
ACID 特性とは?
ACID とは、データベースにおけるトランザクション処理の信頼性を保証するために求められる特性です。ここで「トランザクション」とは、データベースにある特定の操作を行う際の、一連のタスクをまとめたもので、それ以上分解できない処理単位です。
ACID は、Atomicity (原子性)、Consistency (一貫性)、Isolation (独立性)、Durability (永続性) の頭文字を取ったもので、それぞれ簡単に説明すると:
Atomicity:
トランザクションに含まれるタスクが全て実行されるか、あるいは全く実行されないかのどちらかであることを保証する性質
Consistency:
トランザクション開始と終了時にあらかじめ与えられた整合性を満たすことを保証する性質
Isolation:
トランザクション中に行われる操作の過程が他の操作から隠蔽されること
Durability:
トランザクション操作の完了通知をユーザが受けた時点で、その操作は永続的となり、結果が失われないこと
となります。
実際の処理における ACID 特性の説明には銀行での口座間送金がよく使われます。銀行口座 A から、銀行口座 B への送金を確実に行うためには、銀行口座 A からの出金と、銀行口座 B への入金の 2 つの処理が ACID 特性を満たすトランザクションとして処理される必要があります。逆に、ACID 特性が保証されない場合、口座 A の金額だけが減ったり、口座 B の金額が問い合わせの度に異なったり、おかしなことが起こる可能性があります。
そのため、EC サイトや銀行など、データの値のずれが重大な問題になるユースケースでは、トランザクション機能はデータベースの必須機能と言えます。
この銀行口座の例を使った、4 特性のそれぞれについての説明は、Wikipedia をはじめ、様々な場所でなされているので、より詳しくはリンク先を参照下さい。
NoSQL データベースにおけるトランザクション
ほとんどの伝統的なリレーショナルデータベースではトランザクション機能がサポートされています。これにより、適切な SQL 文でトランザクションを記述さえすれば、タイミングによって返り値が異なるようなことはありません。
一方、分散型の NoSQL データベースでは、処理の厳密性を緩和することで処理性能やスケールアウト性能の大幅な向上を実現しています。しかしその代償として、多くの NoSQL データベースでは、ACID 特性が保証されたトランザクション機能がサポートされていないか、何らかの制限があります。
GridDB も他の NoSQL データベースと同様、高速性・高スケーラビリティを追求しており、リレーショナルデータベースのようなデータベース全域に渡るトランザクション機能は持っていません。しかしながら、「コンテナ」単位ではトランザクションがサポートされています。下図に、GridDB のキー・コンテナ型の概念図を添付します。キー・コンテナ型について、詳しくはこちらの資料も参照下さい。
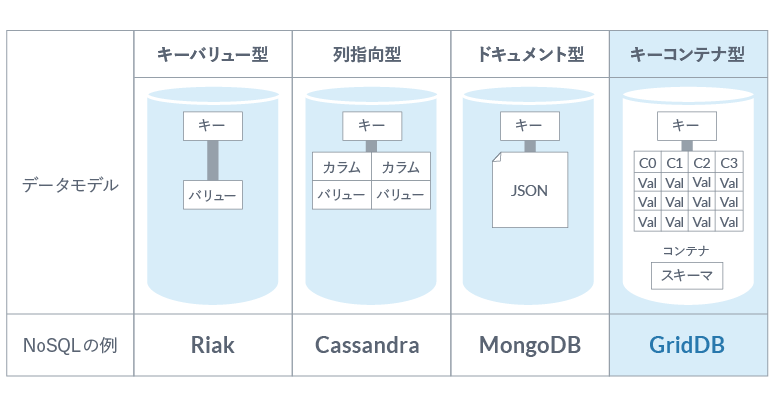
我々は、このコンテナ単位でのトランザクションが、IoTアプリケーションを想定した際に必要十分であると考えています。具体的な例として、こちらのブログで紹介したような、大量のスマートメーターに対する電力消費量計算の事例を考えてみましょう。
まず最初に、コンテナの粒度ですが、GridDB ではコンテナはセンサ(ここではスマートメーター) 毎に作成します。これにより、時系列データを扱う際に非常に便利な「時系列コンテナ型」を利用することが可能です。次に、各スマートメーターは地理的にグループ分けされていると思いますので、そのような地理情報を管理するコンテナを作ります。他に、様々な管理用のコンテナも必要かもしれませんね。
さて、GridDB では、コンテナ単位でのトランザクションをサポートすると述べました。つまり、この例では、スマートメーターコンテナ、管理用コンテナ、地理情報を管理するコンテナ、それぞれに対してACID保障されたトランザクション処理が可能で、SQL文もサポートされています。では、データベース全域に渡る計算についてはどうでしょうか?
GridDBでは、複数コンテナを参照するトランザクションではAtomicity (原子性)が保障されません。そのため、複数コンテナに対して値の更新を行うような場合には、アプリケーション側でエラー処理などを記述する必要があります。しかしこの事例で、データベース全域に対して行われる処理は、全てのスマートメーターのデータからある時間の電力消費量の合計を求めるとか、電力消費量の時間変化を分析し需要予測するとか、多くの場合で値の参照のみではないでしょうか。
前回のブログ記事で書いたとおり、GridDB はCAP 理論でいう CP 型のデータベースですので、可用性を重視した AP型のデータベースとは異なり、問い合わせの度に値が変わることはありません。よって、この例ではAtomicity の欠如は問題なく、アプリケーション側も特別なエラー処理などは必要ありません。データの集計・分析にフォーカスし、結果をリアルタイムに意思決定に活かすようなアプリケーションには、最適なデータベースと言えるでしょう。
いかがだったでしょうか?コンテナ単位でのトランザクションをサポートし、データベース全体でも一貫性を重視する GridDB は、パフォーマンスに不満を持つリレーショナルデータベースのユーザーにも最適です。是非、GridDB を試してみてください。Community Edition なら、AGPL ライセンスでソースコードが公開されており、いつでも無料で利用可能です。