以前、GridDBとstreamlitとの連携について紹介しました。自社で保有するサーバーがすでに稼働している場合は以前紹介した方法が適していますが、このブログではもう1つのGridDBとstreamilitを連携する方法について紹介します。
このブログでは、GridDBサーバーをデータのホストとして利用するのではなく、インタラクティブなダッシュボードを作成するために、GridDB Cloudのインスタンスを利用する方法について説明します。具体的には、クラウドにデータを取り込み、そこからクエリを実行し、関連するデータをStreamlitチャートにプッシュする方法について順を追って説明します。
ご存じない方のために説明すると、Streamlitの宣伝文句は次の通りです。「Streamlitは、データスクリプトを数分で共有可能なウェブアプリケーションに変えます。すべて純粋なPythonでできています。フロントエンドの経験は必要ありません。」つまり、データセットを入手し、適切な方法で処理し、マッサージすれば、Python以外のコードを書くことなく、魅力的なダッシュボードを構築することができるということです。
ここでは、チャートを使った簡単なビデオを紹介します。
準備
このブログの手順に従うには、GitHubページからソースコードを取得してください。
$ git clone https://github.com/griddbnet/Blogs.git --branch streamlit_cloudステップバイステップの手順
以下の手順を実行する前に、ソースコードにアクセスして、クラウドインスタンスのURLとヘッダーobjの認証部分を含む変数を編集することを確認してください。
- GitHub Repoをクローンする
- URLとHeaderオブジェクトを認証情報で更新する
- 依存関係Aをインストールする $ python3 -m pip install streamlit pandas
- ingest.pyを実行してデータを取り込む ($ python3 ingest.py)
- Streamlitアプリを実行する ($streamlit run app.py)
データセット
以前の試みでは、より「学術的」なタイプのデータセットを使いましたが、このブログは主にクラウドの側面に焦点を当てているため、よりシンプルで楽しいデータセットを選択することにしました。このブログのデータはKaggleのもので、NBAの歴史におけるプレーオフの歴代得点者上位25人のリストを使います。
このデータセットは25行しかありませんが、多くのカラムを持っています。前述したように、ここでは csv ファイルからデータを取り込み、Streamlit の便利な API を使って必要なデータを照会し、最後に Streamlit の出力ウィジェットを使って関連データを表示するところまで説明します。
データを取り込む
それでは、選んだデータセットGridDBクラウドインスタンスに取り込んでみましょう。サーバーと対話する最も簡単な方法は、Web APIを利用する方法です。この方法では、RESTインターフェースを使用して対話することができます。つまり、HTTPリクエストを通じてデータをPUTすることができます。また、Webリクエストを通じてTQLやSQLクエリを実行し、ストリームリットチャートのデータを検索することもできます。
コンテナを作る
csvファイルを読み込んでその内容をCloudインスタンスにプッシュする前に、コンテナのスキーマをレイアウトし、その情報をサーバーにプッシュする必要があります。コンテナとスキーマが整い、サーバーがどのようなデータをプッシュするかを理解したら、データの各行を送信して保存させることができます。
data_obj ={
"container_name":"Playoff_Scorers",
"container_type":"COLLECTION",
"rowkey":False,
"columns":[
{
"name":"rank",
"type":"INTEGER"
},
{
"name":"player",
"type":"STRING"
},
{
"name":"position",
"type":"STRING"
},
{
"name":"teams",
"type":"STRING"
},
{
"name":"total_points",
"type":"INTEGER"
},
{
"name":"total_games",
"type":"INTEGER"
},
{
"name":"total_points_pre_game",
"type":"FLOAT"
},
{
"name":"field_goals",
"type":"INTEGER"
},
{
"name":"three_point_goals",
"type":"INTEGER"
},
{
"name":"free_shots",
"type":"INTEGER"
},
{
"name":"born",
"type":"STRING"
},
{
"name":"active_player",
"type":"INTEGER"
},
{
"name":"country",
"type":"STRING"
},
{
"name":"recording_year",
"type":"INTEGER"
}
]
}ここでは、csvファイルのスキーマを作成しています。これは、元のデータセットから1列を除いたすべての列を取り出したもので、次のセクションで削除することになります。もちろん、カラムを削除せずにCSVデータを送信しようとすると、取り込みがうまくできません。
スキーマをクラウドに送信するために、POSTリクエストを行います。
header_obj = {"Authorization":"Basic XXX","Content-Type":"application/json; charset=UTF-8","User-Agent":"PostmanRuntime/7.29.0"}header_objはHTTPリクエストと一緒に送信されます。これがないとリクエスト全体が失敗してしまいます。つまり、自分の認証情報と、単なるPythonスクリプトではないUser-Agentを含める必要があります。ユーザー名とパスワードはbase64でエンコードし、header_objに含めます。
import requests
import http
http.client.HTTPConnection.debuglevel = 1
base_url = 'https://[host]:[port]/griddb/v2/[clustername]/dbs/[database_name]/'
#Set up the GridDB WebAPI URL
url = base_url + 'containers'
req_post = requests.post(url, json = data_obj, headers = header_obj)ここでは、スキーマ obj をリクエスト・ボディとして POST リクエストを実行しています。すべてがうまくいけば、コンテナがクラウド上に作成されるはずです。
Reading CSV And Pushing Data CSV を読み込みデータをプッシュする
Kaggleからダウンロードしたデータを取り込むには、人気のあるpandas ライブラリを使用して、csvデータのデータフレームを作成します。そこから、データをJSONファイルに変換し、HTTPリクエストのボディにそのデータを入れて、データをクラウドインスタンスにプッシュすることができます。
# read our data and make it into a dataframe
df = pd.read_csv('nba_playoffs.csv')
# Drop the column we don't need
df = df.drop('hall_of_fame', axis=1)
# Convert df to JSON
scores_json = df.to_json(orient="values")
# Send our converted json df using PUT command to push all data into cloud
# Here we borrow the same header_obj from before
url = base_url + 'containers/Playoff_Scorers/rows'
req_ingest = requests.put(url, data=scores_json, headers=header_obj)分析のためにデータをクエリする
では、クラウドインスタンスからデータを照会し、何らかの形で使用できるかどうかを確認します。データクエリを形成するために、ユーザーが特定のパラメータを選択できるようにしたいので、TQLまたはSQLクエリを使用して、ユーザーの選択に基づいて数値を入力することができます。
そこでもう一度、header_objとbase_urlを作成します。
header_obj = {"Authorization":"Basic XXX","Content-Type":"application/json; charset=UTF-8","User-Agent":"PostmanRuntime/7.29.0"}
base_url = 'https://[host]:[port]/griddb/v2/[clustername]/dbs/[database_name]/'次にクエリを作成します。
import streamlit as st
scoring_threshold = st.slider("Total_Points", 3000, 8000, 3000, 200)
total_points_query_str = ("select * where total_points > " + str(scoring_threshold))ここでは、Streamlit APIを利用して、デフォルト値が3000のシンプルなスライダーを作成し、作成したUIエレメントを使用してユーザーがより大きな数値を選択できるようにします。
url_total_points = base_url + 'tql'
request_body_total_pts = '[{"name":"Playoff_Scorers", "stmt":"' +
total_points_query_str+'", "columns":[]}]'
res = requests.post(url_total_points, data=request_body_total_pts, headers=header_obj)
total_points_data = res.json() インジェストと同様に、関連情報(この場合はユーザーが選択したスコアリングしきい値を含むTQLクエリ)を含むリクエストボディでPOSTリクエストを行います。ユーザーが新しい数字を選択するたびに、アプリはリロードしてコードを再実行します。つまり、クエリが再び実行され、クラウドインスタンスから新しいレスポンスが返ってきます。
データをレンダリングする前に、サーバーの応答から生のjsonデータをpandasデータフレームに変換する必要があります。
dataset_columns = ['rank', 'player', 'position', 'teams', 'total_points', 'total_games', 'total_points_pre_game',
'field_goals', 'three_point_goals', 'free_shots', 'born', 'active_player', 'country', 'recording_year']
scorers = pd.DataFrame(total_points_data[0]["results"], columns=dataset_columns)さて、関連する情報をデータフレームとして入手したので、チャートをレンダリングしてみましょう。
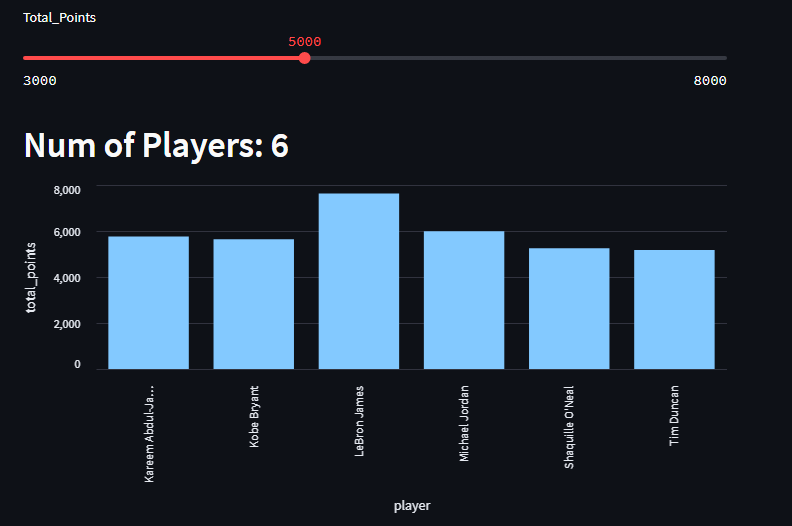
スライダーから得点のしきい値を上げるたびに、その点数を取った選手の量が棒グラフで変化するように留意してください。
st.header("Num of Players: " + str(scorers.shape[0]))
st.bar_chart(data=scorers, x='player', y='total_points')データ・カラムにデータ・フレームを入力することで、X軸とY軸にカラム名を使用することができるようになりました。また、スライダーで新しいクエリを実行すると、データフレームのデータがどんどん移動していくので、ほとんど手間をかけずにダッシュボードがインタラクティブになりました。
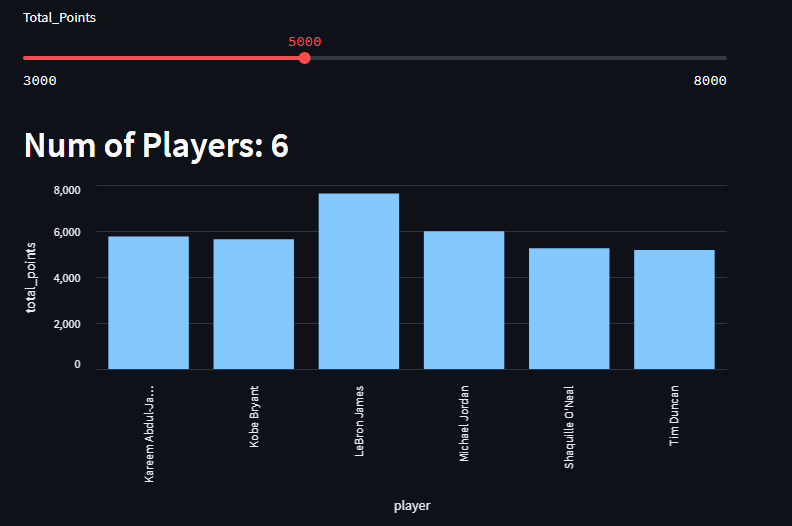
このグラフが示しているのは、nbaプレーオフの成績上位25人による得点数です。つまり、数字をスライドさせると、得点の基準値が高くなればなるほど、その金額を達成した選手は少なくなる、レブロン・ジェームズの圧倒的な強さを示す、とてもクールな方法です。
その他のデータとチャート
githubのページでソースコードの全文を見ると、さらにいくつかのグラフがあり、それを使ってみることができます。1つはNBAプレーオフの総試合数で、もう1つは選手のキャリアにおけるフィールドゴールのうち3ポイントゴールの割合です。
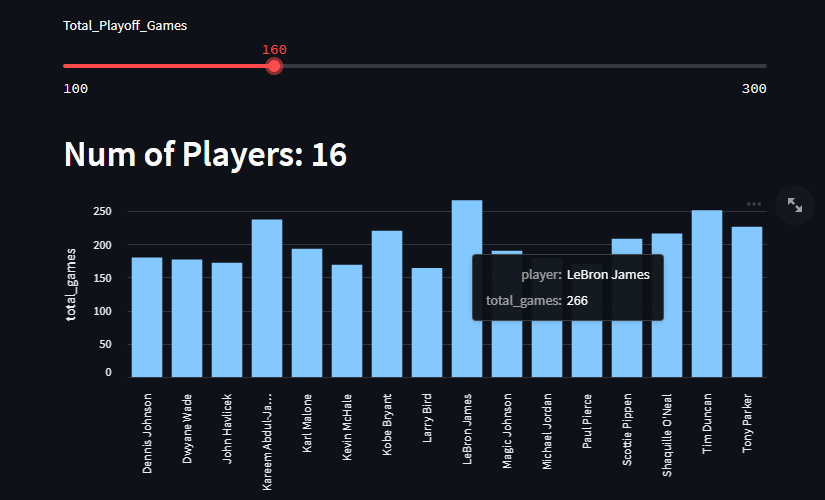
これは、クエリーと表示を行うカラムが追加されただけで、基本的には前回と同じです。しかし、これはティム・ダンカンとレブロン・ジェームズの優位性を示すものでもあり、彼らは他の競争相手よりも非常に優れていると言えます。
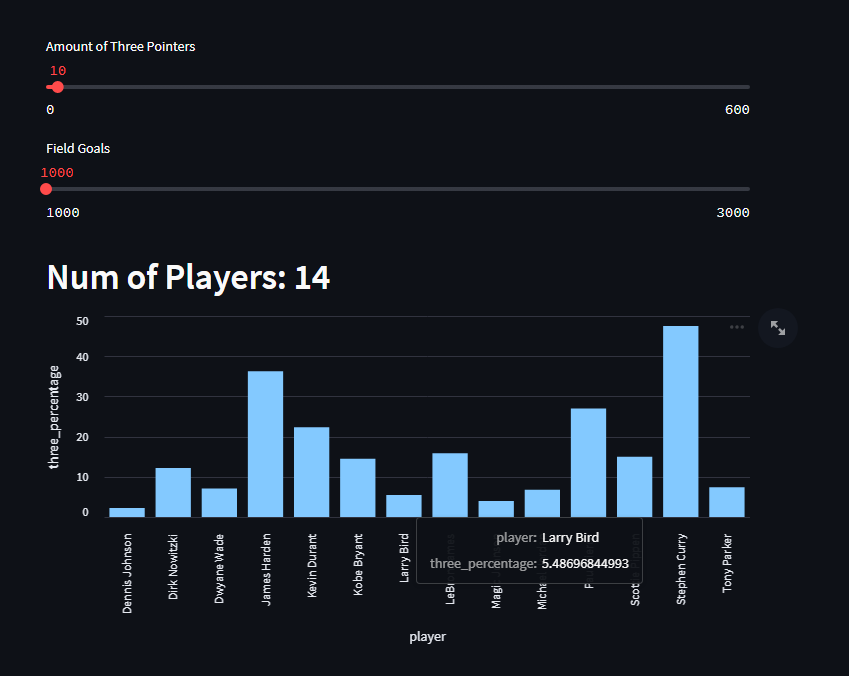
そして最後のグラフは、フィールドゴールとスリーポイントの合計と、プレーオフで決めたフィールドゴールのうちスリーポイントが占める割合を示しています。ステファン・カリーがこの指標を圧倒的にリードしていますが、今の試合と昔の試合とで、どれだけ多くのスリーポイントが作られているかを示すのも興味深いでしょう。
今回は3つのグラフを作成しましたが、このシンプルなデータセットを使って、もっと面白くて興味深い角度を見つけ、グラフや他の手段で表示してみてください。
まとめ
ここまでで、GridDBクラウドインスタンスにデータを取り込み、TQLクエリを送信して美しいStreamlitチャートを作成する方法をご紹介しました。ぜひ使ってみてください。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.