity", griddb.Type.INTEGER],
],
'type': griddb.ContainerType.TIME_SERIES, 'rowKey': true
});このコードスニペットでコンテナ名を 「Weather」 とつけ、データベースに格納するカラムの項目を指定しました。このうちの日付の属性はTIMESTAMP型で、これはタイムスタンプの属性を表すために使います。平均気圧の属性には DOUBLE 型のデータを使い、今回の分析で使う他の属性はすべてINTEGER型を使います。最後の行で、このGridDBのコンテナタイプをTIME_SERIESコンテナとしました。
データベースにデータを挿入する
ここまでで環境設定が完了し、コンテナを作成できました。次に、データセットでの分析に必要なデータカラムを挿入します。それには最初に、このデータセットを含むCSVファイルからデータを読み込みます。csv-parserはCSVファイルを読み込み、CSVファイルへ書き込むことができるモジュールです。このnpmモジュールは、次のコマンドでインストールできます。
npm i -s csv-parserでは、CSVファイルを読み込みます。保存したCSVファイルの中に「data.csv」 というデータセットがありますが、必要に応じて任意の名前を使用できます。CSVファイルからデータを読み込むには、次のコードスニペットを使います。ここではaddRowsToDatabaseメソッドを使って、必要なデータをデータベースに追加しています。
const csv = require('csv-parser');
const fs = require('fs');
fs.createReadStream('data.csv')
.pipe(csv())
.on('data', (row) => {
addRowsToDatabase(row.date, row.meantempm, row.meandewptm, row.meanpressurerm, row.maxhumidity);
})
.on('end', () => {
console.log('CSV file successfully processed');
});このコードでは、fsモジュールを使ってReadStreamを作成し、CSVオブジェクトに送り込みます。このCSVオブジェクトは、CSVファイルの新たな行を処理するたびにdataイベントを発生させます。endイベントは、CSVファイルの行の処理がすべて完了すると発生します。
date、meantempm、meandewptm、meanpressurem、maxhumidityのみを指定したのは、この特定のカラムのデータのみを分析するからです。そのため、データベース内のデータセットのカラムすべてを格納する必要はありません。
選択した行は、次のようにgriddb.Container.putメソッドを使ってGridDBに追加できます。addRowsToDatabaseメソッドを実装したのが、こちらです。
addRowsToDatabase(date, meantempm, meandewptm, meanpressurerm, maxhumidity){
var col2;
Var newDate = convertDateToTimeStamp(date)
store.putContainer(conInfo, false)
.then(col => {
col2 = col;
col.createIndex("count", griddb.GS_INDEX_FLAG_DEFAULT);
return col;
})
.then(col => {
col.setAutoCommit(false);
col.put([newDate, meantempm, meandewptm, meanpressurerm, maxhumidity]);
return col;
})
}このメソッドで、パラメータとしてデータベースに格納するために必要なデータをすべて取得しました。関数内にputContainerメソッドがあり、これはGridDBにデータを保存するために使います。このメソッドにはパラメータが2つあります。最初のパラメータはコンテナ情報(conInfo) をとります。
コードを見てのとおり、別のconvertDateToTimeStampメソッドを使って日付を 「タイムスタンプ」 に変換しています。putContainerは、JavaScriptのPromiseを使ってインデックスを作成し、カラムとデータを生成します。
データを分析する
前のステップで、必要なデータをデータベースに保存しました。これでデータベースを照会してデータを分析する準備が整いました。
次にデータベースを照会するためのクエリオブジェクトを形成します。GridDBでデータアクセスとデータ操作に使う問合せ言語は、TQLです。データにアクセスすると、データをフェッチして別のオブジェクトに保存できます。
コンテナに関連データが格納されるとデータを照会できます。node.jsクライアントAPIを使って実行するには、Containerオブジェクトからqueryメソッドを呼び出します。
var col2;
var newDate = convertDateToTimeStamp(date)
store.putContainer(conInfo, false)
.then(col => {
col2 = col;
col.createIndex("count", griddb.GS_INDEX_FLAG_DEFAULT);
return col;
})
.then(col => {
col.setAutoCommit(false);
col.put([newDate, meantempm, meandewptm, meanpressurerm, maxhumidity]);
return col;
})
.then(col => {
col.commit();
return col;
})
.then(col => {
query = col.query("select *");
return query.fetch();
})
.then(rs => {
while (rs.hasNext()) {
console.log(rs.next());
}
col2.commit();
})
.catch(err => {
console.log(err.what());
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
});上記のコードでデータベースへの変更をコミットし、select *というシンプルなクエリをデータベース上でテストしました。条件を一切適用せずに、データベースの値をすべて選択しています。コードの最後の部分は、エラーが発生した場合に検出するためのものです。
ではいくつかのクエリを使って、データセットを分析してみます。
var timeseries;
store.getContainer("Weather")
.then(ts => {
timeseries = ts;
query = ts.query("select * from Weather where meantemp > 34");
return query.fetch();
})
.then(rowset => {
var row;
while (rowset.hasNext()) {
row = rowset.next();
var timestamp = Date.parse(row[0]);
aggCommand = "select AVG(maxhumidity) from Weather where timestamp > 05012019 00:00:00", 10)";
aggQuery = timeseries.query(aggCommand);
aggQuery.fetch()
.then(aggRs => {
while (aggRs.hasNext()) {
aggResult = aggRs.next();
console.log("[Timestamp = " + timestamp + "] Average voltage = "+ aggResult.get(griddb.GS_TYPE_DOUBLE));
}
});
}
})このコードでは、まず「Weather」というコンテナにアクセスし、最初の部分で select * from Weather where `meantemp` > 34 というクエリを実行しました。Weatherコンテナで、平均気温が34度を超える行をすべて返します。
コードの2番目の部分で次の集計クエリを実行します。
select AVG(maxhumidity) from Weather where timestamp > 05012019 00:00:00これで、指定したタイムスタンプより後のtimestampが記録されているものをクエリで取得し、それらの平均最大湿度を取得します。
さまざまな種類のクエリを生成できます。例えば、select MAX(meanpressurem) from Weather where maxhumidity > 27 は、最大湿度が27%を超えた時の平均気圧の最大値を表示します。
結論
いいですね。今回は以上です。この記事では、インドのジャイプール市で記録された天気予報のデータセットを分析するシンプルな方法を説明しましたが、この時系列データセットを操作するのに、GridDBを使いました。このように時系列データベースを分析するのに、複数の異なるメソッドとクエリを追加できます。このチュートリアルで扱った考え方は、関連するシナリオならどんな場合でも使えます。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.