
このブログでは、NYC(ニューヨーク)タクシーコミッションによって提供されたいくつかのオープンデータを用いて分析するための簡単なスクリプトを紹介します。ここに示す指針は、さまざまなタイプの問題に適用することができるでしょう。
GridDBサーバーをまだ設定していない場合は、クイックスタートに従って設定してください。Node.js用にGridDBを設定する場合は、こちらのブログを使用して設定することができます。NYC Open Dataのウェブサイトで、NYCタクシーのデータの詳細をダウンロードして見ることができます。
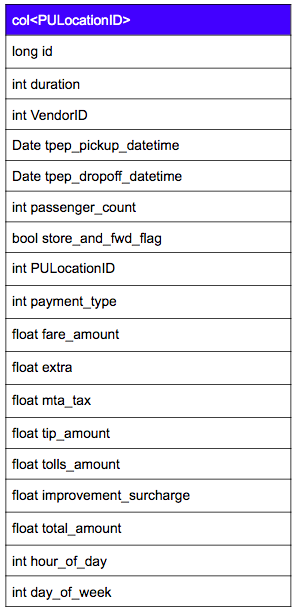
データモデル
VendorID,tpep_pickup_datetime,tpep_dropoff_datetime,passenger_count,trip_distance,RatecodeID,store_and_fwd_flag,PULocationID,DOLocationID,payment_type,fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,total_amount 2,03/13/2018 02:58:38 PM,03/13/2018 03:00:22 PM,1,0.31,1,N,132,132,2,3.5,0,0.5,0,0,0.3,4.3 1,03/13/2018 02:34:11 PM,03/13/2018 02:40:35 PM,1,2.3,1,N,132,132,1,9,0,0.5,1.95,0,0.3,11.75 1,03/13/2018 02:42:12 PM,03/13/2018 03:21:44 PM,1,17.5,2,N,132,230,1,52,0,0.5,5,5.76,0.3,63.56 1,03/13/2018 02:36:05 PM,03/13/2018 03:04:08 PM,1,10.5,1,N,230,138,1,32.5,0,0.5,7.8,5.76,0.3,46.86 1,03/13/2018 02:41:52 PM,03/13/2018 02:45:41 PM,1,0.7,1,N,264,264,2,5,0,0.5,0,0,0.3,5.8 1,03/13/2018 02:47:40 PM,03/13/2018 02:55:06 PM,1,1.3,1,N,264,264,1,7,0,0.5,2,0,0.3,9.8 1,03/13/2018 02:27:57 PM,03/13/2018 02:48:45 PM,1,4.8,1,N,142,13,1,18.5,0,0.5,3.85,0,0.3,23.15 1,03/13/2018 02:03:27 PM,03/13/2018 02:10:51 PM,1,0.6,1,N,164,100,1,6,0,0.5,1.36,0,0.3,8.16 1,03/13/2018 02:12:58 PM,03/13/2018 02:25:04 PM,1,1,1,N,100,230,2,8.5,0,0.5,0,0,0.3,9.3
オープンデータには17のフィールドがあるため、まずはデータを複数のコンテナーに分割する方法を決定します。最も理想的なのは、個々のタクシーからのデータを個々のコンテナーに入れる方法ですが、この方法ではデータが匿名化されるため各タクシーの一意の識別子は提供されません。次に望ましいフィールドは、PULocationIDです。これは、ニューヨークとその近隣の場所それぞれの一意の識別子を表す1〜265の整数です。
異なるタクシーがまったく同じ近所で同じタイミングで別の乗客を乗せている可能性があるため、tpep_pickup_datetimeを主キーとすることはできません。代わりに、行が追加されるたびに増分される一意の整数を使用します。
また、hour_of_dayとday_of_weekの計算フィールドをいくつか追加します。これはタクシーデータの分析に役立ちます。
var colInfo = new griddb.ContainerInfo({
'name': "col"+data['PULocationID'],
'columnInfoList': [
["id" , griddb.Type.LONG],
["duration" , griddb.Type.INTEGER],
["VendorID", griddb.Type.INTEGER ],
["tpep_pickup_datetime", griddb.Type.TIMESTAMP ],
["tpep_dropoff_datetime", griddb.Type.TIMESTAMP ],
["passenger_count", griddb.Type.LONG],
["store_and_fwd_flag" , griddb.Type.BOOL],
["PULocationID", griddb.Type.INTEGER],
["DOLocationID", griddb.Type.INTEGER],
["payment_type", griddb.Type.INTEGER],
["fare_amount", griddb.Type.FLOAT],
["extra", griddb.Type.FLOAT],
["mta_tax", griddb.Type.FLOAT],
["tip_amount", griddb.Type.FLOAT],
["tolls_aount", griddb.Type.FLOAT],
["improvement_surcharge", griddb.Type.FLOAT],
["total_amount", griddb.Type.FLOAT],
["hour_of_day", griddb.Type.INTEGER],
["day_of_week", griddb.Type.INTEGER]],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});
|
 |
データ取り込み
実際にデータを取り込む際は、csv-parser npm moduleを使用すると非常に簡単です。データはCSVパーサーからストリーミングされ、処理された後、単純な配列に変換します。この配列が適切なGridDBコンテナーに取り込まれます。
var griddb = require('griddb_node');
var fs = require('fs');
var csv = require('csv-parser')
let factory = griddb.StoreFactory.getInstance();
let store = factory.getStore({
"host": '239.0.0.1',
"port": 31999,
"clusterName": "defaultCluster",
"username": "admin",
"password": "admin"
});
let cols = {}
let count=0
fs.createReadStream('data.csv')
.pipe(csv())
.on('data', (data) => {
let row = []
row[0] = count++;
row[1] = parseInt(Date.parse(data['tpep_dropoff_datetime'])-Date.parse(data['tpep_pickup_datetime']))/1000)
row[2] = parseInt(data['VendorID'], 10);
row[3] = Date.parse(data['tpep_pickup_datetime'])
row[4] = Date.parse(data['tpep_dropoff_datetime'])
row[5] = parseInt(data['passenger_count'], 10)
if(data['store_and_fwd_flag'] == 'Y')
row[6] = true
else
row[6] = false
row[7] = parseInt(data['PULocationID'])
row[8] = parseInt(data['DOLocationID'])
row[9] = parseInt(data['payment_type'])
row[10] = Number(data['fare_amount'])
row[11] = Number(data['extra'])
row[12] = Number(data['mta_tax'])
row[13] = Number(data['tip_amount'])
row[14] = Number(data['tolls_amount'])
row[15] = Number(data['improvement_surcharge'])
row[16] = Number(data['total_amount'])
let date = new Date(row[3])
row[17] = date.getHours()
row[18] = date.getDay()
var colInfo = . . . snipped above . . .
store.putContainer(colInfo, false)
.then(cont => {
cont.put(row)
console.log(row[0])
})
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
});
分析
興味深い結果が得られるクエリはたくさんあります。たとえば、最も長距離の乗車はどれですか?最も料金が高額となったドライブはいつですか?最も忙しかった乗車はどれですか?
// standard boilerplate
var griddb = require('griddb_node');
var fs = require('fs');
var csv = require('csv-parser')
// our Cluster's credentials
let factory = griddb.StoreFactory.getInstance();
let store = factory.getStore({
"host": '239.0.0.1',
"port": 31999,
"clusterName": "defaultCluster",
"username": "admin",
"password": "admin"
});
let promises = []
let results = {}
var iterate = function(locID) {
return function(rowset) {
if(rowset != null) {
if (rowset.hasNext()) {
row = rowset.next();
results[locID] = row;
// if result is an aggregation use this instead
// results[locID] = row..get(griddb.GS_TYPE_LONG);
}
}
}
}
var query = function (locID) {
return function(cont) {
if(cont != null) {
q = cont.query("SELECT * ORDER BY fare_amount DESC LIMIT 1 ");
return q.fetch()
}
}
}
for (let i=0; i < 100; i++) {
var locID = i
promise = store.getContainer("col"+i)
.then(query(i))
.then(iterate(i))
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
})
promises.push(promise)
}
Promise.all(promises).then(values => {
var retval=null;
console.log("sorting...")
for (var k in results) {
if (retval == null || results[k][10] > retval[10])
retval=results[k]
}
console.log(retval)
})
上記のコードで調べた結果、3月22日に3時間を超え利用料金が計$475と最も高額な乗車が見つかりました。
[ 1725438, true, 2, 2018-03-22T06:43:13.000Z, 2018-03-22T09:59:34.000Z, 1, false, 93, 265, 1, 450, 0, 0, 0, 24.760000228881836, 0.30000001192092896, 475.05999755859375, 6, 4 ]
非同期の性質があるNode.jsでは、2つの手順が必要です。最初に、クエリパラメータ(locationID)を決定します。これは少し複雑で、プロミスチェーン内に配置され、カリー化を用いて解決することができ、以下のようにthen() 呼び出しで関数が指定されています。
for (let i=0; i < 100; i++) {
promise=store.getContainer("col"+i) .then(query(i)) .then(iterate(i))
...
}
すべてのクエリはバックグラウンドで同時に実行されるため、完了するまで待ちます。
最初に、クエリpromiseをリストに追加します。
promises.push(promise)
そして、すべてのpromiseが完了するのを待ちます。
Promise.all(promises).then(values => {
// display results
}
これを最も長距離の乗車を検索するクエリに変更するには、「fare_amount」を「duration」に変更し、最後の比較キーを「10」から「1」に変更します。
...
q = cont.query("SELECT * ORDER BY duration DESC LIMIT 1 ");
...
if (retval == null || results[k][1] > retval[1])
...
最も乗車回数の多いエリアを見たい場合は、集計クエリを使用します。あわせて結果の取得と最終的な並べ替えも変更されます。
...
var iterate = function(locID) {
return function(rowset) {
if(rowset != null) {
if (rowset.hasNext()) {
row = rowset.next();
results[locID] = row.get(griddb.GS_TYPE_LONG);
}
}
}
}
var query = function (locID) {
return function(cont) {
if(cont != null) {
q = cont.query("SELECT COUNT(*)");
return q.fetch()
}
}
}
...
Promise.all(promises).then(values => {
var items = Object.keys(results).map(function(key) {
return [key, results[key]];
});
items.sort(function(first, second) {
return second[1] - first[1];
});
console.log(items.slice(0, 10))
})
以下を出力すると、エリア161(マンハッタンミッドタウン)で156,727回の乗車があり最も忙しいことがわかります。
[ [ '161', 156727 ], [ '237', 153388 ], [ '162', 144923 ], [ '230', 143784 ], [ '186', 136234 ], [ '236', 136093 ], [ '170', 134533 ], [ '48', 131547 ], [ '234', 130747 ], [ '79', 115052 ] ]
より複雑な分析
上記のシンプルなクエリは興味深い傾向を知ることができましたが、たとえば「1日の特定の時間にどのエリアが最も忙しいか」などのより複雑なクエリを使えば、タクシー会社は利益を最大化するためのタクシーの配備を考えることができるようになります。
これには、複数のクエリを使用して、1日の特定の時間に各近隣からの乗車回数を知ることができます。場所ごと、時間ごとに、シンプルなカウント集計を実行します。
結果は、さらに処理を行う時のために2次元ディクショナリに配置されます。
var iterate = function(locID, hour ) {
return function(rowset) {
if(rowset != null) {
while (rowset.hasNext()) {
row = rowset.next();
results[hour][locID] = row.get(griddb.GS_TYPE_LONG)
}
}
}
}
var query = function (locID, hour) {
return function(cont) {
if(cont != null) {
q = cont.query("SELECT count(*) where hour_of_day = "+hour);
return q.fetch()
}
}
}
for(let hour=0; hour < 24; hour++) {
results[hour] = {};
for (loc=0; loc < 265; loc++)
results[hour][loc] = 0
for (let i=0; i < 265; i++) {
var locID = i
promise = store.getContainer("col"+i)
.then(query(i, hour))
.then(iterate(i, hour))
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
})
promises.push(promise)
}
}
次のスクリプトは、すべてのクエリプロミスを待ってから、最も乗車回数の多い10カ所を出力する最終処理を実行します。
Promise.all(promises).then(values => {
for (hour=0; hour < 24; hour++) {
var items = Object.keys(results[hour]).map(function(key) {
return [key, results[hour][key]];
});
items.sort(function(first, second) {
return second[1] - first[1];
});
locations = items.map(function(item) {
return item[0]
})
console.log(hour+": "+locations.slice(0, 10))
}
})
0: 79,230,48,249,148,234,132,161,164,114 1: 79,148,48,230,249,114,164,132,234,68 2: 79,148,48,114,249,68,230,164,158,234 3: 79,148,68,48,230,249,114,164,158,144 4: 79,48,230,148,68,164,249,186,107,114 5: 48,100,132,186,79,230,170,236,107,263 6: 186,48,100,132,236,170,162,68,107,263 7: 186,236,48,170,100,237,141,162,107,140 8: 236,237,170,186,48,141,162,107,140,239 9: 236,237,170,162,186,48,141,239,138,161 10: 237,236,186,138,162,170,161,48,230,142 11: 237,236,161,162,186,170,138,230,142,234 12: 237,236,161,162,186,170,230,234,239,138 13: 237,161,236,162,170,186,234,239,163,230 14: 237,161,236,162,234,170,239,163,138,186 15: 237,161,236,162,234,138,170,186,239,142 16: 161,237,236,162,138,234,132,170,230,239 17: 161,237,162,230,236,234,170,138,163,186 18: 161,162,237,230,234,236,170,163,186,142 19: 161,162,234,237,170,230,186,163,138,142 20: 161,162,234,230,170,237,79,186,48,138 21: 230,161,162,234,48,79,186,138,170,142 22: 230,161,48,79,234,186,162,142,164,138 23: 230,79,48,142,234,161,138,249,132,186
結果を見ると、早朝はエリア79(イーストビレッジ)が最も忙しく、昼頃にはエリア237(アッパーイーストサイド)が最も忙しく、夕方・夜は161(マンハッタンミッドタウン)が最も忙しいことが分かります。
最終処理を変更してパーセントで乗車回数を計算したり、上記のクエリを変更して潜在的な最大収益を見つけることも簡単にできます。
スクリプトのフルバージョンは、こちらからダウンロードできます。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.