はじめに
以前のブログで、ニューヨークの犯罪データ を使って、ニューヨーク市の犯罪苦情データの地理空間分析を行ったことがあります。そのブログでは、緯度・経度データを使って、予測・分析を試みました。
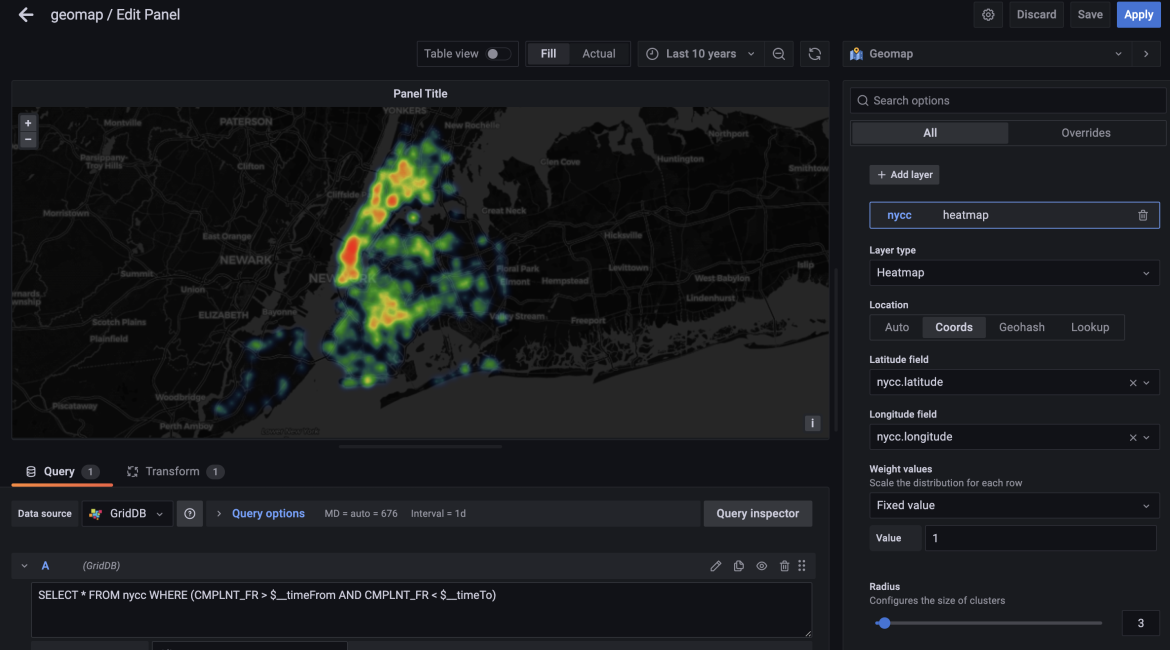
今回のブログでは、同じデータセットを使って、GridDBとGrafanaを使って犯罪の苦情のヒートマップを描きます。完成したら、ニューヨークの地図の上に明示的なヒートマップを重ね、様々な苦情が頻度とともに表示される分かりやすいグラフィックになることを目指します。
データの取り込み
Open Dataが提供するこのデータセットはかなり堅牢なものですが、その全てを取り込むコードは以前のブログで紹介しました。以下はそのクイックバージョンです。
単純化するために、すべての苦情データは1つのコンテナに入れられます。単純な .java プログラムがあり、これが取り込みを処理してくれます。このプログラムを使用するには、まず commons-csv と gridstore の jar を CLASSPATH に追加します。そこから、単純にIngestファイルをコンパイルして実行します。また、 .csv ファイルの名前を rows.csv にするか、または、Ingest ファイルにジャンプしてファイル名を変更します。
概要は以下の通りです。
$ export CLASSPATH=:/path/to/commons-csv-1.8.jar:/usr/share/java/gridstore.jar
$ javac Ingest.java
$ java IngestGridDB WebAPIを利用する
GridDBのデータをGrafanaで使用するために、GridDB WebAPIを使用することにします。これにより、HTTPプロトコルを使用してGrafanaインスタンスにデータを送信することができます。WebAPIを動かすには、前回のブログの説明に従うか、公式のGithubのページを参照してください。
また、WebAPIの利用はGrafanaとの併用に限らず、こちらのブログにあるように、データの取り込みやクエリに利用することもできます。
Grafanaのインストールと使用方法
Grafanaは、メトリクスがどこに保存されていても、クエリ、可視化、アラート、理解することを可能にする 製品です。今回のユースケースでは、Grafanaを使って、NYCCデータセットからのジオメトリ緯度・経度データをヒートマップの形で可視化したいと考えています。
Grafanaのインストールについては、以前のブログ をご覧ください。ここでは、その要約版をご紹介します。
Grafana本体をインストールする方法は以下の通りです。
sudo cat > /etc/yum.repos.d/grafana.repo << EOF
> [grafana]
> name=grafana
> baseurl=https://packages.grafana.com/oss/rpm
> repo_gpgcheck=1
> enabled=1
> gpgcheck=1
> gpgkey=https://packages.grafana.com/gpg.key
> sslverify=1
> sslcacert=/etc/pki/tls/certs/ca-bundle.crt
> EOF次に、
sudo yum -y install grafana次に、起動させます。
sudo /bin/systemctl enable grafana-server.service
sudo /bin/systemctl start grafana-server.serviceインストールするGrafanaのバージョンがバージョン8.1以降であることを確認してください。
次にGridDBプラグインをインストールします。以前のブログでも説明しましたが、こちらでも簡単に説明します。
$ curl -o https://github.com/griddb/griddb-datasource/archive/refs/tags/1.1.0.tar.gz
$ tar zxvf 1.1.0.tar.gz
$ cd 1.1.0/
$ sudo cp -a dist /var/lib/grafana/plugins/GridDB-DataSourceそれが終わったら、grafana.iniを編集します。特に難しい手順はなく、Grafanaが署名されていないモジュールの実行を許可するだけです。次にファイルを開いて、次のように追加してください。
[plugins]
allow_loading_unsigned_plugins = griddb-datasourceGrafanaインスタンスがGridDBをデータソースとして許可しているので、起動しているGrafanaにログインしてデータソースを追加する必要があります。こちらのブログ でもいくつか例を紹介しています。基本的には、GrafanaのデータソースにGridDBのWebAPIのURLを指定し、サーバの認証情報も一緒に指定します。
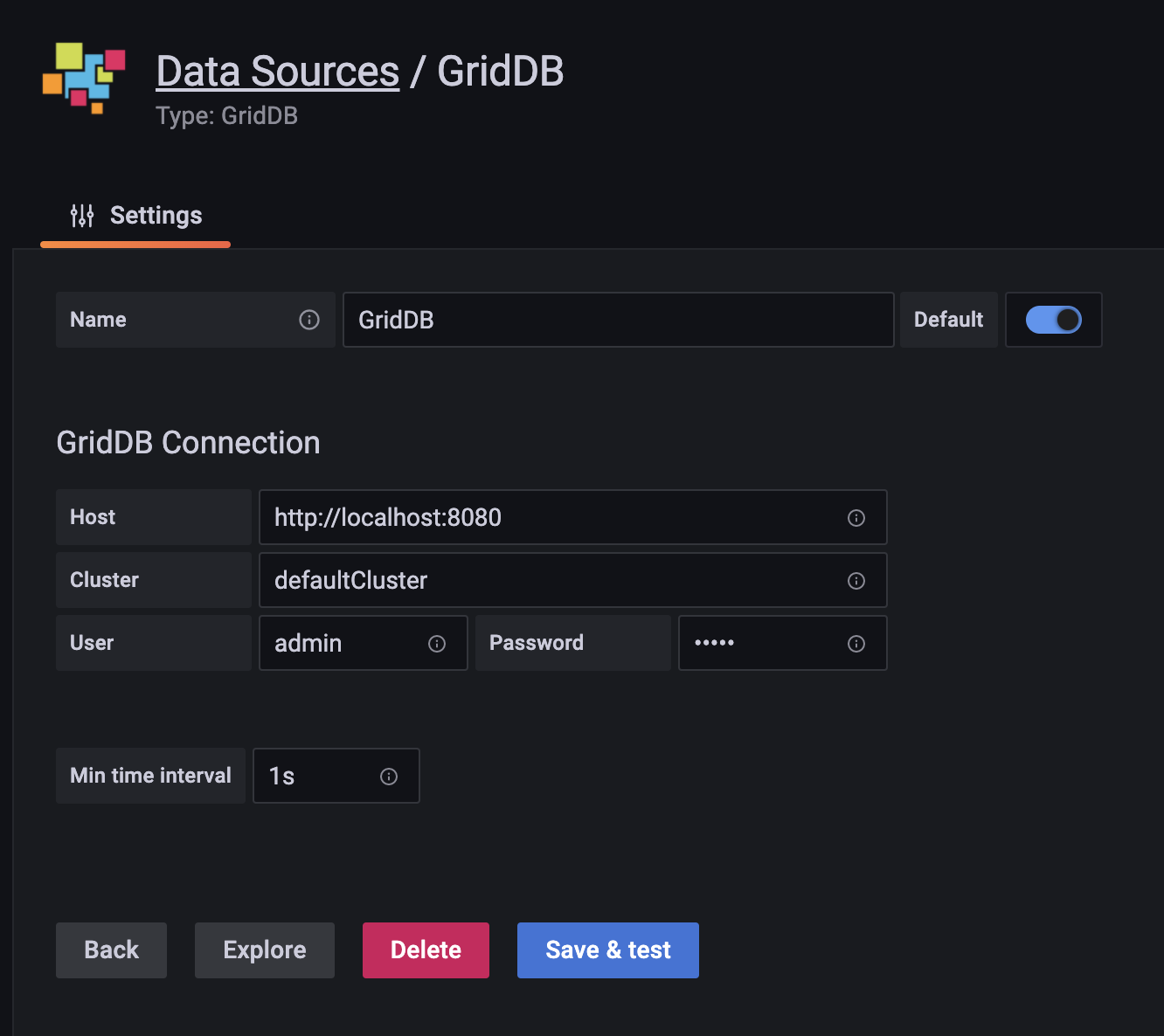
情報を入力したら、保存とテストをクリックします。
データの可視化
次に、新しいパネルを作成し、右上のオプションで可視化タイプをGeoMAPに変更します。次に、苦情データが相関する期間と一致するように期間を設定します。
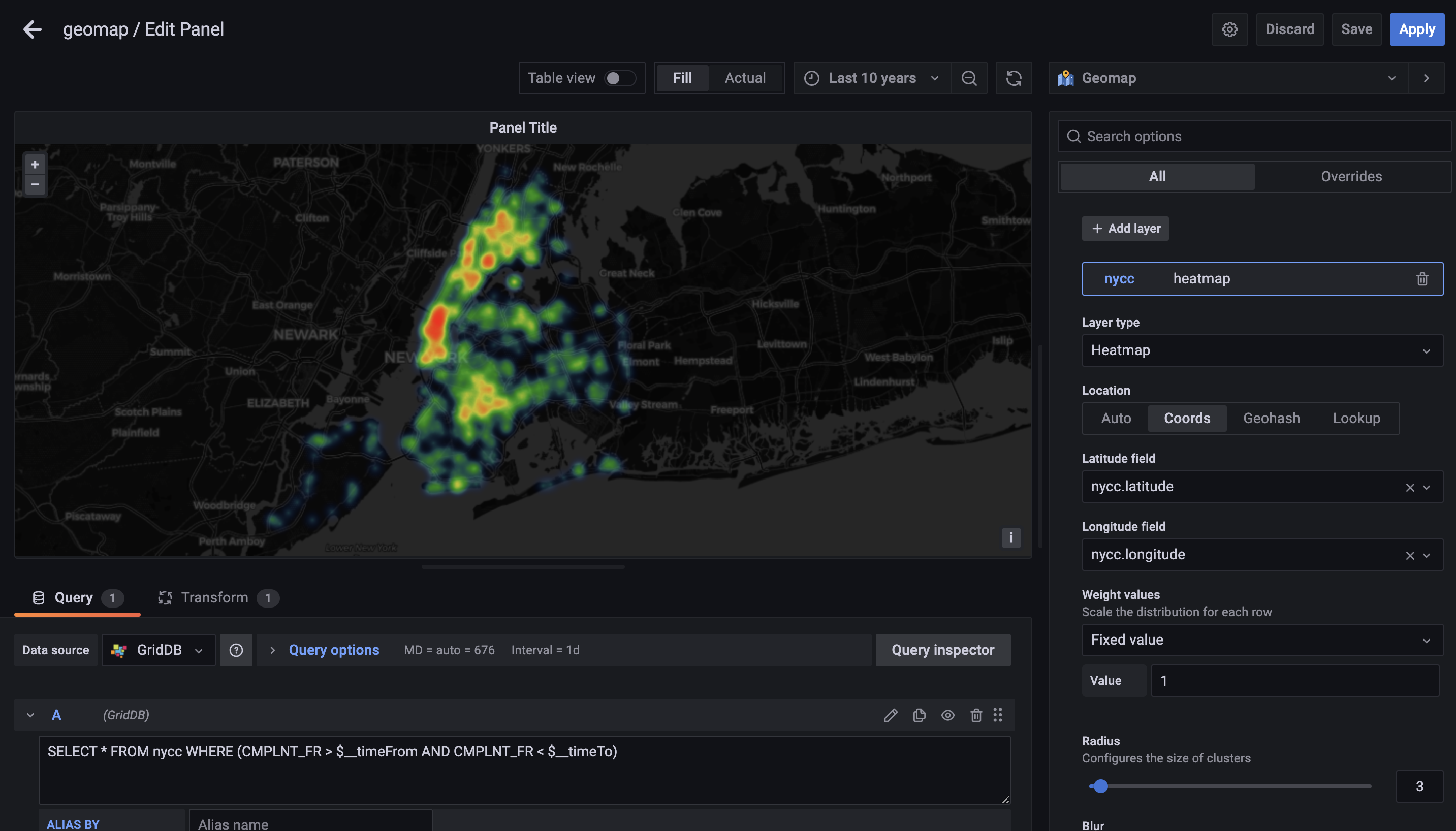
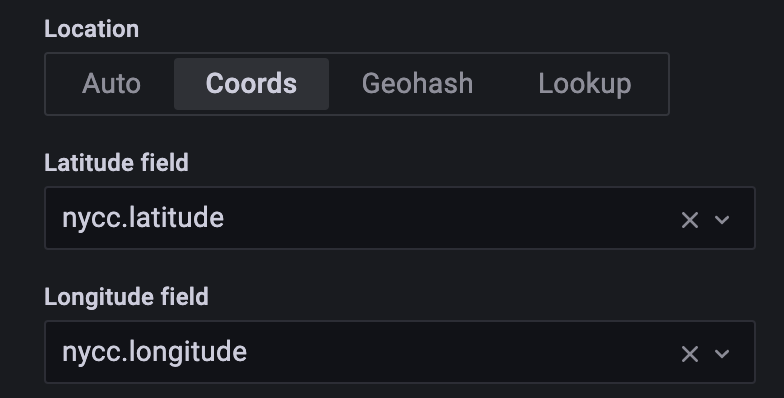
次に、Grafanaインスタンスにデータ型として座標を使用することを伝える必要があります。そこで、オプションをAutoからCoordsに変更し、実際の名前である nycc.latitude と nycc.longitude を指定します。
最後のステップで、変換タブを使用します。GridDB DataSourceは、異なる内部データ構造を使用する古いバージョンのGrafana用に開発されたため、データフレームは一緒に連結する必要があります。
![]()
まとめ
GridDBとGrafanaを組み合わせることで、非常に有益で見やすい結果を導き出すことができました。このように大規模なデータセットをGrafanaであらゆる種類の方法で可視化することができます。さらに重要なのは、GridDBを使用することで大規模なデータセットを任意のGrafanaインスタンスで簡単に共有することができることです。
このデータセットから生成されるヒートマップは、同じデータセットについて全く新しい方法で考え、分析するのにとても役立ちます。ぜひ使ってみてください。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.