はじめに
オンラインアカウントでの異常なログインを知らせるメールが届くたびに、異常検知のプロセスが実行されていることがわかります。
異常検知は、現代のシステムが円滑かつ安全に稼働するために重要な役割を果たしており、不正検知、システムの健全性監視、侵入検知、障害検知、品質保証、データマイニングなど、さまざまな分野や使用例があります。
一言で言えば、異常検知とは、データセットの中にある通常とは異なるパターンや予想外のパターンを特定することです。これらの確率の低いアイテムやイベントは、一般的に外れ値と呼ばれます(文脈によってはノベルティとも呼ばれます)。
機械学習の技術は、外れ値の発見と処理のプロセスを自動化するのに役立ちます。これにより、異常検知を大規模に実行することができ、IoTやビッグデータアプリケーションのようなデータ集約型の分散システムの要求に応えることができます。
このブログ記事では、人気の高いPythonライブラリscikit-learn (sklearn)と、オープンソースのIoTに最適化された時系列データベースであるGridDBを併用して、異常検知技術を利用する方法を探ります。
いくつかの前置きについて
scikit-learnでの異常検知を始める前に、まず最初に設定しなければならない前提条件と、議論を進める上での留意点を説明します。
目標と範囲
前述したように、このブログではsklearnライブラリが提供する様々な異常検知ツールと機能、特にGridDBと組み合わせて使用する場合の機能を紹介します。できるだけ概要と背景を理解してもらうために、教師あり、教師なしの両方の異常検知について、sklearnとGridDBの両方を使用する場合の理想的なユースケースを紹介します。
また、この目的に沿ってわかりやすく説明するために、コード例ではGridDBとの連携、基本的な探索的データ分析、モデルのトレーニングに焦点を当てます。特徴選択、ハイパーパラメータチューニング、モデル選択など、機械学習パイプラインの他のステップについては省略します(ただし、これらのトピックについても重要なアイデアやコンセプトを盛り込みます)。
GridDBのセットアップと接続
ここでは、GridDBのインストールと設定方法については詳しく説明しません。もしGridDBの設定方法やPythonでの接続方法について詳しく知りたい場合は、便利なガイドが別のブログで公開されているのでぜひご覧になってください。また、GridDBとJupyterを素早く立ち上げるために、このdocker-composeファイルを使用することをお勧めします。
また、GridDBの接続を作成するヘルパー関数も書きました。このコードは前述のガイドに基づいており、プロジェクトディレクトリ内のutils/helpers/db.pyというファイルに保存されています。
$ sudo yum -y install griddb_nosql griddb-c-client
import jaydebeapi
def get_connection() -> jaydebeapi.Connection:
conn = jaydebeapi.connect(
"com.toshiba.mwcloud.gs.sql.Driver",
"jdbc:gs://griddb:20001/defaultCluster/public?notificationMember:127.0.0.1:20001",
["admin", "admin"],
"/usr/share/java/gridstore-jdbc-4.5.0.jar",
)
return conn
この機能により、Jupyter Notebookや本プロジェクトで使用する他のスクリプトやモジュール(次のセクションを参照)でGridDB接続を取得することができます。
データについて
scikit-learnの異常検知の概要を説明するために、2つの異なるデータセットを使用します。1つは教師なし異常検知の議論に使用する人工的に生成された時系列で、もう1つは教師あり異常検知モデルの学習に使用するラベル付きデータです。
人工的なセンサーデータの生成と保存
教師なしで異常を検出するために、電気使用量センサーの出力をシミュレートした人工的なデータセットを作成してみましょう。データポイントは、一定の時間間隔で取得されたセンサーの測定値(単位:キロワット時)です。これを行う関数は以下の通りです。
import numpy as np
import pandas as pd
rng = np.random.RandomState(42)
def create_sensor_data(
size: int,
freq: str,
outlier_fraction: float
) -> pd.DataFrame:
"""Generates toy time-series dataset."""
# Generate normally-distributed values
ts_index = pd.date_range("2020-01-15", periods=size, freq=freq)
sensor_readings = rng.normal(loc=4, scale=0.6, size=size)
df = pd.DataFrame(sensor_readings, index=ts_index, columns=["kwh"])
# Replace some values with outliers at random timestamps
num_outliers = int(outlier_fraction * size)
outlier_ts = np.random.choice(df.index, size=num_outliers, replace=False)
df.loc[outlier_ts, "kwh"] = rng.normal(
loc=9,
scale=0.01,
size=num_outliers
)
# Add integer timestamp column
df['ts'] = df.apply(lambda row: int(row.name.timestamp()), axis=1)
return df
この関数は、外れ値を含む正規分布の時系列データを持つpandasデータフレームを返します。
以降の説明のために、15分ごとに500個の観測値(そのうちの2%が外れ値)を生成します。
sensor_data = create_sensor_data(
size=500,
freq='15T',
outlier_fraction='0.02'
)
そして、以下の関数を用いて、時系列データをGridDBに格納します。
from jaydebeapi import Connection
def load_into_sensor_table(conn: Connection, data: pd.DataFrame) -> int:
"""Inserts data into sensor table."""
cursor = conn.cursor()
row_count = 0
try:
# Create table
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS power_sensor(
ts INTEGER PRIMARY KEY,
kwh FLOAT
)
"""
)
# Insert all rows
for row in data.itertuples():
cursor.execute(
"""
INSERT INTO power_sensor(ts, kwh)
VALUES (?, ?)
""",
(row.ts, row.kwh)
)
conn.commit()
# Check if successfully inserted
cursor.execute("SELECT * FROM power_sensor")
result = cursor.fetchall()
if len(result) == 0:
raise ValueError('No rows inserted')
row_count = len(result)
except Exception as e:
conn.rollback()
print(f'Error loading data into db: {e}')
finally:
cursor.close()
return row_count
ここでは、power_sensorというテーブルを作成し、値を行として挿入します。conn変数の値は、先ほど定義したget_connection()関数を使って以下のように取得できます。
from utils.helpers.db import get_connection
conn = get_connection()
nrows = load_into_sensor_table(conn, sensor_data)
nrows # Should be 500 if everything is ok
HTTPリクエストデータの読み込みと保存
教師ありの異常検知には、ODDS(Outlier Detection Datasets)サイトから入手可能なhttpデータセット(KDDCUP99)を使用します。このデータセットの詳細は以下の通りです。
- 567,498個のデータポイントを含み、それぞれがHTTPリクエストを表します。
- 3つの属性(duration, src_bytes, and dst_bytes)を含んでいます。
- リクエストが攻撃(1)であるか通常のトラフィック(0)であるかを示すラベル列を持ちます。
- 元の値をゼロから遠ざけるために、属性を対数変換しています。
- 2,211(0.4%)の攻撃(外れ値)を含みます。
これはダウンロード可能な.matファイルとして提供されていますが、scipy.io.loadmatでは簡単に読めません。そこで、mat7.3というパッケージを使用して、データを有効なPythonオブジェクトに適切に読み込む必要があります。
pandasデータフレームに変換されたデータは、時系列データセットで使用したのと同様の関数を使ってGridDBに格納されます。以下はそのコードの一例です。
# ...
try:
# Create table
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS http_traffic(
duration FLOAT,
src_bytes FLOAT,
dst_bytes FLOAT,
is_attack INTEGER
)
"""
)
# Insert all rows
for row in data.itertuples():
cursor.execute(
"""
INSERT INTO http_traffic (duration, src_bytes, dst_bytes, is_attack)
VALUES (?, ?, ?, ?)
""",
(
row.duration,
row.src_bytes,
row.dst_bytes,
row.is_attack,
)
)
conn.commit()
# ...
Sklearnによる異常検知
Sklearnには、教師あり、教師なしの両方の異常検知を行うための機械学習モデルの豊富なコレクションが搭載されています。ここでは、GridDBのデータに適用できるツールと、その適用方法について説明します。
教師なしの異常検知
データの異常なパターンがどのようなものであるかについての事前の知識がない限り、外れ値と正常なデータポイントとを見分けるには、教師なし異常検知技術に頼らざるを得ません。
教師なし異常検知は、データセットの正常な動作を最もよく表す確率分布を近似することで機能します。この分布から十分に離れたデータポイントは、潜在的な異常値または外れ値となります。
異常検知モデルによって、上記の問題を解決する方法は異なります。scikit-learnライブラリでは、密度ベースの異常検知アルゴリズム、クラスタベースのアプローチ、サポートベクターマシンモデルなどがあります。
教師なしの異常検知のためのSklearnモデル
一般的に使用されている教師なしのscikit-learnにおける異常検知モデルには以下のようなものがあります。
- NearestNeighbors
- LocalOutlierFactor
- IsolationForest
- EllipticEnvelope
- KMeans
- DBSCAN
- TSNE
- OneClassSVM
IsolationForestの使用例
それでは、sklearnのIsolationForestモデルを使った、教師なしの異常検知の例を見てみましょう。
Isolation Forestは、正常なデータポイントがどのように振る舞うかを近似するのではなく、データセット内の特定の外れ値を直接特定することで機能します。外れ値は稀であるため、通常のデータに比べて分離に要する分割数が少ないはずだという考えに基づき、アンサンブル法を用いて観測値を分離します。これにより、外れ値は木の根に近いところに配置され、その結果、横断するための平均経路長が短くなります。
Isolation Forestモデルがどのように動作するかを確認するために、人工的に作成されたセンサーデータに含まれる異常値を特定してみましょう。
まずは、必要なモジュールを読み込みます。
import math
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.ensemble import IsolationForest
from utils.helpers.db import get_connection
get_connection()関数は、./utils/helpers/db.py(./はこのJupyter Notebookがあるカレントディレクトリ)に保存したことを思い出してください。
以下の例では、GridDBデータベースに接続し、power_sensorテーブルからデータを読み込むSQLクエリを実行します。
conn = get_connection()
sql_stmt = 'SELECT * FROM power_sensor'
sensor_data = pd.read_sql(sql_stmt, conn)
読み込んだデータセットの情報を取得してみましょう。
sensor_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 500 entries, 0 to 499
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ts 500 non-null int64
1 kwh 500 non-null float64
dtypes: float64(1), int64(1)
memory usage: 7.9 KB
上記の結果より、タイムスタンプと電力使用量のデータが、GridDB データベースから正しいカラム名とデータタイプで DataFrame に正しく読み込まれていることがわかります。
この後の分析やデータの可視化を容易にするために、タイムスタンプをsensor_dataデータフレームのインデックスとして設定しましょう。
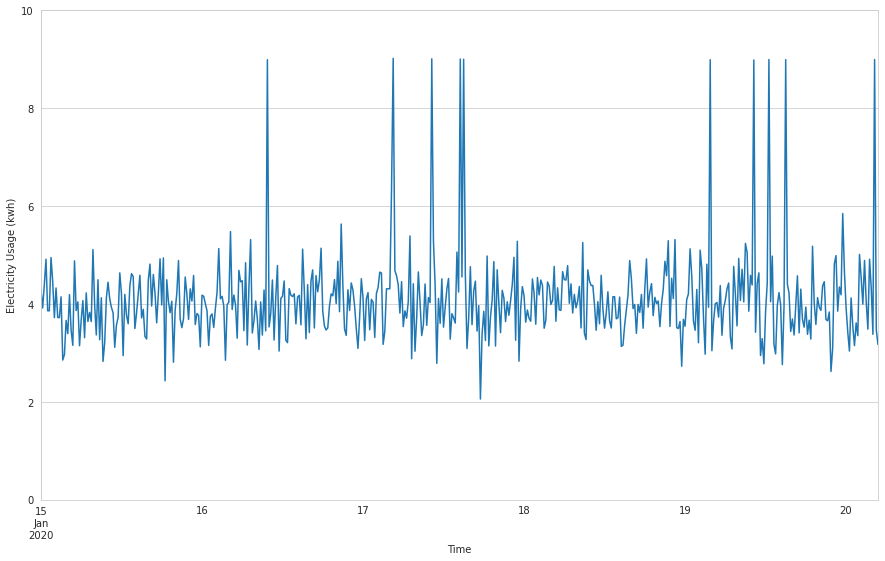
sensor_data.index = pd.to_datetime(sensor_data['ts'], unit='s')ここでは、kwh(電力使用量)のデータを、いくつかの要約統計を使って調べ、ランチャートとボックスプロットを使って、どのように分布しているかを把握します。
sensor_data.kwh.describe()
count 500.000000
mean 4.098142
std 0.908688
min 2.055240
25% 3.590052
50% 4.024251
75% 4.398410
max 9.019094
Name: kwh, dtype: float64
# Plot electricity usage
sensor_data.kwh.plot(
figsize=(15, 9),
ylim=(0, math.ceil(sensor_data.kwh.max())),
xlabel='Time',
ylabel='Electricity Usage (kwh)',
)

# Generate a box plot
sensor_data.kwh.plot.box()
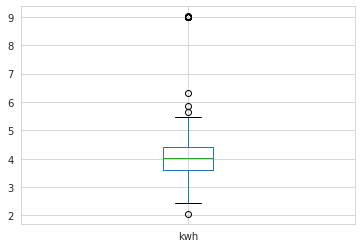
時系列プロットでは、グラフ上のいくつかのランダムなポイントで電力使用量の急激な増加が見られ、異常値の可能性を示しています。箱ひげ図でもう少し詳しく調べてみると、ひげの外側に位置するポイントがいくつかあり、これも異常値の可能性を示しています。
それでは、Isolation Forestモデルをトレーニングして、外れ値を識別できるかどうかを確認してみましょう。
# Reshape the kwh time series into a 500 by 1 array
kwh = sensor_data.kwh.values.reshape(-1, 1)
# Fit the isolation forest model
rng = np.random.RandomState(42)
isolation_forest_clf = IsolationForest(
contamination=0.02,
max_samples=100,
random_state=rng
)
isolation_forest_clf.fit(kwh)
outlier_pred = isolation_forest_clf.predict(kwh)
前述のコードスニペットでは、後でモデルをフィットさせる際に使用するために、まずkwhシリーズの列を(500, 1)形状のnumpy配列に変換します。次に、kwhの値の2%が外れ値であるという仮定のもと、IsolationForestモデルのインスタンスを作成します。次に、kwh配列の値を使ってモデルをフィッティングし、最後に学習したモデルを適用して、どのkwh値が外れ値で、どの値が外れ値でないかを予測します。
IsolationForestモデルのpredict()メソッドは、-1または1のいずれかの予測値の配列を返します。値が-1の場合は観測値が異常値であることを示し、1の場合は正常な観測値であることを示します。predict()メソッドは、各観測値の異常値スコアを計算し、そのデータポイントが異常値であるかどうかを判断します。
outlier_pred 配列を sensor_data の新しいカラムに格納し、どれだけの観測値が異常値と判定され、どれだけの観測値が正常値と判定されたかを見てみましょう。
sensor_data['predicted_outlier'] = outlier_pred
sensor_data.predicted_outlier.value_counts()
1 490
-1 10
Name: predicted_outlier, dtype: int64
上の結果から、モデルが10個のデータポイントを外れ値として分類し、490個のデータポイントを通常の観測値として分類していることがわかります。どのデータが外れ値なのか見てみましょう。
sensor_data.loc[sensor_data.predicted_outlier == -1, ['kwh', 'predicted_outlier']]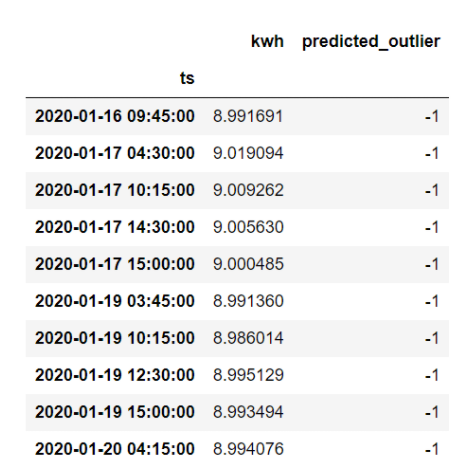
学習したモデルによって計算された異常スコアを分析するために、scikit-learn公式サイトにあるIsolationForestの使用例で用いられているのと同様のアプローチをとります。Isolation Forestに関するこちらの記事からコードを借用してみましょう。これで、異常スコアの閾値と外れ値の領域を以下のように可視化することができます。
plt.plot(xx, anomaly_score, label='Anomaly Score')
plt.fill_between(
xx.T[0],
np.min(anomaly_score),
np.max(anomaly_score),
where=outlier==-1,
color='r',
alpha=.4,
label='outlier region'
)
plt.legend()
plt.ylabel('Anomaly Score')
plt.xlabel('Electricity Usage (kwh)')
plt.show();
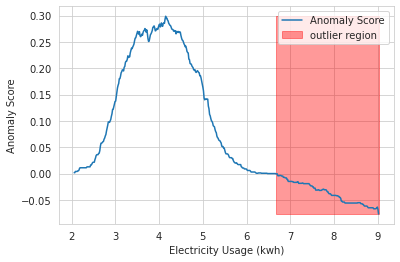
見ての通り、訓練されたIsolation Forestモデルは、人工的なデータ生成手順で作成した外れ値のすべてを正しく識別します。しかしこれには重要な注意点があり、観測したデータの何パーセントが実際に外れ値であるかを事前に知っているということです。
教師ありの異常検知
解析対象のデータセットに、どのデータポイントが異常値で、どのデータポイントが正常値であるかを示すラベルが含まれている場合、異常値検出プロセスは分類技術に依存する。教師あり分類モデルは、特徴とラベルの間の関係を識別することで、異常値を判定します。
モデルがこれらの関係を正しく学習するためには、外れ値の十分なインスタンスを含むデータセットで学習する必要があります。しかし、もともと外れ値は少ない傾向にあるため、データセットのバランスが悪いという問題があります。アンバランスなデータセットでは学習時に外れ値が過小評価され、その結果としてモデルの異常値検出の精度が低くなってしまいます。
教師あり異常検知のためのSklearnモデル
教師あり異常検知のためによく知られたscikit-learnモデルには、以下のようなものがあります。
- KNeighborsClassifier
- SVC (SVM classifier)
- DecisionTreeClassifier
- RandomForestClassifier
RandomForestClassifierの使用例
scikit-learnのRandomForestClassifierを使ってHTTP攻撃を識別する異常検知モデルを学習してみましょう。ここでは、上記で紹介した http (KDDCUP99) データセットを使用します。
教師あり分類タスクのために、scikit-learnライブラリから追加のモジュールと関数をインポートします。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
教師なしの異常検知の例と同様に、GridDB 接続を使用して http_traffic テーブルから必要なデータを取得します。
sql_stmt = 'SELECT * FROM http_traffic'
http_request_data = pd.read_sql(sql_stmt, conn)
データセットの全体像は以下の通りです。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 567498 entries, 0 to 567497
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 duration 567498 non-null float64
1 src_bytes 567498 non-null float64
2 dst_bytes 567498 non-null float64
3 is_attack 567498 non-null int64
dtypes: float64(3), int64(1)
memory usage: 17.3 MB
duration, src_bytes, dst_bytesを特徴量とし、is_attackにはラベル(通常のHTTPリクエストには0,HTTP攻撃には1)を設定しています。
データセットに含まれるHTTP攻撃のインスタンスの数を見てみましょう。
http_request_data.is_attack.value_counts()
0 565287
1 2211
Name: is_attack, dtype: int64
ここでラベル付けされた外れ値は合計2,211個で、全データポイントの約0.4%にあたります。
各属性の値をラベルに応じて分類した箱ひげ図で可視化すると、興味深いパターンが見えてきます。
http_request_data.boxplot(
column=['duration', 'src_bytes', 'dst_bytes'],
by='is_attack',
figsize=(12, 8),
layout=(3, 1)
)
外れ値と非外れ値を比較すると、3つの特徴それぞれの値の広がり方に明確な違いがあります。
次に、モデルフィッティングのためにデータを準備します。以下のようにして、データをトレーニングセットとテストセットに分けます。
rng = np.random.RandomState(42)
feature_cols = ['duration', 'src_bytes', 'dst_bytes']
features = http_request_data[feature_cols]
labels = http_request_data['is_attack']
features_train, features_test, labels_train, labels_test = train_test_split(
features,
labels,
stratify=labels,
test_size=0.05,
random_state=rng
)
上記では、stratifyパラメータにラベルの値を渡しています。これにより、外れ値クラスと非外れ値クラスの割合が、トレーニングデータセットとテストデータセットの両方で同じになるようにしています。
これで、モデルをフィットさせて予測値を出す準備ができました。
random_forest_clf = RandomForestClassifier(n_jobs=4, random_state=rng)
random_forest_clf.fit(features_train, labels_train)
labels_pred = random_forest_clf.predict(features_test)
訓練されたモデルの性能を、混同行列と分類レポートを見て確認してみましょう。
print(confusion_matrix(labels_test, labels_pred))
[[28264 0]
[ 0 111]]
print(classification_report(labels_test, labels_pred))
precision recall f1-score support
0 1.00 1.00 1.00 28264
1 1.00 1.00 1.00 111
accuracy 1.00 28375
macro avg 1.00 1.00 1.00 28375
weighted avg 1.00 1.00 1.00 28375
結果は、学習したモデルが外れ値と非外れ値を識別するのに非常に良い仕事をしていることを示しているようです。また、精度、再現率、f1スコアも非常に高い値を示しています。しかし、教師なしの異常検知の例と同様に、この数値をすぐに受け入れることには注意が必要です。これは、オーバーフィッティングの可能性や別の問題を示している可能性があります。現実的な状況では、これはより深い分析の一部に過ぎません。
まとめ
このブログ記事では、異常検知を行うためにscikit-learnライブラリに用意されているツールの概要を説明しました。また、教師あり、教師なしの異常検知の使用例を用いて、sklearnベースの機械学習プロジェクトでデータソースとしてGridDBを使用する方法を説明しました。これで、sklearnの異常検知機能をさらに探求するための準備が整ったことになります。
ソースコード
本記事で紹介したソースコードは GitHub で公開しています。