
はじめに
このチュートリアルでは、GridDBに保存されているデータを使って、簡単な線形回帰モデルを構築します。まず、GridDBのpython-connectorを使用して、データの挿入とアクセスを行います。その後、pandasとnumpyを使ってデータを取得し、変換する方法を見ていきます。最後に、scikit-learnとmatplotlibを使って回帰モデルを学習し、その結果を表示します。
前提条件と環境設定
以下のチュートリアルは、Ubuntu オペレーティングシステム(v.18.04)と gcc (v7.5.0) を使用して行われます。GridDB (v.4.5.2) は、GitHubにあるドキュメントを参考にしてインストールしました。
GridDB の python コネクタを有効にするには、GridDB C クライアント、SWIG、pcre が必要です。詳細はこちらを参照してください。
まず必要なパスを設定します。
export CPATH=$CPATH:<Python header file directory path>
export LIBRARY_PATH=$LIBRARY_PATH:<C client library file directory path>
export PYTHONPATH=$PYTHONPATH:<installed directory path>
GridDB Python クライアントのディレクトリ内でmakeコマンドを実行します。そして必要なライブラリをインストールします。
$ pip3 install numpy
$ pip3 install pandas
$ pip3 install matplotlib
インストールが正常に完了したかを確認するためにpythonコンソール内で以下のコマンドを実行します。
import griddb_python
もしくは、/python-client/sample/ ディレクトリ内にあるサンプルプログラムを実行することでも確認できます。
python3 sample1.py <GridDB notification address> <GridDB notification port> <GridDB cluster name> <GridDB user> <GridDB password>
→ Person: name=name02 status=False count=2 lob=[65, 66, 67, 68, 69, 70, 71, 72, 73, 74]
備考:PythonのデフォルトバージョンがPython3に設定されている場合は、pythonとpipだけで前述のコマンドを実行できます。UbuntuにはPython2がデフォルトでインストールされているため、実行時にpython3とpip3を明示しています。
GridDBへのアクセスとデータの取得
このチュートリアルでは、一般に公開されているCalCOFI データセットを使用します。このデータセットには、世界中の海洋生物と幼魚の時系列データが含まれています。CalCOFIデータは、以下のコマンドでGridDBに挿入されます。
import griddb_python as griddb
import pandas as pd
factory = griddb.StoreFactory.get_instance()
# Initialize container
try:
gridstore = factory.get_store(host=your_host, port=ypur_port,
cluster_name=your_cluster_name,
username=your_username,
password=your_password)
conInfo = griddb.ContainerInfo("Ocean_Data",
[["id", griddb.Type.INTEGER],
["T_degC",griddb.Type.FLOAT],
["Salnty", griddb.Type.FLOAT]],
griddb.ContainerType.COLLECTION, True)
cont = gridstore.put_container(conInfo)
cont.create_index("id", griddb.IndexType.DEFAULT)
data = pd.read_csv("bottle.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Data added successfully")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))
# After the data insertion is successful, we can now access the data using SQL queries.
sql_statement = ('SELECT * FROM Ocean_Data')
sql_query = pd.read_sql_query(sql_statement, cont)
pandasライブラリが提供するread_sql_query関数は、ユーザーが作業しやすいように、取得したデータをpandasデータフレームに変換します。
sql_query.info()
<class 'pandas.core.frame.DataFrame'>
CalCOFIデータセットを用いた線形回帰モデル
CalCOFIデータセットはサイズが大きいので、簡単にするために、このデータの最初の500インスタンスを使用して、単純な線形回帰モデルを構築します。
データセットには74の属性または列が含まれていますが、このチュートリアルでは、塩分(Salinity)と温度(Temperature)の2つだけを使用します。
まず必要なライブラリをすべてインポートしましょう。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
それでは、データセットを読み込みます。pythonファイルとデータセットが同じディレクトリにあることを確認してください。あるいは、csvファイルの全パスを指定してください。
dataset = pd.read_csv("bottle.csv")
データセットを見て、どのようなものを扱っているのかを把握するのは、非常に良い考えです。
dataset.head()
これがその出力です。

データの次元は以下のようにして確認することができます。
dataset.shape
Out []: (499, 74)
データについてより深く理解するために、データセットの要約統計量を確認しましょう。
dataset.describe()
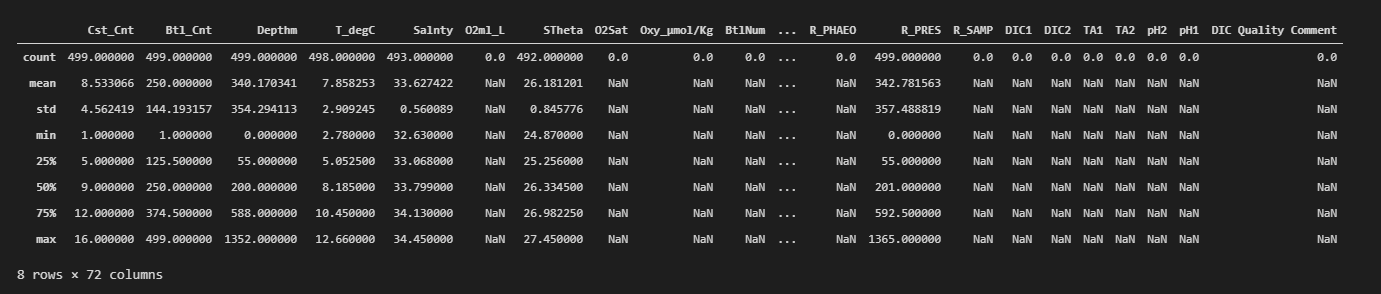
前述の通り、使用するのは2つの属性のみなので、この回帰モデルでは他の属性を保持する必要はありません。
dataset=dataset[["Salnty","T_degC"]]
dataset.head()
これで、データセットには期待通り2つの属性しか表示されなくなりました。
モデルを学習する前に、欠落している値や無効な値がないか確認しておくことが望ましいです。これらの値が存在すると以降の手順に支障をきたす可能性があるためです。
dataset.Salnty.isnull().value_counts()
Out[]: False 493
True 6
Name: Salnty, dtype: int64
dataset.T_degC.isnull().value_counts()
Out[]: False 498
True 1
Name: T_degC, dtype: int64
学習段階に移る前に、NULL値を削除してインデックスをリセットします。
dataset=dataset.dropna(axis=0)
dataset.reset_index(drop=True,inplace=True)
dataset.shape
Out[]: (492,2)
データセットをプロットして、塩分(Salinity)と温度(Temperature)との間にどのような関係があるかを見てみましょう。
plt.figure(figsize=(12,10))
plt.scatter(dataset.Salnty,dataset.T_degC, color='aqua')
plt.xlabel("Temperature",fontsize=22)
plt.ylabel("Salinity",fontsize=22)
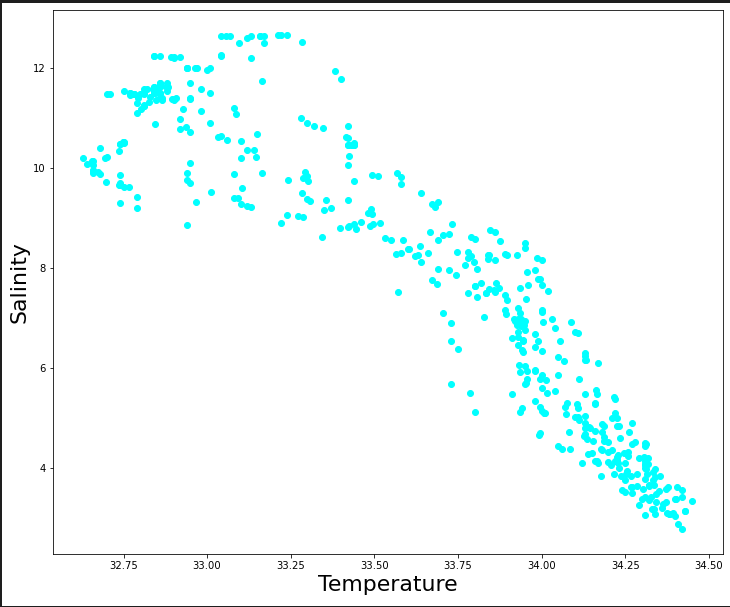
ここでは、データを1次元の配列に整形します。
x_label=np.array(dataset['Salnty']).reshape(492,1)
y_label=np.array(dataset['T_degC']).reshape(492,1)
いよいよデータセットを学習用とテスト用に分けます。ここでは、80%-20%の割合で分割します。割合はお好みで自由に変えてください。
x_train, x_test, y_train, y_test = train_test_split(x_label, y_label, test_size = 0.2, random_state = 100)
データセットの分離が完了したので、今度は学習用データセットを用いて線形回帰モデルを構築してみましょう。
regression_model=LinearRegression()
regression_model.fit(x_train,y_train)
print('Coefficients: ', regression_model.coef_)
print('Intercept: ',regression_model.intercept_)
Out[]: Coefficients: [[-4.80500593]]
Intercept: [169.4247854]
次に、構築したモデルの精度を確認するために、テストデータセットを与えてみます。
accuracy = regression_model.score(x_test, y_test)
print(accuracy)
0.876504976866808
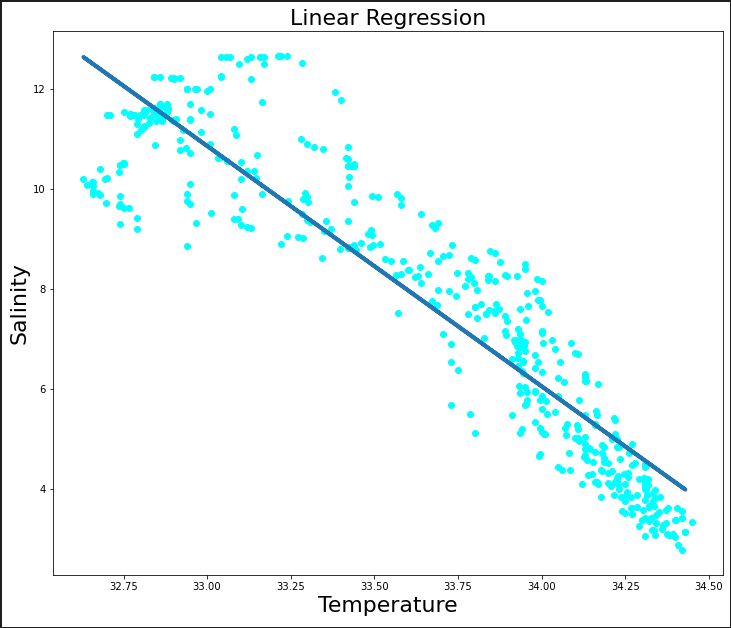
構築した線形回帰モデルによる予測結果がどの程度合っているかを視覚化してみましょう。
plt.figure(figsize=(12,10))
plt.scatter(x_label, y_label, color='aqua')
plt.plot(x_train, regression_model.predict(x_train),linewidth="4")
plt.xlabel("Temperature",fontsize=22)
plt.ylabel("Salinity",fontsize=22)
plt.title("Linear Regression",fontsize=22)
モデルの平均誤差を確認しましょう。
y_predicted_value = regression_model.predict(x_test)
print("Mean absolute error:",np.mean(np.absolute(y_predicted_value - y_test)))
Out []: Mean absolute error: 0.8090316355920698
このチュートリアルでは、データをGridDBに挿入する方法と、pandasライブラリとSQLを使ってデータにアクセスする方法を見ました。その後、このデータを使って線形回帰モデルを構築しました。GridDBとJupyter Notebooksを接続する方法については、こちらのチュートリアルをご覧ください。データセットの他のパラメータについても、自由に試してみてください。このようなチュートリアルをもっと見たい方は、私たちのブログをご覧ください。