このブログでは、GridDBに格納したデータをGrafanaで簡単に視覚化する方法を紹介します。
Grafanaのセットアップ
はじめに、Grafanaには適切なインストールドキュメントがこちらにあります。CentOS 7の基本的な手順は次のとおりです。
Grafana yumリポジトリーファイルを作成します。
$ sudo cat > /etc/yum.repos.d/grafana.repo << EOF > [grafana]
> name=grafana
> baseurl=https://packages.grafana.com/oss/rpm
> repo_gpgcheck=1
> enabled=1
> gpgcheck=1
> gpgkey=https://packages.grafana.com/gpg.key
> sslverify=1
> sslcacert=/etc/pki/tls/certs/ca-bundle.crt
> EOF
yumでパッケージをインストールし、GPGキーの確認画面で「y」と入力します。
$ sudo yum -y install grafana
Grafanaを起動し、起動時に開始するように設定します。
$ sudo /bin/systemctl enable grafana-server.service
$ sudo /bin/systemctl start grafana-server.service
これで、http://:3000/にアクセスしてGrafanaにログインすることができるようになりました。デフォルトのユーザーネームとパスワードはどちらも「admin」に設定されており、初回ログイン後すぐにパスワードを変更するように求められます。
GridDB Grafana-JSONコネクタを設定する
私たちは、GridDBに接続し、Grafana JSONデータソースプラグインからアクセス可能なエンドポイントを提供する、シンプルなPython Flaskアプリケーションを作成しました。こちら [ダウンロードが見つかりません]からダウンロードできます。 コネクタを変更せずに利用するには、便宜上、いくつかの制約を課しています。
- 時系列コンテナのみをクエリできます。
- 時系列コンテナのキーには「タイムスタンプ」という名前を付ける必要があります。
まず、GridDB Python Clientをインストールします。GridDB Python Client についてはこちらのブログに詳しい説明があります。
zipファイルを解凍し下記コマンドを実行します。
$ cd griddb_grafanajson_connector
$ nohup app.py &
コネクタのログは/tmp/griddb_grafanajson_connector.logに記録され、http://:3003/からアクセスすることができます。
Grafana JSON Data Sourceプラグインをインストールする
Grafana JSONデータソースプラグインは、grafana-cliツールを使用してインストールできます。インストール後にGrafanaを再起動してください。
$ sudo grafana-cli plugins install simpod-json-datasource
$ sudo systemctl restart grafana-server.service
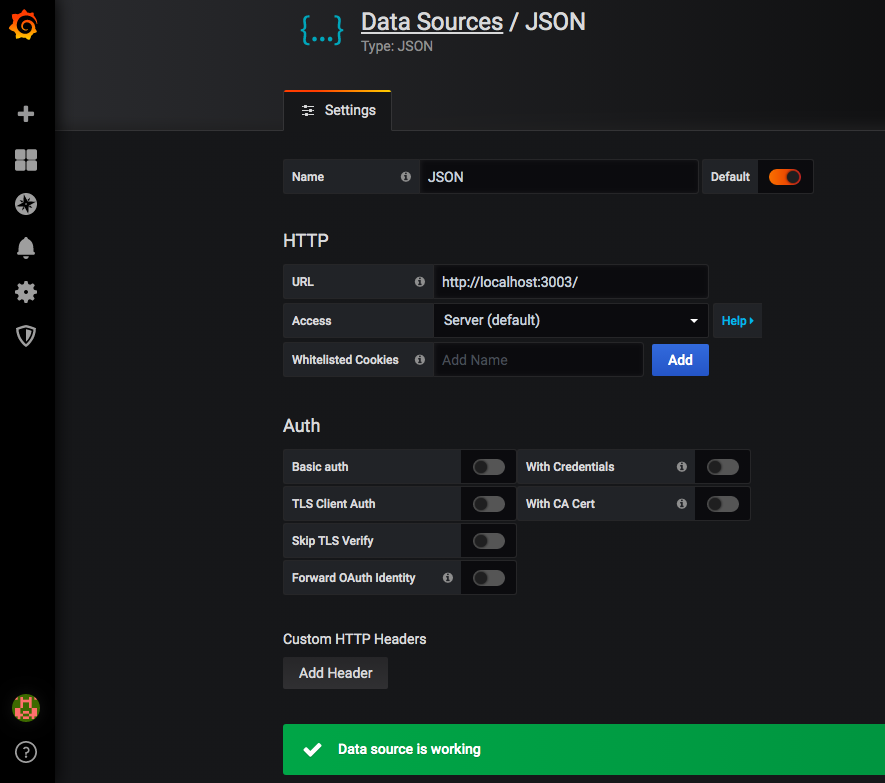
次に、WebブラウザーでGrafanaのインストールに進み、「データソースの追加」を選択します。JSONがリストにない場合は、検索し、追加するデータソースとして選択してください。
URLフィールドにhttp://localhost:3003と入力し、「保存してテスト」をクリックします。
データ視覚化を作成する
Grafanaホームページから「新しいダッシュボード」を選択すると、新しいパネルが表示された新しいダッシュボードが開きます。新しいパネル内で、「クエリの追加」を選択します。
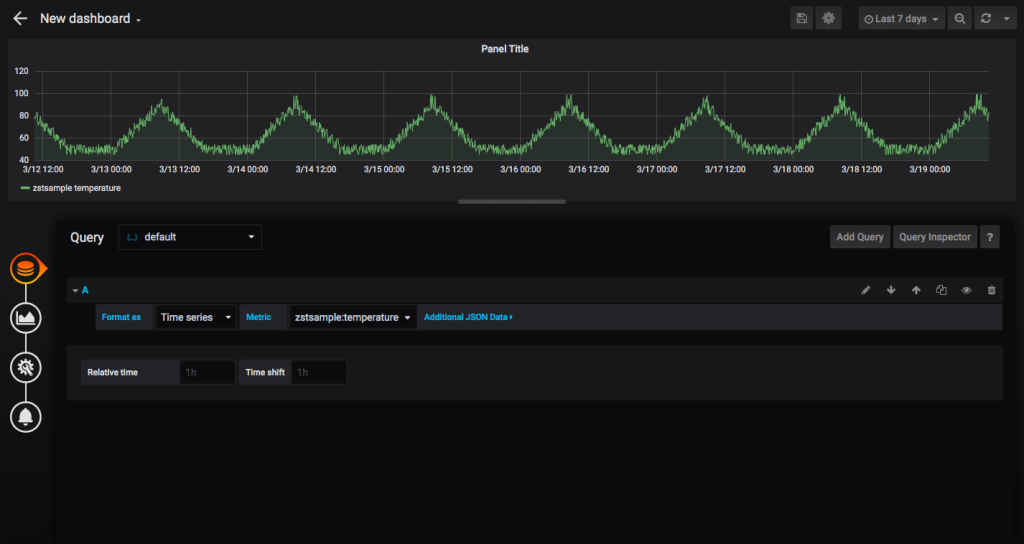
これで、パネルにメトリックを追加できるようになりました。コネクタが予期する形式は、:です。上のスクリーンショットでは、コンテナは「zstsample」、列は「温度」です。右上隅のウィジェットで時間範囲を調整することができます。
注釈を追加する
データ視覚化に注釈を追加する場合は、「ダッシュボードの設定」(タイトルの歯車型アイコン)、「注釈」、「新しい注釈」の順に進みます。
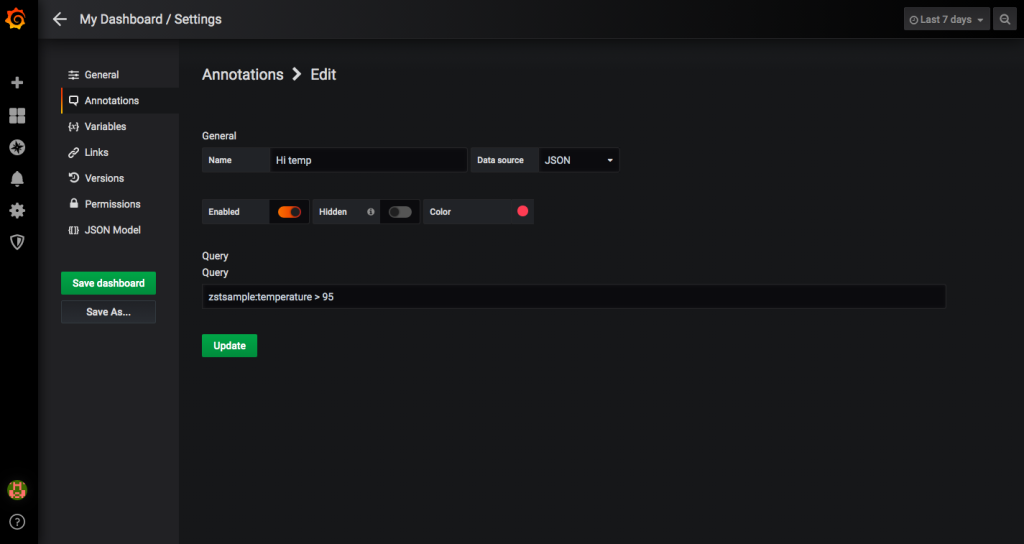
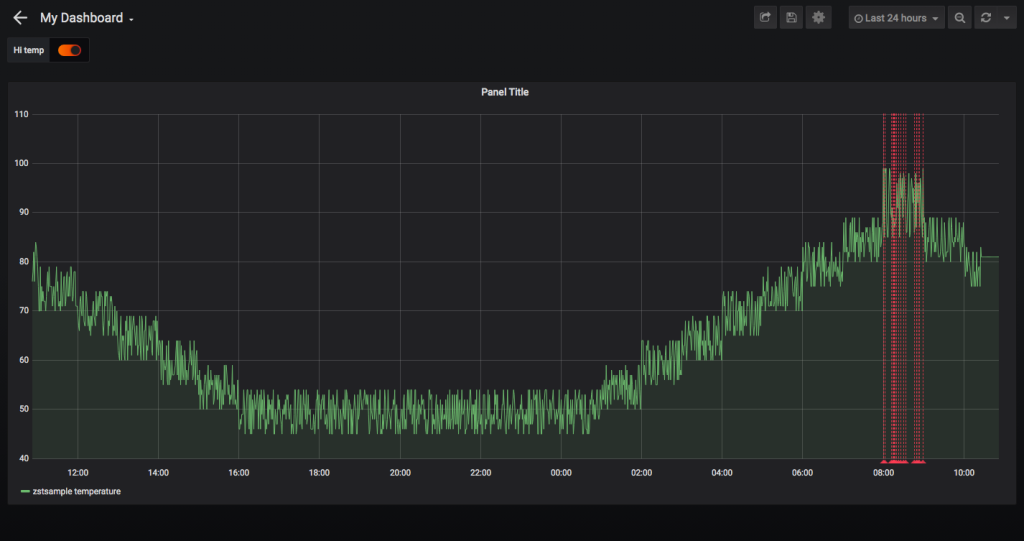
注釈の名前を作成し、データソースとして「JSON」を選択してクエリを入力します。 メトリックと同様に、形式は :です。今回は、温度が高い(> 95℉)箇所に注釈を付けたいので、「 zstsample:temperature > 95」と入力します。
注釈付きデータの視覚化は次のようになります。
データ集計を視覚化する
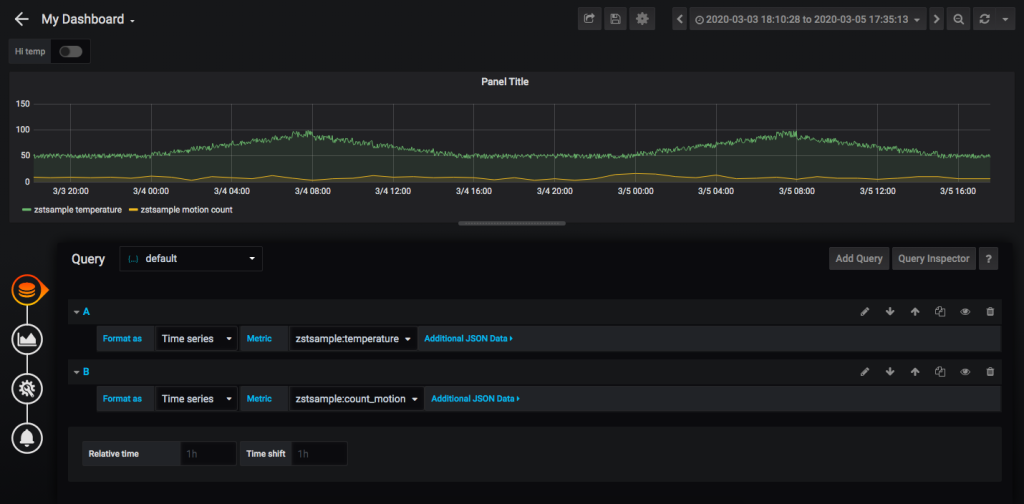
環境センサーからのデータセットには、センサーがモーションを検出したときにTrueに設定され、それ以外の場合にFalseに設定されたモーションフィールドがあります。各モーションイベントを簡単にプロットできますが、1時間あたりのモーションイベントの数を確認すると、視覚化を簡単に定量化できます。GridDBの集計とマルチクエリを使用して、GridDB Grafana JSONコネクタにカスタム関数を追加します。
def count_motion(container, start, end ):
results=[]
cn = gridstore.get_container(container)
i = 0;
lsQ=[]
datapoints=[]
interval_start= start - start%(3600*1000)
interval_end= start + 3600*1000
intervals=[]
while interval_end < end: tql = "select count(*) where timestamp > TO_TIMESTAMP_MS("+str(interval_start)+") and timestamp < TO_TIMESTAMP_MS("+str(interval_end)+") and motion"
print("AGG:"+tql)
query = cn.query(tql)
i=i+1
lsQ.append(query)
interval_start = interval_start + 3600*1000
interval_end = interval_end + 3600*1000
gridstore.fetch_all(lsQ)
interval=start
for q in lsQ:
rs = q.get_row_set()
rs.timestamp_output_with_float = True
columns = rs.get_column_names()
if rs.has_next():
row = rs.next()
datapoints.append([ row.get(griddb.Type.LONG), interval])
else:
datapoints.append([0, interval])
if interval == start:
interval=interval - start%(3600*1000) + 3600*1000
else:
interval=interval + 3600*1000
datapoints.append([datapoints[len(datapoints)-1][0], end])
return {'target': '%s' % (container+" motion count"), 'datapoints': datapoints }
この関数は、選択した時間の範囲で1時間ごとに繰り返し、モーションイベントの数をカウントします。関数を有効にするには、メインのクエリ関数をifステートメントで変更します。
if column == "count_motion":
results.append(count_motion(container, start, end))
else:
results.append(query_column(container, column, freq, start, end))
パネルに別のクエリを追加すると、特定の時間における特定のエリアのトラフィック量を確認することができます。
ここまででGridDBのさまざまなデータの視覚化の例を示し、コネクタの変更がいかに簡単かを紹介してきました。GridDBの集計とクエリを使用して、より複雑な視覚化を作成することもできます。ぜひ使ってみてください。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.