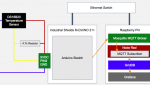
このブログでは、シンプルで柔軟なオープンソースのIoTソフトウェアスタック、CroMFlaG2(CROn、Mqtt、FLAsk、GridDB、Grafana)の活用方法とおすすめする理由を紹介します。CroMFlaG2は、IoTアプリケーションを構築するために必要なデータを取り込み、分析、視覚化するための複数のオプションを備えています。
イントロダクション
2000年代にインターネットのコモディティ化を促進したLAMP(Linux、Apache、MySQL、PHP / Perl / Python)スタックの人気が高まり、多くのソフトウェア企業の製品が他製品と連携でき、利用やデプロイが簡単に行えるようになりました。
しかしこれらのソフトウェアスタックの中には、いくつかの難点を持つものがあります。それは、ベンダーロックインを促進し、そのソフトウェアスタックが意図するモデルにソリューションを強制的に適合させなければならず、改善、変更、新機能の追加などが難しくなるという点です。CroMFlaG2にはそのような難点はなく、オープンソースで広範囲に構成可能でユーザーが変更できるようになっており、LAMPスタックのように動作することを目的としています。
CroMFlaG2は安定性が高く、軽量で数十万のデバイスにまで拡張可能であることが証明されています。ホストアプリケーションとして利用する従来の方法や、DevOps、コンテナ化などの新しい方法でも簡単に実装することができます。構成するソフトウェア間で互いにうまく機能することが実証されています。
CroMFlaG2はCron、MQTT、Flask、GridDB、Grafanaで構成されます。
IoTスタックアーキテクチャ
多くのIoTソリューションは、センサまたは他のデータジェネレーターを含むエッジデバイスで構成され、直接またはローカルゲートウェイを介して集中型インフラストラクチャと通信します。
集中型インフラストラクチャは、パブリッククラウドまたはプライベートオンプレミスサーバのいずれかでホスティングされます。デバイスは通常、データベースと直接ではなく別のデータコレクターと通信しますが、そうしなくてもよい場合もあります。
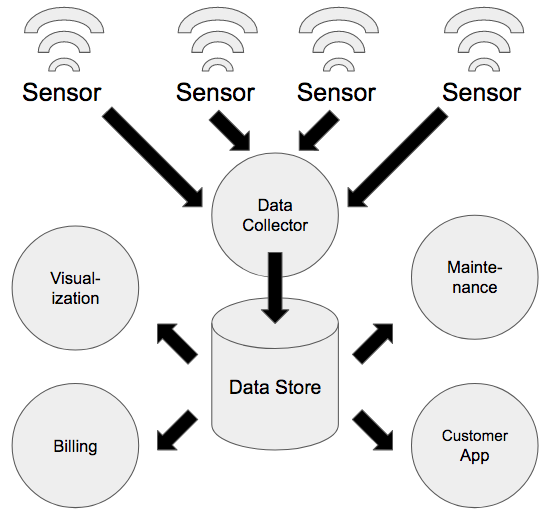
データがプライマリデータストアに保存されると、他のプロセスがリアルタイムまたはバッチで、保存されたデータを分析したり、視覚化したりすることができるようになります。
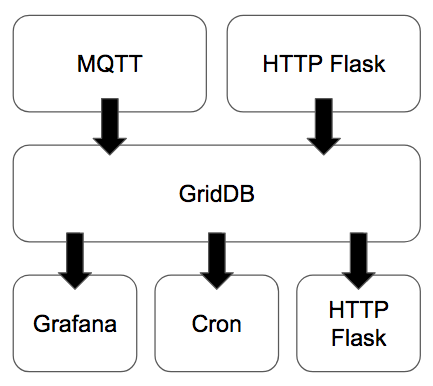
CroMFlaG2では、MQTTブローカーとサブスクライバーまたはHTTP Flaskアプリケーションがデータコレクターとして機能し、GridDBはデータストアとなります。HTTP Flaskはエンドポイントとしても動作し、信頼できないアプリケーション(データホスティング組織外のサードパーティによって開発、実行されたアプリケーションなど)にリアルタイムデータを提供することができます。Grafanaはデータを視覚化するプラットフォームを提供し、Cronはレポートや請求書などを事前に定義された間隔で生成するために使用されます。
データの送信と収集
MQTT
MQTTは、マシン間(M2M)通信を対象とした軽量のパブリッシュ・サブスクライブプロトコルです。MQTTの主な利点は、接続が長く持続し、オーバーヘッドが低く(2バイト)、そしてメッセージが送信されるか、メッセージが受信されるか、メッセージが確実に一度で受信されるか、を保証する3つのQoSレベルを持つ点です。
MQTTブローカーは、データコレクターで実行され、センサまたはエッジデバイス内で実行されるMQTTパブリッシャーと、パブリッシャーのデータを読み取ってデータストアに書き込むMQTTサブスクライバーとの間でデータを受け渡すサービスです。Mosquitto、HiveMQ、RabbitMQなどのブローカーが人気があり、これらはすべてCroMFlaG2内で使用することができます。
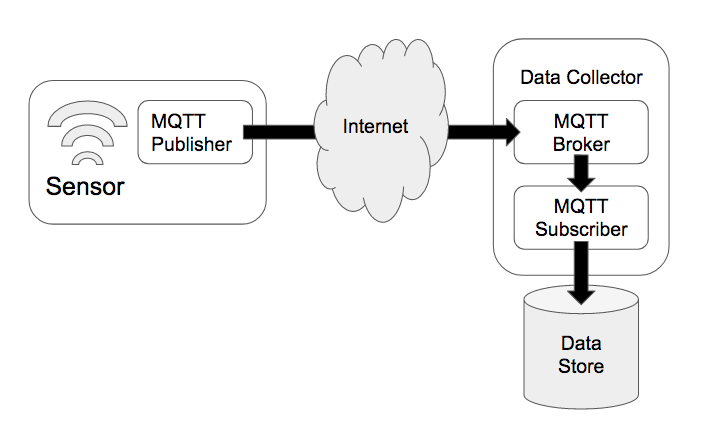
データは任意の形式で送信できますが、通常はバイナリ・ブロブか、もしくはより一般的なMessagePack、JSON、XMLなどの形式が使われます。MessagePackは非常に軽量なバイナリ形式であり、データ型変換またはカスタムパッキングを通じて簡単にシリアルライズすることができます。JSONとXMLはどちらも広く使用されており、生成と解析に使用できる優れたライブラリがあります。
HTTP/Flask
HTTPは最も一般的に使用されているネットワークプロトコルであり、ほぼすべてのWebトラフィックを処理することができます。HTTPはMQTTよりもネットワークオーバーヘッドが多く、QoS機能を備えていませんが、いくつかの利点があります。最初の利点として、HTTPがネットワークファイアウォールによってブロックされることはめったにありません。テストは簡単で、多くの開発者によく理解されています。また、HTTPを使用してソリューションを構築するための多くのライブラリとフレームワークを備えており、集中インフラストラクチャからエッジデバイスにデータを送信する場合は、信頼性が高くなります。
エッジまたはデバイス側では、libcurlまたはMicrosoftの C++ Rest SDKなどのより抽象化されたライブラリを使用してデータを送信することができます。データコレクターで受信データを処理するさまざまな方法もあります。その1つが軽量WebアプリケーションフレームワークであるFlaskです。
以下のサンプルコードは、curlを使用してレコードを挿入するデバイスをシミュレートする方法を示しています。シンプルなスクリプトにより、DevOpsの導入と継続的インテグレーションを簡単に実行できます。
$ curl -X POST --header "Content-Type: application/json" \
http://localhost:8000/insert/sample --data '{
"deviceinfo" : { "deviceid": "sample", "fw_ver" : "12345.009", "batt_lvl": 78 },
"tsdata": [
{ "day": 18, "dayofweek": 2, "hour": 17, "humidity": 75.0,
"illuminance": 74.0, "month": 2, "motion": false, "temperature": 78.0,
"timestamp": 1582046738255 },
{ "day": 18, "dayofweek": 2, "hour": 17, "humidity": 66.0,
"illuminance": 96.0, "month": 2, "motion": false, "temperature": 82.0,
"timestamp": 1582046748255 },
{ "day": 18, "dayofweek": 2, "hour": 17, "humidity": 67.0,
"illuminance": 93.0, "month": 2, "motion": false, "temperature": 81.0,
"timestamp": 1582046758255 },
{ "day": 18, "dayofweek": 2, "hour": 17, "humidity": 77.0,
"illuminance": 95.0, "month": 2, "motion": true , "temperature": 80.0,
"timestamp": 1582046768255 },
{ "day": 18, "dayofweek": 2, "hour": 17, "humidity": 70.0,
"illuminance": 90.0, "month": 2, "motion": false, "temperature": 79.0,
"timestamp": 1582046778255 },
{ "day": 18, "dayofweek": 2, "hour": 17, "humidity": 66.0,
"illuminance": 86.0, "month": 2, "motion": false, "temperature": 77.0,
"timestamp": 1582046788255 }
]
}'
以下は、GridDBへのデータ記録を可能にしたFlaskフレームワークで構築されたアプリの一例です。
#!/usr/bin/python3 -u
from flask import Flask, request, abort
from flask_cors import CORS, cross_origin
from datetime import datetime
import griddb_python
import json
griddb = griddb_python
factory = griddb.StoreFactory.get_instance()
app = Flask(__name__)
cors = CORS(app)
@app.route('/insert/', methods=['POST'])
def post(device):
try:
data = json.loads(request.data)
if data['deviceinfo']['deviceid'] != device:
abort(500, "malformed request")
conInfo = griddb.ContainerInfo("devices",
[["deviceid", griddb.Type.STRING],
["batt_lvl", griddb.Type.INTEGER],
["fw_ver", griddb.Type.STRING]],
griddb.ContainerType.COLLECTION, True)
devConInfo = griddb.ContainerInfo(device,
[["timestamp", griddb.Type.TIMESTAMP],
["motion", griddb.Type.BOOL],
["temperature", griddb.Type.FLOAT],
["humidity", griddb.Type.FLOAT],
["illuminance", griddb.Type.FLOAT],
["month", griddb.Type.LONG],
["day", griddb.Type.LONG],
["dayofweek", griddb.Type.LONG],
["hour", griddb.Type.LONG]],
griddb.ContainerType.TIME_SERIES, True)
col = gridstore.put_container(conInfo)
devCol = gridstore.put_container(devConInfo)
col.set_auto_commit(False)
devCol.set_auto_commit(False)
col.put([data['deviceinfo']['deviceid'], data['deviceinfo']['batt_lvl'],
data['deviceinfo']['fw_ver']])
tsdata = []
for row in data['tsdata']:
tsdata.append([datetime.fromtimestamp(row['timestamp']/1000), row['motion'],
row['temperature'], row['humidity'], row['illuminance'],
row['month'], row['day'], row['dayofweek'], row['hour']])
devCol.multi_put(tsdata)
col.commit()
devCol.commit()
except:
abort(500, "Insert failed")
return "True"
if __name__ == "__main__":
gridstore = factory.get_store(
host="239.0.0.1",
port=31999,
cluster_name="defaultCluster",
username="admin",
password="admin"
)
app.run(host='0.0.0.0', port=8000 )
デバイスは、JSONを解析してデータを複数のGridDBコンテナに挿入するエンドポイントにHTTP POST要求を送信します。
上記のコードには含まれていませんが、Flaskなどのウェブフレームワークを使用する大きな利点の1つは、デバイスの認証が簡単なことです。認証に実績のあるフレームワークを提供するOAuth2などのライブラリを含めることができます。
データの保存
GridDB
GridDBは、東芝デジタルソリューションズ株式会社が開発した、IoTおよびビッグデータ向けに最適化された高いスケーラビリティ特性を備えたインメモリNoSQL時系列データベースです。
GridDBのキー・コンテナデータモデルは、典型的なNoSQLキー・バリューストアを拡張します。キー・コンテナモデルは、キーによって参照されるコレクションの形式でデータを表します。キーとコンテナは、リレーショナルデータベース(RDB)のテーブル名とテーブルデータにほぼ相当します。GridDBでのデータモデリングは、RDBのスキーマと同様にスキーマを定義してデータを設計できるため、他のNoSQLデータベースよりも簡単です。
I/OはDBMSの一般的なボトルネックであり、CPUの使用率を低下させる可能性があります。GridDBのインメモリ・ディスクアーキテクチャのハイブリッド構成は、最大のI/Oパフォーマンスを実現するように設計されています。GridDBは、頻繁にアクセスされる「プライマリ」データがメモリに常駐し、残りがディスク(SSDおよびHDD)に渡される「メモリファースト、ストレージセカンド」構造でこのボトルネックを克服します。
GridDBは、Cassandraと比較したYCSBのベンチマークで示されているように、優れたパフォーマンスを維持しながら、汎用ハードウェア上で線形および水平方向にスケーリングします。従来のRDBMSは、スケールアップアーキテクチャに基づいて構築されています(既存のサーバやノードにCPUやメモリやストレージを追加します)。トランザクションとデータの整合性は、RDBMSの方がより優れています。一方のNoSQLデータベースはスケールアウトアーキテクチャに重点を置いていますが、トランザクションとデータの一貫性については改善の余地があります。
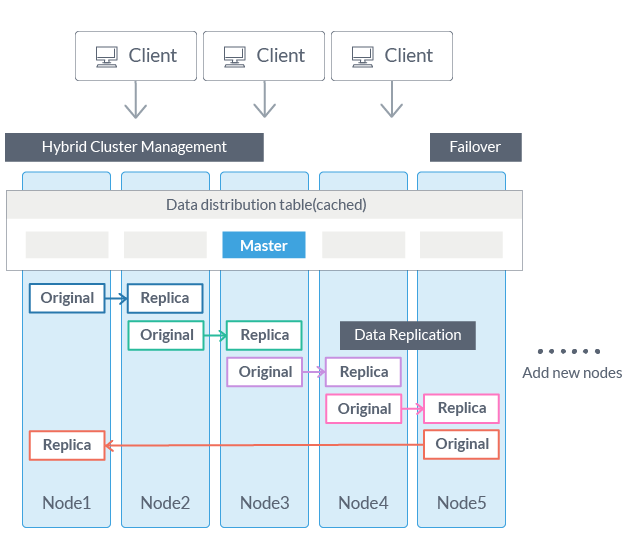
GridDBのハイブリッドなクラスター管理と高度な耐障害性を誇るシステムは、ミッションクリティカルなアプリケーションとしては非常に優れています。ネットワークパーティション、ノード障害、およびデータ一貫性の維持は、データがノード間で分散されるときに起こりがちな問題です。通常、分散システムは「マスタースレーブ」または「ピアツーピア」アーキテクチャを採用しています。マスター・スレーブオプションはデータの一貫性を維持するのに適していますが、シングルポイント障害(SPOF)を回避するためにマスターノードの冗長性を必要とします。ピアツーピアではSPOFを回避することができますが、ノード間の通信オーバーヘッドという大きな問題があります。
データの処理と利用
HTTP/Flask
HTTPとFlaskを使用してデータを取り込むように、HTTPとFlaskは、他のアプリケーション、特にサードパーティが使用するアプリケーションにデータを配信するのに最適です。HTTPとFlaskを使用する利点としては、開発の容易さ、HTTPが提供する柔軟性、そしてアプリケーションの構築に使用できるさまざまなライブラリとフレームワークの数などが挙げられます。
@app.route('/fetch/', methods=['GET'])
def fetch(device):
try:
ts = gridstore.get_container(device)
tql = "select *"
first = True;
if device != "devices":
for arg in request.args:
if first:
tql = tql + " WHERE"
else:
tql = tql + " AND"
if arg == "from":
tql = tql + " timestamp >= TO_TIMESTAMP_MS("+request.args['from']+") "
if arg == "to":
tql = tql + " timestamp < TO_TIMESTAMP_MS("+request.args['to']+") "
first = False
query = ts.query(tql)
rs = query.fetch(False)
columns = rs.get_column_names()
datadict = {}
retval=[]
while rs.has_next():
data = rs.next()
for col in columns:
if col == "timestamp":
datadict[col] = int(data[columns.index(col)].timestamp()*1000)
else:
datadict[col] = data[columns.index(col)]
retval.append(datadict.copy())
return json.dumps(retval)
except:
abort(500, "Fetch failed")
上記は、時系列データのクエリを実行することができるシンプルなエンドポイントの例です。オプション指定によってあるタイムスタンプ間のデータを問い合わせることができます。Pythonで利用可能な多数のデータ分析ツールや、OAuth2認証などのFlaskウェブフレームワークへの便利な追加機能により、必要に応じて機能を簡単に追加して、データプライバシーを確保したり、WebSocketsでリアルタイムストリーミングアプリケーションを構築したりすることが可能です。
Grafana
Grafanaは、GridDBを含む多くの異なるデータベースからデータを読み取ることができる、オープンソースの分析とインタラクティブな視覚化が可能なプラットフォームです。GridDBでGrafanaを使用する方法は2つあります。1つはFlaskでカスタムエンドポイントを使用した後にJSONデータソースを使用する方法、もう1つはGridDB WebAPIとネイティブのGrafana GridDBデータソースを使用する方法です。
Grafanaを使用することで、さまざまなグラフ形式でリアルタイムの時系列データを視覚化できるだけでなく、データベース駆動型の注釈を追加したり、テーブルに集計を表示したりすることもできます。
これは、運用チームにとっては事前の設定をほとんど行わずに機器を監視することができ理想的なツールであると言えます。
Cron
Cronは、ソフトウェアの管理に使用されるユーティリティの中で最も古いもの1つであり、そのシンプルな使いやすさと有効性のために今も見落すことのできないものです。Cronを使用することで、任意のタスクを実行する目的のアプリケーションを、毎時、毎週、毎月実行することができます。CroMFlaG2スタックにおいて、これらのアプリケーションは通常、取り込まれたデータに基づいて、毎日または毎週のレポートまたは毎月の請求書を生成します。
Cronは、ほとんどのLinuxディストリビューションに含まれているだけでなく、Kubernetesコンテナオーケストレーションを使用してアプリケーションをデプロイすることもできます。
結論
CroMFlaG2を使用すると、開発者はインフラストラクチャをIoTソフトウェアスタックに適応させるのではなく、インフラストラクチャに適応するオープンソースコンポーネントでIoTソリューションを構築することができます。MQTTとHTTP Flaskによって、高速データストリームと定期的なバッチデータの両方をGridDBデータストアに取り込むことができ、HTTP Flask、Cron、Grafanaによって、IoTデータをさまざまな方法で提供、処理、視覚化することができるようになります。
このブログで紹介したHTTP Flaskサンプルはこちらで、DockerイメージはDockerHubで入手することができます。PDFのホワイトペーパーはこちらからダウンロードできます。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb