はじめに
データとは一般的に大量の数値の集まりであり、専門家でない人にとっては参考になるというよりも混乱させられるものかもしれません。ビッグデータの出現により、専門家でさえデータの分析に苦労しています。そこで可視化の出番です。データの可視化とは、図表を使って情報を視覚的にわかりやすく表したものです。チャート、グラフ、マップなどの視覚的要素が、データのトレンドを理解してデータ主導型の意思決定をする主要な鍵となります。上手に可視化することで情報を最も的確に伝えられるということが往々にしてあります。「百聞は一見にしかず」ということです。この記事では、PythonとGridDBを使って可視化する際の重要な要素をいくつか取り上げます。
可視化する時は、ビッグデータを扱いやすいデータベースを用意しておくことが重要です。そこでGridDBの出番です。GridDBはオープンソースの時系列データベースで、IoTとビッグデータに最適化されています。高い拡張性と信頼性を備え、高いパフォーマンスを保証し、IoTに最適化されています。さらに、C言語、Python、Javaなどの一般的なプログラミング言語で簡単に扱えます。インストールは非常に簡単です。詳しくはこちらにまとめられています。GridDB Python クライアントについては、このビデオをご参照ください。
この記事では、Pythonのmatplotlibライブラリを使って簡単に可視化する方法をいくつか紹介します。
設定
Ubuntu 20.04上でGridDB Python クライアントのクイック設定
- GridDBのインストール
ここから.debファイルをダウンロードしてインストールします。 -
Cクライアントのインストール
ここからUbuntuをダウンロードしてインストールします。 -
インストールの要件
A) SWIG
wget https://prdownloads.sourceforge.net/swig/swig-3.0.12.tar.gz
tar xvfz swig-3.0.12.tar.gz
cd swig-3.0.12
./configure
make
sudo make installB) PCRE
sudo apt-get install -y libpcre2-dev C) Pythonクライアントをインストールする
wget
https://github.com/griddb/python_client/archive/0.8.1.tar.gz
tar xvzf 0.8.1.tar.gz
お手持ちのPythonのバージョンに対応するpython-devがインストールされていることを確認してください。Python 3.6を使用している場合、先にリポジトリを追加する必要があるかもしれません。
sudo add-apt-repository ppa:deadsnakes/ppa そして
sudo apt-get install python3.6-dev
Pythonクライアントをインストールします。
cd python_client-0.8.1/
make
正しい位置も指定します。
export LIBRARY_PATH=$LIBRARY_PATH:/usr/share/doc/griddb-c-client [insert path to c_client]
export PYTHONPATH=$PYTHONPATH:[insert path to python_client]
export LIBRARY_PATH=$LD_LIBRARY_PATH:[insert path to c_client/bin]
Pythonライブラリ
この記事ではPython 3.6を使います。matplotlib、NumPy、statsmodels、pandasはpipで簡単にインストールできます。
pip install matplotlib
pip install numpy
pip install pandas
pip install statsmodels
これで可視化する準備が整いました。
GridDBは優れたインターフェースで時系列データにアクセスできます。GridDB クラスタに接続し、データをすべてpandasデータフレームに格納できます。この記事では、Pythonを使ってGridDBクラスタのデータにアクセスする方法を詳しく説明します。簡単に参照できるよう、単にGridDBクラスタを宣言し、SQLクエリを実行します。こちらが例です。
query = ts.query("select * where timestamp > TIMESTAMPADD(HOUR, NOW(), -6)")
データ分析と可視化
ステップ1:データセットのダウンロード
Kaggleで公開されているデータセットを使用します。この記事ではシャンプーの販売データを選びました。このデータセットは、シャンプーの3年間の月別売上です。売上と「年・月」を示す2つの列があります。
ステップ2:ライブラリのインポート
まず、関連するライブラリをインポートします。例えば、データセットロード用のpandas、可視化用のmatplotlib、時系列分析用のstatsmodelsなどです。matplotlibのPlot オブジェクトはpylotと呼び、pltとしてインポートします。時系列のインポートについては、この記事の後半で詳しく説明します。
import pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
ステップ3:データのロードと処理
まず、データをロードします。これには、pandasのread_csv関数を使用します。
df = pd.read_csv("sales-of-shampoo-over-a-three-ye.csv")
あるいは、GridDBを使ってこのデータフレームを取得することもできます。
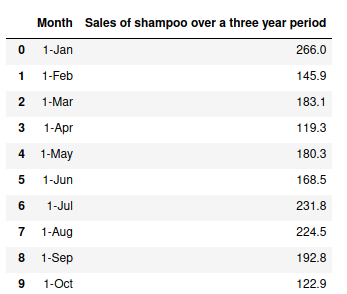
このデータには、 「月」 と「3年間のシャンプー売上」の2つの列があります。
次に、「年・月」が表示されている「Month」の列を、年と月の2つの列に分けます。
df[['year','month']] = df.Month.str.split("-",expand=True)
いよいよ可視化に進みます。
ステップ4:可視化
折れ線グラフ
まず、x軸が年・月、y軸が売上の簡単な折れ線グラフを使います。
figsizeで図形サイズを、linestyleで線種を、markerでマーカー(s=四角形)を指定します。
線とマーカーの色は、それぞれcolorとmarkerfacecolorで指定でき、マーカーサイズはmarkersizeで指定できます。さらに<グラフの>ラベル名も変更できます。グラフ上で指定することができるその他の引数はhttps://matplotlib.org/3.5.3/api/_as_gen/matplotlib.pyplot.htmlから参照できま
df.plot(x='Month',y='Sales of shampoo over a three year period',figsize=(15,6),linestyle='-', marker='s', markerfacecolor='b',color='y',markersize=11)
plt.xlabel('Year-Month')
plt.ylabel('Sales')
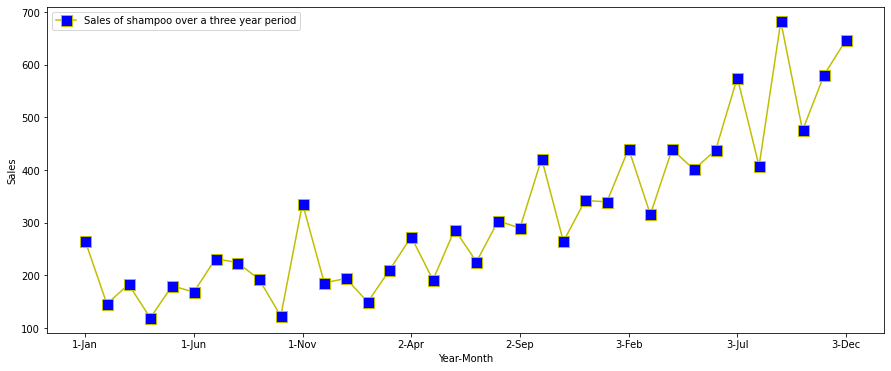
シャンプーの売上が前年比で増加していて、データは明らかに増加傾向があるとわかります。毎年、売上が一番高いのは決まって11月頃であることもわかります。データセットに季節性があると十分に言えるでしょう。
次に、1か月間のデータを平均化し、トレンドを確認します。
dfm =df.groupby('month').mean().reset_index().sort_values(by=['month'])
dfm["month_number"] = pd.to_datetime(dfm["month"], format= "%b").dt.month
dfm = dfm.sort_values(by=['month_number'])
dfm.plot(x='month',y='Sales of shampoo over a three year period',figsize=(15,6),linestyle='-', marker='s', markerfacecolor='b',color='y',markersize=11)
plt.xlabel('Year-Month')
plt.ylabel('Mean Sales')
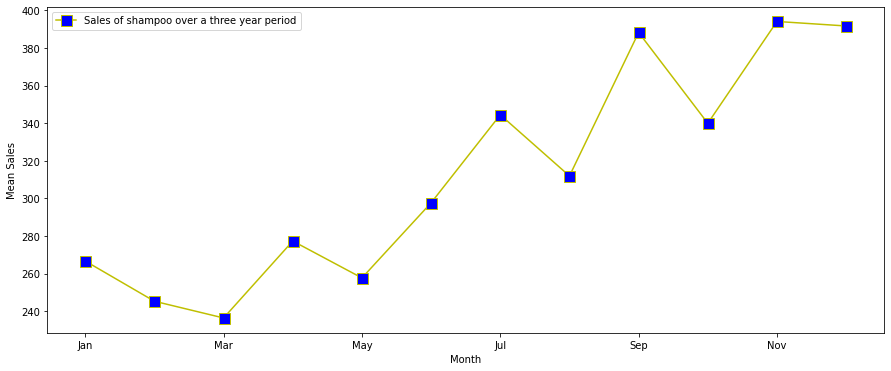
確かに売上は11月頃にピークを迎え、減少しています。
2Dヒートマップを使っても、うまく可視化できます。
x=dfm['month_number']
y=dfm['Sales of shampoo over a three year period']
plt.hist2d(x, y)
plt.xlabel('Month')
plt.ylabel('Mean Sales')

次は、基本的な時系列ベースのグラフをプロットします。
ラグプロット
ラグプロットは、y軸がx軸に対して一定のラグ(デフォルト1)がある簡単なプロットです。
ラグプロットを使うと、データセットがランダムかどうか検証できます。
時系列データセットなら、トレンドが確認できるはずです。
pd.plotting.lag_plot(df['Sales of shampoo over a three year period'])

いくつかのハズレ値はあるものの、上向きの線形傾向があると確認できます。
オートコレログラム、または自己相関プロット
オートコレログラムでも、データがランダムかどうか検証できます。さまざまな時間のラグがあるデータ値に対して自己相関を計算します。プロットは、x軸に沿ったラグとy軸上の相関を示します。点線より上の相関値は、統計的に有意差があることを示しています。
pd.plotting.autocorrelation_plot(df['Sales of shampoo over a three year period'])
ラグが低いデータセットには正の自己相関が見られます。データが3年分しかないので、ラグが高いと意味をなしません。statsmodelsのライブラリを使えばプロットの精度を上げられます。
import statsmodels.api as sm
sm.graphics.tsa.plot_acf(df["Sales of shampoo over a three year period"])
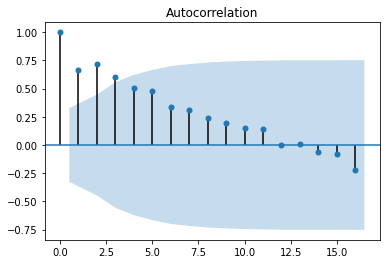
lag=12まで、正の相関が強いことがわかります。
季節性
ここでstatsmodelsのts関数の出番です。データのトレンドを確認するため、簡単な季節変動の分析を行います。季節性をプロットするのにseasonal_decomposeを使います。ただし、tsはdataindexを持つデータが必要なので、ダミーのdataindexを作成します。
df["month_number"] = pd.to_datetime(df["month"], format= "%b").dt.month
df.year = df.year.astype("int")
df["date"] = pd.to_datetime(((df.year+2000)*10000+df.month_number*100+1).apply(str),format='%Y%m%d')
df = df.set_index("date")
from statsmodels.tsa.seasonal import seasonal_decompose
decomp = seasonal_decompose(x=df[["Sales of shampoo over a three year period"]], model='additive')
est_trend = decomp.trend
est_seasonal = decomp.seasonal
fig, axes = plt.subplots(3, 1)
fig.set_figheight(10)
fig.set_figwidth(15)
axes[0].plot(df["Sales of shampoo over a three year period"], label='Original')
axes[0].legend()
axes[1].plot(est_trend, label='Trend',color="b")
axes[1].legend()
axes[2].plot(est_seasonal, label='Seasonality',color='r')
axes[2].legend()
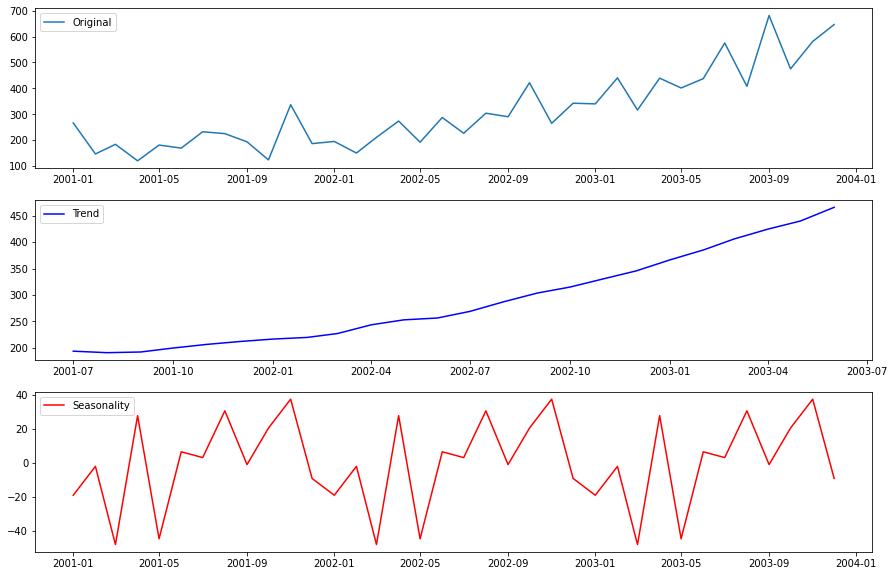
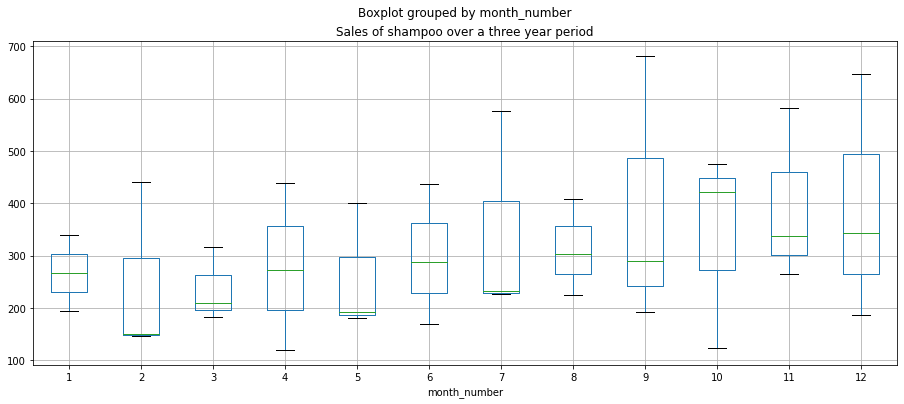
月別のグラフには、箱ひげ図も作れます。
df.boxplot(figsize=(15,6),by='month_number',column='Sales of shampoo over a three year period')

上昇傾向と、11月にピークを迎える緩やかな季節性が確認できます。しかしデータセットが少なすぎるので、季節性について結論は出せません。
結論
この記事では、最初にGridDBとPythonの設定方法を学びました。次に時系列を可視化する一般的な方法について考えました。最後にトレンド、自己相関、季節性の分析を行い、対応するグラフをプロットしました。より高度に可視化する方法やダッシュボードについて知りたい方は、こちらの記事をご覧ください。
ソースコード
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.