
インターネット上には、日々膨大な量のニュースを提供するソースが存在します。また、ユーザーの情報に対する要求も高まり続けており、ユーザーが興味のある情報に素早く、効率的にアクセスできるようなニュースの分類が重要です。マルチクラステキスト分類のモデルを用いることで、ユーザは、追跡されていないニュースのトピックを特定したり、事前の興味に基づいた推薦をしたりすることができるようになります。そこで、ニュースの見出しと短い説明を入力とし、ニュースのカテゴリを出力とするモデルを構築することを目指します。
我々が取り組む問題は、BBCニュースの記事とそのカテゴリの分類です。テキストを入力として、そのカテゴリが何になるかを予測します。カテゴリには、ビジネス、エンターテイメント、政治、スポーツ、テクノロジーの5種類があります。
チュートリアルの概要は以下の通りです。
- 前提条件と環境設定
- データセット概要
- 必要なライブラリのインポート
- データセットの読み込み
- データのクリーニングと前処理
- 機械学習モデルの構築と学習
- まとめ
1. 前提条件と環境設定
このチュートリアルは、Windows オペレーティングシステム上の Anaconda Navigator (Python バージョン – 3.8.3) で実行されます。チュートリアルを続ける前に、以下のパッケージがインストールされている必要があります。
-
Pandas
-
NumPy
-
tensorflow
-
nltk
-
csv
-
griddb_python
-
matplotlib
これらのパッケージは Conda の仮想環境に conda install package-name を使ってインストールすることができます。ターミナルやコマンドプロンプトから直接Pythonを使っている場合は、 pip install package-name でインストールできます。
GridDBのインストール
このチュートリアルでは、データセットをロードする際に、GridDB を使用する方法と、With文を使用する方法の 2 種類を取り上げます。Pythonを使用してGridDBにアクセスするためには、以下のパッケージも予めインストールしておく必要があります。
- GridDB Cクライアント
- SWIG (Simplified Wrapper and Interface Generator)
- GridDB Pythonクライアント
2. データセット概要
テキスト文書は、企業にとって最も豊富なデータソースの1つです。
BBCが提供する2225の記事からなる公開データを使用します。各記事は、ビジネス、エンターテインメント、政治、スポーツ、技術という5つのカテゴリのうちの1つでラベル付けされています。
このプロジェクトで使用したデータセットは、BBC News Raw Datasetです。ダウンロードはこちら(http://mlg.ucd.ie/datasets/bbc.html)から可能です。
3. 必要なライブラリのインポート
import griddb_python as griddb
import csv
import tensorflow as tf
import numpy as np
import pandas as pd
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, LSTM, Dropout, Activation, Embedding, Bidirectional
import nltk
from nltk.corpus import stopwords
import matplotlib.pyplot as plt4. データセットの読み込み
続けて、データセットをノートブックにロードしてみましょう。
4.a GridDBの使用
GridDB™は、IoTやビッグデータに最適な高スケーラブルNoSQLデータベースです。GridDBの理念の根幹は、IoTに最適化された汎用性の高いデータストアの提供、高いスケーラビリティ、高性能なチューニング、高い信頼性の確保にあります。
大量のデータを保存する場合、CSVファイルでは面倒なことがあります。GridDBは、オープンソースでスケーラブルなデータベースとして、完璧な代替手段となっています。GridDBは、スケーラブルでインメモリなNoSQLデータベースで、大量のデータを簡単に保存することができます。GridDBを初めて使う場合は、GridDBへの読み書きのチュートリアルが役に立ちます。
すでにデータベースの設定が済んでいると仮定して、今度はデータセットを読み込むためのSQLクエリをpythonで書いてみましょう。
sql_statement = ('SELECT * FROM bbc-text')
dataset = pd.read_sql_query(sql_statement, cont)変数 cont には、データが格納されるコンテナ情報が格納されていることに注意してください。bbc-text はコンテナ名で置き換えてください。詳細は、チュートリアル GridDBへの読み書きを参照してください。
IoTやビッグデータのユースケースに関して言えば、GridDBはリレーショナルやNoSQLの領域の他のデータベースの中で明らかに際立っています。全体として、GridDBは高可用性とデータ保持を必要とするミッションクリティカルなアプリケーションのために、複数の信頼性機能を提供しています。
4.b With文の使用
Pythonでは、ファイルを開くことによって、そのファイルにアクセスできるようにする必要があります。これはopen()関数を用いて行うことができます。openはファイルオブジェクトを返し、そのオブジェクトは開かれたファイルに関する情報を取得し、操作するためのメソッドと属性を持っています。上記のどちらの方法を使っても、pandas dataframeの形でデータが読み込まれるので、同じ出力になります。
ntlkライブラリをインポートし、stopwords関数をインポートします。ここでは、英語のストップワードを設定します。英語のストップワードのサンプルは、has, hasn’t, and, aren’t, because, each, during です。
データをコンピュータが理解できるものに変換する作業を「前処理」と言います。前処理の代表的なものは、無駄なデータを取り除くことです。自然言語処理では、無駄な言葉(データ)のことをストップワードと呼びます。
ストップワードとは、一般的によく使われる単語(「the」、「a」、「an」、「in」など)で、検索用にエントリをインデックス化する際にも、検索クエリの結果としてエントリを取り出す際にも、検索エンジンが無視するようプログラムされているものです。このような単語がデータベース内のスペースを占有したり、貴重な処理時間を奪ったりすることは避けたいものです。このため、ストップワードと思われる単語のリストを保存しておくことで、簡単に削除することができます。
nltk.download('stopwords')
STOPWORDS = set(stopwords.words('english'))#We populate the list of articles and labels from the data and also remove the stopwords.
articles = []
labels = []
with open("bbc-text.csv", 'r') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
next(reader)
for row in reader:
labels.append(row[0])
article = row[1]
for word in STOPWORDS:
token = ' ' + word + ' '
article = article.replace(token, ' ')
article = article.replace(' ', ' ')
articles.append(article)モデルの構築と学習に必要なハイパーパラメータを設定します。
vocab_size = 5000
embedding_dim = 64
max_length = 200
trunc_type = 'post'
padding_type = 'post'
oov_tok = '<oov>' # OOV = Out of Vocabulary
training_portion = 0.8</oov>データセットが読み込まれたら、次はそのデータセットを調べてみましょう。head() 関数を使って、このデータセットの最初の 10 行を表示してみましょう。
5. データのクリーニングと前処理
articles[:1]['tv future hands viewers home theatre systems plasma high-definition tvs digital video recorders moving living room way people watch tv radically different five years time. according expert panel gathered annual consumer electronics show las vegas discuss new technologies impact one favourite pastimes. us leading trend programmes content delivered viewers via home networks cable satellite telecoms companies broadband service providers front rooms portable devices. one talked-about technologies ces digital personal video recorders (dvr pvr). set-top boxes like us tivo uk sky+ system allow people record store play pause forward wind tv programmes want. essentially technology allows much personalised tv. also built-in high-definition tv sets big business japan us slower take europe lack high-definition programming. people forward wind adverts also forget abiding network channel schedules putting together a-la-carte entertainment. us networks cable satellite companies worried means terms advertising revenues well brand identity viewer loyalty channels. although us leads technology moment also concern raised europe particularly growing uptake services like sky+. happens today see nine months years time uk adam hume bbc broadcast futurologist told bbc news website. likes bbc issues lost advertising revenue yet. pressing issue moment commercial uk broadcasters brand loyalty important everyone. talking content brands rather network brands said tim hanlon brand communications firm starcom mediavest. reality broadband connections anybody producer content. added: challenge hard promote programme much choice. means said stacey jolna senior vice president tv guide tv group way people find content want watch simplified tv viewers. means networks us terms channels could take leaf google book search engine future instead scheduler help people find want watch. kind channel model might work younger ipod generation used taking control gadgets play them. might suit everyone panel recognised. older generations comfortable familiar schedules channel brands know getting. perhaps want much choice put hands mr hanlon suggested. end kids diapers pushing buttons already - everything possible available said mr hanlon. ultimately consumer tell market want. 50 000 new gadgets technologies showcased ces many enhancing tv-watching experience. high-definition tv sets everywhere many new models lcd (liquid crystal display) tvs launched dvr capability built instead external boxes. one example launched show humax 26-inch lcd tv 80-hour tivo dvr dvd recorder. one us biggest satellite tv companies directtv even launched branded dvr show 100-hours recording capability instant replay search function. set pause rewind tv 90 hours. microsoft chief bill gates announced pre-show keynote speech partnership tivo called tivotogo means people play recorded programmes windows pcs mobile devices. reflect increasing trend freeing multimedia people watch want want.']
labels[:1] ['tech']それでは、BBCの公開データセットに対して、機械学習モデルを構築し、評価してみましょう。まず、モデルの「特徴」と「ラベル」を作成し、訓練用とテスト用のサンプルに分割します。テストサンプルはデータセット全体の20%としています。
トレーニングセットとバリデーションセットに分ける必要があります。80% (training_portion = .8) をトレーニング用に、残りの20%を検証用に設定します。
train_size = int(len(articles) * training_portion)
train_articles = articles[0: train_size]
train_labels = labels[0: train_size]
validation_articles = articles[train_size:]
validation_labels = labels[train_size:]5.a トークン化
トークン化は num_words を vocab_size (5000) と等しく、oov_token を ‘
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(train_articles)
word_index = tokenizer.word_indexoov_tokenは、その単語が辞書に載っていない場合に入れる値 ‘
5.b シーケンスに変換する
トークン化の後に、text_to_sequencesというメソッドがあります。これは、textsの各テキストを整数のシーケンスに変換します。このメソッドは基本的に、テキスト内の各単語を取り出し、辞書 tokenizer.word_index にある対応する整数値に置き換えます。その単語が辞書にない場合は、値として1が割り当てられます。
train_sequences = tokenizer.texts_to_sequences(train_articles)5.c 配列の切り捨てとパディング
自然言語処理のために学習させる場合、それらの配列を同じ大きさ(具体的な形)にする必要があります。すべての配列が同じサイズになるように、パディングを使い、切り捨てます。
train_padded = pad_sequences(train_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)train_articlesとvalidation_articlesに対して、トークン化、シーケンスへの変換、padding/truncatingを適用する予定です。
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(train_articles)
word_index = tokenizer.word_index
train_sequences = tokenizer.texts_to_sequences(train_articles)
train_padded = pad_sequences(train_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
validation_sequences = tokenizer.texts_to_sequences(validation_articles)
validation_padded = pad_sequences(validation_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)前回同様、ここでも機能や記事の場合と同じことをする必要があります。このモデルは単語を理解しないので、ラベルを数字に変換する必要があります。先ほどと同じようにトークン化し、シーケンスに変換します。トークン化の際、vocab sizeとoov_tokenは指示しません。
label_tokenizer = Tokenizer()
label_tokenizer.fit_on_texts(labels)
training_label_seq = np.array(label_tokenizer.texts_to_sequences(train_labels))
validation_label_seq = np.array(label_tokenizer.texts_to_sequences(validation_labels))6. 機械学習モデルの構築
これでニューラルネットワークのモデルを作成する準備が整いました。モデルの構造は以下の層で構成されています。
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(Dropout(0.5))
model.add(Bidirectional(LSTM(embedding_dim)))
model.add(Dense(6, activation='softmax'))
model.summary() Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 64) 320000
_________________________________________________________________
dropout (Dropout) (None, None, 64) 0
_________________________________________________________________
bidirectional (Bidirectional (None, 128) 66048
_________________________________________________________________
dense (Dense) (None, 6) 774
=================================================================
Total params: 386,822
Trainable params: 386,822
Non-trainable params: 0
_________________________________________________________________そして、ラベルを One-Hot エンコーディングしなかったので、loss を sparse_categorical_crossentropy にして学習プロセスを構成するためにモデルをコンパイルします。オプティマイザはAdamを使用します。
opt = tf.keras.optimizers.Adam(learning_rate=0.001, decay=1e-6)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['accuracy'])num_epochs = 12
history = model.fit(train_padded, training_label_seq, epochs=num_epochs, validation_data=(validation_padded, validation_label_seq), verbose=2) Epoch 1/12
56/56 - 8s - loss: 1.6055 - accuracy: 0.2949 - val_loss: 1.4597 - val_accuracy: 0.3191
Epoch 2/12
56/56 - 5s - loss: 1.0623 - accuracy: 0.5854 - val_loss: 0.7767 - val_accuracy: 0.8000
Epoch 3/12
56/56 - 5s - loss: 0.6153 - accuracy: 0.7989 - val_loss: 0.7209 - val_accuracy: 0.7910
Epoch 4/12
56/56 - 5s - loss: 0.3402 - accuracy: 0.9101 - val_loss: 0.5048 - val_accuracy: 0.8135
Epoch 5/12
56/56 - 6s - loss: 0.1731 - accuracy: 0.9685 - val_loss: 0.1699 - val_accuracy: 0.9618
Epoch 6/12
56/56 - 6s - loss: 0.0448 - accuracy: 0.9955 - val_loss: 0.1592 - val_accuracy: 0.9663
Epoch 7/12
56/56 - 6s - loss: 0.0333 - accuracy: 0.9966 - val_loss: 0.1428 - val_accuracy: 0.9663
Epoch 8/12
56/56 - 5s - loss: 0.0400 - accuracy: 0.9927 - val_loss: 0.1245 - val_accuracy: 0.9685
Epoch 9/12
56/56 - 6s - loss: 0.0178 - accuracy: 0.9972 - val_loss: 0.1179 - val_accuracy: 0.9685
Epoch 10/12
56/56 - 5s - loss: 0.0135 - accuracy: 0.9972 - val_loss: 0.1557 - val_accuracy: 0.9573
Epoch 11/12
56/56 - 5s - loss: 0.0264 - accuracy: 0.9983 - val_loss: 0.1193 - val_accuracy: 0.9685
Epoch 12/12
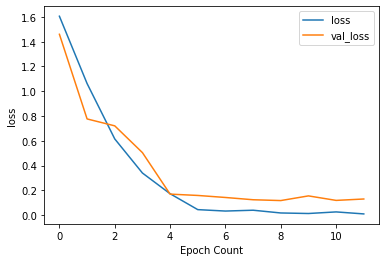
56/56 - 6s - loss: 0.0102 - accuracy: 0.9994 - val_loss: 0.1306 - val_accuracy: 0.9663精度と損失の履歴をプロットし、オーバーフィッティングが起きていないかどうかを確認します。
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epoch Count")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")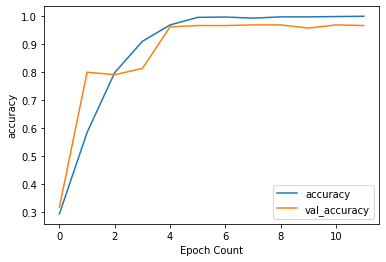
最後にpredict()というメソッドを呼び、サンプルテキストに対して予測を行います。
txt = ["Only bonds issued by the Russian government can be traded as part of a phased re-opening of the market. The exchange closed hours after Russian President Vladimir Putin sent thousands of troops into Ukraine on 24 February.Andrei Braginsky, a spokesman for the Moscow Exchange, said he hoped that trading in stocks would be able to start again soon. Technically everything is ready, and we are hoping this will resume in the near future, he said."]
seq = tokenizer.texts_to_sequences(txt)
padded = pad_sequences(seq, maxlen=max_length)
pred = model.predict(padded)
labels = ['sport', 'bussiness', 'politics', 'tech', 'entertainment']
print(pred)
print(np.argmax(pred))
print(labels[np.argmax(pred)-1]) [[2.6411068e-04 2.1545513e-02 9.6170175e-01 7.2104726e-03 1.0733245e-03
8.2047796e-03]]
2
bussiness7. まとめ
このチュートリアルでは、BBCニュースの記事のカテゴリを予測するために、LSTMを用いてテキスト分類モデルを構築しました。データのインポート方法として、(1)GridDBと(2)With文の2つの方法を検討しました。GridDBはオープンソースで拡張性が高いため、大規模なデータセットの場合、ノートブックにデータを取り込むための優れた代替手段を提供します。今すぐGridDBをダウンロードしてみましょう!
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.